Command Palette
Search for a command to run...
Quantification Des Transformateurs De Vision (Vit) Pour Un Déploiement Efficace : Stratégies Et Meilleures Pratiques
Ce tutoriel recommande d'utiliser la version 2.0 de pytorch et un seul GPU 4090. Pour faciliter l'utilisation, les modèles utilisés ont été téléchargés dans le tutoriel. Veuillez les exécuter un par un.
1. Introduction
Alors que la demande de systèmes de vision par ordinateur avancés continue de croître dans tous les secteurs, le déploiement de Vision Transformers est devenu une priorité pour les chercheurs et les praticiens. Cependant, pour exploiter pleinement le potentiel de ces modèles, il faut une compréhension approfondie de leur architecture. De plus, il est tout aussi important de développer des stratégies d’optimisation pour déployer efficacement ces modèles.
Cet article vise à fournir un aperçu du Vision Transformer, en explorant pleinement son architecture, ses composants clés et les fondamentaux qui les rendent uniques. À la fin de l'article, nous discuterons de certaines stratégies d'optimisation avec des démonstrations de code pour rendre le modèle plus compact pour un déploiement plus facile.
2. Aperçu de Vit
ViT est un type spécial de réseau neuronal principalement utilisé pour la classification d'images et la détection d'objets. La précision du ViT a dépassé celle des CNN traditionnels, et le facteur clé qui y contribue est qu'ils sont basés sur l'architecture Transformer. Quelle est cette architecture maintenant ?
En 2017, Vaswani et al. « L'attention est tout ce dont vous avez besoin »L'architecture du réseau neuronal Transformer est introduite dans . Le réseau utilise une structure d'encodeur et de décodeur très similaire à un réseau neuronal récurrent (RNN). Dans ce modèle, il n’y a pas de concept d’horodatage sur l’entrée ; tous les mots sont transmis en même temps et leurs intégrations de mots sont déterminées en même temps.
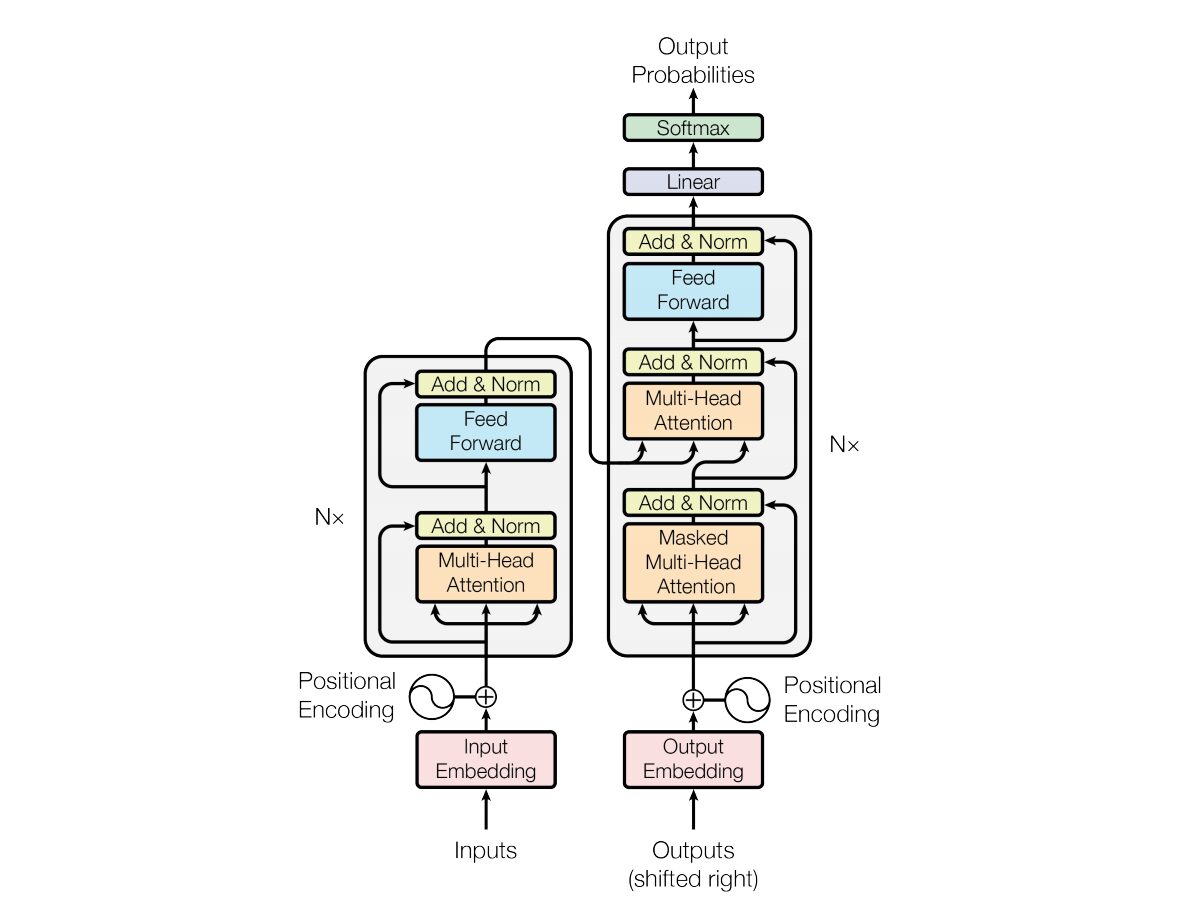
Ce type d’architecture de réseau neuronal repose sur un mécanisme appelé auto-attention.
Voici une explication de haut niveau des composants clés de l'architecture Transformer :
- Intégration d'entrée : l'intégration d'entrée est la première étape de transmission de l'entrée au transformateur. L'intégration d'entrée fait référence au processus de conversion de jetons ou de mots d'entrée en un vecteur de taille fixe qui peut être introduit dans le modèle. Cette étape d’intégration est cruciale car elle convertit la représentation du jeton discret en une représentation vectorielle continue d’une manière qui capture les relations sémantiques entre les mots. Cette étape d’intégration mappe un mot à un vecteur, mais le même mot peut avoir des significations différentes dans différentes phrases. C'est là qu'interviennent les codeurs de position.
