Command Palette
Search for a command to run...
Collaboration latente dans les systèmes multi-agents
Collaboration latente dans les systèmes multi-agents
Résumé
Les systèmes multi-agents (MAS) étendent les grands modèles linguistiques (LLM) au-delà du raisonnement autonome d’un seul modèle, vers une intelligence de système coordonnée. Alors que les agents LLM existants dépendent d’une médiation textuelle pour le raisonnement et la communication, nous franchissons une étape importante en permettant aux modèles de collaborer directement dans l’espace latent continu. Nous introduisons LatentMAS, un cadre d’entraînement libre et end-to-end qui permet une collaboration purement latente entre agents LLM. Dans LatentMAS, chaque agent génère d’abord des pensées latentes auto-régressives à partir des embeddings cachés de la dernière couche. Un espace de mémoire de travail latente partagé préserve et transfère ensuite les représentations internes de chaque agent, assurant un échange d’information sans perte. Nous fournissons des analyses théoriques établissant que LatentMAS atteint une expressivité supérieure et une préservation sans perte de l’information, avec une complexité nettement réduite par rapport aux MAS basés sur le texte classiques. En outre, des évaluations empiriques sur 9 benchmarks complets couvrant le raisonnement mathématique et scientifique, la compréhension du sens commun et la génération de code montrent que LatentMAS surpasse systématiquement les baselines fortes à modèle unique et les MAS basés sur le texte, atteignant jusqu’à 14,6 % de précision supplémentaire, réduisant l’utilisation de jetons de sortie de 70,8 % à 83,7 %, et offrant une inférence end-to-end 4 à 4,3 fois plus rapide. Ces résultats démontrent que notre nouveau cadre de collaboration latente améliore la qualité du raisonnement de système tout en offrant des gains substantiels en efficacité, sans nécessiter d’entraînement supplémentaire. Le code et les données sont entièrement open source à l’adresse suivante : https://github.com/Gen-Verse/LatentMAS.
Summarization
Researchers from the University of Illinois Urbana-Champaign, Princeton University, and Stanford University introduce LatentMAS, a training-free framework that bypasses traditional text-based mediation by utilizing a shared latent working memory for direct embedding-level collaboration, thereby significantly enhancing inference speed and accuracy across mathematical, scientific, and coding benchmarks.
Introduction
Large Language Model (LLM)-based multi-agent systems have become essential for solving complex tasks ranging from mathematical reasoning to embodied decision-making. Typically, these systems rely on natural language text as the primary medium for coordination, requiring agents to decode and re-encode internal thoughts into discrete tokens to communicate. However, this text-based approach creates information bottlenecks and computational inefficiencies, as it fails to capture the full richness of a model's internal state and requires expensive decoding processes.
To address these inefficiencies, the authors introduce LatentMAS, a training-free framework that enables agents to collaborate entirely within the continuous latent space. By bypassing natural language decoding, the system integrates internal latent thought generation with a shared latent working memory, allowing agents to interact directly through their internal representations.
Key Innovations
- Enhanced Reasoning Expressiveness: The framework leverages continuous hidden states to encode and process richer semantic information than is possible with discrete text tokens.
- Lossless Communication: The authors utilize a shared latent working memory stored in layer-wise KV caches, enabling the direct and lossless transfer of context and thoughts between agents.
- Superior Efficiency: The approach significantly reduces computational overhead, delivering up to 4.3x faster inference and reducing output token usage by over 70% compared to text-based baselines.
Dataset
The authors evaluate the model using a diverse suite of benchmarks categorized into three primary domains. The composition and specific details for each subset are as follows:
Math & Science Reasoning
- GSM8K: Contains 8.5K grade-school math word problems designed to assess multi-step numerical reasoning and the ability to decompose natural language into arithmetic steps.
- AIME24: Consists of 30 competition-level problems from the 2024 American Invitational Mathematics Examination, covering algebra, geometry, number theory, and combinatorics with precise numeric answers.
