Command Palette
Search for a command to run...
Déploiement De DeepSeek R1 Avec Ollama Et Open WebUI
1. Introduction au tutoriel
DeepSeek-R1 est la première version de la série de modèles de langage lancée par DeepSeek en 2025, axée sur des tâches de traitement du langage naturel efficaces et légères. Cette famille de modèles est optimisée grâce à des techniques avancées, telles que la distillation des connaissances, visant à réduire les besoins en ressources de calcul tout en maintenant des performances élevées. DeepSeek-R1 est conçu en mettant l'accent sur des scénarios d'application pratiques, prend en charge un déploiement et une intégration rapides et convient à une variété de tâches, notamment la génération de texte, les systèmes de dialogue, la traduction et la génération de résumés.
Sur le plan technique, DeepSeek-R1 utilise la technologie de distillation des connaissances pour extraire les connaissances de grands modèles afin de former des modèles plus petits avec des performances similaires. Dans le même temps, des algorithmes efficaces de formation et d’optimisation distribués réduisent encore le temps de formation et améliorent l’efficacité du développement du modèle. Ces points forts techniques permettent à DeepSeek-R1 de fonctionner efficacement dans des applications pratiques.
本教程预设 DeepSeek-R1-Distill-Qwen-1.5B 、 DeepSeek-R1-Distill-Qwen-7B 、 DeepSeek-R1-Distill-Qwen-8B 、 DeepSeek-R1-Distill-Qwen-32B 四种模型作为演示,算力资源采用「单卡 RTX4090」。
2. Étapes de l'opération
- Après avoir cloné et démarré le conteneur, cliquez sur l'adresse API pour accéder à l'interface Web (si « Bad Gateway » s'affiche, cela signifie que le modèle est en cours d'initialisation. Étant donné que le modèle est volumineux, veuillez patienter environ 5 minutes et réessayer.)
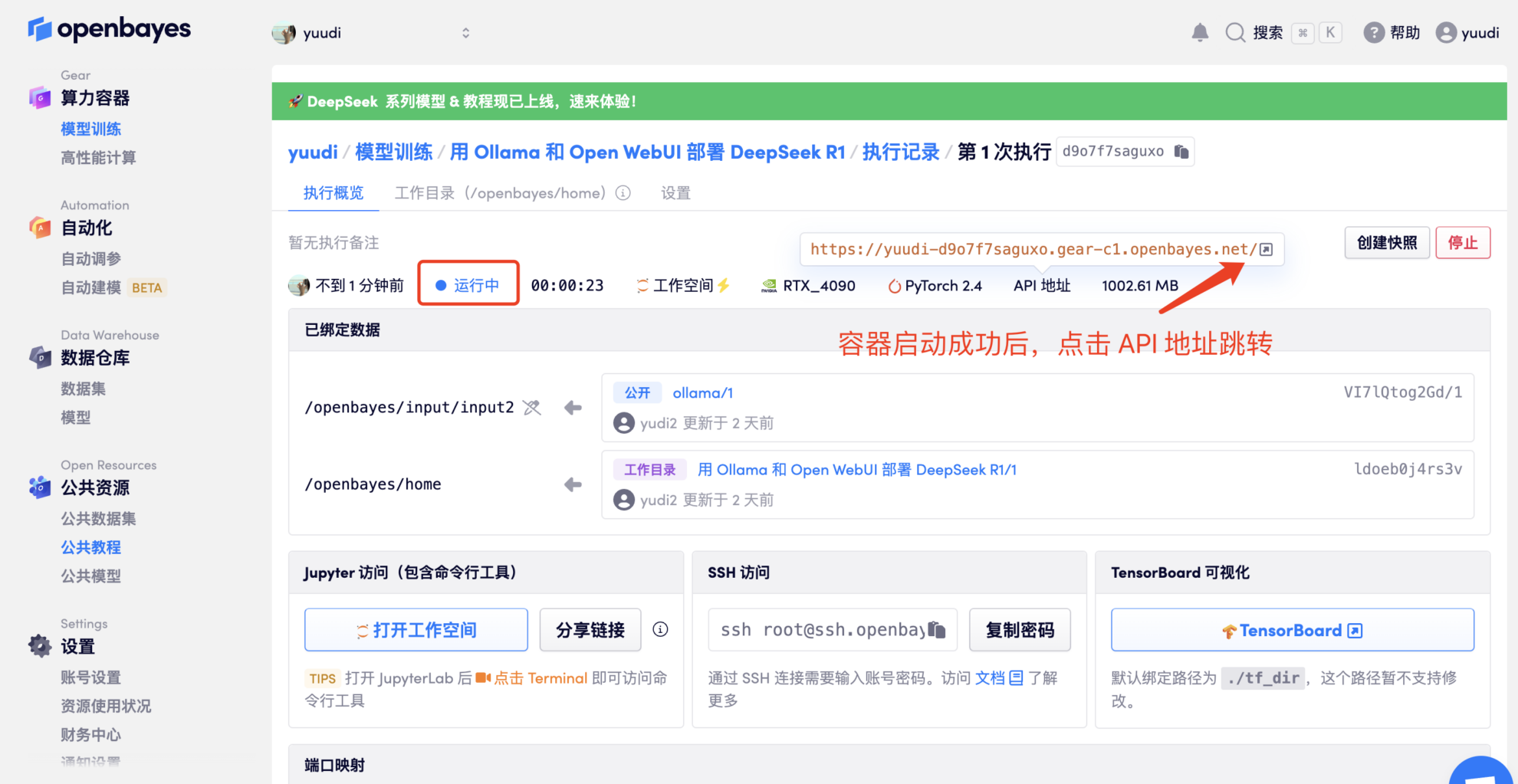
2. Après être entré sur la page Web, vous pouvez démarrer une conversation avec le modèle
Avis:
- Ce tutoriel prend en charge la « recherche en ligne ». Une fois cette fonction activée, la vitesse d'inférence ralentira, ce qui est normal.
- Vous pouvez changer de modèle dans le coin supérieur gauche de l'interface.
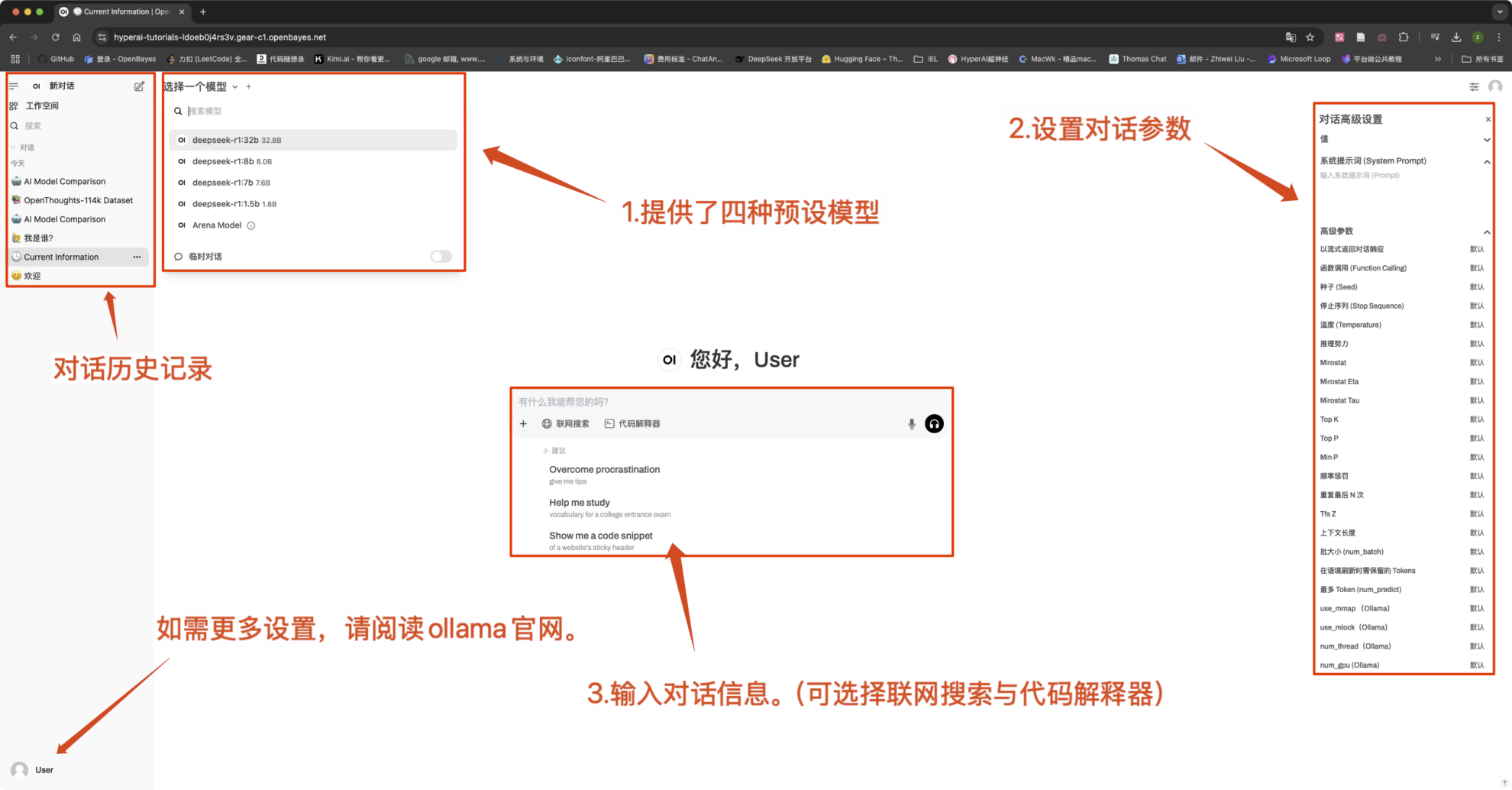
Paramètres de conversation courants
1. Température
- Contrôle le caractère aléatoire de la sortie, généralement dans la plage de 0.0-2.0 entre.
- Valeur faible (par exemple 0,1):Plus certain, biaisé vers les mots courants.
- Valeur élevée (par exemple 1,5):Contenu plus aléatoire, potentiellement plus créatif mais erratique.
2. Échantillonnage Top-k
- Uniquement à partir de Le k avec la probabilité la plus élevée Échantillonnage en mots, excluant les mots à faible probabilité.
- k est petit (par exemple 10):Plus de certitude, moins d’aléatoire.
