Command Palette
Search for a command to run...
Utilisation De La Diffusion De Gibbs Pour La Réduction Du Bruit Des Images Aveugles
Débruitage d'image aveugle basé sur la diffusion de Gibbs

Introduction au tutoriel
GDiff, abréviation de Gibbs-Diffusion, est une méthode de débruitage bayésienne aveugle qui résout le problème d'échantillonnage a posteriori des paramètres du signal et du bruit. Elle repose sur un échantillonneur de Gibbs qui alterne entre des étapes d'échantillonnage avec un modèle de diffusion pré-entraîné (définissant la distribution a priori du signal) et un échantillonneur hamiltonien de Monte Carlo. Cet article présente ses applications au débruitage d'images naturelles et à la cosmologie (analyse du fond diffus cosmologique). Les résultats de l'article sont… Écouter le bruit : débruitage aveugle avec diffusion de Gibbs
Le document officiel ne donne que la méthode de test, qui consiste à transmettre une image originale claire, à superposer du bruit, puis à effectuer une comparaison de débruitage non aveugle et de débruitage aveugle.
Démonstration d'effet
Dans la démonstration officielle de l'effet, une image originale claire est entrée, du bruit avec certains paramètres y est superposé, puis un débruitage aveugle est effectué.
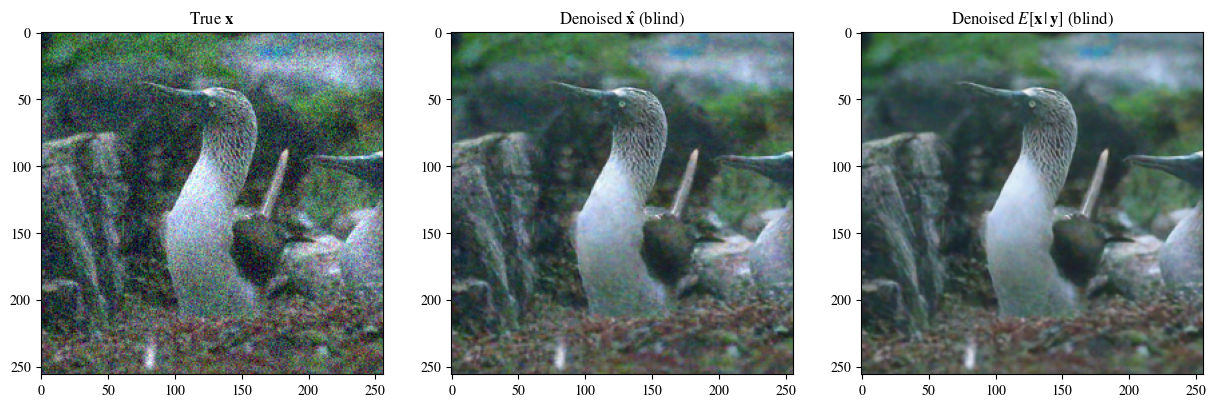
Les figures suivantes sont de gauche à droite : l'image après superposition du bruit, l'image originale, l'effet de débruitage aveugle et la moyenne postérieure débruitée

Introduction au débruitage aveugle et non aveugle
Le débruitage aveugle et le débruitage non aveugle sont deux méthodes de débruitage dans le traitement d'image et le traitement du signal. Leur principale différence réside dans le degré de prédiction des informations sur le bruit.
Débruitage aveugle
Définition : Le débruitage aveugle fait référence au débruitage sans connaître les caractéristiques du bruit ou le modèle de bruit. Cette méthode ne s'appuie pas sur une connaissance préalable du bruit, mais utilise plutôt les informations de l'image ou du signal lui-même pour débruiter.
Caractéristiques:
- Modèle de bruit indépendant : pas besoin de connaître le type, la distribution ou l'intensité du bruit.
- Forte adaptabilité : peut être appliqué à différents types d'environnements de bruit et de signal.
- Complexité élevée : comme le modèle de bruit n'apporte aucune aide, la débruitisation aveugle nécessite généralement des algorithmes plus complexes et davantage de ressources de calcul.
Débruitage non aveugle
Définition : Le débruitage non aveugle fait référence au débruitage lorsque les caractéristiques du bruit ou le modèle de bruit sont connus. Cette méthode utilise la connaissance préalable du bruit pour optimiser le processus de débruitage.