- AIME25: Includes 30 additional problems from the 2025 exam. This set maintains the difficulty profile of AIME24 but introduces more multi-phase derivations and complex combinatorial constructions to test mathematical robustness.
- GPQA-Diamond: Represents the most difficult split of the GPQA benchmark with 198 graduate-level multiple-choice questions in physics, biology, and chemistry, emphasizing cross-disciplinary reasoning.
- MedQA: Comprises real medical licensing exam questions that require integrating textual context with domain-specific biomedical knowledge and clinical reasoning.
Commonsense Reasoning
- ARC-Easy: A subset of the AI2 Reasoning Challenge focusing on grade-school science questions to establish a baseline for foundational factual knowledge and basic inference.
- ARC-Challenge: Contains the most difficult items from the AI2 Reasoning Challenge. These adversarial questions require multi-hop reasoning, causal inference, and the systematic elimination of distractors.
Code Generation
- MBPP-Plus: Extends the original MBPP benchmark with broader input coverage and additional hidden test cases. It evaluates the generation of self-contained Python functions through strict execution-based testing.
- HumanEval-Plus: Augments HumanEval with denser and more challenging test suites to rigorously measure functional correctness and the ability to generalize beyond prompt examples.
Method
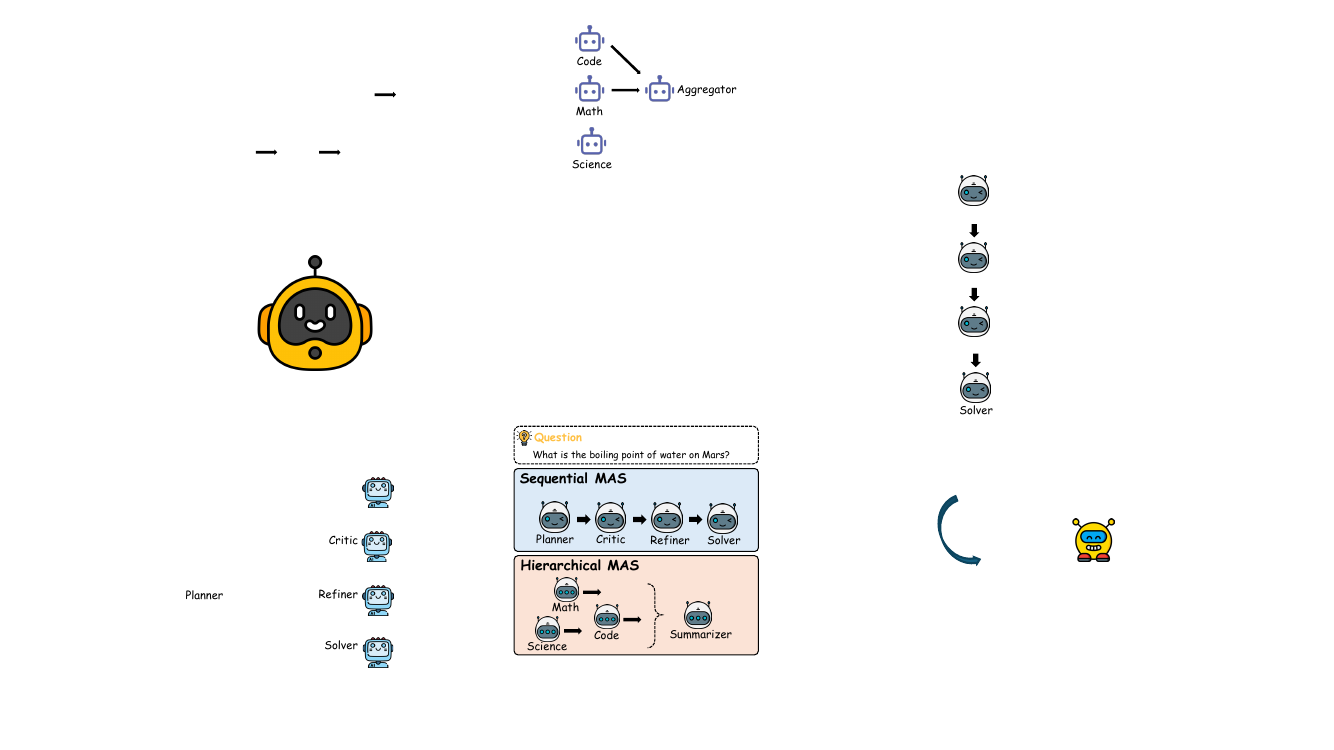
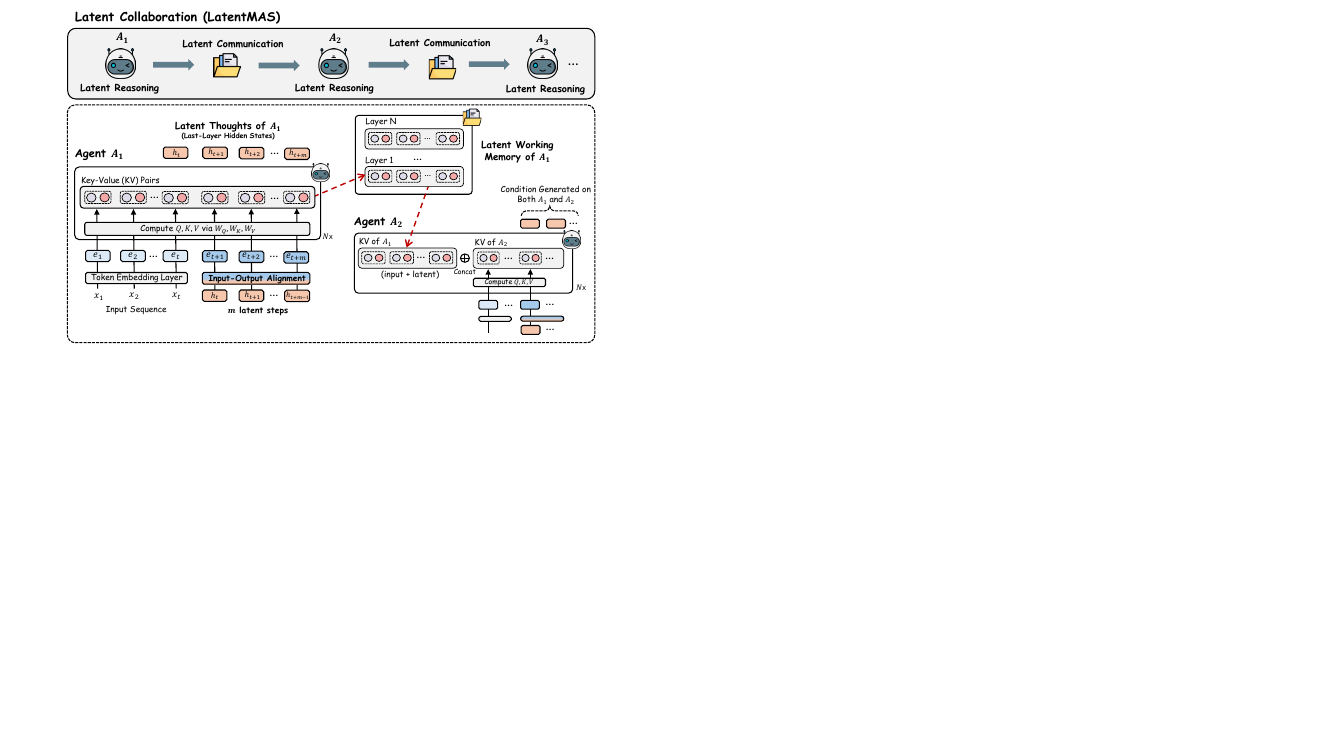
The authors introduce LatentMAS, an end-to-end framework for latent collaboration among large language model (LLM) agents, designed to enable efficient and expressive reasoning within a multi-agent system (MAS) without explicit text-based communication. The core of the framework revolves around two key innovations: latent thought generation within individual agents and a lossless latent working memory transfer mechanism for inter-agent communication. The overall architecture is illustrated in the framework diagram, which shows a sequence of agents, each performing latent reasoning followed by latent communication, enabling a system-wide collaboration process entirely within the latent space.
