Command Palette
Search for a command to run...
Déploiement En Un Clic Du Grand Modèle Chimique Puke ChemLLM-7B-chat Démo
Introduction au tutoriel
Ce tutoriel est une démonstration de déploiement en un clic de ChemLLM-7B-Chat. Il vous suffit de cloner et de démarrer le conteneur et de copier directement l'adresse API générée pour expérimenter l'inférence du modèle.
ChemLLM-7B-Chat est le premier modèle de langage open source à grande échelle pour la chimie et les sciences moléculaires, « ChemLLM », publié en 2024 par le Laboratoire d'intelligence artificielle de Shanghai (Shanghai AI Lab), et basé sur InternLM-2. Parmi les articles de recherche associés, on peut citer… ChemLLM : un modèle de langage chimique à grande échelle .
S'appuyant sur les excellentes capacités multilingues du modèle de base Shusheng·PuYu 2.0, Puke Chemistry, après une formation professionnelle en connaissances chimiques, dispose également d'excellentes capacités de traduction chinois-anglais en chimie, ce qui peut aider les chercheurs en chimie à surmonter les barrières linguistiques, à traduire avec précision les termes spéciaux de la littérature chimique et à acquérir davantage de connaissances chimiques.
En outre, l'équipe de recherche a également rendu le code source ouvert Ensemble de données ChemData700K, versions chinoise et anglaise de l'ensemble de données ChemPref-10K, ensemble de données C-MHChemet Ensemble de données de référence pour l'évaluation des capacités chimiques ChemBench4K.
La figure ci-dessous montre le résumé d'un article traduit par Pu Ke Chemistry et publié dans la revue Nature Chemistry le 16 janvier 2024.

En plus de la formation professionnelle en chimie, Puke Chemistry propose également un apprentissage des connaissances du collège et du lycée. Lorsque vous répondez à des questions de chimie au collège et au lycée, vous pouvez non seulement donner la réponse, mais également donner une explication spécifique. La figure suivante montre un exemple :

