Command Palette
Search for a command to run...
Fish Speech v1.4 Clonage Vocal : Démonstration De l'outil De Synthèse Vocale
Introduction au tutoriel

Les principales fonctionnalités de Fish Speech incluent la synthèse vocale, la prise en charge multilingue, la personnalisation de la voix, une bibliothèque sonore de haute qualité et une source ouverte gratuite. Il convient à une variété de scénarios, tels que la création de contenu, l'éducation, le service client, les outils auxiliaires, etc. Le modèle prend également en charge l'intégration d'API et le réglage fin du modèle, permettant aux utilisateurs de personnaliser et d'optimiser en fonction de leurs besoins.
La dernière version 1.4 a réalisé des avancées significatives en matière de prise en charge et de performances multilingues, et la quantité de données de formation a doublé pour atteindre 700 000 heures., prend en charge 8 langues principales, dont l'anglais, le chinois, l'allemand, le japonais, le français, l'espagnol, le coréen et l'arabe. La nouvelle version introduit également le clonage vocal instantané, permettant aux utilisateurs de reproduire rapidement un style de voix spécifique, et fournit des options de déploiement flexibles et des services API.
Ce tutoriel a déployé le modèle et l'environnement. Vous pouvez effectuer directement des tâches de clonage vocal ou de synthèse vocale selon les instructions du didacticiel.