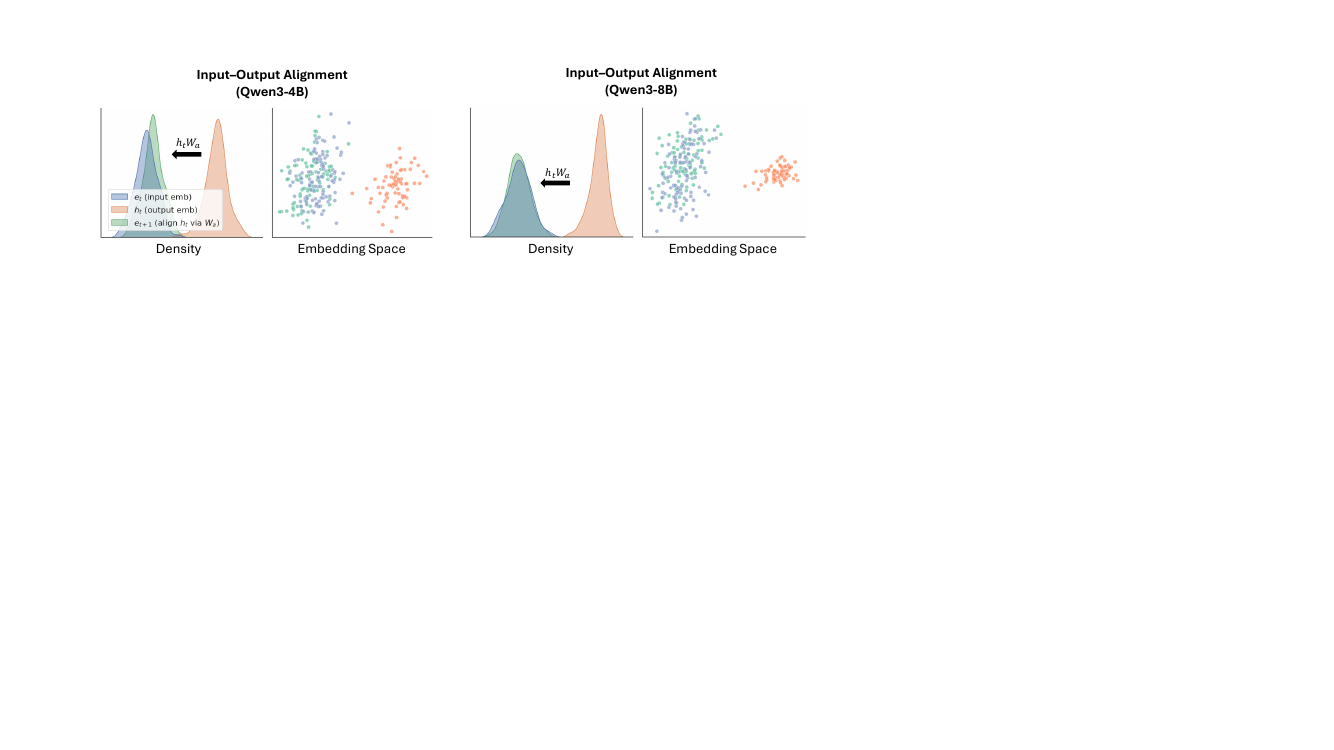
Each LLM agent in the system performs reasoning by generating a sequence of latent thoughts, which are continuous, high-dimensional representations derived from the model's last-layer hidden states. This process, detailed in Section 4, is an auto-regressive procedure that operates directly on the model's internal representations. Given an input sequence, the agent first processes it through its transformer layers to obtain the final-layer hidden state ht. Instead of decoding this state into a text token, the model auto-regressively appends ht as the next input embedding, repeating this process for m steps to generate a sequence of latent thoughts H=[ht+1,ht+2,…,ht+m]. This approach allows for super-expressive reasoning, as the latent thoughts can capture richer semantic structures than discrete text tokens. To ensure that these generated latent states are compatible with the model's input layer and avoid out-of-distribution activations, the authors employ a training-free linear alignment operator. This operator, defined by a projection matrix Wa, maps the last-layer hidden states back to the valid input embedding space. The matrix Wa is computed once as Wa≈Wout−1Win using a ridge regression, where Win and Wout are the model's input and output embedding matrices. This alignment ensures that the latent thoughts are distributed consistently with the model's learned input embeddings, preserving the integrity of the model's internal representations.
