Command Palette
Search for a command to run...
GLM-4-Voice Modèle De Conversation chinois-anglais De Bout En Bout
Date
Taille
1.91 GB
1. Introduction au tutoriel
GLM-4-Voice est un modèle vocal de bout en bout lancé par Zhipu AI en 2024. GLM-4-Voice peut comprendre et générer directement des discours chinois et anglais, mener des conversations vocales en temps réel et peut suivre les instructions de l'utilisateur pour modifier l'émotion, l'intonation, la vitesse de parole, le dialecte et d'autres attributs du discours.
Cette démo de tutoriel contient deux implémentations fonctionnelles du modèle : « Conversation vocale » et « Conversation textuelle ».
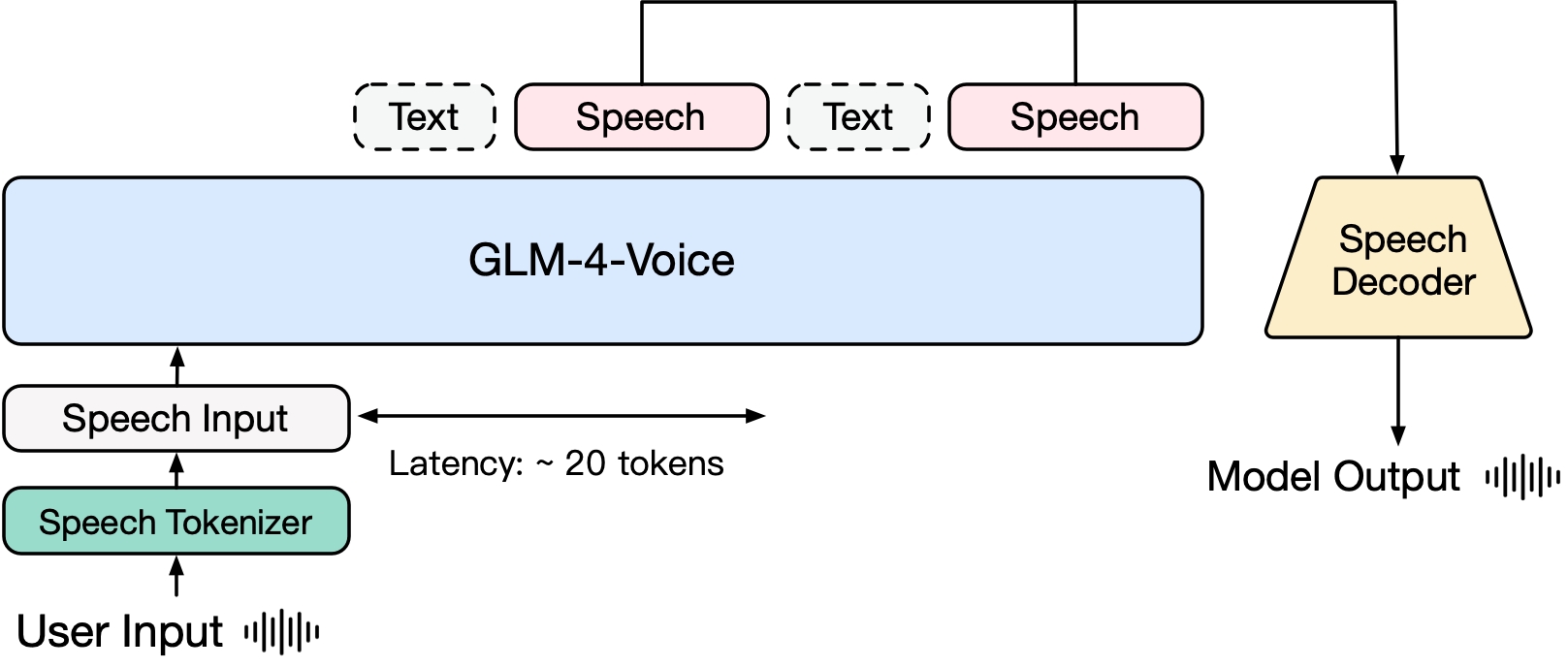
GLM-4-Voice se compose de trois parties :
- GLM-4-Voice-Tokenizer : convertit l'entrée vocale continue en jetons discrets en ajoutant une quantification vectorielle à la partie encodeur de Whisper et une formation supervisée sur les données ASR. En moyenne, seulement 12,5 jetons discrets sont nécessaires pour représenter chaque seconde d'audio.
