Command Palette
Search for a command to run...
Entraînement De YOLOv8 Avec Des Données Personnalisées
Dans ce tutoriel, nous explorerons les nouvelles fonctionnalités du nouveau modèle d'Ultralytics, YOLOv8, nous analyserons en détail les changements architecturaux par rapport à YOLOv5 et nous présenterons le nouveau modèle en testant ses capacités de détection par API Python sur notre jeu de données de basket-ball. Ce tutoriel aborde principalement les principes de YOLOv8, montre comment créer et étiqueter un jeu de données, entraîner le modèle et l'utiliser sur tout fichier ou flux vidéo entrant.
La détection d’objets reste l’un des cas d’utilisation les plus populaires et les plus simples de la technologie de l’IA. Depuis la publication de la première version dans le travail révolutionnaire de Joseph Redman et al. En 2016, « You Only Look Once: Unified, Real-Time Object Detection », la famille de modèles YOLO a été à la pointe de la tendance. Ces modèles de détection d'objets ont ouvert la voie à l'étude de l'utilisation de modèles DL pour effectuer une reconnaissance en temps réel des entités, des sujets et des emplacements dans les images.
Dans cet article, nous allons revisiter les bases de ces techniques, discuter des nouvelles fonctionnalités de la dernière version d'Ultralytics, YOLOv8, et parcourir les étapes pour affiner un modèle YOLOv8 personnalisé à l'aide de RoboFlow et Paperspace Gradient et de la nouvelle API Ultralytics. À la fin de ce didacticiel, les utilisateurs devraient être en mesure d’adapter rapidement et facilement un modèle YOLOv8 à n’importe quel ensemble d’images étiquetées.
Comment fonctionne YOLO ?
Tout d’abord, discutons des bases du fonctionnement de YOLO. Voici une courte citation de l’article original de YOLO décomposant la somme des capacités du modèle :
Un réseau convolutif unique prédit simultanément plusieurs boîtes englobantes et leurs probabilités de classe. YOLO est entraîné sur des images complètes et optimise directement les performances de détection. Ce modèle unifié présente plusieurs avantages par rapport aux méthodes traditionnelles de détection d'objets.
Comme mentionné ci-dessus, le modèle est capable de prédire l’emplacement de plusieurs entités dans une image et d’identifier son sujet, étant donné qu’il a été formé sur ces caractéristiques. Il le fait en une seule étape en divisant l'image en N grilles, chacune de taille s*s. Ces régions sont analysées simultanément pour détecter et localiser tous les objets qu’elles contiennent. Le modèle prédit ensuite les coordonnées de la boîte englobante B dans chaque cellule de la grille et prédit les étiquettes et les scores de prédiction pour les objets qu'elle contient.
En combinant tous ces éléments, nous obtenons une technique capable d'effectuer des tâches de classification et de détection d'objets, ainsi que de segmentation d'images. La technologie sous-jacente de YOLO restant identique, nous pouvons en déduire qu'elle fonctionnera également avec YOLOv8. Pour une description plus complète du fonctionnement de YOLO, consultez nos précédents articles sur YOLOv5 et YOLOv7, nos tests comparatifs avec YOLOv6 et YOLOv7, ainsi que l'article original sur YOLO.
Quoi de neuf dans YOLOv8 ?
Étant donné que YOLOv8 vient d'être publié, aucun article n'a encore été publié couvrant ce modèle. Les auteurs ont l'intention de le publier bientôt, mais pour l'instant, nous ne pouvons que suivre la publication officielle, déduire les changements à partir de l'historique des commits et essayer de déterminer par nous-mêmes l'étendue des changements entre YOLOv5 et YOLOv8.
selonSortie officielle, YOLOv8 adopte un nouveau réseau fédérateur, une tête de détection sans ancrage et une fonction de perte. L'utilisateur de Github RangeKing a partagé un aperçu de l'infrastructure du modèle YOLOv8, montrant la structure principale et la structure principale du modèle mises à jour. En comparant ce chiffre avec YOLOv5 , RangeKing dans leurArticlesLes changements suivants ont été identifiés dans :

C2f Module, Source de l'image : RoboFlow (source)- Ils utilisent
C2fModule remplacéC3module. existerC2fDans, deBottleneck(deux 3×3 avec connexions résiduellesconvs) sont connectés ensemble, mais dansC3Seul le dernier est utiliséBottleneckSortir. (source)

