Command Palette
Search for a command to run...
Inferix : un moteur d'inférence de nouvelle génération pour la simulation du monde basé sur le block-diffusion
Inferix : un moteur d'inférence de nouvelle génération pour la simulation du monde basé sur le block-diffusion
Résumé
Les modèles mondiaux servent de simulateurs fondamentaux dans des domaines tels que l’intelligence artificielle agente, l’intelligence artificielle incarnée et les jeux vidéo, capables de générer des vidéos de haute qualité, longues, physiquement réalistes et interactives. En outre, l’agrandissement de ces modèles pourrait libérer des capacités émergentes en perception visuelle, compréhension et raisonnement, ouvrant la voie à un nouveau paradigme qui dépasserait les modèles fondamentaux actuels centrés sur les grands modèles linguistiques (LLM). Un progrès clé qui les rend possibles est le paradigme de décodage semi-autorégressif (block-diffusion), qui combine les forces des méthodes de diffusion et des méthodes autorégressives en générant des tokens vidéo par blocs via une diffusion appliquée à chaque bloc, tout en conditionnant la génération sur les blocs précédents. Ce mécanisme permet d’obtenir des séquences vidéo plus cohérentes et stables. De façon cruciale, il surmonte les limites des modèles de diffusion vidéo classiques en réintroduisant une gestion du cache KV inspirée des LLM, permettant une génération efficace, de longueur variable et de haute qualité.En conséquence, Inferix a été spécifiquement conçu comme un moteur d’inférence de nouvelle génération, visant à permettre la synthèse immersive du monde grâce à des processus d’inférence semi-autorégressive optimisés. Ce focus dédié à la simulation du monde le distingue nettement des systèmes conçus pour des scénarios à haute concurrence (comme vLLM ou SGLang) et des modèles classiques de diffusion vidéo (tels que xDiTs). Inferix renforce encore son offre par la diffusion vidéo interactive et le profilage, permettant une interaction en temps réel et une simulation réaliste pour modéliser avec précision la dynamique du monde. En outre, il intègre de manière fluide LV-Bench, un nouveau benchmark d’évaluation à très fine granularité spécifiquement conçu pour les scénarios de génération vidéo d’une minute, offrant ainsi une évaluation efficace. Nous espérons que la communauté collaborera pour faire évoluer Inferix et promouvoir l’exploration des modèles mondiaux.
Summarization
The Inferix Team introduces Inferix, a next-generation inference engine for immersive world synthesis that employs optimized semi-autoregressive block-diffusion decoding and LLM-style KV Cache management to enable efficient, interactive, and long-form video generation distinct from standard high-concurrency or classic diffusion systems.
Introduction
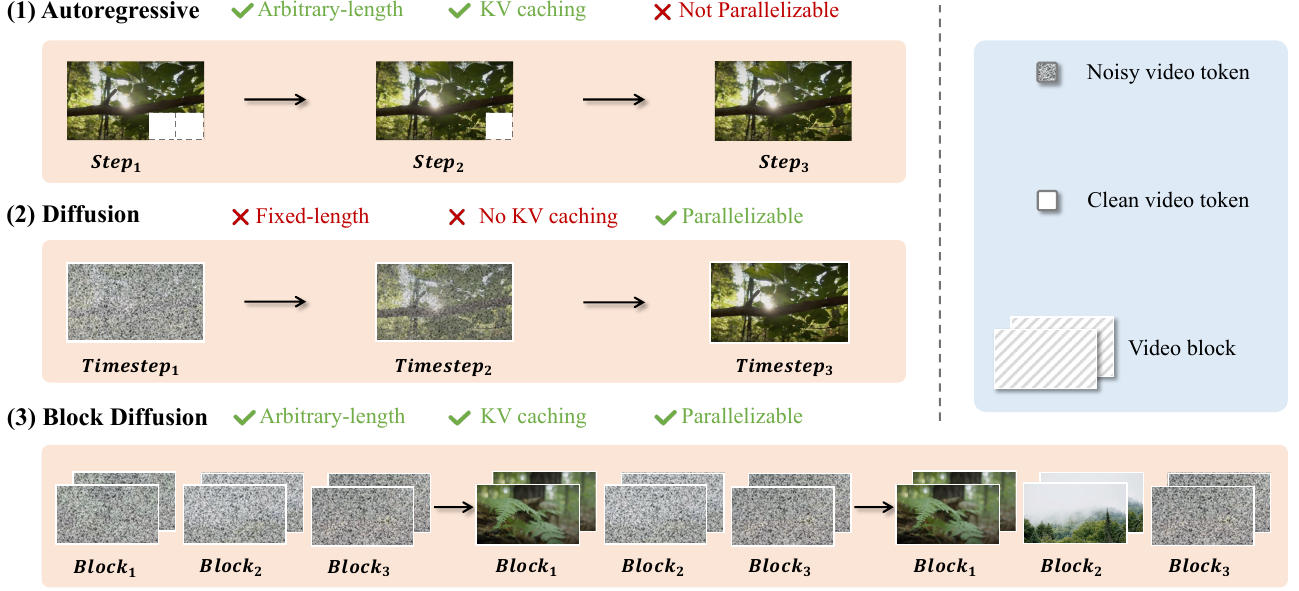