The collaboration between agents is facilitated by a novel latent working memory transfer mechanism, which is central to the framework's efficiency and expressiveness. As shown in the framework diagram, after an agent A1 generates its latent thoughts, it does not produce a text output. Instead, it extracts its complete Key-Value (KV) cache from all L transformer layers. This cache, which encapsulates the model's internal state from both the initial input and the generated latent thoughts, is defined as the agent's latent working memory. This memory is then transferred to the next agent, A2. Before A2 begins its own latent reasoning, it integrates the received memory by performing a layer-wise concatenation, prepending the K and V matrices from A1 to its own existing KV cache. This allows A2 to condition its reasoning on the full context of A1's output without any loss of information. Theorem 2 formally establishes that this mechanism guarantees information fidelity equivalent to direct text-based input exchange, ensuring that the collaborative process is lossless. The framework is agnostic to the specific MAS design, and can be applied to both sequential and hierarchical architectures, as illustrated in the figure showing the two settings.
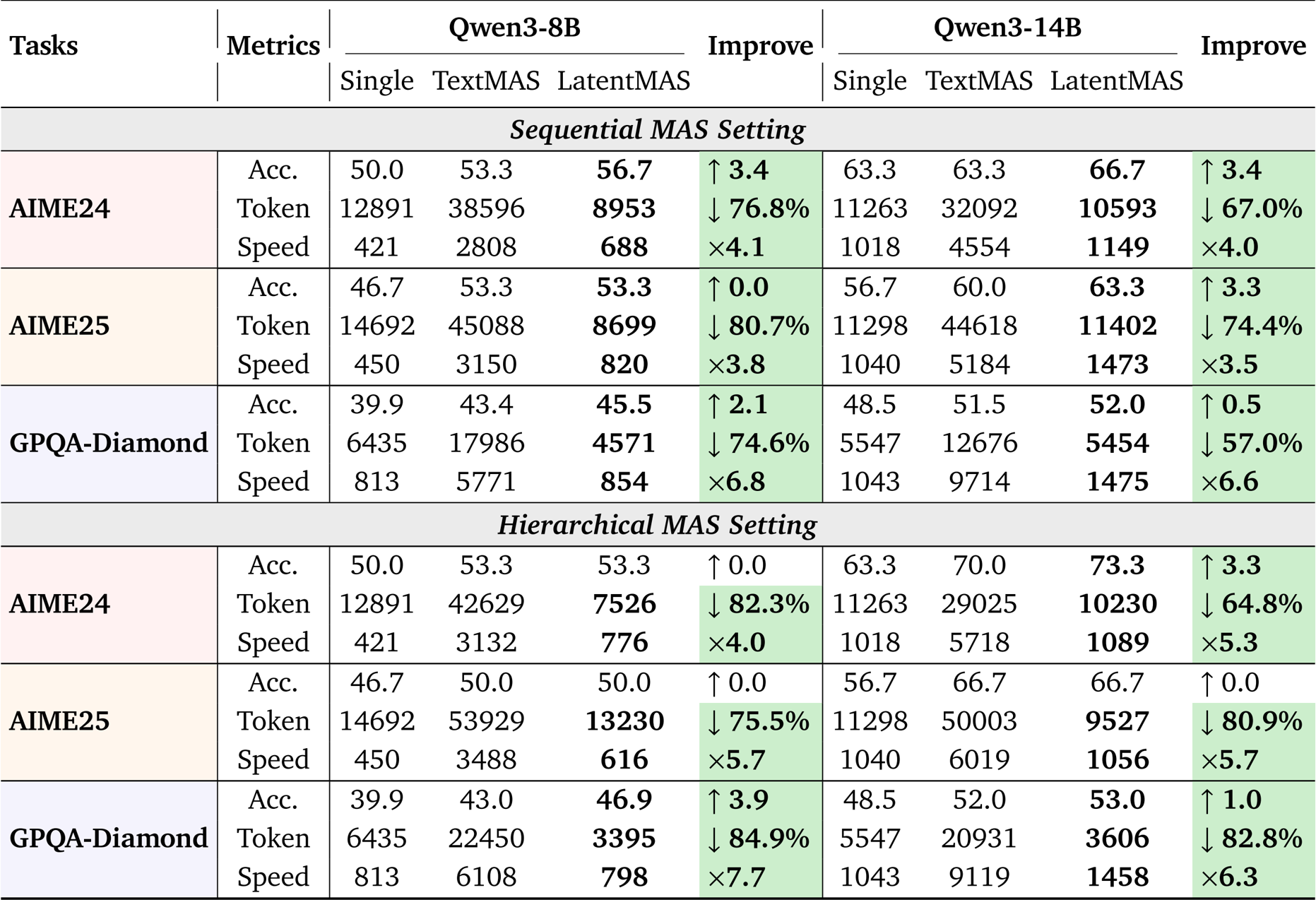
Experiment