- Ils sont
BackboneUtilisez-en un3x3 ConvLe bloc remplace le premier6x6 Conv - Ils ont supprimé deux
Conv(10e et 14e dans la configuration YOLOv5)

- Ils sont
BottleneckUtilisez-en un3x3 ConvRemplacé le premier1x1 Conv - Ils sont passés aux en-têtes découplés et ont supprimé
objectnesssuccursales
Veuillez revenir une fois que le document YOLOv8 sera publié, nous mettrons à jour cette section avec plus d'informations. Pour une analyse détaillée des changements ci-dessus, veuillez consulter l'article RoboFlow qui présente YOLOv8 Libérer.
Accessibilité
En plus de l'ancienne méthode de clonage du référentiel Github et de configuration manuelle de l'environnement, les utilisateurs peuvent désormais accéder à YOLOv8 pour la formation et l'inférence à l'aide de la nouvelle API Ultralytics. Veuillez voir ci-dessous Entraîner le modèle section pour plus de détails sur la configuration de l'API.
Pas de boîte englobante d'ancrage
Selon un article de blog du partenaire d'Ultralytics, RoboFlow YOLOv8, YOLOv8 dispose désormais de boîtes englobantes sans ancre. Dans la version initiale de YOLO, les utilisateurs devaient identifier manuellement ces boîtes d'ancrage afin de faciliter le processus de détection d'objets. Ces cadres de délimitation prédéfinis ont une taille et une hauteur prédéterminées, capturant l'échelle et le rapport hauteur/largeur de catégories d'objets spécifiques dans l'ensemble de données. Les décalages entre ces limites et les objets prédits aident le modèle à mieux identifier l’emplacement des objets.
Dans YOLOv8, ces boîtes d'ancrage sont automatiquement prédites au centre de l'objet.
Arrêtez l'augmentation de la mosaïque avant la fin de l'entraînement
À chaque époque d'entraînement, YOLOv8 voit une version légèrement différente de l'image qui lui est fournie. Ces changements sont appelés améliorations. L'un d'eux,Amélioration de la mosaïque, est le processus de combinaison de quatre images ensemble, forçant le modèle à apprendre l'identité des objets dans de nouveaux emplacements où ils sont partiellement bloqués les uns des autres par l'occlusion, avec une plus grande variation dans les pixels environnants. Il a été démontré que l’utilisation de cette augmentation tout au long de la formation peut avoir un effet néfaste sur la précision de la prédiction, donc YOLOv8 peut arrêter ce processus pendant les dernières époques de la formation. Cela permet d'exécuter le meilleur modèle de formation sans passer à l'échelle de l'exécution entière.
Efficacité et précision
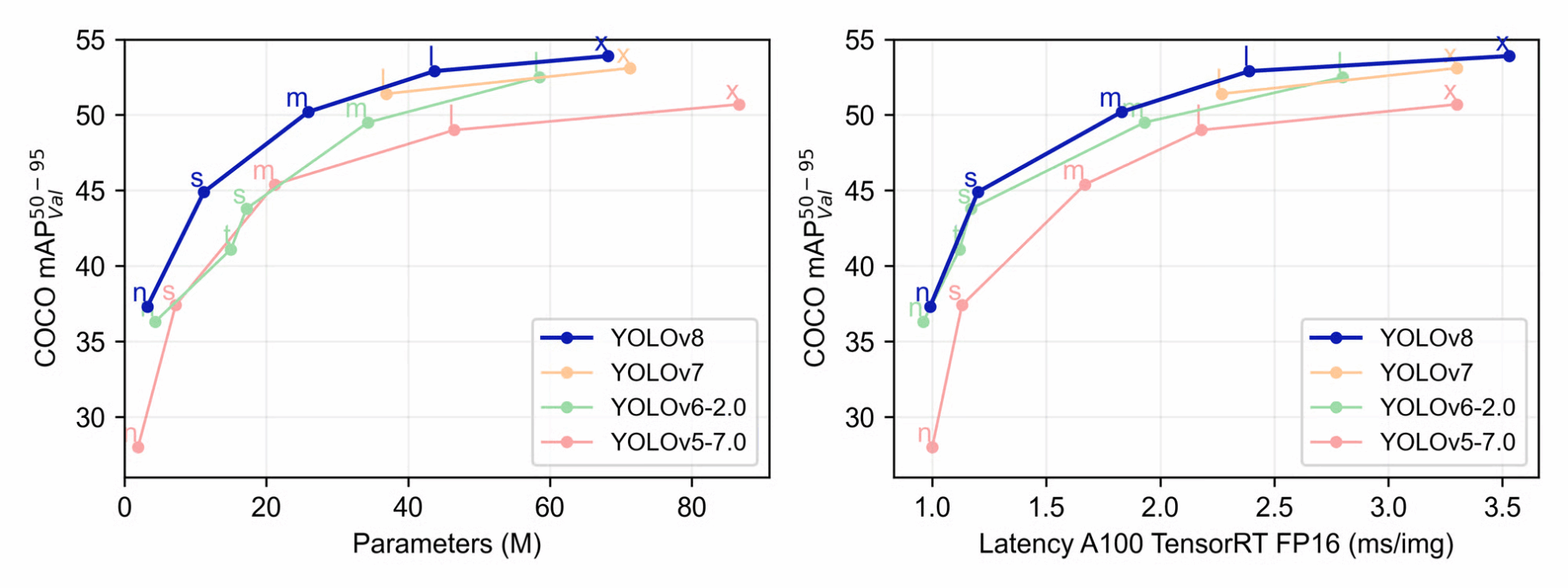
Notre principale raison ici est d’améliorer la précision et l’efficacité des performances lors de l’inférence et de la formation. Les auteurs d’Ultralytics nous ont fourni quelques exemples de données utiles que nous pouvons utiliser pour comparer la nouvelle version de YOLO avec d’autres versions. Comme le montrent les graphiques ci-dessus, lors de la formation, YOLOv8 surpasse YOLOv7, YOLOv6-2.0 et YOLOv5-7.0 en termes de précision moyenne, de taille et de latence.