- Codages positionnels : Étant donné que le transformateur lui-même ne comprend pas l'ordre des éléments dans une séquence, des codages positionnels sont ajoutés aux incorporations d'entrée pour fournir au modèle des informations sur la position de l'élément dans la séquence. En bref, les intégrations de position donnent un vecteur qui est contextuellement basé sur la position d'un mot dans une phrase. L’article original utilisait des fonctions sinus et cosinus pour générer ce vecteur. Ces informations sont transmises au bloc codeur.
- Structure de l'encodeur-décodeur : Transformer est principalement utilisé pour les tâches de séquence à séquence telles que la traduction automatique. Il se compose d'un encodeur et d'un décodeur. L'encodeur traite la séquence d'entrée et le décodeur génère la séquence de sortie.
- Auto-attention multi-têtes : l'auto-attention permet au modèle de pondérer différemment différentes parties de la séquence d'entrée lors de la réalisation de prédictions. L’innovation clé du Transformer est l’utilisation de plusieurs têtes d’attention, ce qui permet au modèle de se concentrer simultanément sur différents aspects de l’entrée. Chaque tête d’attention est entraînée à se concentrer sur un modèle différent.
- Attention au produit scalaire mis à l'échelle : le mécanisme d'attention calcule un ensemble de scores d'attention en prenant le produit scalaire de la séquence d'entrée et un vecteur de pondération apprenable. Ces scores sont mis à l’échelle et transmis via une fonction softmax pour obtenir des pondérations d’attention. La somme pondérée de la séquence d’entrée utilisant ces poids d’attention est la sortie du mécanisme d’attention.
- Réseau neuronal à propagation directe : après la couche d'attention, chaque bloc d'encodeur et de décodeur comprend généralement un réseau neuronal à propagation directe avec une fonction d'activation telle que ReLu. Le réseau est appliqué indépendamment à chaque position de la séquence.
- Normalisation des couches et connexions résiduelles : la normalisation des couches et les connexions résiduelles sont utilisées pour stabiliser la formation. Chaque sous-couche (attention ou feed-forward) dans l'encodeur et le décodeur possède une normalisation de couche, et la sortie de chaque sous-couche passe par une connexion résiduelle.