- Comprehensive evaluation across nine benchmarks (including GSM8K, MedQA, and HumanEval-Plus) validated LatentMAS against single-agent and text-based multi-agent systems (MAS) using Qwen3 backbones.
- In terms of accuracy, LatentMAS improved over single-model baselines by an average of 13.3% to 14.6% and surpassed text-based MAS by 2.8% to 4.6%.
- Efficiency experiments demonstrated 4x to 4.3x faster inference speeds and a token usage reduction of over 70% compared to text-based MAS, achieving up to a 7x speedup against vLLM-optimized baselines.
- Analysis of latent representations confirmed they encode semantics similar to correct text responses but with greater expressiveness, while the input-output realignment mechanism contributed accuracy gains of 2.3% to 5.3%.
- Ablation studies on latent step depth revealed that performance consistently peaks between 40 and 80 steps, establishing an optimal range for balancing accuracy and efficiency.
The authors use LatentMAS to evaluate its performance across multiple benchmarks under sequential and hierarchical MAS settings, comparing it against single LLM agents and text-based MAS baselines. Results show that LatentMAS consistently achieves higher accuracy while significantly reducing token usage and improving inference speed, with average gains of 14.6% and 13.3% over single and text-based MAS, respectively, and up to 4.3× faster inference speed compared to text-based methods.