Sur leurs pages Github respectives, nous pouvons trouver un tableau de comparaison statistique des modèles YOLOv8 de différentes tailles. D'après le tableau ci-dessus, nous pouvons voir qu'à mesure que la taille des paramètres, la vitesse et les FLOP augmentent, le mAP augmente également. Le plus grand modèle YOLOv5, YOLOv5x, a une valeur mAP maximale de 50,7. L’augmentation de 2,2 unités de la valeur mAP représente une amélioration significative des capacités. Cela est valable pour toutes les tailles de modèles, le nouveau modèle YOLOv8 surpassant systématiquement le YOLOv5, comme indiqué ci-dessous.

Dans l’ensemble, nous pouvons voir que YOLOv8 est une avancée significative par rapport à YOLOv5 et à d’autres frameworks concurrents.
Réglage fin de YOLOv8
Pour exécuter le didacticiel :Commencez à fonctionner sur OpenBayes
Le processus de réglage fin d’un modèle YOLOv8 peut être divisé en trois étapes : création et étiquetage d’un ensemble de données, formation du modèle et déploiement du modèle. Dans ce tutoriel, nous passerons en revue les deux premières étapes en détail et montrerons comment utiliser notre nouveau modèle sur n'importe quel fichier ou flux vidéo entrant.
Configuration du jeu de données
Nous allons recréer l'expérience YOLOv7 utilisée pour comparer les deux modèles. Nous allons donc revenir à l'ensemble de données de basket-ball sur Roboflow. Consultez la section « Configuration d'un ensemble de données personnalisé » de l'article précédent pour obtenir des instructions détaillées sur la configuration, l'étiquetage et l'extraction de l'ensemble de données depuis RoboFlow vers notre notebook.
Étant donné que nous utilisons un ensemble de données précédemment créé, il nous suffit maintenant d’extraire les données. Vous trouverez ci-dessous les commandes utilisées pour extraire les données dans l’environnement Notebook. Pour votre propre ensemble de données étiqueté, utilisez le même processus, mais remplacez les valeurs de l'espace de travail et du projet par les vôtres pour accéder à votre ensemble de données de la même manière.
Assurez-vous de modifier la clé API par la vôtre si vous souhaitez suivre la démonstration dans le notebook à l'aide du script ci-dessous.
!pip install roboflow
from roboflow import Roboflow
rf = Roboflow(api_key="")
project = rf.workspace("james-skelton").project("ballhandler-basketball")
dataset = project.version(11).download("yolov8")
!mkdir datasets
!mv ballhandler-basketball-11/ datasets/Entraîner le modèle
En utilisant la nouvelle API Python, nous pouvons utiliser ultralytics La bibliothèque effectue tout le travail facilement dans l'environnement Gradient Notebook. Nous allons construire à partir de zéro en utilisant la configuration et les poids fournis YOLOv8n Modèle. Nous utiliserons ensuite l’ensemble de données que nous venons de charger dans notre environnement en utilisant model.train() Affiner la méthode.
from ultralytics import YOLO
# 加载模型
model = YOLO("yolov8n.yaml") # 从头构建新模型
model = YOLO("yolov8n.pt") # 加载预训练模型(建议用于训练)
# 使用模型
results = model.train(data="datasets/ballhandler-basketball-11/data.yaml", epochs=10) # 训练模型Tester le modèle
results = model.val() # 在验证集上评估模型性能Nous pouvons utiliser model.val() 方法 Définissez le nouveau modèle à évaluer sur l'ensemble de validation. Cela affichera un joli tableau dans la fenêtre de sortie montrant les performances de notre modèle. Étant donné que nous n'avons été entraînés ici que pendant dix époques, ce mAP relativement faible de 50 à 95 est à prévoir.

