Command Palette
Search for a command to run...
Démo De Modèle De Synchronisation Labiale De Haute Qualité De MuseTalk
Date
Taille
2.41 GB
Les fonctionnalités de MuseTalk incluent :
- Temps réel : capable de fonctionner dans un environnement en temps réel, atteignant une vitesse de traitement de plus de 30 images par seconde pour assurer une synchronisation labiale fluide.
- Synchronisation de haute qualité : une méthode d'inpainting d'espace latent est utilisée pour ajuster la forme de la bouche en fonction de l'audio d'entrée tout en conservant les traits du visage, obtenant ainsi une synchronisation labiale de haute qualité.
- Fonctionne avec MuseV : MuseTalk peut être utilisé avec le modèle MuseV, qui est un framework de génération vidéo capable de générer des vidéos humaines virtuelles.
- Open Source : le code de MuseTalk a été rendu open source pour faciliter les contributions de la communauté et le développement ultérieur.
MuseTalk excelle dans la génération de synchronisation labiale et peut générer une synchronisation labiale précise avec une bonne cohérence d'image, en particulier pour la génération de vidéos en personne réelle. Il présente également des avantages par rapport à d'autres produits tels que EMO, AniPortrait, Vlogger et VASA-1 de Microsoft.
Exemples d'effets
Cadre du modèle
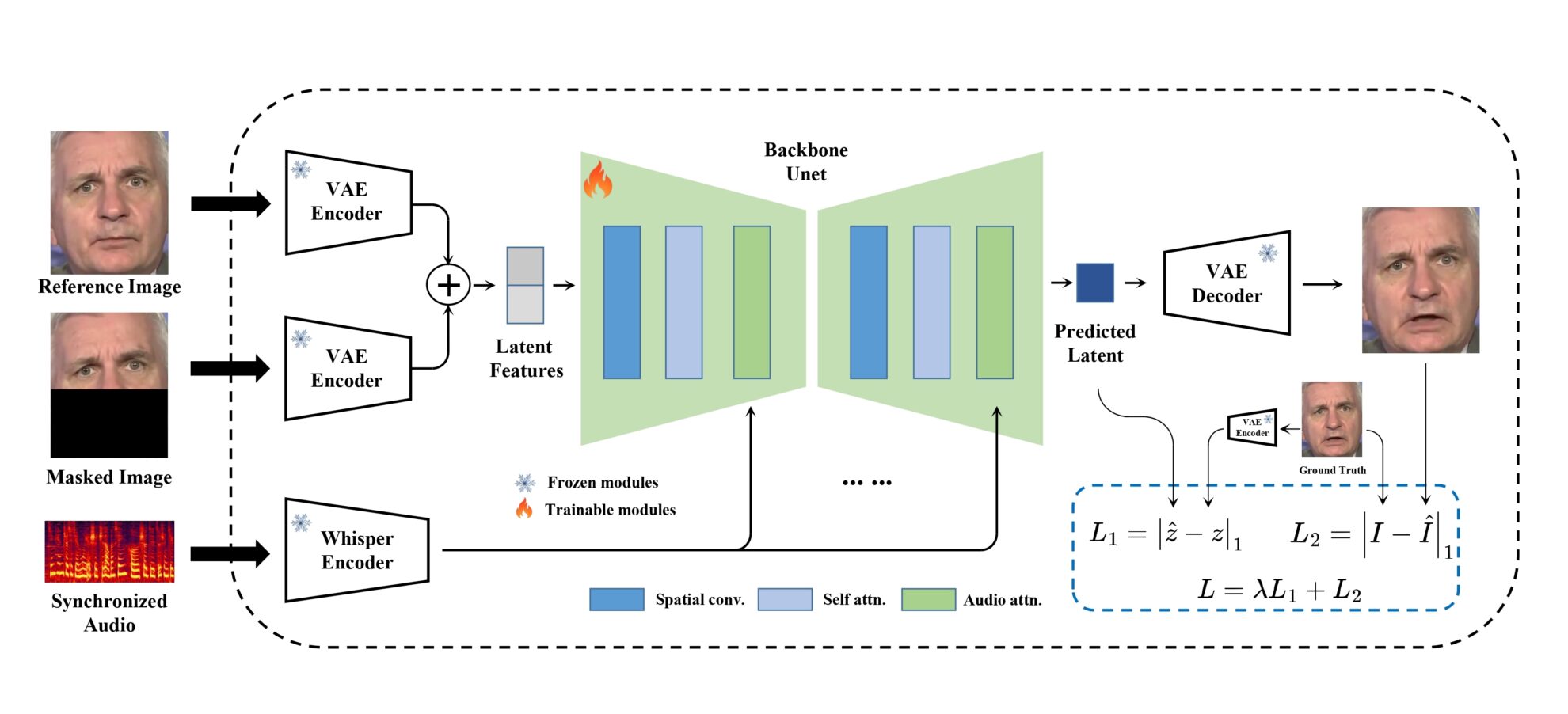
MuseTalk L'entraînement est réalisé dans un espace latent où les images sont codées par un VAE gelé. L'audio est codé par un modèle minuscule et figé. L'architecture du réseau génératif est empruntée à UNet dans stable-diffusion-v1-4, où les intégrations audio sont fusionnées avec les intégrations d'images via l'attention croisée.
