Command Palette
Search for a command to run...
Ebook2Audiobook eBook Vers Livre Audio

1. Introduction au tutoriel
Ebook2Audiobook est un outil, open source en 2024, conçu pour convertir des livres électroniques (eBooks) en livres audio (audiobooks). Le projet utilise une technologie avancée de synthèse vocale (TTS) pour convertir automatiquement le contenu textuel des livres électroniques en parole, générant ainsi des livres audio que les utilisateurs peuvent écouter. Ebook2Audiobook prend en charge plusieurs formats de livres électroniques, tels que EPUB, PDF, MOBI, etc., et peut préserver la structure des chapitres et les métadonnées, ce qui rend les livres audio générés plus faciles à parcourir et à comprendre.
Caractéristiques du projet :
- 📖 Convertissez des livres électroniques au format texte à l'aide de Calibre.
- 📚Divisez les livres électroniques en chapitres pour organiser l'audio.
- 🎙️Synthèse vocale de haute qualité utilisant Coqui XTTSv2 et Fairseq.
- 🗣️Clonage vocal facultatif, utilisez vos propres fichiers vocaux.
- 🌍Prend en charge 1107 langues (anglais par défaut)
Nouveaux effets d'interface graphique Web v2.0

2. Étapes de l'opération
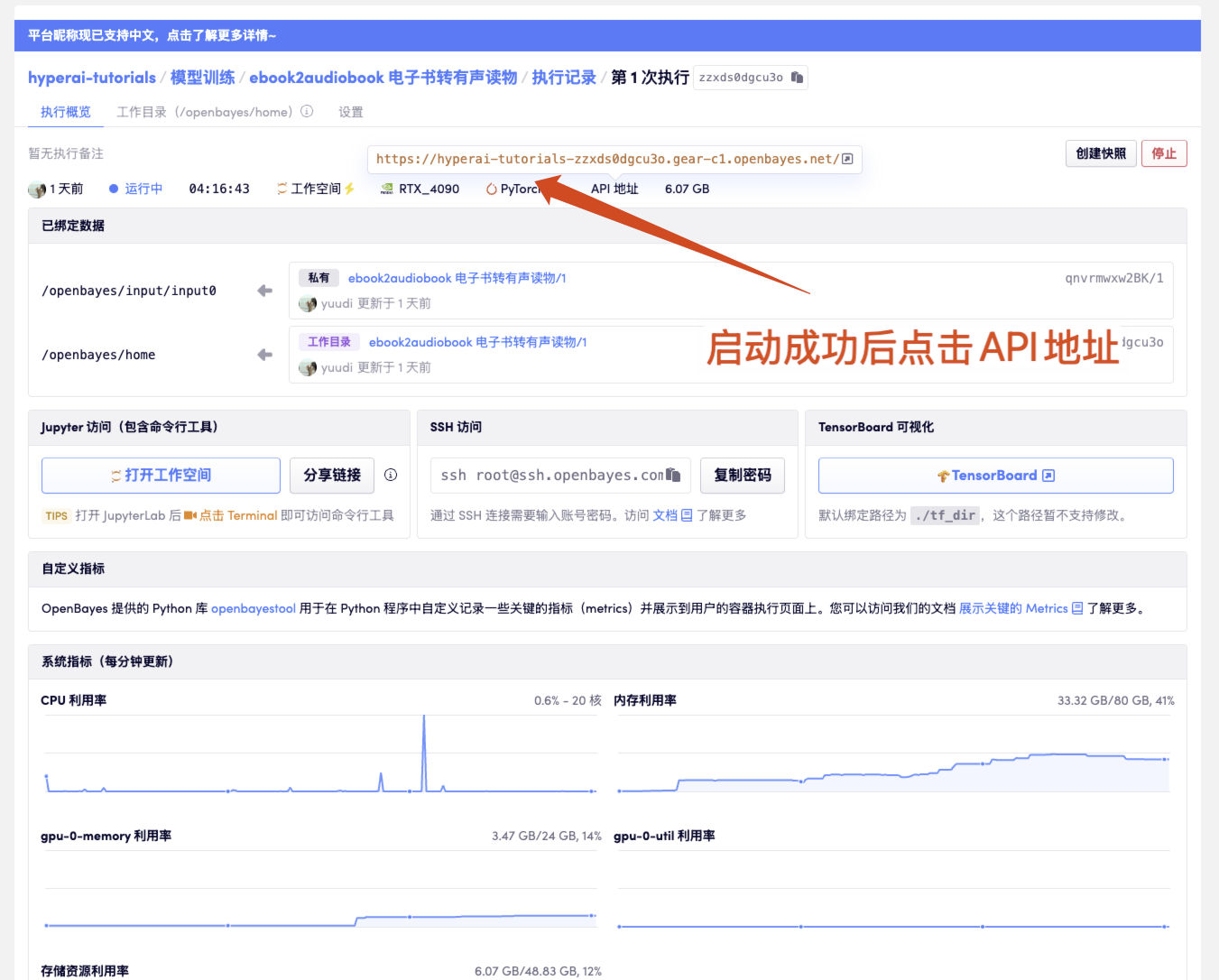
1. Démarrez le conteneur
Cliquez ensuite sur l'adresse API pour accéder à l'interface Web
2. Démonstration du processus
Veuillez noter:
- Ce projet a un « processus de chargement de modèle », qui prend environ 3 à 4 minutes ;
- Une fois la barre de progression générée, si l'audio en ligne ne peut pas être affiché, veuillez actualiser la page Web ou la télécharger sur votre ordinateur local pour la visualiser ;
- Lors de l'utilisation d'un fichier txt, seule la première ligne sera lue ;
- Veuillez noter que la langue du livre électronique doit être cohérente avec la langue sélectionnée, sinon une « langue non humaine » sera générée ;
- Dans ce projet, Fine Tuned Models met en cache uniquement le modèle std.