Comment courir
1. 首先克隆容器, 按步骤启动容器
2. 复制生成的 API 地址到浏览器即可使用
3. 该教程主要包含 2 个功能:文本转语音和声音克隆
3.1 文本转语音:在「Input Text」输入生成的文本,点击「Generate」即可生成结果

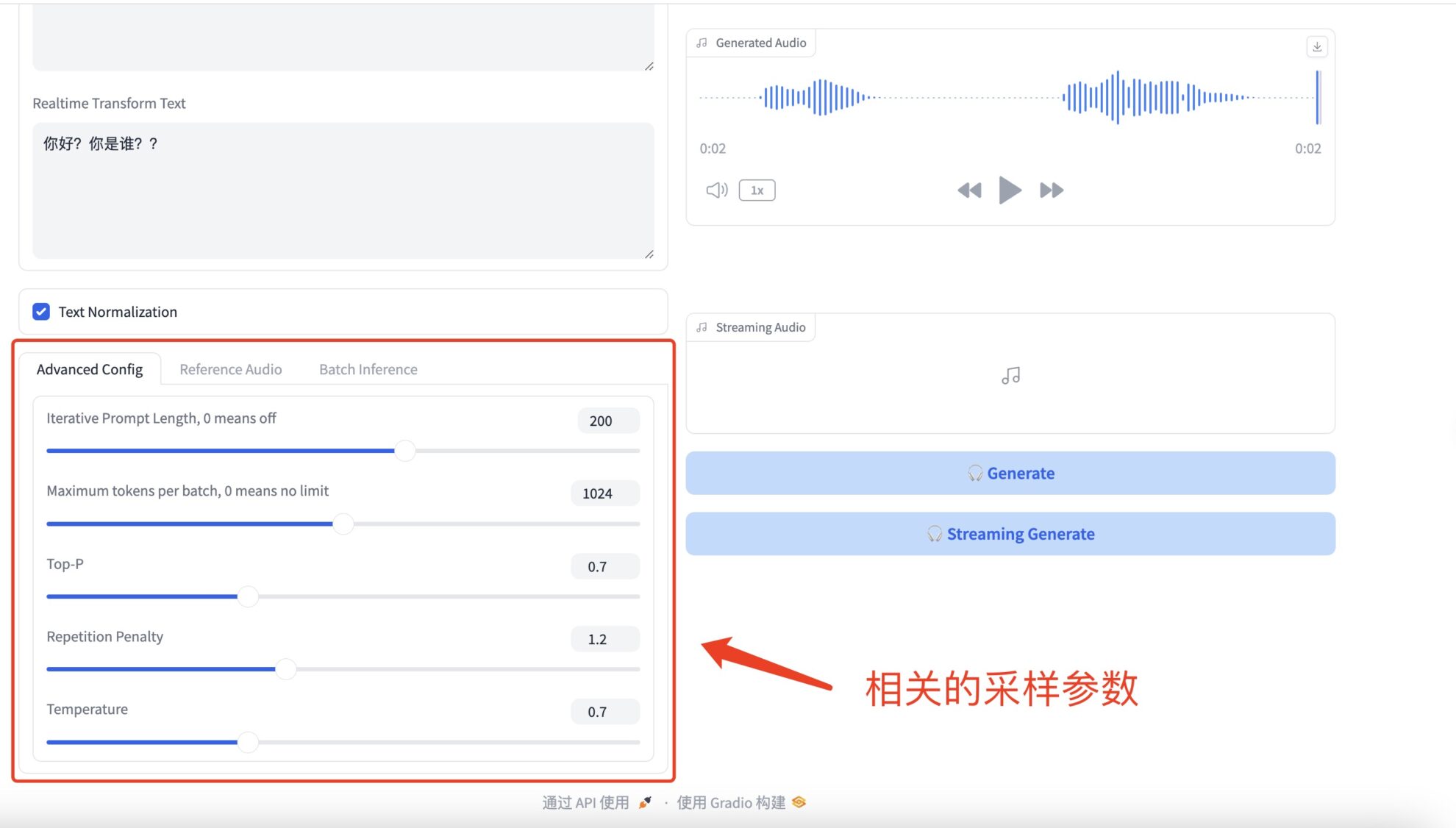
* Advanced Configs
相关的采样参数具体如下:
- Longueur de l'invite itérative : fait référence à la longueur du texte précédent que le modèle prendra en compte lors de la génération du texte. Si la valeur est différente de zéro, le modèle considérera le nombre spécifié de mots ou de jetons récents comme contexte à chaque étape de génération. Si la valeur est définie sur 0, cette fonctionnalité est désactivée et le modèle peut prendre en compte tout le contexte disponible ou décider de la longueur du contexte en fonction d'autres paramètres tels que la taille de la fenêtre du modèle.
- Le nombre maximal de jetons par lot limite le nombre maximal de jetons que le modèle peut générer dans chaque lot. Les balises font généralement référence à des mots, des signes de ponctuation, etc. Si la valeur est définie sur 0, il n'y a pas de limite et le modèle générera du texte d'une longueur aussi longue que nécessaire, ou jusqu'à ce que la limite de longueur maximale interne du modèle soit atteinte.