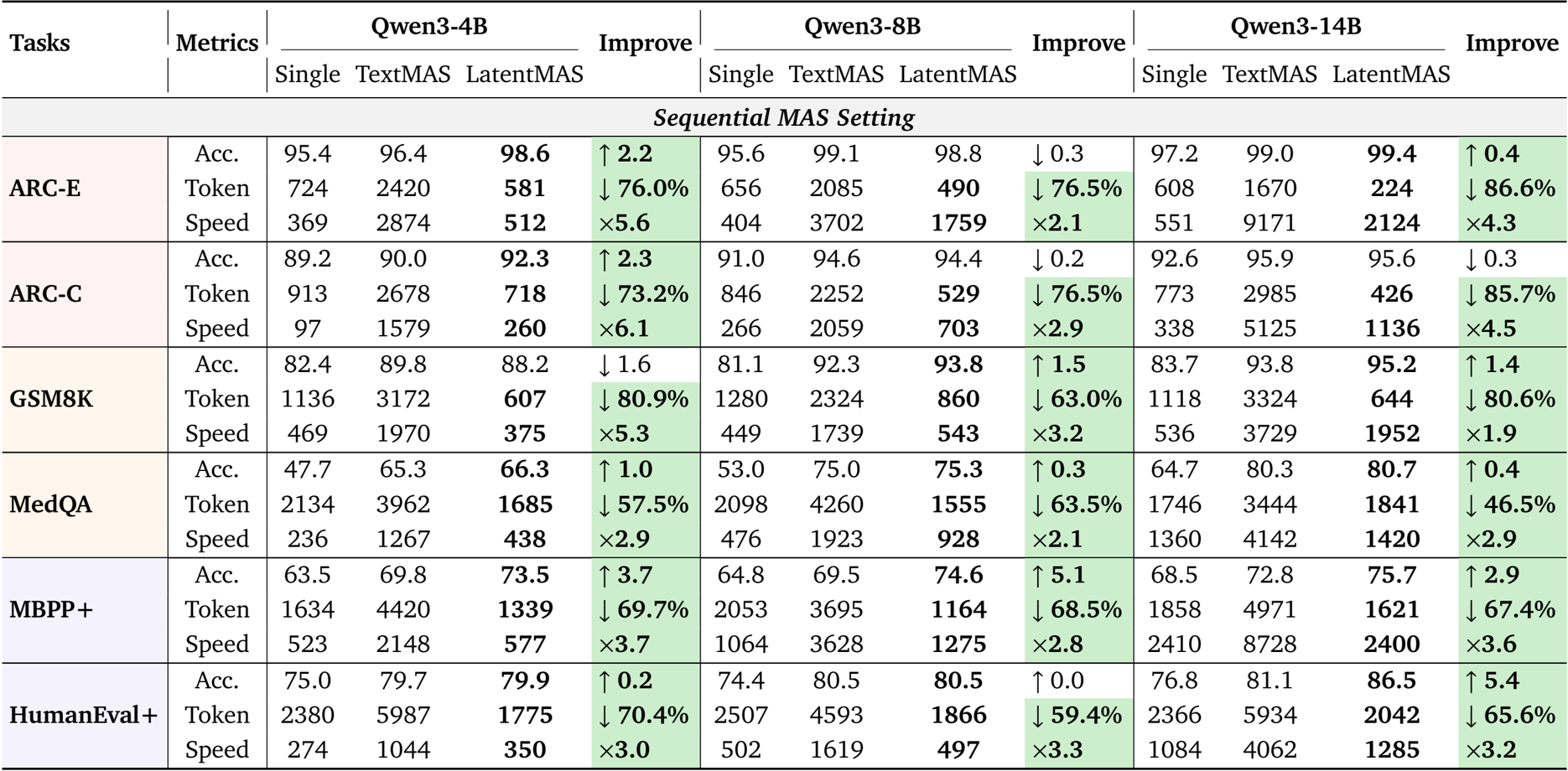
The authors use LatentMAS to evaluate performance across multiple benchmarks under hierarchical and sequential MAS settings, comparing it against single LLM agents and text-based MAS baselines. Results show that LatentMAS consistently improves task accuracy while significantly reducing token usage and increasing inference speed, with average gains of 14.6% and 13.3% over single and text-based MAS, respectively, and up to 4.3× faster inference speed compared to text-based methods.