- k est grand (par exemple 50):Plus de diversité, plus d'innovation.
3. Échantillonnage Top-p (échantillonnage du noyau, échantillonnage Top-p)
- choisirL'ensemble de mots avec une probabilité cumulative atteignant p, la valeur k n'est pas fixe.
- Valeur faible (par exemple 0,3):Plus de certitude, moins d’aléatoire.
- Valeur élevée (par exemple 0,9):Plus de diversité, une meilleure fluidité.
4. Pénalité de répétition
- Contrôle la répétition du texte, généralement en 1.0-2.0 entre.
- Valeur élevée (par exemple 1,5):Réduisez les répétitions et améliorez la lisibilité.
- Valeur faible (par exemple 1,0): Aucune pénalité, peut amener le modèle à répéter des mots et des phrases.
5. Max Tokens (durée de génération maximale)
- Modèle de restrictionNombre maximum de jetons générés, pour éviter une sortie trop longue.
- Gamme typique :50-4096(Dépend du modèle spécifique).
Échange et discussion
🖌️ Si vous voyez un projet de haute qualité, veuillez laisser un message en arrière-plan pour le recommander ! De plus, nous avons également créé un groupe d’échange de tutoriels. Bienvenue aux amis pour scanner le code QR et commenter [Tutoriel SD] pour rejoindre le groupe pour discuter de divers problèmes techniques et partager les résultats de l'application↓

Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.