Requis:
- Document de livre électronique
- Sélectionnez la langue

Figure 1 Processus principal
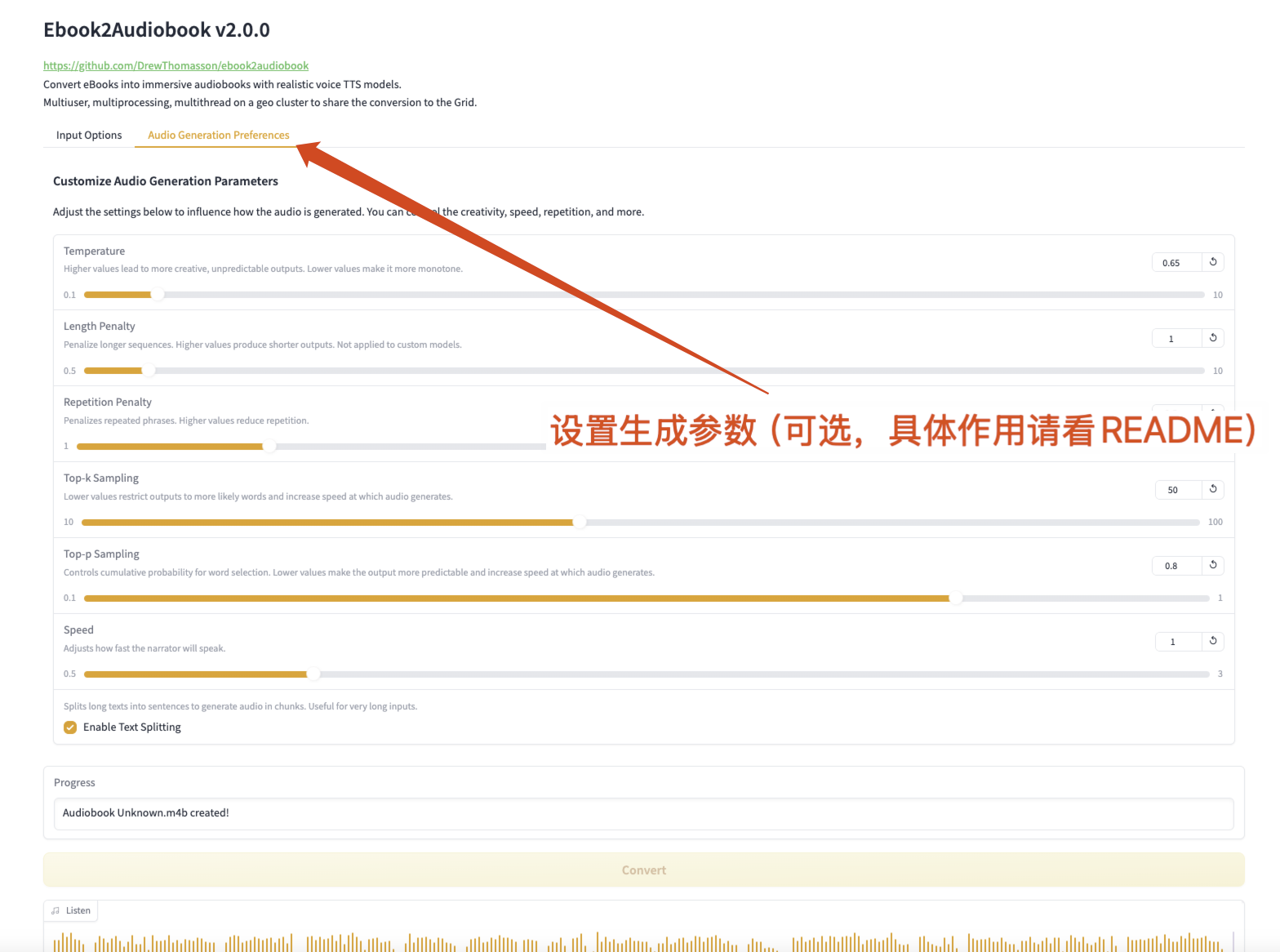
Figure 2 Génération des paramètres
Générer des paramètres
- Température: 0.65
- Des valeurs plus élevées produisent un résultat plus créatif et imprévisible, des valeurs plus faibles rendent le résultat plus monotone.