- Pile d'encodeurs et de décodeurs : L'encodeur et le décodeur sont constitués de plusieurs couches identiques empilées les unes sur les autres. Le nombre de couches est un hyperparamètre.
- Auto-attention masquée dans le décodeur : pendant la formation, dans le décodeur, le mécanisme d'auto-attention est modifié pour empêcher de prêter attention aux futurs jetons. Cela se fait à l’aide de techniques de masquage pour garantir que chaque position ne peut traiter que la position qui la précède.
- Couches linéaires finales et Softmax : la sortie de la pile de décodeurs est transformée en probabilités de prédiction finales (par exemple, en utilisant une couche linéaire suivie d'une activation softmax) pour produire la séquence de sortie.
3. Comprendre l'architecture du Vision Transformer
Le CNN est considéré comme la meilleure solution pour les tâches de classification d’images. Si l'ensemble de données de pré-formation est suffisamment grand, ViT bat systématiquement CNN sur de telles tâches. ViT a obtenu un succès significatif en entraînant avec succès un encodeur Transformer sur ImageNet, démontrant des résultats impressionnants par rapport aux architectures convolutives bien connues.
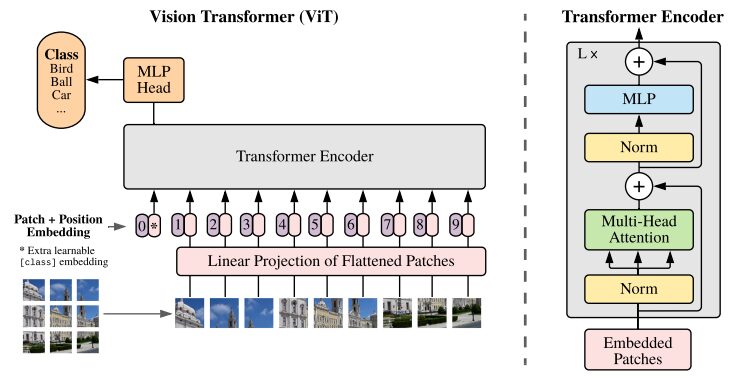
Illustration de l'architecture ViT tirée du document de recherche original
Les modèles de transformateurs traitent généralement des images et des mots qui sont transmis séquentiellement à un encodeur-décodeur. Voici un aperçu simplifié de ViT :
- Extraction de patchs : une image est transmise à l’encodeur Transformer sous la forme d’une séquence de patchs. Un patch est une petite partie rectangulaire d’une image, généralement de 16 × 16 pixels.

- Après avoir divisé l'image en blocs non superposés (généralement une grille 16 × 16), chaque bloc est converti en un vecteur représentant ses caractéristiques. Ces caractéristiques sont généralement extraites à l’aide d’un réseau neuronal convolutif (CNN), qui est formé pour identifier les caractéristiques importantes nécessaires à la classification des images.
- Incorporation linéaire : ces patchs extraits sont intégrés linéairement dans des vecteurs plans. Ces vecteurs sont ensuite traités comme la séquence d’entrée du transformateur, également connue sous le nom de projection linéaire du patch aplati.
- Encodeur de transformateur : le vecteur de patch intégré est transmis via la pile de couches de l'encodeur de transformateur. Chaque couche d'encodeur se compose d'un mécanisme d'auto-attention et d'un réseau neuronal à réaction directe.
- Mécanisme d'auto-attention : Le mécanisme d'auto-attention permet au modèle de capturer la relation entre différents patchs de l'image, lui permettant d'apprendre les dépendances et les relations à longue portée. Le mécanisme d’attention du Transformer permet au modèle de capturer des informations contextuelles locales et globales, lui permettant d’effectuer efficacement diverses tâches de vision.
- Codage de position : Étant donné que le transformateur lui-même ne comprend pas la relation spatiale entre les patchs, le codage de position est ajouté à l'intégration d'entrée pour fournir des informations sur l'emplacement du patch dans l'image d'origine.
