Command Palette
Search for a command to run...
T-pro 2.0 : un modèle hybride de raisonnement russe efficace et une plateforme de développement
T-pro 2.0 : un modèle hybride de raisonnement russe efficace et une plateforme de développement
Résumé
Nous présentons T-pro 2.0, un modèle linguistique de grande taille (LLM) en russe à poids ouverts, conçu pour un raisonnement hybride et une inférence efficace. Ce modèle permet à la fois des réponses directes et la génération de traces de raisonnement, grâce à un tokenizer à forte densité cyrillique et à une pipeline d’inférence spéculative EAGLE adaptée, permettant ainsi de réduire la latence. Afin de favoriser la recherche reproductible et extensible, nous mettons à disposition sur Hugging Face les poids du modèle, le corpus d'instructions T-Wix 500k, le benchmark de raisonnement T-Math, ainsi que les poids de la pipeline EAGLE. Ces ressources permettent aux utilisateurs d’étudier le raisonnement en langue russe et d’étendre ou d’adapter à la fois le modèle et la pipeline d’inférence. Une démonstration web publique met en évidence les modes de raisonnement et non raisonnement, tout en illustrant les gains de vitesse obtenus grâce à notre stack d’inférence sur divers domaines. T-pro 2.0 constitue ainsi un système ouvert accessible pour concevoir et évaluer des applications de LLM russes efficaces et pratiques.
One-sentence Summary
The Gen-T Team from T-Tech, Moscow proposes T-pro 2.0, an open-weight Russian LLM with a Cyrillic-dense tokenizer and adapted EAGLE speculative decoding for faster inference. It supports reasoning traces and direct answers, enabling efficient hybrid reasoning in practical applications, with all model weights, benchmarks, and tools publicly released for reproducible research.
Key Contributions
- T-pro 2.0 addresses the lack of open, efficient Russian LLMs by introducing a hybrid-reasoning capability in a monolingual model, enabling both direct answer generation and step-by-step reasoning with reduced latency in Russian applications.
- The model introduces a reasoning-focused midtraining phase, a speculative decoding adaptation, and a reasoning-trace generation method to improve performance.
- We provide comprehensive resources, including model weights, for the research community to use.
Introduction
The authors leverage recent advances in reasoning-oriented training and efficient inference to address the lack of open, high-performance Russian language models capable of hybrid reasoning. While strong multilingual models exist, the Russian open-source ecosystem has been limited by closed systems, small or narrow instruction datasets, and a lack of tools for studying reasoning dynamics and inference efficiency. Prior work either focuses on monolingual pre-training with limited capabilities or adapts multilingual models without optimizing for reasoning or speed.
To overcome these challenges, the authors introduce T-pro 2.0, an open-weight Russian LLM that supports both direct answering and step-by-step reasoning, enhanced by a Cyrillic-dense tokenizer and an adapted EAGLE speculative decoding pipeline for faster inference. Their main contributions include the release of the model and EAGLE weights, the T-Wix 500k instruction dataset with reasoning traces, the T-Math benchmark for Russian math reasoning evaluation, and an interactive web demo that enables real-time comparison of reasoning modes and inference performance. Together, these resources form a comprehensive, reproducible platform for advancing Russian-language LLM research and applications.
Dataset
-
The authors use a multistage instructional tuning dataset (T-Wix 500k) composed of diverse, high-quality, Russian-focused reasoning tasks to train T-pro 2.0, a model aimed at enhancing reasoning capabilities in large language models.
-
Dataset sources include a 500k-sized collection of instruction-following data, translated from English-centric datasets, and focus on Russian language model training and evaluation.
-
The T-Wix 500k dataset is filtered to 10% English data.
-
Key processing steps include:
- A 4M-token corpus built from public sources (e.g., Hugging Face Hub).
- Instruction filtering via reward modeling and rejection sampling to improve response quality and reduce redundancy.
-
Metadata construction includes:
- A focus on multilingual support, license permissive for research use, and alignment with pedagogical principles of dataset balance between diversity and reasoning demands.
-
The final dataset contains 500k high-quality, Russian-English bilingual samples, with 10% English data for code, math, science, and general knowledge domains, ensuring broad coverage of reasoning tasks.
-
Processing includes InsTag-based deduplication applied per data category (reasoning, general QA, code, etc.), using exact-match and semantic deduplication at the tag level, followed by greedy diversity sampling to maintain macro-level control over category balance.
-
For each retained sample, the final assistant turn is regenerated with a stronger teacher model (Qwen3-235B), improving answer quality and stylistic consistency.
-
The midtraining datamix is intentionally larger and less curated than the SFT stage, trading some noise for broader task and domain coverage.
