Command Palette
Search for a command to run...
Tutoriel De Démarrage vLLM : Un Guide Étape Par Étape Pour Les Débutants
Date
Taille
5.07 MB
Balises
Licence
Other
GitHub
URL du document

Table des matières
- 1. Introduction au tutoriel
- 2. Installation de vLLM
- 3. Pour commencer
- 4. Lancement du serveur vLLM
- 5. Envoi de requêtes
1. Introduction au tutoriel
vLLM (Virtual Large Language Model) est un framework conçu spécifiquement pour accélérer le raisonnement des grands modèles de langage. Il a attiré une attention considérable dans le monde entier en raison de son excellente efficacité de raisonnement et de ses capacités d’optimisation des ressources. En 2023, une équipe de recherche de l'Université de Californie à Berkeley (UC Berkeley) a proposé un algorithme d'attention révolutionnaire, PagedAttention, qui peut gérer efficacement les clés et les valeurs d'attention. Sur cette base, les chercheurs ont construit un moteur de service LLM distribué à haut débit vLLM, ont obtenu une perte quasi nulle de mémoire cache KV et ont résolu le problème du goulot d'étranglement de la gestion de la mémoire dans le raisonnement du modèle de langage volumineux. Comparé aux transformateurs Hugging Face, il atteint un débit 24 fois supérieur et cette amélioration des performances ne nécessite aucune modification de l'architecture du modèle. Les résultats pertinents de l'article sontGestion efficace de la mémoire pour la diffusion de modèles de langage volumineux avec PagedAttention".
Dans ce tutoriel, nous vous montrerons étape par étape comment configurer et exécuter vLLM, en fournissant un guide de démarrage complet de l'installation au démarrage.
Ce tutoriel utilisera Qwen3-0.6B À des fins de démonstration, des modèles avec d’autres quantités de paramètres sont également fournis.
2. Installer vLLM
Cette plateforme a été complétée vllm==0.8.5 Installation. Si vous opérez sur une plateforme, veuillez ignorer cette étape. Si vous effectuez un déploiement local, suivez les étapes ci-dessous pour l'installer.
L'installation de vLLM est très simple :
pip install vllmNotez que vLLM est compilé avec CUDA 12.4, vous devez donc vous assurer que votre machine exécute cette version de CUDA.
Pour vérifier la version CUDA, exécutez :
nvcc --versionSi votre version de CUDA n'est pas 12.4, vous pouvez soit installer une version de vLLM compatible avec votre version actuelle de CUDA (voir les instructions d'installation pour plus d'informations), soit installer CUDA 12.4.
3. Commencez à utiliser
3.1 Préparation du modèle
Méthode 1 : Utiliser le modèle public de la plateforme
Tout d’abord, nous pouvons vérifier si le modèle public de la plateforme existe déjà. Si le modèle a été téléchargé dans un référentiel public, vous pouvez l'utiliser directement. Si vous ne le trouvez pas, veuillez vous référer à la méthode 2 pour le télécharger.
Par exemple, la plateforme a stocké Qwen3 Modèle de série. Voici les étapes pour lier le modèle (ce tutoriel a déjà lié ce modèle).