- GLM-4-Voice-Decoder : un décodeur vocal qui prend en charge le raisonnement en continu et est formé sur la base de la structure du modèle Flow Matching de CosyVoice, convertissant des jetons vocaux discrets en sortie vocale continue. Seuls 10 jetons vocaux sont nécessaires pour commencer à générer, réduisant ainsi la latence de conversation de bout en bout.
- GLM-4-Voice-9B : pré-entraîne et aligne la modalité vocale basée sur GLM-4-9B, afin qu'elle puisse comprendre et générer des jetons vocaux discrets.
En termes de pré-formation, afin de surmonter les deux difficultés de l'intelligence du modèle et de l'expressivité synthétique dans la modalité vocale, l'équipe de recherche a découplé la tâche Speech2Speech en deux tâches : « faire des réponses textuelles basées sur l'audio de l'utilisateur » et « synthétiser la parole de réponse basée sur les réponses textuelles et la voix de l'utilisateur », et a conçu deux objectifs de pré-formation, synthétisant des données entrelacées parole-texte basées sur des données de pré-formation textuelle et des données audio non supervisées pour s'adapter à ces deux formes de tâches. GLM-4-Voice-9B est basé sur le modèle de base du GLM-4-9B. Il a été pré-entraîné avec des millions d'heures d'audio et des centaines de milliards de jetons de données entrelacées audio-texte, et possède de solides capacités de compréhension et de modélisation audio.
En termes d'alignement, afin de prendre en charge des conversations vocales de haute qualité, l'équipe de recherche a conçu une architecture de réflexion en streaming : en