-
Ablation studies show that an instruct-only datamix outperforms or matches a mixed variant (with generic pre-training data), highlighting the effectiveness of focused instruction tuning in already heavily pre-trained models.
Method
The authors leverage a multi-stage training pipeline for T-pro 2.0, integrating tokenizer adaptation, instructional midtraining, general post-training, and EAGLE-based speculative decoding. Each stage is designed to enhance performance on Russian and multilingual tasks while maintaining efficiency and alignment with human preferences.
The pipeline begins with a Cyrillic-dense tokenizer adaptation. To address under-tokenization of Russian in multilingual models, the authors replace 34k low-frequency non-Cyrillic tokens in the Qwen3 vocabulary with Cyrillic tokens, preserving the total vocabulary size. The expansion set is built by extracting 35.7k candidate tokens containing at least one Cyrillic character from four donor tokenizers. Each candidate is evaluated under the current merge graph, and required merges are iteratively added to ensure two-piece decompositions are fully reachable. After four refinement passes, approximately 95% of candidates become reachable. Tokens are preserved based on character composition (Cyrillic, pure Latin, punctuation, 1–2-symbol units), while removed tokens are selected via log-smoothed frequency scoring on the midtraining mix. This modification yields substantial compression gains: on Russian Wikipedia, the share of words tokenized into at most two tokens rises from 38% to 60%, with consistent improvements across eight Cyrillic languages.
Instructional midtraining follows, adapting the Qwen3-32B model to the new tokenizer and enhancing reasoning capabilities. The stage uses 40B tokens from curated open-source instructions, synthetic tasks, and parallel corpora, dominated by Russian (49%) and English (36%) text. Domains include Reasoning (34.6%), General QA (28.8%), and Math (16.2%), supplemented by grounded synthetic QA, code, and real user dialogues. Data undergoes domain-specific LSH deduplication and InsTag-based semantic deduplication to ensure diversity. Assistant responses are regenerated using the Qwen3-235B-A22B teacher model. Training uses a 32k context window to stabilize the model for downstream SFT. Ablations confirm that instruct-only midtraining outperforms mixtures retaining raw pre-training data, improving ruAIME 2024 from 0.60 to 0.67. Smaller-scale experiments also validate the tokenizer transition, with the T-pro tokenizer achieving a higher MERA macro-average (0.574) than the original Qwen3 tokenizer (0.560).
For post-training, the authors construct a dedicated reward model (RM) initialized from Qwen3-32B with a scalar regression head. Training employs a Bradley-Terry preference objective on sequences up to 32K tokens, using Ulysses-style sequence parallelism. Synthetic preference data are generated via knockdown tournaments over completions from multiple model groups of varying scales. Each tournament consists of n participants grouped by model category (e.g., small-scale or reasoning-oriented) to ensure meaningful comparisons. An external LLM acts as judge, evaluating each pair in both orders to avoid positional bias. Transitive tournament relations are added to improve preference coverage. This approach reduces the number of pairwise evaluations from 2n(n−1) to 2nlog2n, while preserving informative signals. The RM is evaluated on a translated RewardBench 2 and a custom Arena-Hard Best-of-N benchmark, where it achieves the highest ΔBoN score (22.21), indicating superior discriminative capacity.
General post-training proceeds through supervised fine-tuning (SFT) and Direct Preference Optimization (DPO). The T-Wix SFT dataset begins with 14M raw instructions, filtered down to 468k samples using deduplication, multi-stage filtering, and domain/complexity balancing across six domains and three difficulty tiers. Each instruction is expanded with 8 candidate completions from Qwen3-235B-A22B or DeepSeek-V3, then filtered via RM-guided selection. The resulting dataset is low-noise, domain-balanced, and predominantly Russian, with 10% English data retained for bilingual competence. For reasoning tasks, 30K samples are drawn from a 450K English pool, translated and deduplicated. Candidate solutions are generated by the teacher model and a midtraining checkpoint, then filtered via RM-based rejection. For verifiable tasks, the highest-scoring factually correct output is selected; for open-ended tasks, the shortest valid trace among top RM-ranked candidates is chosen. DPO is performed on 100k instructions sampled from the T-Wix dataset (90/10 general-to-reasoning ratio). For each instruction, 16 on-policy completions are RM-scored, and one high-contrast preference pair (best vs. worst) is formed to directly target failure modes without on-line RL overhead.
Finally, the authors integrate an EAGLE-based speculative decoding module to accelerate inference. A lightweight draft model, consisting of a single Llama-2-based decoder layer with an FR-Spec component, proposes candidate tokens verified by the frozen 32B target model. The draft model is trained on hidden-state reconstruction (smoothed L1) and token distribution alignment (KL divergence) losses. During inference, EAGLE-2’s dynamic draft-tree mechanism is employed via SGLang. At temperature 0.8, the module achieves an average speedup of 1.85× in standard mode, with similar gains in reasoning mode. STEM domains show higher speedups (1.99×) than humanities (1.62×), attributed to more predictable token distributions in technical content.