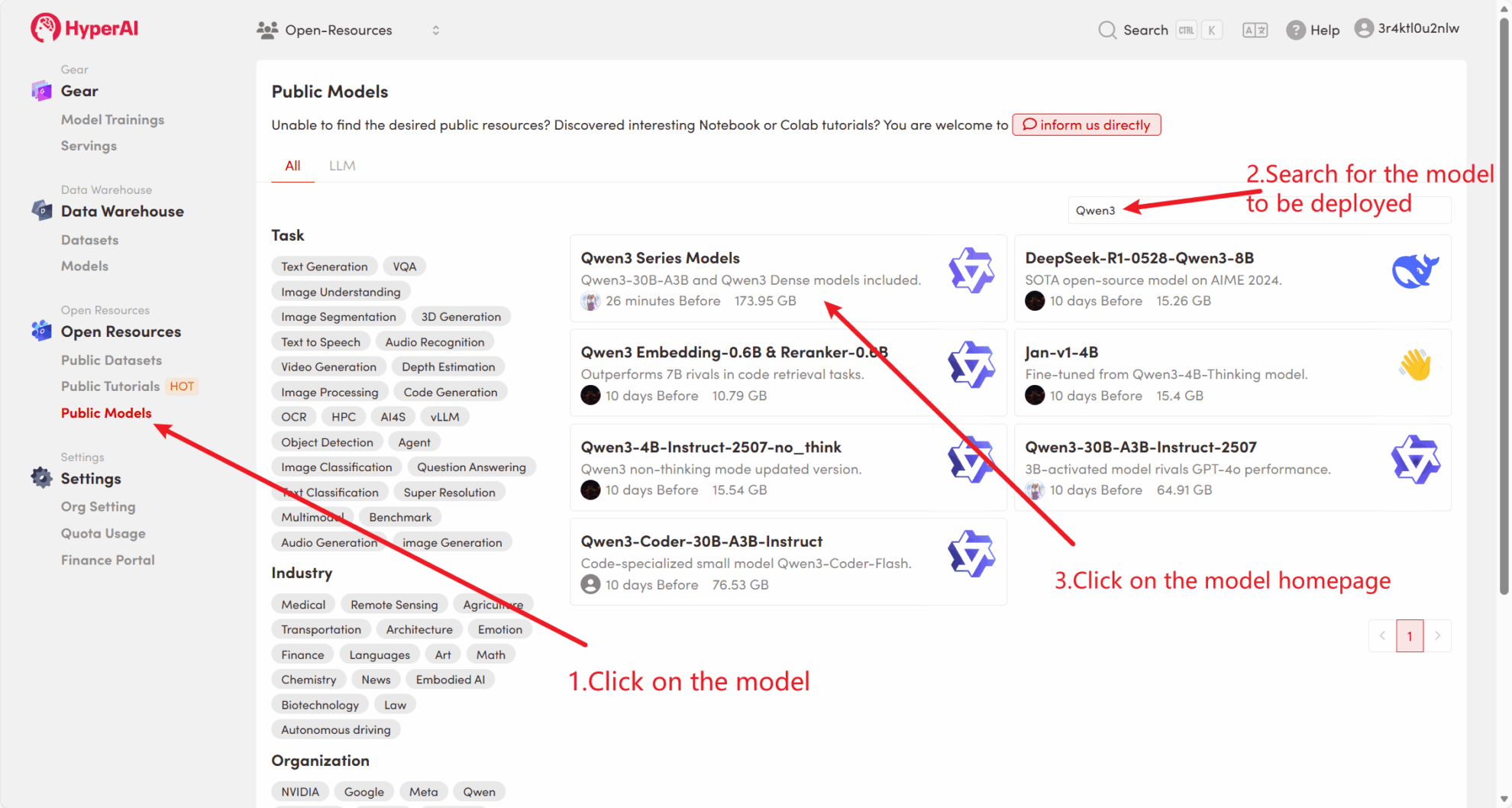
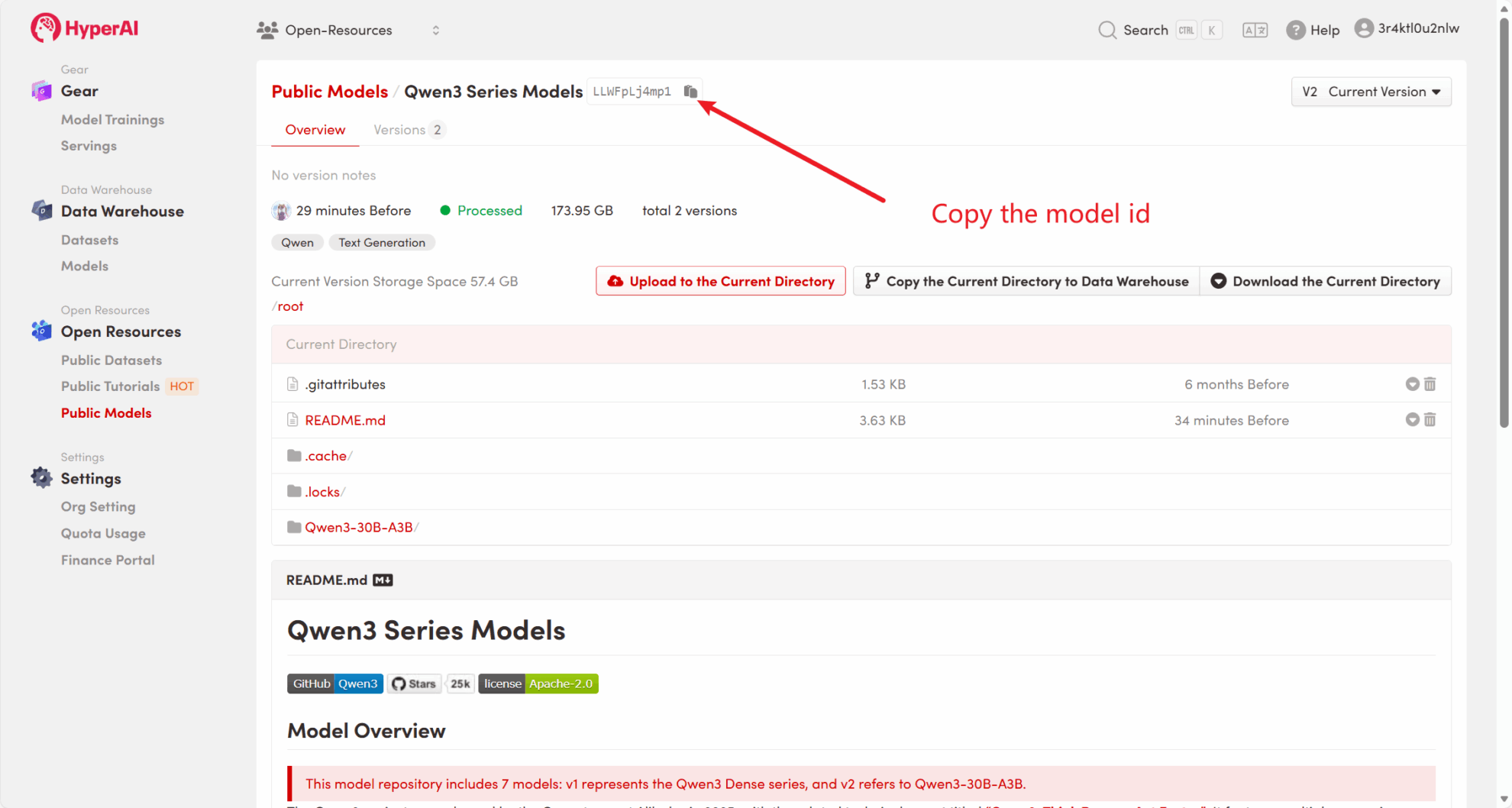
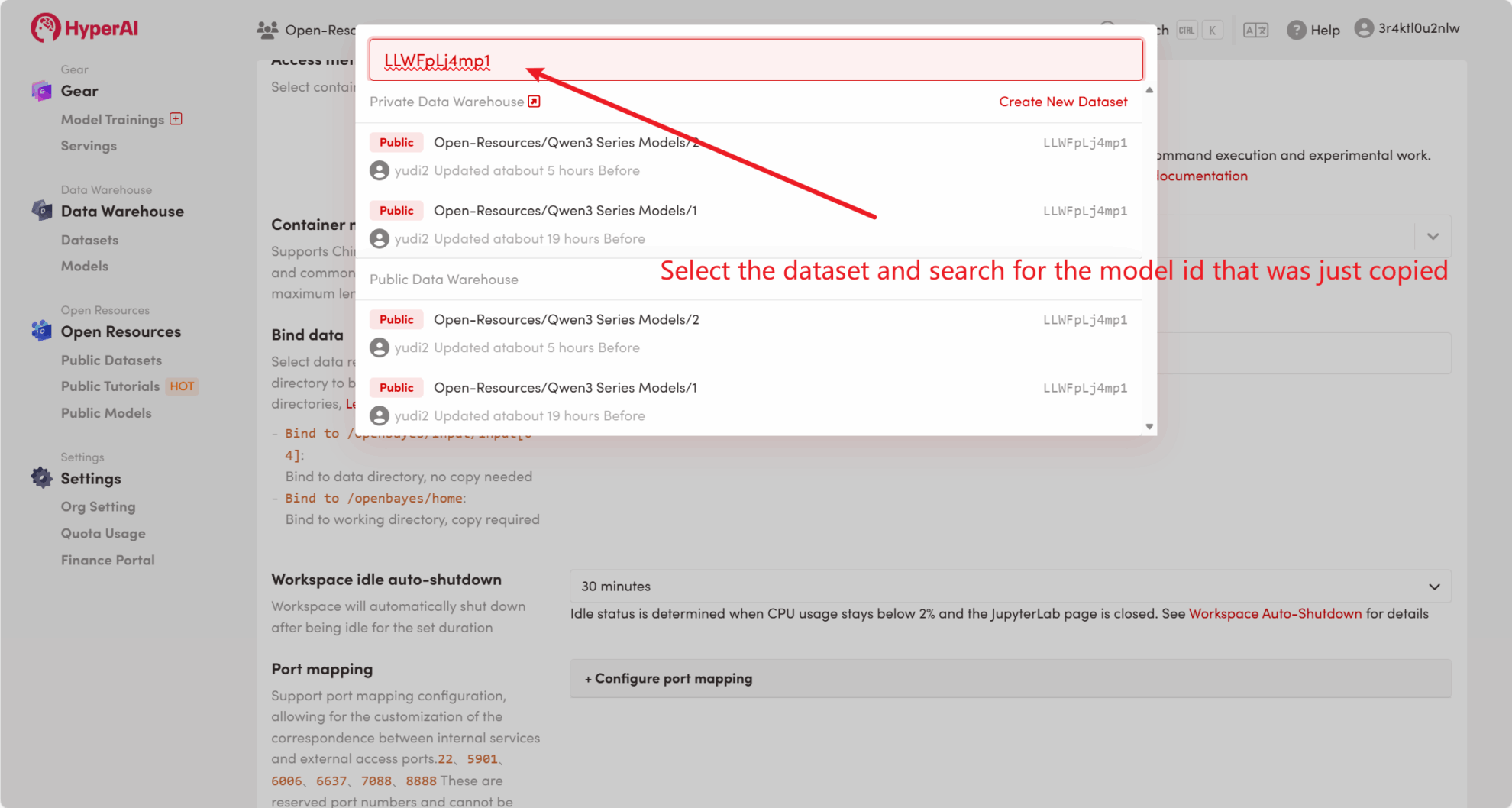
Méthode 2 : Téléchargez le fichier depuis HuggingFace ou contactez le service client pour obtenir de l’aide concernant le téléchargement sur la plateforme.
La plupart des modèles grand public peuvent être trouvés sur HuggingFace. Pour une liste des modèles pris en charge par vLLM, veuillez vous référer à la documentation officielle : modèles pris en charge par vllm .
Veuillez suivre les étapes ci-dessous pour télécharger le modèle à l'aide de huggingface-cli :
huggingface-cli download --resume-download Qwen/Qwen3-0.6B --local-dir ./input03.2 Raisonnement hors ligne
En tant que projet open source, vLLM peut effectuer un raisonnement LLM via son API Python. Voici un exemple simple. Veuillez enregistrer le code sous offline_infer.py document:
from vllm import LLM, SamplingParams
# 输入几个问题
prompts = [
« Bonjour, qui êtes-vous ? », « Où se trouve la capitale de la France ? »,]
# 设置初始化采样参数
sampling_params = SamplingParams(temperature=0.8, top_p=0.95, max_tokens=100)
# 加载模型,确保路径正确
llm = LLM(model="/input1/Qwen3-0.6B/", trust_remote_code=True, max_model_len=4096)
# 展示输出结果
outputs = llm.generate(prompts, sampling_params)
# 打印输出结果
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
Ensuite, exécutez le script :
python offline_infer.pyUne fois le modèle chargé, vous verrez la sortie suivante :

4. Démarrez le serveur vLLM
Pour fournir des services en ligne à l’aide de vLLM, vous pouvez lancer un serveur compatible avec l’API OpenAI. Après un lancement réussi, vous pouvez utiliser le modèle déployé comme vous le feriez avec GPT.