Étapes de course
1. Cliquez sur « Cloner » dans le coin supérieur droit du projet, puis cliquez sur « Suivant » pour effectuer les étapes suivantes : Informations de base > Sélectionner la puissance de calcul > Réviser. Enfin, cliquez sur « Continuer » pour ouvrir ce projet dans le conteneur personnel.
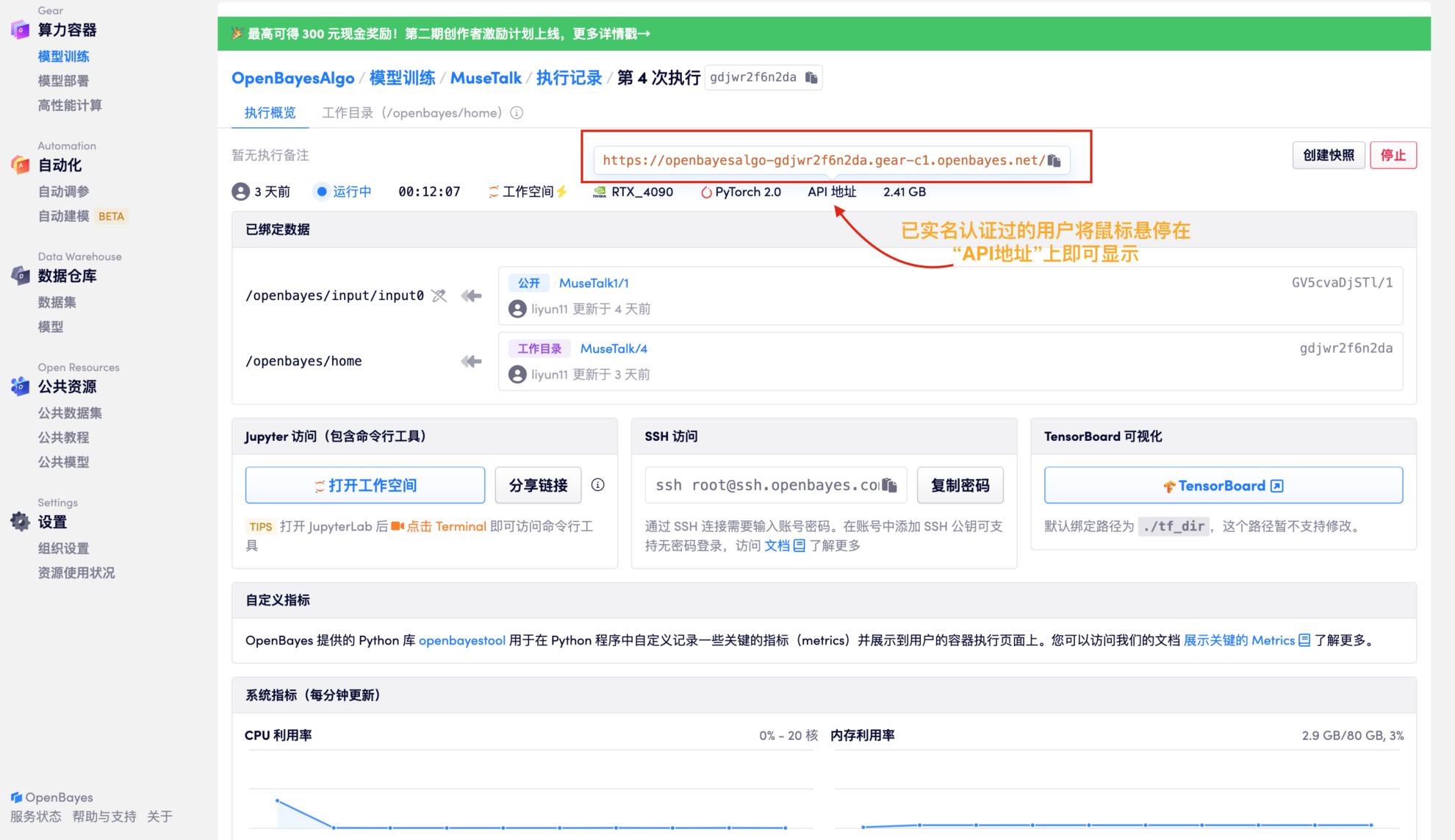
2. Une fois l'allocation des ressources terminée, copiez directement l'adresse de l'API et collez-la dans n'importe quelle URL (l'authentification par nom réel doit avoir été effectuée et il n'est pas nécessaire d'ouvrir l'espace de travail pour cette étape)
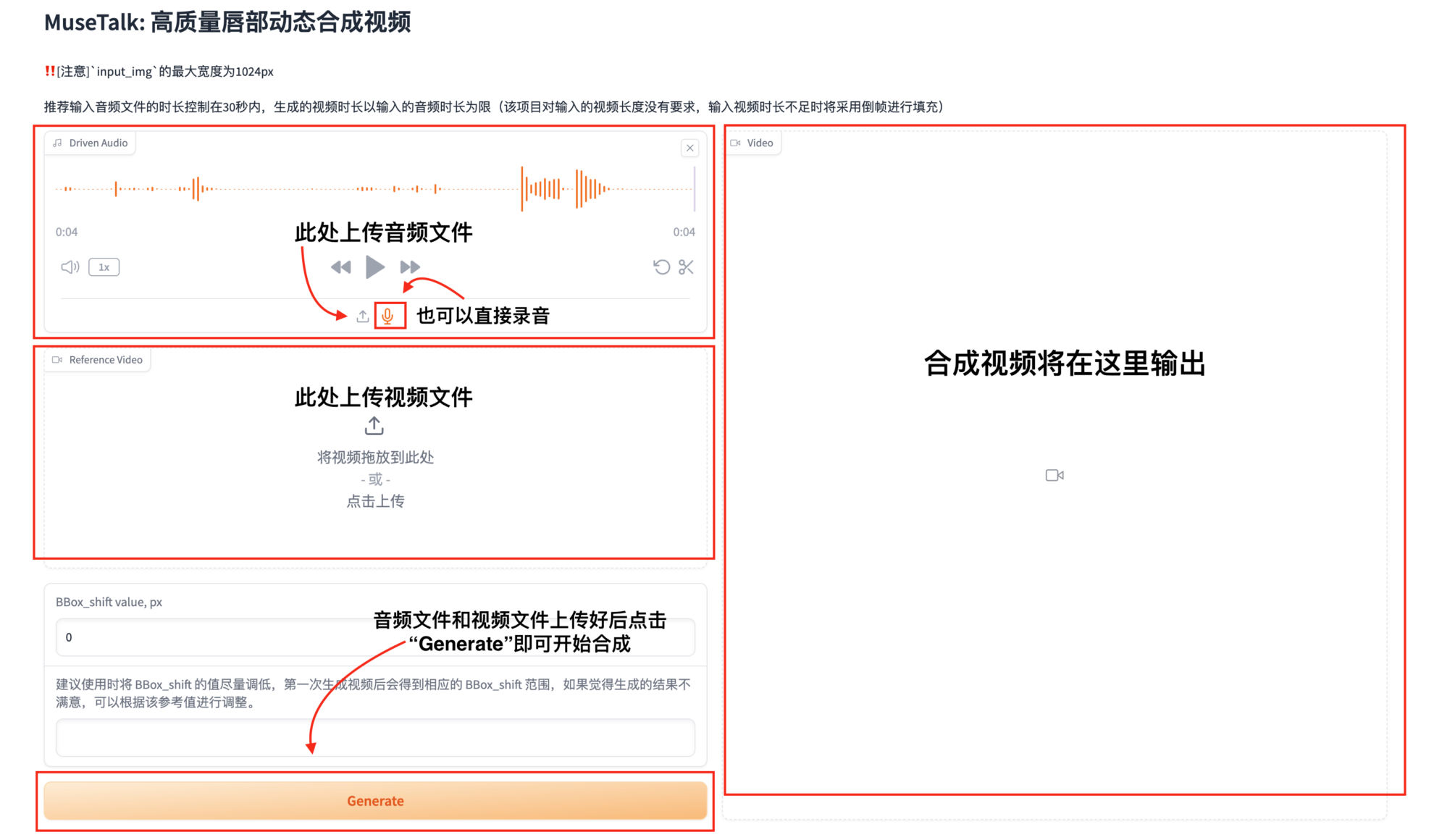
3. Téléchargez des fichiers audio et vidéo pour la synthèse
Après test : il faut environ 3 minutes pour générer un fichier audio d'une durée de 17 secondes ; il faut environ 6 minutes pour générer un fichier audio d'une durée d'environ une minute.
-|MuseTalk La forme du visage et de la bouche peut être modifiée en fonction de l'audio d'entrée. La taille de la zone du visage est de préférence de 256 x 256. en même temps MuseTalk Il prend également en charge la modification des propositions de points centraux de la région faciale, ce qui affectera considérablement les résultats de la génération.
-|Actuellement MuseTalk Prend en charge l'entrée audio dans plusieurs langues, notamment le chinois, l'anglais, le japonais, etc.
-|La durée finale de la vidéo générée est basée sur la durée audio.
Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.