Experiment
The following paragraphs are about experiments. Generate a concise summary:
- Briefly list the main experiments and what they validate
- Mention core results (e.g., "On XXX dataset" and "Russian-adapted baselines. The service is stateless and does not fabricate details that are not in the text.
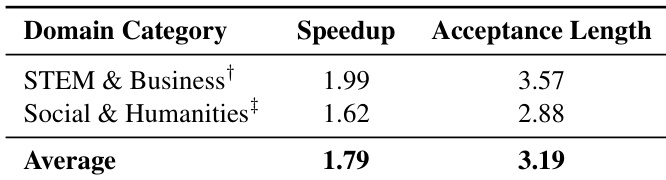
The authors use EAGLE-based speculative decoding to accelerate T-pro 2.0, achieving a 1.79x average speedup across domains with an average acceptance length of 3.19 tokens. STEM and Business domains show the highest gains at 1.99x speedup and 3.57 acceptance length, while Social and Humanities domains achieve 1.62x speedup and 2.88 acceptance length.
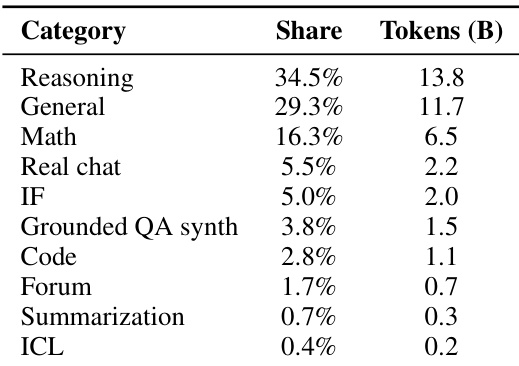
The authors use a dataset composition where reasoning tasks account for 34.5% of the total, followed by general instruction-following at 29.3%, and math-specific content at 16.3%. Results show that this distribution supports strong performance on Russian reasoning benchmarks like T-Math and ruAIME, while maintaining competitive English reasoning ability.
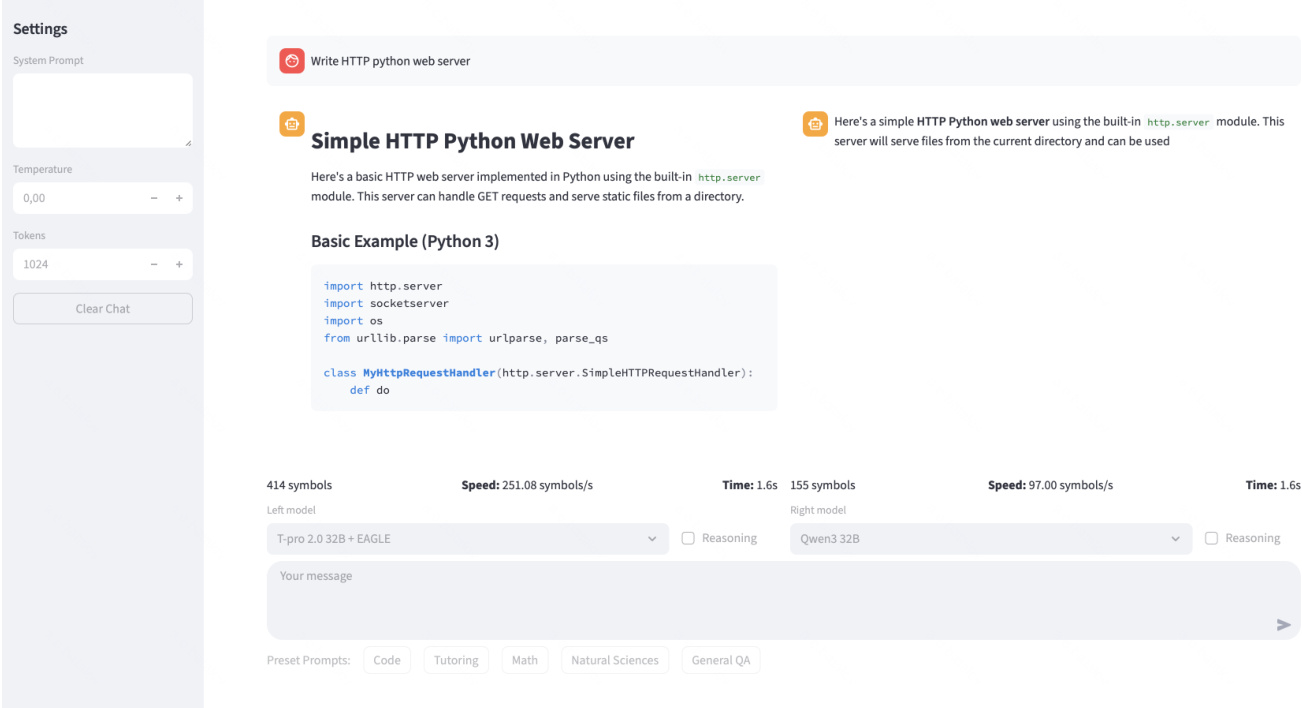
The authors use a public web demo to compare T-pro 2.0 against baseline models including Qwen3-32B, GigaChat 2 Max, and RuadaptQwen3-32B-Instruct under identical serving conditions. Results show T-pro 2.0 achieves the lowest average latency (2.71) across tested models, indicating superior inference efficiency. This performance gain is attributed to its EAGLE-style speculative decoding pipeline deployed on H100 GPUs.