4.1 Principaux paramètres de réglage
Voici quelques paramètres courants lors du démarrage d'un serveur vLLM :
--model: Nom du modèle HuggingFace ou chemin à utiliser (par défaut :facebook/opt-125m).--hostet--port: Spécifiez l'adresse du serveur et le port.--dtype: Le type de précision des poids et des activations du modèle. Valeurs possibles :auto,half,float16,bfloat16,float,float32. valeur par défaut :auto.--tokenizer: Nom ou chemin du tokenizer HuggingFace à utiliser. Si non spécifié, le nom ou le chemin du modèle est utilisé par défaut.--max-num-seqs: Nombre maximal de séquences par itération.--max-model-len: La longueur du contexte du modèle. La valeur par défaut est automatiquement obtenue à partir de la configuration du modèle.--tensor-parallel-size,-tp: Nombre de copies parallèles du tenseur (pour GPU). valeur par défaut :1.--distributed-executor-backend=ray: Spécifie le backend du service distribué. Valeurs possibles :ray,mp. valeur par défaut :ray(Lorsque vous utilisez plusieurs GPU, il est automatiquement réglé surray).
4.2 Démarrer la ligne de commande
Créez un serveur compatible avec l'interface API OpenAI. Exécutez la commande suivante pour démarrer le serveur :
python3 -m vllm.entrypoints.openai.api_server --model /input1/Qwen3-0.6B/ --host 0.0.0.0 --port 8080 --dtype auto --max-num-seqs 32 --max-model-len 4096 --tensor-parallel-size 1 --trust-remote-codeUne fois le démarrage réussi, vous verrez un résultat similaire à celui-ci :

vLLM peut désormais être déployé en tant que serveur implémentant le protocole API OpenAI, par défaut il sera disponible dans http://localhost:8080 Démarrer le serveur. Tu peux --host et --port Le paramètre spécifie une adresse différente.
5. Faire une demande
L'adresse API démarrée dans ce tutoriel est http://localhost:8080, vous pouvez utiliser l'API en visitant cette adresse. localhost Fait référence à la plateforme elle-même,8080 Il s'agit du numéro de port sur lequel le service API écoute.