World models are rapidly advancing toward generating long-form, interactive video sequences, creating a critical need for specialized infrastructure capable of handling the immense computational and storage demands of immersive world synthesis. Current approaches face a distinct trade-off: Diffusion Transformers (DiT) offer high-quality, parallelized generation but suffer from inefficient decoding and fixed-length constraints, while Autoregressive (AR) models support variable lengths but often lag in visual quality and lack parallelization capabilities.
To bridge this gap, the authors introduce Inferix, a dedicated inference engine designed to enable efficient, arbitrary-length video generation. By adopting a "block diffusion" framework, the system interpolates between AR and diffusion paradigms, utilizing a semi-autoregressive decoding strategy that reintroduces LLM-style memory management to maintain high generation quality over extended sequences.
Key innovations include:
- Semi-Autoregressive Block Diffusion: The engine employs a generate-and-cache loop where attention mechanisms leverage a global KV cache to maintain context across generated blocks, ensuring long-range coherence without sacrificing diffusion quality.
- Advanced Memory Management: To address the storage bottlenecks of long-context simulation, the system integrates intelligent KV cache optimization techniques similar to PageAttention to minimize GPU memory usage.
- Scalable Production Features: The framework supports distributed synthesis for large-scale environments, continuous prompting for dynamic narrative control, and built-in real-time video streaming protocols.
Dataset
The authors introduce LV-Bench, a benchmark designed to address the challenges of generating minute-long videos. The dataset construction and usage involve the following components:
- Composition and Sources: The benchmark comprises 1,000 long-form videos collected from diverse open-source collections, specifically DanceTrack, GOT-10k, HD-VILA-100M, and ShareGPT4V.
- Selection Criteria: The team prioritized high-resolution content, strictly selecting videos that exceed 50 seconds in duration.
- Metadata Construction: To ensure linguistic diversity and temporal detail, the authors utilized GPT-4o as a data engine to generate granular captions every 2 to 3 seconds.
- Quality Assurance: A rigorous human-in-the-loop validation framework was applied across three stages: sourcing (filtering unsuitable clips), chunk segmentation (ensuring coherence and removing artifacts), and caption verification (refining AI-generated text). At least two independent reviewers validated each stage to maintain reliability.
- Model Usage: The final curated dataset is partitioned into an 80/20 split for training and evaluation purposes.