Déployer l'étape d'inférence
Ce tutoriel a déployé le modèle et l'environnement. Vous pouvez utiliser directement le grand modèle pour raisonner le dialogue selon les instructions du didacticiel. Le tutoriel spécifique est le suivant :
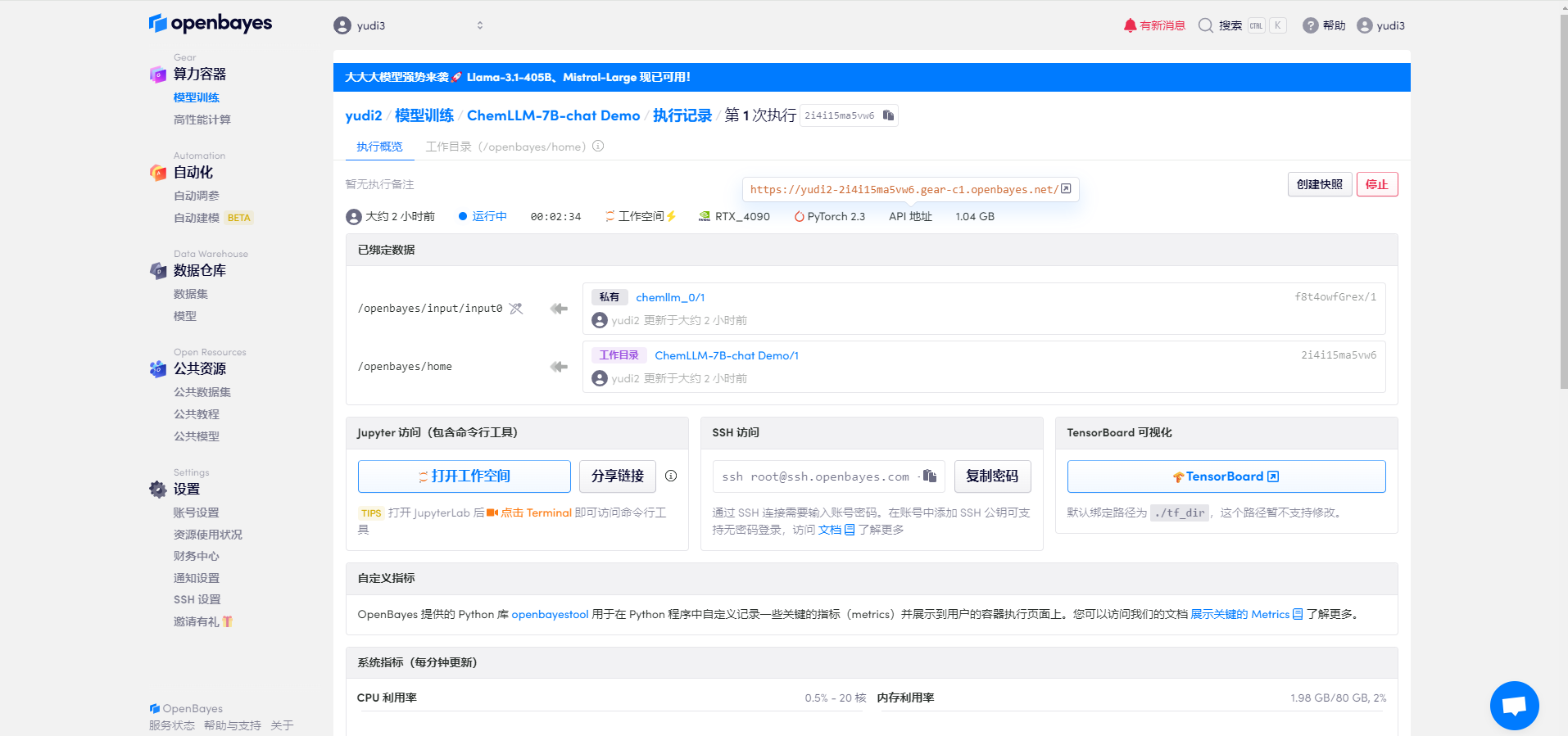
1. Configuration du modèle
Une fois les ressources configurées, démarrez le conteneur et cliquez sur le lien à l'adresse de l'API pour accéder à l'interface de démonstration (étant donné que le modèle doit être chargé une fois le conteneur démarré avec succès, il faut environ une demi-minute pour ouvrir la page Web)
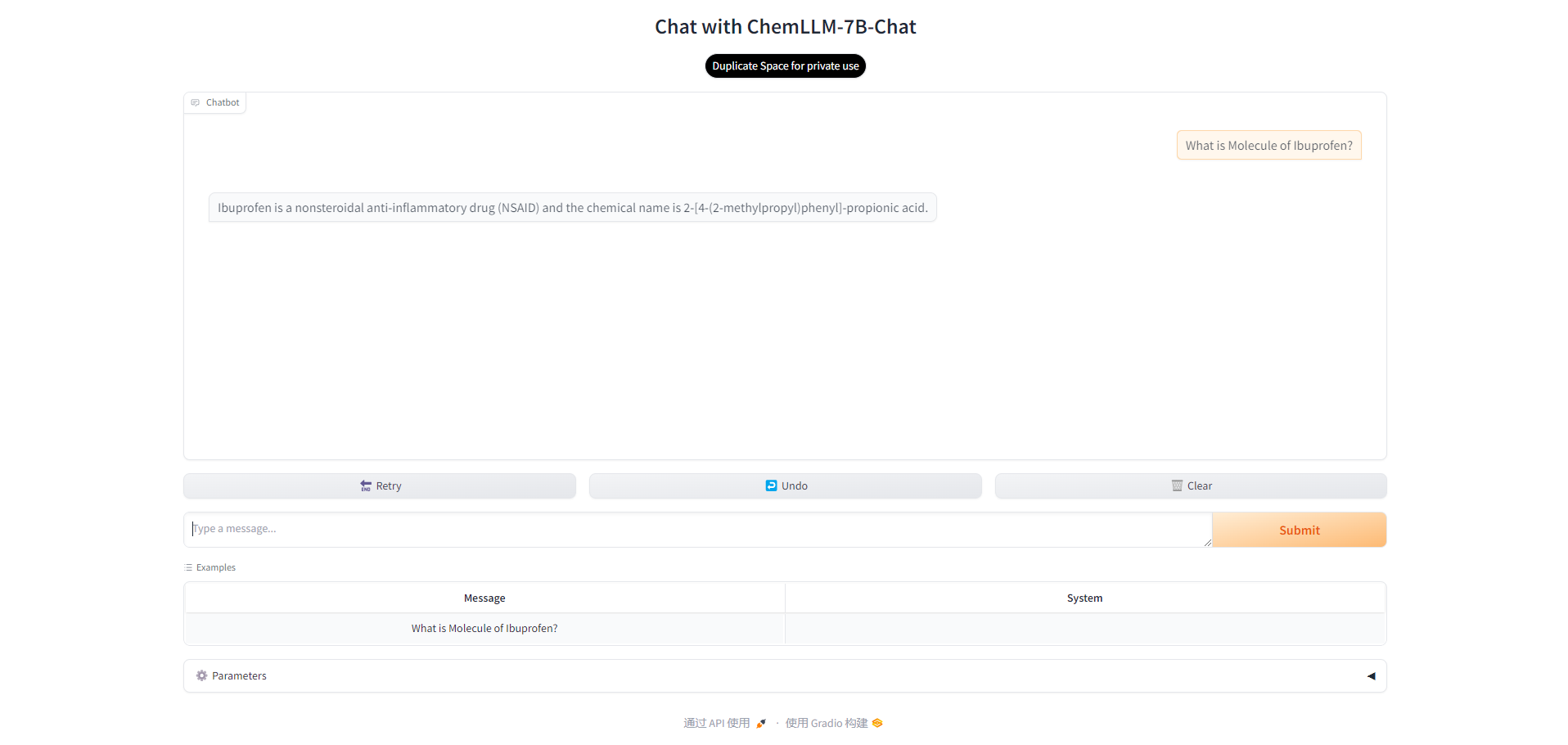
2. Ouvrez l'interface
Après une courte attente, vous pouvez voir l'interface du modèle et commencer à communiquer avec le modèle. Vous pouvez saisir un exemple de question ou votre propre question.
3. Réglage des paramètres
Il existe également plusieurs paramètres dans le modèle qui peuvent être ajustés. dans:
- Température : Utilisé pour ajuster le caractère aléatoire du texte généré. Plus la valeur est faible, plus le modèle est susceptible de choisir les mots avec la probabilité la plus élevée, ce qui donne un texte plus prévisible. Plus la valeur est élevée, plus le modèle est susceptible d'explorer des mots avec une probabilité plus faible, ce qui donne un texte plus diversifié mais potentiellement plus d'erreurs.
- Max New Tokens : spécifie le nombre maximal de mots que le modèle peut générer lors de la génération de texte. En limitant le nombre de mots générés, vous pouvez contrôler la longueur de la sortie et éviter la génération de texte trop long ou trop court.
Vous pouvez ajuster les paramètres selon vos besoins.

Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.