Caractéristiques:
- Modèle de dépendance au bruit : il nécessite une connaissance préalable du type, de la distribution et de l'intensité du bruit.
- Meilleur effet : lorsque le modèle de bruit est connu, il peut être optimisé pour des types de bruit spécifiques afin d'obtenir un meilleur effet de débruitage.
- Champ d'application limité : différents modèles et paramètres sont requis pour différents types de bruit, et le champ d'application est plus étroit que le débruitage aveugle.
Comment exécuter le didacticiel
Ce tutoriel est divisé en deux parties. La première partie est « Débruitage aveugle des images floues », qui peut être exécutée dans le fichier start.ipynb (ce fichier). Ici, vous pouvez transmettre une image floue avec du bruit pour un débruitage aveugle. La deuxième partie est « Clear Image Superimposed Noise and Denoising », qui est exécutée dans le fichier test.ipynb. Il s'agit d'une simplification du document officiel et peut être utilisé pour transmettre des images claires avec du bruit superposé afin de comparer la différence entre le modèle de débruitage aveugle et le modèle de débruitage non aveugle.
Si vous devez utiliser des images personnalisées, téléchargez simplement les images et modifiez les chemins des images que vous souhaitez traiter, puis exécutez-les une par une. (Le nom de l'image doit être en anglais)
Partie 1 : Débruitage aveugle des images floues (start.ipynb)
Importer les packages requis
import sys, time
import torch
import numpy as np
import matplotlib.pyplot as plt
import corner
import arviz as az
from PIL import Image
sys.path.append('..')
from gdiff.data import ImageDataset, get_colored_noise_2d
from gdiff.model import load_model
import gdiff.hmc_utils as iut
from gdiff.utils import ssim, psnr, plot_power_spectrum, plot_list_of_images
plt.rcParams.update(
{
'text.usetex': False,
'font.family': 'stixgeneral',
'mathtext.fontset': 'stix',
}
)Fonctions de lecture et de prétraitement d'images, les méthodes d'utilisation proviennent du document officiel data.py
#图片读取与预处理,方法来自官方文档 data.py
def readimg(filename):
from torchvision import transforms
img=Image.open(filename)
trans = transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(256),
transforms.RandomHorizontalFlip(),
transforms.ToTensor()])
img=trans(img)
return imgCe qui suit est la méthode officielle de lecture des ensembles de données, qui n’est pas utilisée dans ce document. Les utilisateurs peuvent placer leurs propres ensembles de données dans leurs dossiers et apporter quelques modifications mineures pour réaliser un traitement par lots (seuls quelques noms de dossiers peuvent être sélectionnés, dans le dossier de données)
#
# PARAMETERS 官方数据读取与噪声参数,模型选择
#
# Dataset and sample 读取官方数据集
dataset_name = "CBSD68" # Choices among "imagenet_train", "imagenet_val", "CBSD68", "McMaster", "Kodak24"
dataset = ImageDataset(dataset_name, data_dir='./data')
sample_id = 0 # np.random.randint(len(dataset))
# Noise 准备叠在在清晰图片上的噪声
phi_true = -0.4 # Spectral index -> between -1 and 1 (\varphi in the paper)
sigma_true = 0.1 # Noise level
# Device
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# Model 选择模型,有 5000 与 10000 步迭代模型可选
diffusion_steps = 5000 # Number of diffusion steps: 5000 or 10000
model = load_model(diffusion_steps=diffusion_steps,
device=device,
root_dir='./model_checkpoints')
model.eval()
# Inference
num_chains = 4 # Number of HMC chains
n_it_gibbs = 50 # Number of Gibbs iterations after burn-in
n_it_burnin = 25 # Number of burn-in iterationsEnsuite, lisez l’image qui doit être débruitée. Par exemple, l'image utilisée dans ce tutoriel est « 3_noisy.png » dans le répertoire personnel. Dans img=readimg('3_noisy.png'), changez simplement le chemin en '3_noisy.png'.
Dans le cas d'un A6000 avec une seule carte, il faut plusieurs minutes pour traiter une seule image.