- Pénalité de longueur:Pénaliser les séquences plus longues
- Des valeurs plus élevées produisent une sortie plus courte (ne convient pas aux modèles personnalisés).
- Pénalité de répétition:Pénaliser les phrases répétées
- Des valeurs plus élevées réduisent la répétition.
- Échantillonnage Top-K: Des valeurs inférieures limitent la sortie aux mots les plus probables, accélérant ainsi la génération audio.
- Échantillonnage Top-p:Contrôler la probabilité cumulative de sélection de mots
- Des valeurs plus faibles rendent la sortie plus prévisible et génèrent l'audio plus rapidement.
- Vitesse du narrateur: Ajustez la vitesse de parole du narrateur.
- Fractionnement de texte: Divisez un texte long en phrases pour générer de l'audio en morceaux.
- Idéal pour les entrées très longues.
- Activer le fractionnement du texte: Activer le fractionnement du texte.
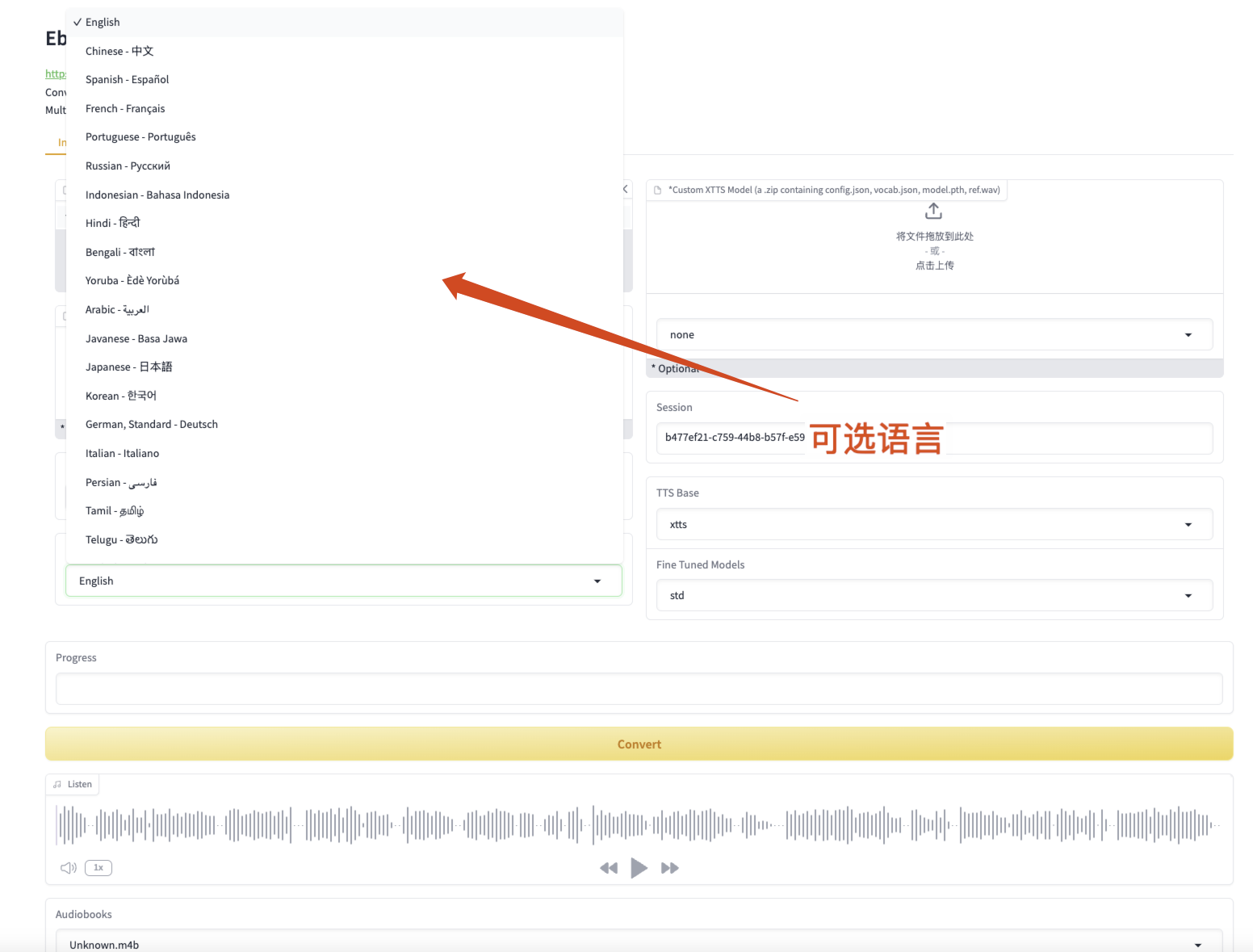
Figure 3 Langues sélectionnables
Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.