- Plusieurs couches d'encodeur : ViT utilise généralement plusieurs couches d'encodeur Transformer pour capturer les fonctionnalités hiérarchiques et abstraites de l'image d'entrée.
- Pooling moyen global : la sortie de l'encodeur Transformer est généralement soumise à un pooling moyen global, qui regroupe les informations de différents patchs dans une représentation de taille fixe.
- Tête de classification : la représentation fusionnée est ensuite introduite dans une tête de classification (généralement constituée d'une ou plusieurs couches entièrement connectées) pour générer la sortie finale pour une tâche de vision par ordinateur spécifique (par exemple, la classification d'images).
Nous vous recommandons fortement de consulter l'originalDocuments de recherche, pour une compréhension plus approfondie de l'architecture ViT.
4. Mode d'emploi
Les codes suivants peuvent tous être consultés et exécutés dans pre_ViT.ipynb ! ! ! !
4.1 Classer les images à l'aide du modèle ViT pré-entraîné
Les modèles ViT pré-entraînés sont pré-entraînés à l'aide du célèbre ImageNet-21k, un ensemble de données avec 14 millions d'images et 21 000 catégories, et affinés sur l'ensemble de données ImageNet avec 1 million d'images et 1 000 catégories.
Démo :
- Les deux bibliothèques suivantes seront manquantes lorsque vous démarrerez la plateforme pour la première fois. Utilisez pip pour installer les dépendances. Ajoutez le paramètre supplémentaire --user lors de l'installation des dépendances avec pip. Ensuite, les dépendances installées seront enregistrées dans l'espace de travail du conteneur et ne seront pas invalidées lors du prochain redémarrage.
!pip install --user -q transformers timm- Importez les classes nécessaires depuis la bibliothèque Transformer. ViTFeatureExtractor est utilisé pour extraire des fonctionnalités d'images, et ViTForImageClassification est un modèle ViT pré-entraîné pour la classification d'images.
from transformers import ViTFeatureExtractor, ViTForImageClassification
from PIL import Image as img
from IPython.display import Image, display
FILE_NAME = '/notebooks/football-1419954_640.jpg'
display(Image(FILE_NAME, width = 700, height = 400))
#预测图片的地址
image_path = "./pic/football.jpg"
image_array = img.open(image_path)
#Vit 模型地址
vision_encoder_decoder_model_name_or_path = "./my_model/"
#加载 ViT 特征转化 and 预训练模型
#feature_extractor = ViTFeatureExtractor.from_pretrained(vision_encoder_decoder_model_name_or_path)
#model = ViTForImageClassification.from_pretrained(vision_encoder_decoder_model_name_or_path)
feature_extractor = ViTFeatureExtractor.from_pretrained('google/vit-base-patch16-224')
model = ViTForImageClassification.from_pretrained('google/vit-base-patch16-224')
#使用 Vit 特征提取器处理输入图像,专为 ViT 模型的格式
inputs = feature_extractor(images = image_array,
return_tensors="pt")
#预训练模型处理输入并生成输出 logits,代表模型对不同类别的预测。
outputs = model(**inputs)
#创建一个变量来存储预测类的索引。
logits = outputs.logits
# 查找具有最高 Logit 分数的类的索引
predicted_class_idx = logits.argmax(-1).item()
print(predicted_class_idx)
#805
print("Predicted class:", model.config.id2label[predicted_class_idx])
#预测种类:足球Décomposition du code :
- ViTFeatureExtractor.from_pretrained : Responsable de la conversion de l'image d'entrée dans un format adapté au modèle ViT.
- ViTForImageClassification.from_pretrained : charge un modèle ViT pré-entraîné pour la classification d'images.
- feature_extractor : traite l'image d'entrée à l'aide de l'extracteur de fonctionnalités ViT, en la convertissant dans un format adapté au modèle ViT.
- Modèle : le modèle pré-entraîné traite l'entrée et génère des logits de sortie, qui représentent les prédictions du modèle pour différentes catégories. L’étape suivante consiste à trouver l’index de la classe avec le score Logit le plus élevé. Créez une variable pour stocker l’index de la classe prédite.
- model.config.id2label[predicted_class_idx] : mappe les indices de classe prédits à leurs étiquettes correspondantes.