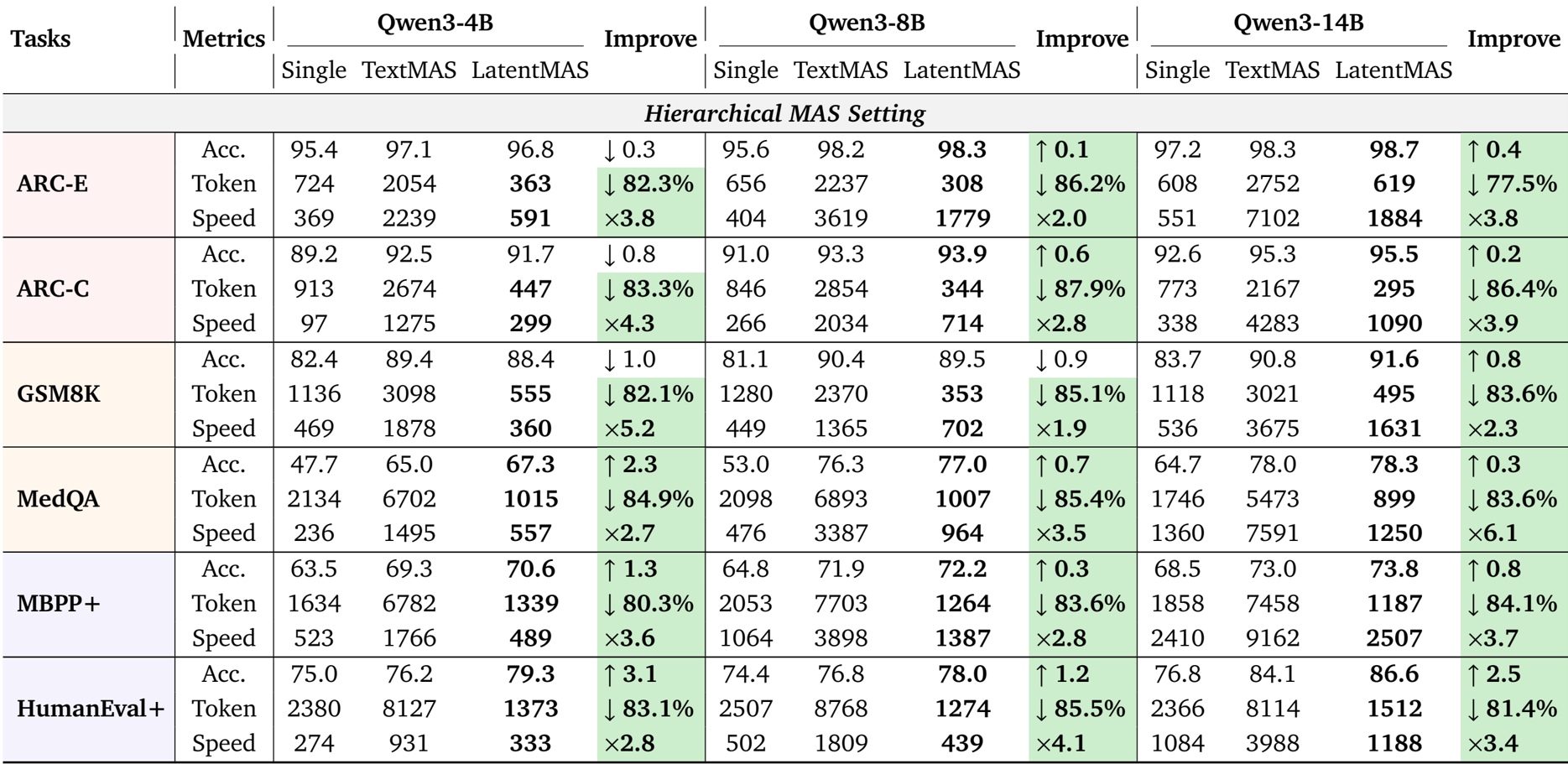
The authors use LatentMAS to evaluate its performance against single-model and text-based multi-agent systems across multiple reasoning tasks. Results show that LatentMAS achieves higher accuracy and significantly reduces token usage while improving inference speed compared to text-based methods, with consistent gains across different model sizes and MAS settings.