fonction de la voix de l'utilisateur, GLM-4-Voice peut diffuser et diffuser le contenu des modes texte et vocal en alternance. Le mode vocal utilise le texte comme référence pour garantir la haute qualité du contenu de la réponse et apporte les modifications sonores correspondantes en fonction des exigences de commande vocale de l'utilisateur. Il a toujours la capacité de modélisation de bout en bout tout en conservant au maximum le QI du modèle de langage et présente une faible latence. Il suffit de produire au minimum 20 jetons pour synthétiser la parole.
2. Étapes de l'opération
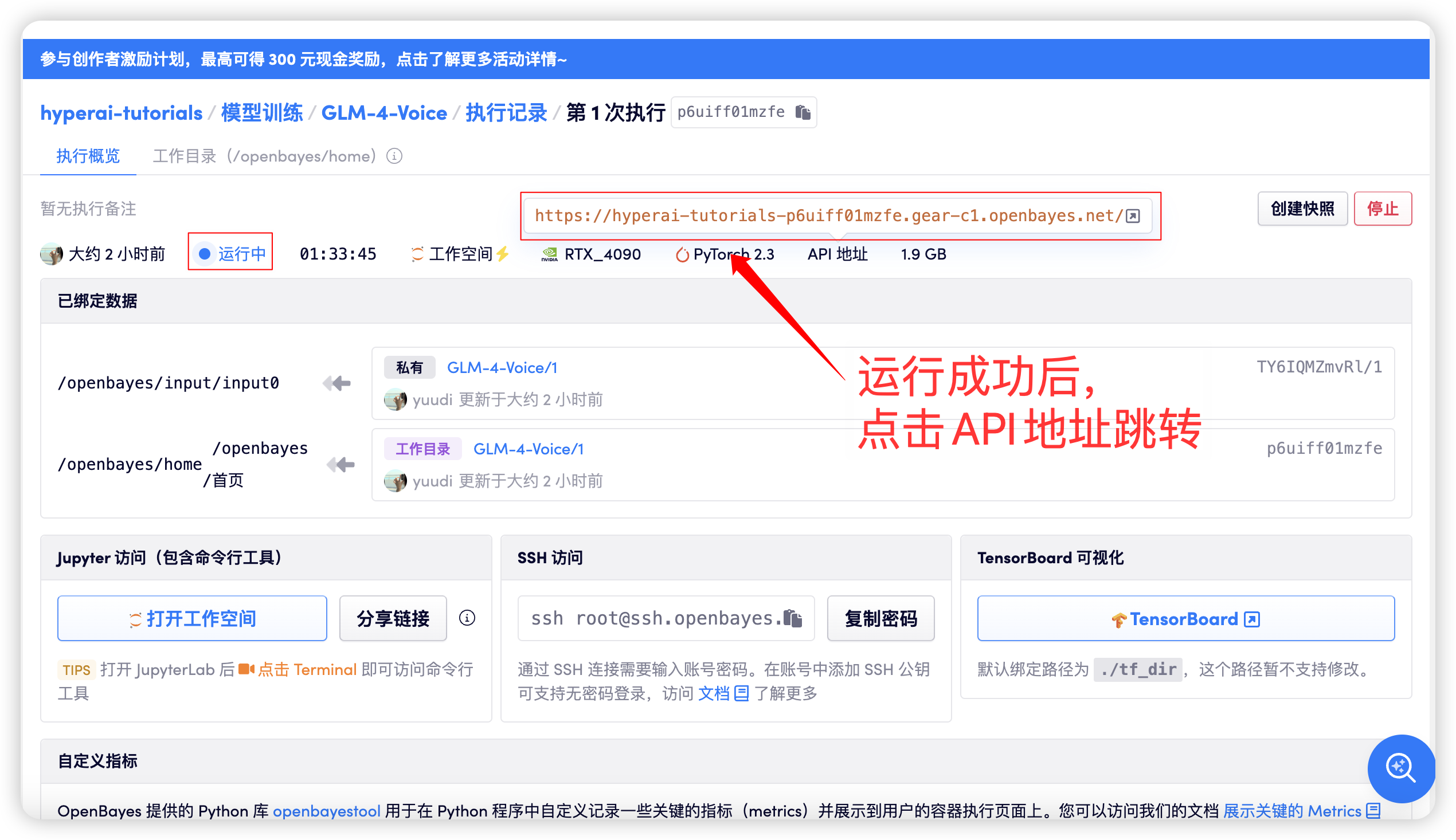
Après avoir démarré le conteneur, cliquez sur l'adresse API pour accéder à l'interface Web
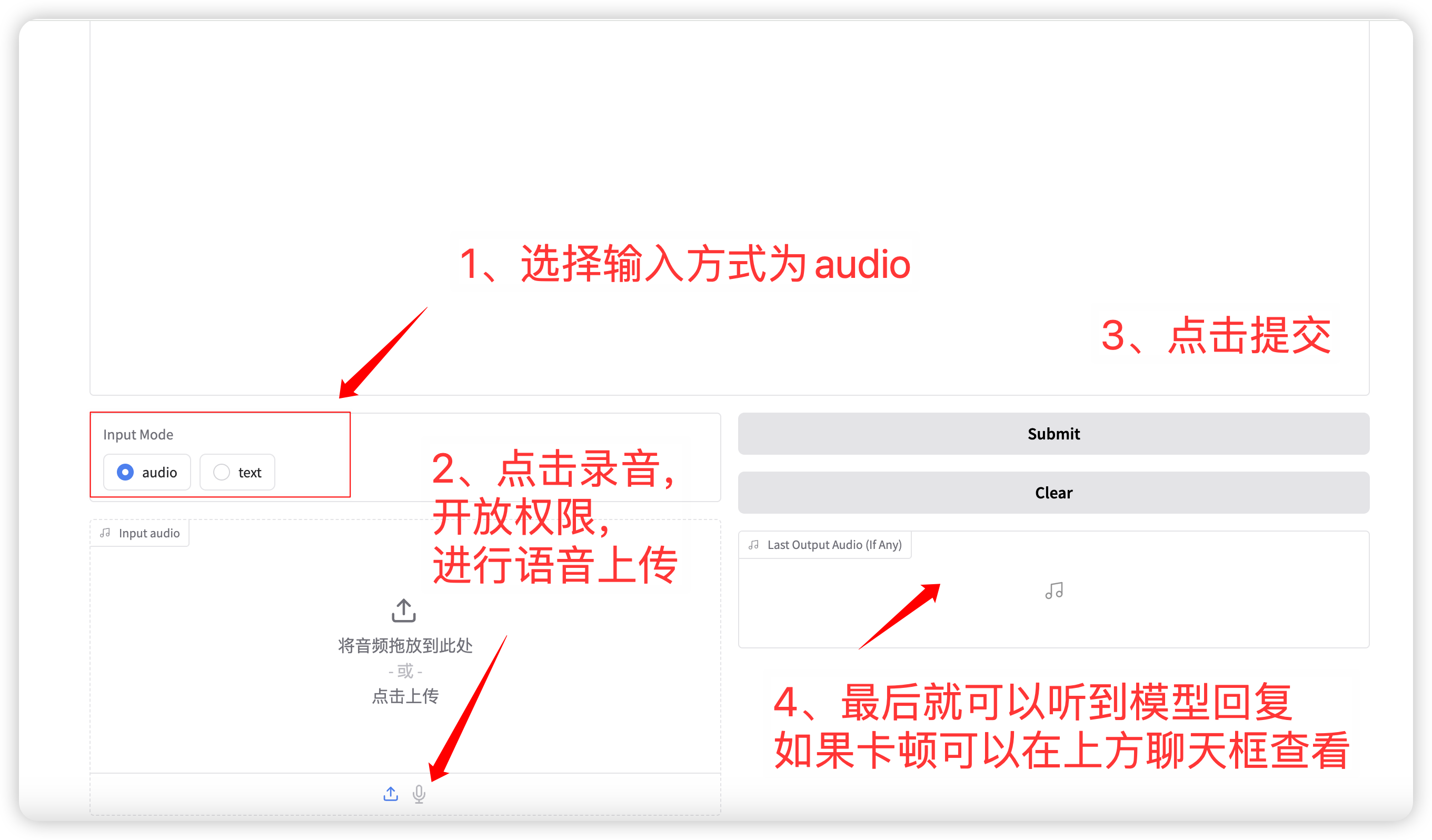
1. Dialogue vocal