4.2 Classification des images à l'aide de DeiT
DeiT démontre l'application réussie des transformateurs aux tâches de vision par ordinateur, même avec une disponibilité de données et des ressources limitées.
from PIL import Image
import torch
import timm
import requests
import torchvision.transforms as transforms
from timm.data.constants import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD
print(torch.__version__)
# should be 1.8.0
#从 DeiT 存储库加载名为 “deit_base_patch16_224” 的预训练 DeiT 模型。
model = torch.hub.load('facebookresearch/deit:main', 'deit_base_patch16_224', pretrained=True)
#将模型设置为评估模式,这在使用预训练模型进行推理时非常重要。
model.eval()
#定义一系列应用于图像的变换。例如调整大小、中心裁剪、将图像转换为 PyTorch 张量、使用 ImageNet 数据常用的平均值和标准差值对图像进行归一化。
transform = transforms.Compose([
transforms.Resize(256, interpolation=3),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD),
])
#从 URL 下载图像并对其进行转换。或者直接从本地上传
#Image.open(requests.get("https://images.rawpixel.com/image_png_800/czNmcy1wcml2YXRlL3Jhd3BpeGVsX2ltYWdlcy93ZWJzaXRlX2NvbnRlbnQvcHUyMzMxNjM2LWltYWdlLTAxLXJtNTAzXzMtbDBqOXFrNnEucG5n.png", stream=True).raw)
img = Image.open("./pic/football.jpg")
#None 模拟大小为 1 的批次
img = transform(img)[None,]
#模型的推理、预测
out = model(img)
clsidx = torch.argmax(out)
#打印预测类别的索引。
print(clsidx.item())Décomposition du code :
- Installation des bibliothèques : La première étape nécessaire consiste à installer les bibliothèques requises. Nous recommandons fortement aux utilisateurs d’étudier ces bibliothèques pour une meilleure compréhension.
- Charger le modèle pré-entraîné :: model=torch.hub.load('facebookresearch/deit:main', 'deit_base_patch16_224', pretrained=True) charge le modèle DeiT pré-entraîné nommé 'deit_base_patch16_224' à partir du référentiel DeiT.
- Définissez le modèle en mode d'évaluation : model.eval() : Définit le modèle en mode d'évaluation, ce qui est très important lors de l'utilisation d'un modèle pré-entraîné pour l'inférence.
- Transformations d'image : définit une série de transformations à appliquer à une image. Par exemple, le redimensionnement, le recadrage central, la conversion d'images en tenseurs PyTorch et la normalisation des images à l'aide des valeurs moyennes et d'écart type couramment utilisées par les données ImageNet. Téléchargez et convertissez l’image : L’étape suivante consiste à télécharger l’image à partir de l’URL et à la convertir. L'ajout de l'argument [None] ajoute une dimension supplémentaire pour simuler des lots de taille 1.
- Inférence et prédiction du modèle : out = model(img) permettra de déduire l'image prétraitée via le modèle DeiT. clsidx = torch.argmax(out) trouvera l'index de la classe avec la probabilité la plus élevée. Ensuite, imprimez l’index de la classe prédite.
4.3 Modèle de quantification
Pour réduire la taille du modèle, une quantification est appliquée. Ce processus réduit la taille sans compromettre la précision du modèle.
#将量化后端指定为 “qnnpack” 。 QNNPACK(Quantized Neural Network PACKage)是 Facebook 开发的低精度量化神经网络推理库
backend = "qnnpack"
model.qconfig = torch.quantization.get_default_qconfig(backend)
torch.backends.quantized.engine = backend
#推理过程中量化模型的权重,并 qconfig_spec 指定量化应仅应用于线性(全连接)层。使用的量化数据类型是 torch.qint8(8 位整数量化)
quantized_model = torch.quantization.quantize_dynamic(model, qconfig_spec={torch.nn.Linear}, dtype=torch.qint8)
scripted_quantized_model = torch.jit.script(quantized_model)
#模型保存到名为 “fbdeit_scripted_quantized.pt” 的文件
scripted_quantized_model.save("fbdeit_scripted_quantized.pt")Décomposition du code :
- torch.quantization.quantize_dynamic(modèle, qconfig_spec={torch.nn.Linear}, dtype=torch.qint8)
- qconfig_spec spécifie que la quantification doit être appliquée uniquement aux couches linéaires (entièrement connectées). Le type de données de quantification utilisé est torch.qint8 (quantification entière 8 bits).