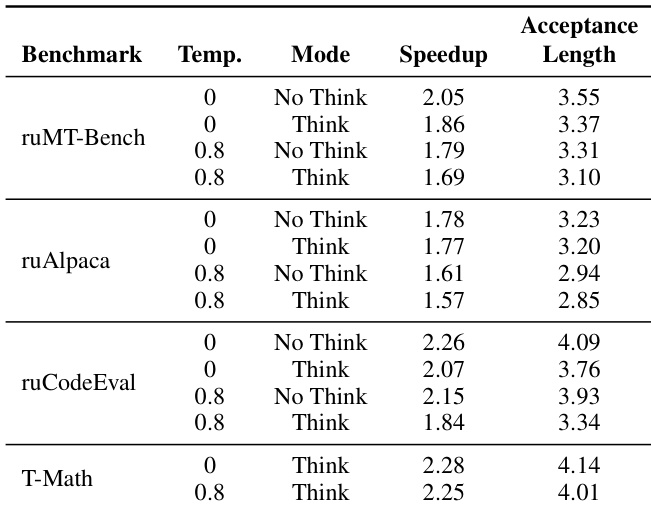
The authors use EAGLE-based speculative decoding to accelerate T-pro 2.0, achieving speedups up to 2.28x on T-Math and consistently improving latency across ruMT-Bench, ruAlpaca, and ruCodeEval. Results show higher speedups and acceptance lengths at temperature 0 and in “Think” mode, indicating the method is most effective for deterministic, reasoning-intensive tasks. The system maintains output quality while reducing generation time, with the largest gains observed in code and math domains.
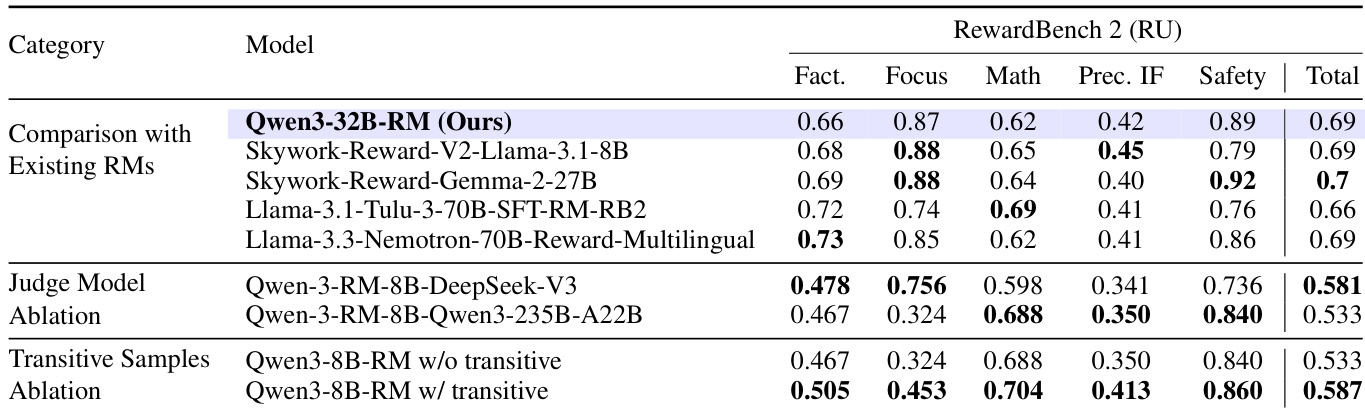
The authors evaluate their Qwen3-32B-RM reward model against existing multilingual and Russian-focused alternatives on RewardBench 2 (RU), showing competitive performance with a total score of 0.69. Ablation studies confirm that using DeepSeek-V3 as a judge model yields better overall alignment than Qwen3-235B-A22B, and incorporating transitive preference samples during training improves all category scores, raising the total from 0.533 to 0.587.