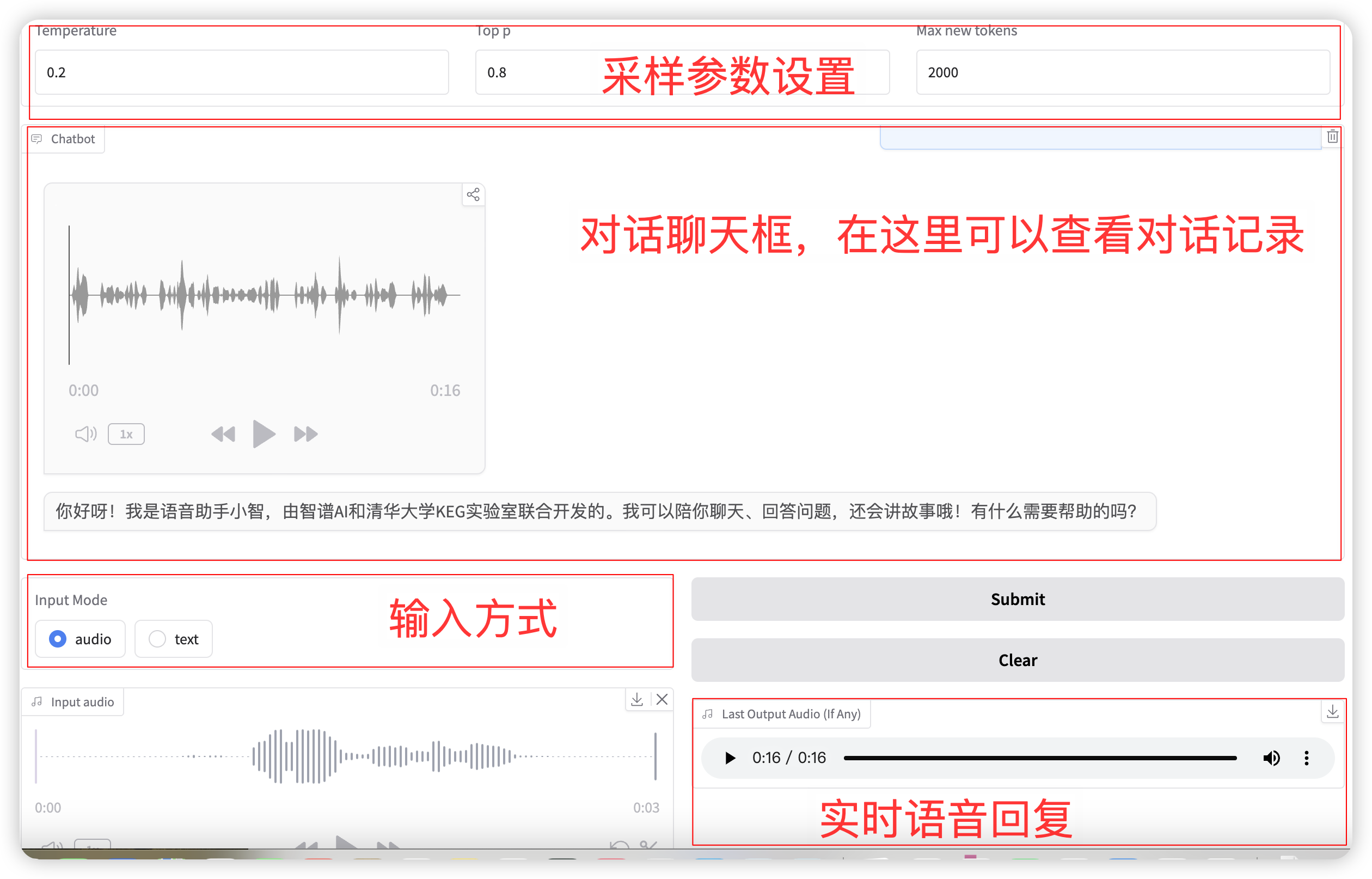
Sélection du mode d'entrée audio Fonction, cliquez pour enregistrer ou télécharger un fichier vocal. Les paramètres d'échantillonnage pertinents sont :
- Température : Plage 0-1, plus la température est élevée, plus le caractère aléatoire de la génération est grand !
- Top p : utilisé pour spécifier que seules les p premières options avec la probabilité la plus élevée seront prises en compte lors de la sélection du mot suivant pendant le processus de génération. Cela permet de maintenir la diversité lors de la génération de texte et évite de toujours sélectionner les résultats de prédiction avec la probabilité la plus élevée, rendant le texte généré plus riche et plus diversifié.
- Nombre maximal de nouveaux jetons : le nombre maximal de jetons générés.