Sur le côté droit de l'espace de travail, l'adresse API sera transmise au service local 8080 et les demandes peuvent être effectuées via l'hôte réel, comme illustré dans la figure suivante :
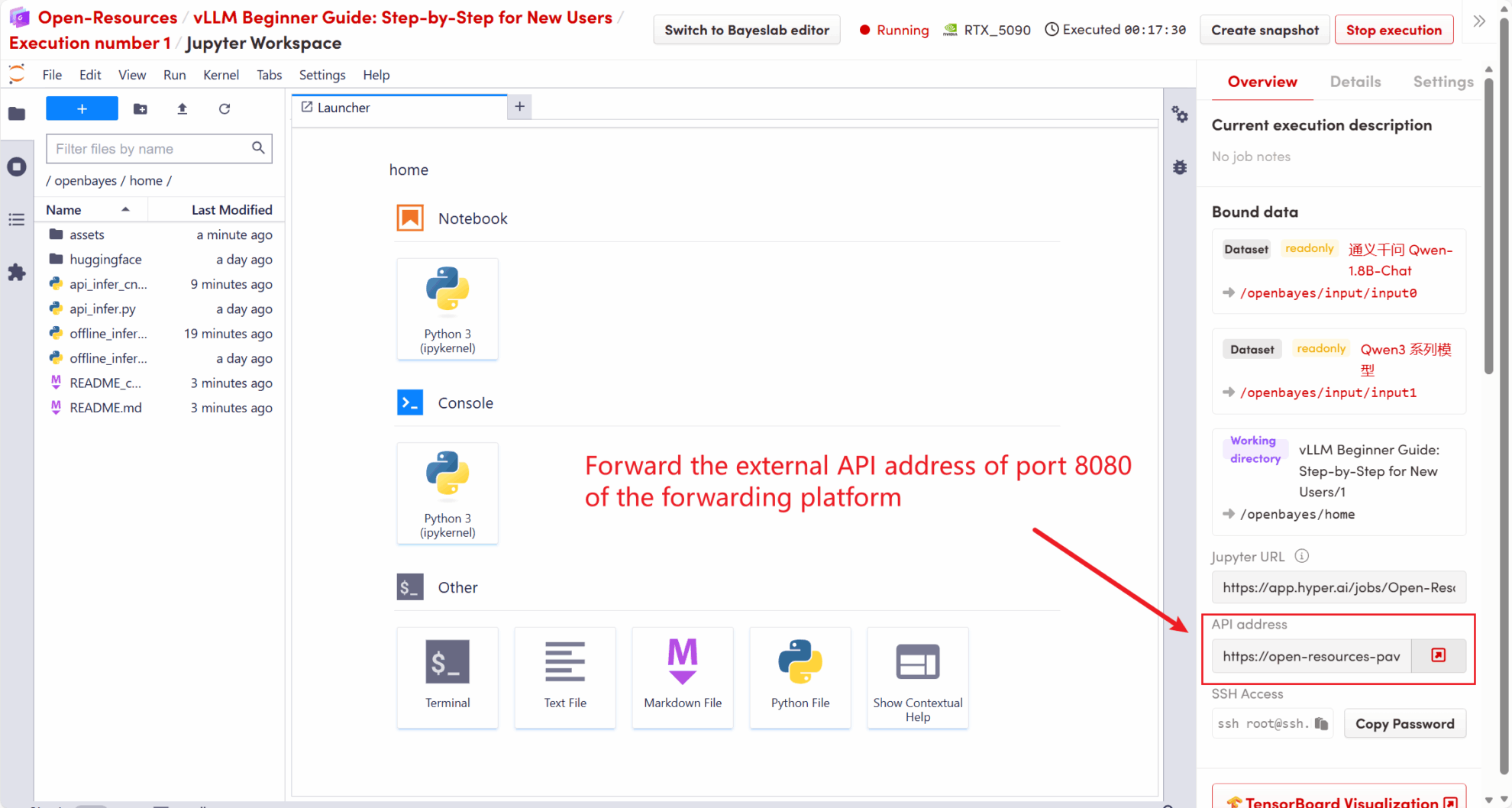
5.1 Utilisation du client OpenAI
Après avoir démarré le service vLLM à l’étape 4, vous pouvez appeler l’API via le client OpenAI. Voici un exemple simple :
# 注意:请先安装 openai
# pip install openai
from openai import OpenAI
# 设置 OpenAI API 密钥和 API 基础地址
openai_api_key = "EMPTY" # 请替换为您的 API 密钥
openai_api_base = "http://localhost:8080/v1" # 本地服务地址
client = OpenAI(api_key=openai_api_key, base_url=openai_api_base)
models = client.models.list()
model = models.data[0].id
prompt = "Describe the autumn in Beijing"
# Completion API 调用
completion
= client.completions.create(model=model, prompt=prompt)
res = completion.choices[0].text.strip()
print(f"Prompt: {prompt}\nResponse: {res}")Exécutez la commande :
python api_infer.pyVous verrez un résultat similaire à ce qui suit :

5.2 Utilisation de la requête de commande Curl
Vous pouvez également envoyer la demande directement en utilisant la commande suivante. Lors de l'accès à la plateforme, entrez la commande suivante :
curl http://localhost:8080/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "/input1/Qwen3-0.6B/",
"prompt": "Describe the autumn in Beijing", "max_tokens": 512
}'Vous obtiendrez une réponse comme celle-ci :

Si vous utilisez la plateforme OpenBayes, entrez la commande suivante :
curl https://hyperai-tutorials-8tozg9y9ref9.gear-c1.openbayes.net/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "/input1/Qwen3-0.6B/",
"prompt": "Describe the autumn in Beijing", "max_tokens": 128
}'Le résultat de la réponse est le suivant :

Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.