#
# DENOISING 在此处读入的图片为高噪声图,在此处进行降噪处理
#
# 读取自己的高噪声图片,用于去噪
img=readimg('3_noisy.png')
x = img.to(device).unsqueeze(0)
# Our DDPM has discrete timestepping -> we get the time step closest to the chosen noise level
sigma_true_timestep, sigma_true = model.get_closest_timestep(torch.tensor([sigma_true]), ret_sigma=True)
alpha_bar_t = model.alpha_bar_t[sigma_true_timestep.cpu()].reshape(-1, 1, 1, 1).to(device)
print(f"Time step corresponding to noise level {sigma_true.item():.3f}: {sigma_true_timestep.item()}")
yt = torch.sqrt(alpha_bar_t) * x # Noisy image normalized for the diffusion model 归一化图像
# Non-blind denoising (for reference) 非盲去噪 即已知噪声参数的情况下去噪
print("Denoising in non-blind setting...")
t0 = time.time()
x_hat_nonblind = model.denoise_samples_batch_time(yt,
sigma_true_timestep.unsqueeze(0),
phi_ps=phi_true)
t1 = time.time()
print(f"Non-blind denoising took {t1-t0:.2f} seconds")
# Blind denoising with GDiff 基于 GDiff 的盲去噪
print("Denoising in blind setting (GDiff)...")
t0 = time.time()
phi_hat_blind, x_hat_blind = model.blind_denoising(x, yt,
num_chains_per_sample=num_chains,
n_it_gibbs=n_it_gibbs,
n_it_burnin=n_it_burnin)
t1 = time.time()
print(f"Blind denoising took {t1-t0:.2f} seconds")
# Denoised posterior mean estimate 去噪的后验均值估计
x_hat_blind_pmean = x_hat_blind[:, n_it_burnin:].mean(dim=(0, 1))Pas de temps correspondant au niveau de bruit 0,100 : 134 Débruitage en mode non aveugle... Le débruitage en mode non aveugle a pris 4,48 secondes Débruitage en mode aveugle (GDiff)...
0%| | 0/75 [00:00
Adaptation de la taille du pas à l'aide de 300 itérations Taille du pas fixée à : tensor([0.0179, 0.0181, 0.0179, 0.0194], device='cuda:0')
100%|██████████| 75/75 [08:52<00:00, 7.10s/it]
Le débruitage aveugle a pris 532,30 secondes
#
# Plot of a reconstruction 展示结果 顺序为:原始图片 非盲去噪 盲去噪 去噪的后验均值
#
data = [x[0],
x_hat_blind[0, -1],
x_hat_blind_pmean]
data = [d.to(device) for d in data]
labels_base = [r"True $\mathbf{x}$",
r"Denoised $\hat{\mathbf{x}}$ (blind)",
r"Denoised $E[\mathbf{x}\,|\,\mathbf{y}]$ (blind)"]
labels = [labels_base[0] ,
labels_base[1] ,
labels_base[2] ]
plot_list_of_images(data, labels)
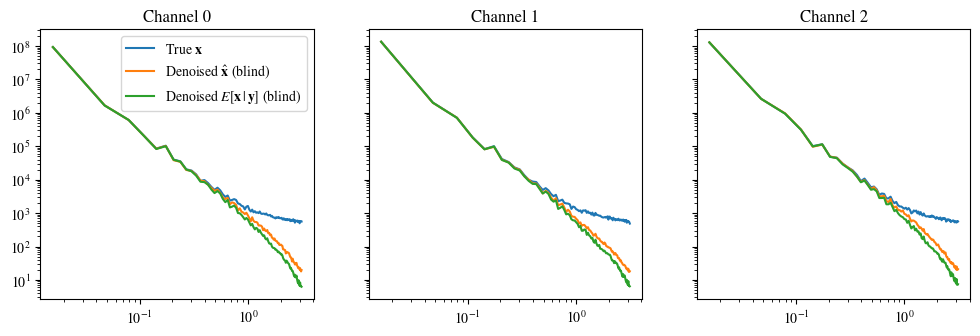
plot_power_spectrum(data, labels_base, figsize=(12, 3.5))Découpage des données d'entrée dans la plage valide pour imshow avec des données RVB ([0..1] pour les flottants ou [0..255] pour les entiers).
Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.