Une fois la configuration terminée, le modèle émettra de la voix et du texte en temps réel, mais cela peut être intermittent en raison de la latence du réseau. Vous pouvez écouter la voix dans la boîte de discussion. La mise en page générale de la page est la suivante :
语音对话流程
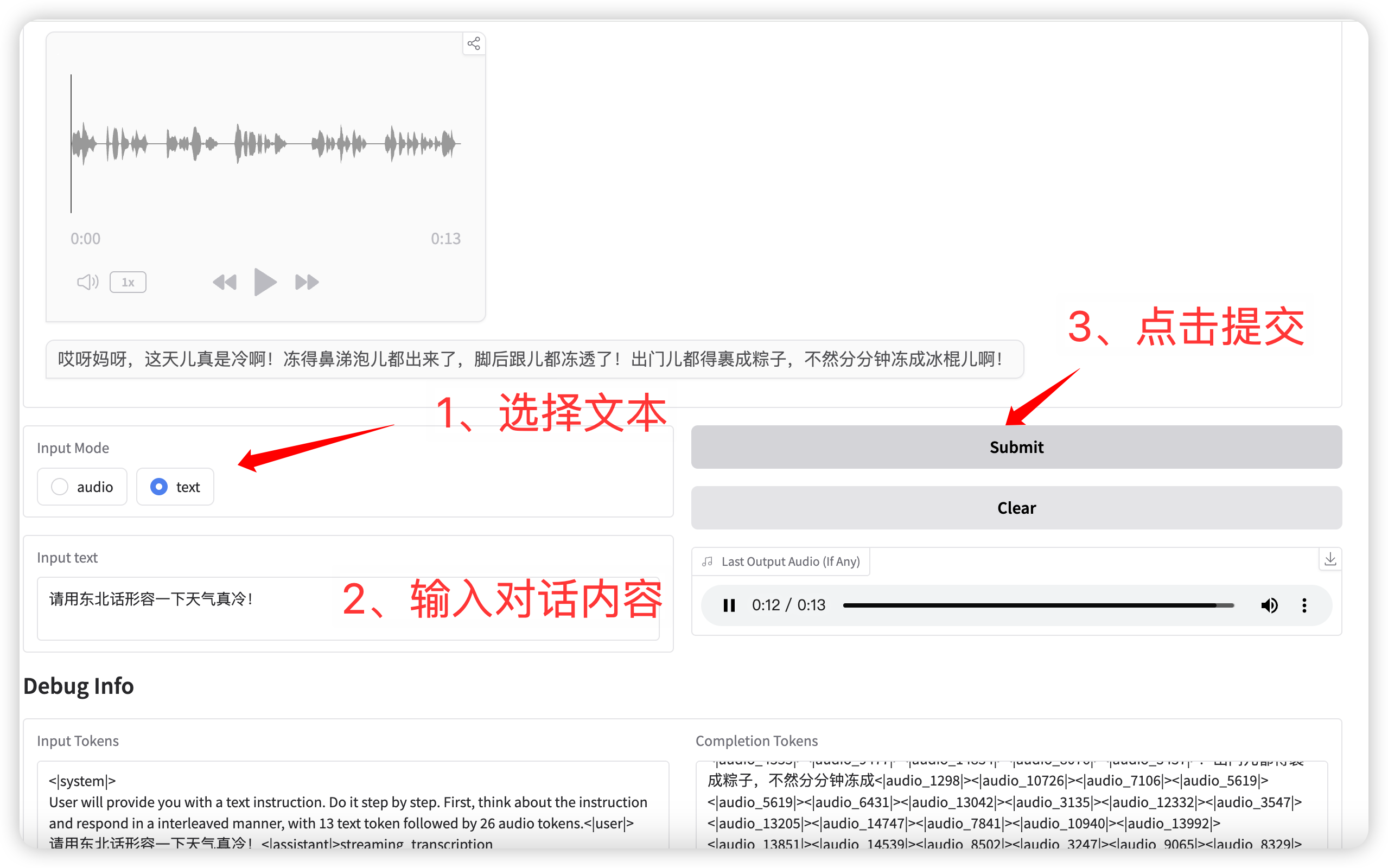
2. Conversation textuelle
输入模式选择 **text** 功能,输入对话文本。
点击提交后,模型同时输出文本和语音。
语音对话(输入为文本)
Échange et discussion
🖌️ Si vous voyez un projet de haute qualité, veuillez laisser un message en arrière-plan pour le recommander ! De plus, nous avons également créé un groupe d’échange de tutoriels. Bienvenue aux amis pour scanner le code QR et commenter [Tutoriel SD] pour rejoindre le groupe pour discuter de divers problèmes techniques et partager les résultats de l'application↓

Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.