Method
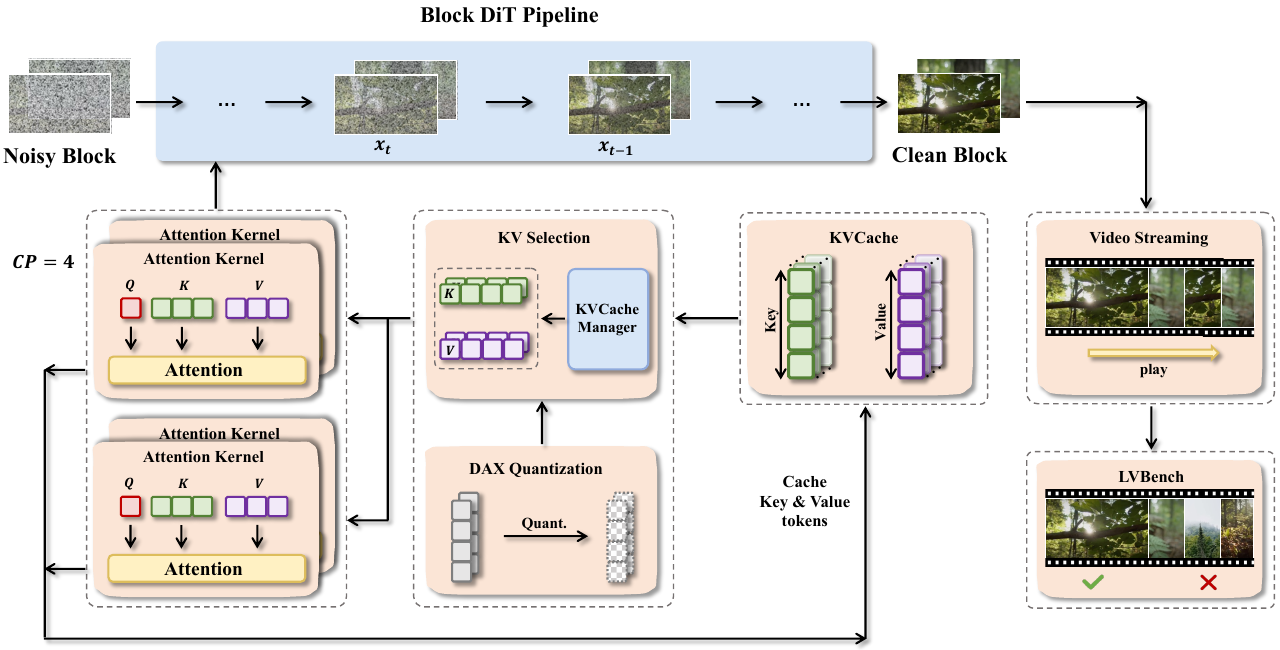
The authors leverage a modular and extensible framework designed to address the unique challenges of block diffusion models for long video generation. The core of the system, as illustrated in the framework diagram, is built around a generalized inference pipeline that abstracts common computational patterns across diverse models such as MAGI-1, CausVid, and Self Forcing. This pipeline orchestrates a sequence of interconnected components to enable efficient and scalable inference.
At the heart of the inference process is the Block DiT Pipeline, which processes video in discrete blocks. Each block undergoes a diffusion-based denoising process, where a noisy block is iteratively refined into a clean block. This process relies on attention mechanisms that require access to key-value (KV) pairs from previous steps. To manage these KV pairs efficiently, the framework employs a block-wise KV memory management system. This system supports flexible access patterns, including range-based chunked access and index-based selective fetch, ensuring scalability and extensibility for future model variants that may require sliding-window or selective global context.
To accelerate computation and reduce memory pressure, the framework integrates a suite of parallelism techniques. Ulysses-style sequence parallelism partitions independent attention heads across multiple GPUs, while Ring Attention distributes attention operations in a ring topology, enabling scalable computation over long sequences. The choice between these strategies is adaptive, based on model architecture and communication overhead, ensuring optimal resource utilization. The framework also incorporates DAX quantization, which reduces the precision of KV cache tokens to minimize memory footprint without significant loss in quality.
The system further supports real-time video streaming, allowing dynamic control over narrative generation through user-provided signals such as prompts or motion inputs. When a new prompt is introduced for a subsequent video chunk, the framework clears the cross-attention cache to prevent interference from prior contexts, ensuring coherent and prompt-aligned generation. This capability is complemented by a built-in performance profiler that provides near-zero-overhead, customizable, and easy-to-use instrumentation for monitoring resource utilization during inference.
Experiment
- Introduces Video Drift Error (VDE), a unified metric inspired by MAPE, designed to quantify relative quality changes and temporal degradation in long-form video generation.
- Establishes five specific VDE variants (Clarity, Motion, Aesthetic, Background, and Subject) to assess drift across different visual and dynamic aspects, where lower scores indicate stronger temporal consistency.
- Integrates these drift metrics with five complementary quality dimensions from VBench (Subject Consistency, Background Consistency, Motion Smoothness, Aesthetic Quality, and Image Quality) to form a comprehensive evaluation protocol.
The authors use the LV-Bench dataset, which contains 1000 videos and is composed of 671 human instances, 171 animal instances, and 158 environment instances, to evaluate long-form video generation. Results show that the dataset spans diverse object classes and video counts, providing a comprehensive benchmark for assessing temporal consistency and visual quality in long-horizon video generation.