À partir de là, soumettre n’importe quelle photo est simple. Il générera des prédictions pour les boîtes englobantes, superposera ces boîtes sur l'image et les téléchargera dans le dossier « runs/detect/predict ».
from ultralytics import YOLO
from PIL import Image
import cv2
# from PIL
im1 = Image.open("assets/samp.jpeg")
results = model.predict(source=im1, save=True) # 保存绘制的图像
print(results)
display(Image.open('runs/detect/predict/image0.jpg'))Nous obtenons les prédictions pour les boîtes englobantes et leurs étiquettes comme suit :
[Ultralytics YOLO <class 'ultralytics.yolo.engine.results.Boxes'> masks
type: <class 'torch.Tensor'>
shape: torch.Size([6, 6])
dtype: torch.float32
+ tensor([[3.42000e+02, 2.00000e+01, 6.17000e+02, 8.38000e+02, 5.46525e-01, 1.00000e+00],
[1.18900e+03, 5.44000e+02, 1.32000e+03, 8.72000e+02, 5.41202e-01, 1.00000e+00],
[6.84000e+02, 2.70000e+01, 1.04400e+03, 8.55000e+02, 5.14879e-01, 0.00000e+00],
[3.59000e+02, 2.20000e+01, 6.16000e+02, 8.35000e+02, 4.31905e-01, 0.00000e+00],
[7.16000e+02, 2.90000e+01, 1.04400e+03, 8.58000e+02, 2.85891e-01, 1.00000e+00],
[3.88000e+02, 1.90000e+01, 6.06000e+02, 6.58000e+02, 2.53705e-01, 0.00000e+00]], device='cuda:0')]Appliquez-les ensuite à l’image, comme indiqué dans l’exemple suivant :

Comme nous pouvons le voir, notre modèle léger et entraîné montre qu'il peut identifier les joueurs sur le terrain à partir des joueurs sur le terrain et des joueurs et spectateurs sur la touche, à l'exception d'un coin. Une formation supplémentaire est presque certainement nécessaire, mais il est facile de voir que le modèle acquiert très rapidement une compréhension de la tâche.
Si nous sommes satisfaits de la formation du modèle, nous pouvons alors exporter le modèle dans le format souhaité. Dans ce cas, nous exporterons une version ONNX.
success = model.export(format="onnx") # 将模型导出为 ONNX 格式Résumer
Dans ce tutoriel, nous avons exploré les nouvelles fonctionnalités du nouveau modèle puissant d'Ultralytics, YOLOv8, examiné en profondeur les changements architecturaux par rapport à YOLOv5 et testé la fonctionnalité de l'API Python du nouveau modèle en le testant sur notre ensemble de données Ballhandler. Nous avons pu montrer que cela représente une avancée significative dans la simplification du processus de réglage fin du modèle de détection d’objets YOLO et avons démontré la capacité du modèle à distinguer les possessions de balle dans les matchs NBA à l’aide de photos en jeu.
Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.