4.4 Modèle d'optimisation
La fonction optimize_for_mobile l'optimise spécifiquement pour le déploiement mobile et enregistre le modèle optimisé résultant dans un fichier.
from torch.utils.mobile_optimizer import optimize_for_mobile
optimized_scripted_quantized_model = optimize_for_mobile(scripted_quantized_model)
optimized_scripted_quantized_model.save("fbdeit_optimized_scripted_quantized.pt")
# 使用优化模型进行预测
out = optimized_scripted_quantized_model(img)
clsidx = torch.argmax(out)
print(clsidx.item())Version 4.5 Lite
Ceci est important pour déployer des modèles sur des appareils mobiles ou périphériques qui prennent en charge PyTorch Lite afin de garantir la compatibilité et l'efficacité de l'environnement d'exécution de ces appareils.
optimized_scripted_quantized_model._save_for_lite_interpreter("fbdeit_optimized_scripted_quantized_lite.ptl")
ptl = torch.jit.load("fbdeit_optimized_scripted_quantized_lite.ptl")4.6 Comparaison de la vitesse d'inférence
Pour comparer la vitesse d'inférence de différentes variantes de modèle, exécutez le code fourni :
with torch.autograd.profiler.profile(use_cuda=False) as prof1:
out = model(img)
with torch.autograd.profiler.profile(use_cuda=False) as prof2:
out = scripted_quantized_model(img)
with torch.autograd.profiler.profile(use_cuda=False) as prof3:
out = optimized_scripted_quantized_model(img)
with torch.autograd.profiler.profile(use_cuda=False) as prof4:
out = ptl(img)
print("original model: {:.2f}ms".format(prof1.self_cpu_time_total/1000))
print("scripted & quantized model: {:.2f}ms".format(prof2.self_cpu_time_total/1000))
print("scripted & quantized & optimized model: {:.2f}ms".format(prof3.self_cpu_time_total/1000))
print("lite model: {:.2f}ms".format(prof4.self_cpu_time_total/1000))
Tous les codes ci-dessus peuvent être consultés et exécutés dans pre_ViT.ipynb ! ! ! !
Conclusion et réflexions
Dans cet article, nous avons couvert tout ce dont vous avez besoin pour démarrer avec le convertisseur visuel et explorer le modèle à l'aide de la console Paperspace. Nous avons exploré l’une des applications importantes de ce modèle : la reconnaissance d’images. Pour une comparaison et une interprétation plus facile de ViT, nous incluons également l'architecture Transformer.
L’article Vision Transformer présente un modèle prometteur et simple comme alternative aux CNN. Après avoir été pré-entraîné sur ImageNet d'ILSVRC et son sur-ensemble ImageNet-21M, le modèle atteint des repères de pointe sur des ensembles de données de classification d'images populaires, notamment Oxford-IIIT Pets, Oxford Flowers et JFT-300M de Google Brain.
En résumé, les Vision Transformers (ViT) et DeiT représentent des avancées significatives dans le domaine de la vision par ordinateur. ViT a démontré l'efficacité du modèle Transformer pour la compréhension d'images avec son architecture basée sur l'attention, remettant en question les approches convolutionnelles traditionnelles.
En particulier, DeiT répond davantage aux défis auxquels est confronté ViT en introduisant la distillation des connaissances. En s'appuyant sur un paradigme de formation enseignant-étudiant, DeiT démontre le potentiel d'atteindre des performances compétitives avec beaucoup moins de données étiquetées, ce qui en fait une solution précieuse dans les scénarios où de grands ensembles de données ne sont pas facilement disponibles.
Alors que la recherche dans ce domaine continue de progresser, ces innovations ouvrent la voie à des modèles plus efficaces et plus puissants, ouvrant des possibilités passionnantes pour l’avenir des applications de vision par ordinateur.
Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.