- Top-P (également connu sous le nom d'échantillonnage par noyau ou échantillonnage probabiliste) est une stratégie de génération de texte dans laquelle le modèle ne considère que le plus petit ensemble de mots dont la probabilité cumulée est supérieure à P lors de la génération de chaque nouveau mot. Cela signifie que le modèle sélectionnera aléatoirement le mot suivant dans cet ensemble, augmentant ainsi la diversité du texte généré tout en évitant de générer des mots non pertinents avec une faible probabilité.
- La pénalité de répétition est utilisée pour réduire le contenu répétitif dans le texte généré. Lorsque le modèle a tendance à répéter des mots ou des phrases déjà générés, l’application de ce paramètre peut réduire la probabilité de sélectionner ces mots. Cela se fait en ajustant (généralement en diminuant) les scores de probabilité des mots qui ont déjà été générés, encourageant ainsi le modèle à choisir des mots différents.
- La température contrôle le caractère aléatoire du texte généré.
3.2 声音克隆:选择「Reference Audio」并点击「Enable Reference Audio」,
上传「Reference Audio(参考音频)」,以及「Reference Text(参考文本)」,在「Input Text」输入生成的文本,点击「Generate」即可生成声音克隆结果

4. 其他参数说明
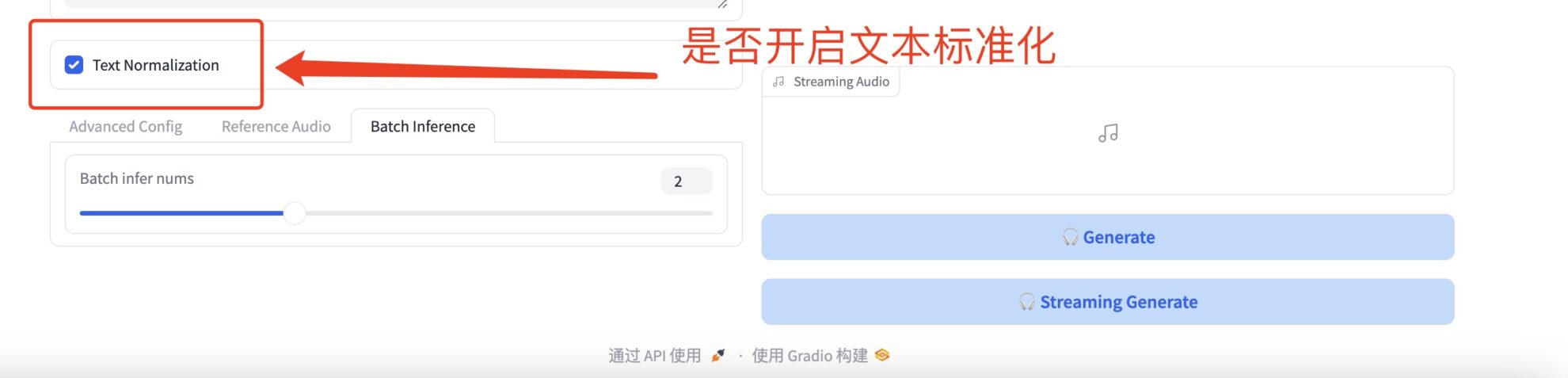
* Text Normalization
是否开启文本标准化(例如日期、固话、金钱等等)
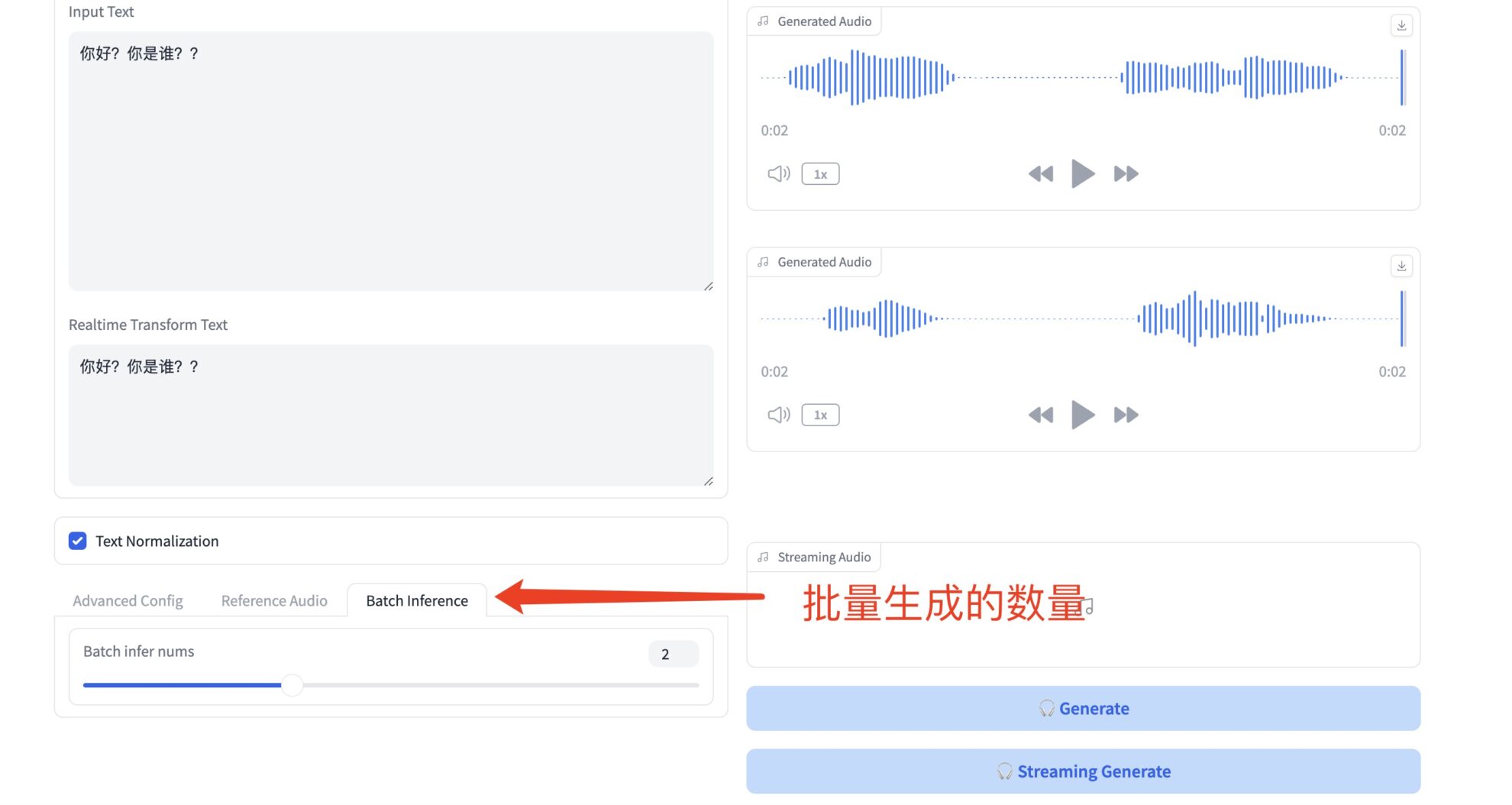
* Batch Inference
设置生成语音数量
Échange et discussion
🖌️ 如果大家看到优质项目,欢迎后台留言推荐!另外,我们还建立了教程交流群,欢迎小伙伴们扫码备注【教程交流】入群探讨各类技术问题、分享应用效果↓

Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.