Command Palette
Search for a command to run...
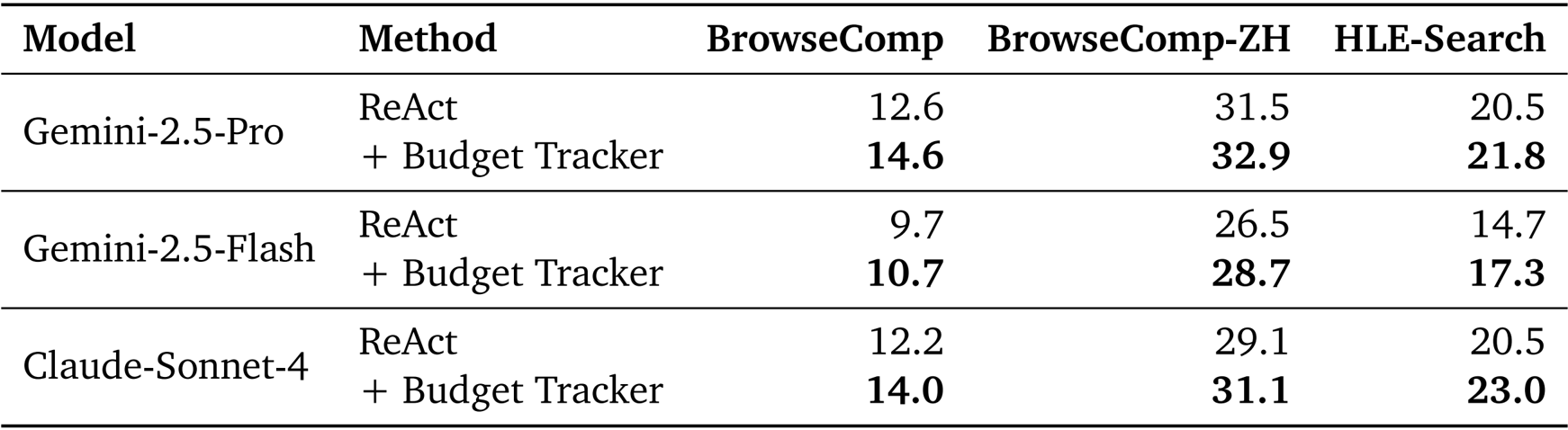
L'utilisation d'outils tenant compte du budget permet une mise à l'échelle efficace de l'Agent.
L'utilisation d'outils tenant compte du budget permet une mise à l'échelle efficace de l'Agent.
Résumé
Voici la traduction du texte en français, respectant le style académique et la terminologie technique appropriée :La mise à l'échelle du calcul au moment du test (test-time computation) améliore les performances sur différentes tâches pour les grands modèles de langage (LLM), une approche qui a également été étendue aux agents augmentés par des outils. Pour ces agents, la mise à l'échelle implique non seulement de « penser » en tokens, mais aussi d'« agir » via des appels d'outils. Le nombre d'appels d'outils délimite directement l'interaction de l'agent avec l'environnement extérieur. Cependant, nous constatons que le simple fait d'accorder aux agents un budget d'appels d'outils plus important ne permet pas d'améliorer les performances, car ils manquent de « conscience budgétaire » et atteignent rapidement un plafond de performance.Pour y remédier, nous étudions comment mettre à l'échelle ces agents de manière efficace sous des budgets explicites d'appels d'outils, en nous concentrant sur les agents de recherche web. Nous introduisons d'abord le Budget Tracker, un module léger qui confère à l'agent une conscience continue de son budget, permettant une mise à l'échelle simple mais efficace. Nous développons ensuite BATS (Budget Aware Test-time Scaling), un cadre avancé qui exploite cette conscience pour adapter dynamiquement sa stratégie de planification et de vérification, décidant s'il faut « approfondir » une piste prometteuse ou « pivoter » vers de nouvelles voies en fonction des ressources restantes.Afin d'analyser la mise à l'échelle du rapport coût-performance de manière contrôlée, nous formalisons une métrique de coût unifiée qui comptabilise conjointement la consommation de tokens et celle des outils. Nous fournissons la première étude systématique sur les agents sous contrainte budgétaire, démontrant que les méthodes conscientes du budget produisent des courbes de mise à l'échelle plus favorables et repoussent la frontière de Pareto coût-performance. Nos travaux offrent des perspectives empiriques vers une compréhension plus transparente et fondée sur des principes de la mise à l'échelle des agents augmentés par des outils.
Summarization
Researchers from UC Santa Barbara, Google, and New York University introduce BATS, a framework for tool-augmented web search agents that leverages a Budget Tracker to dynamically adapt planning and verification strategies based on remaining resources, effectively pushing the cost-performance Pareto frontier beyond the limits of simple tool-call scaling.
Introduction
Scaling test-time compute has proven effective for improving LLM reasoning, prompting a shift toward applying these strategies to tool-augmented agents that interact with external environments like search engines. In this context, performance relies not just on internal "thinking" (token generation) but also on "acting" (tool calls), where the number of interactions determines the depth and breadth of information exploration.
However, standard agents lack inherent budget awareness; they often perform shallow searches or fail to utilize additional resources effectively, hitting a performance ceiling regardless of the allocated budget. Unlike text-only reasoning where token counts are the primary constraint, tool-augmented agents face the unique challenge of managing external tool-call costs without explicit signals to spend them strategically.
To address this, the authors introduce a systematic framework for budget-constrained agent scaling, focusing on maximizing performance within a fixed allowance of tool calls and token consumption.
Key innovations include:
- Budget Tracker: A lightweight, plug-and-play module compatible with standard orchestration frameworks that provides agents with a continuous signal of resource availability to prevent inefficient spending.
- BATS Framework: A dynamic system that adapts planning and verification strategies in real time, allowing the agent to decide whether to "dig deeper" into a lead or "pivot" to alternative paths based on the remaining budget.
- Unified Cost Metric: A formalized method that jointly accounts for the economic costs of both internal token consumption and external tool interactions, enabling a transparent evaluation of the true cost-performance trade-off.
Method
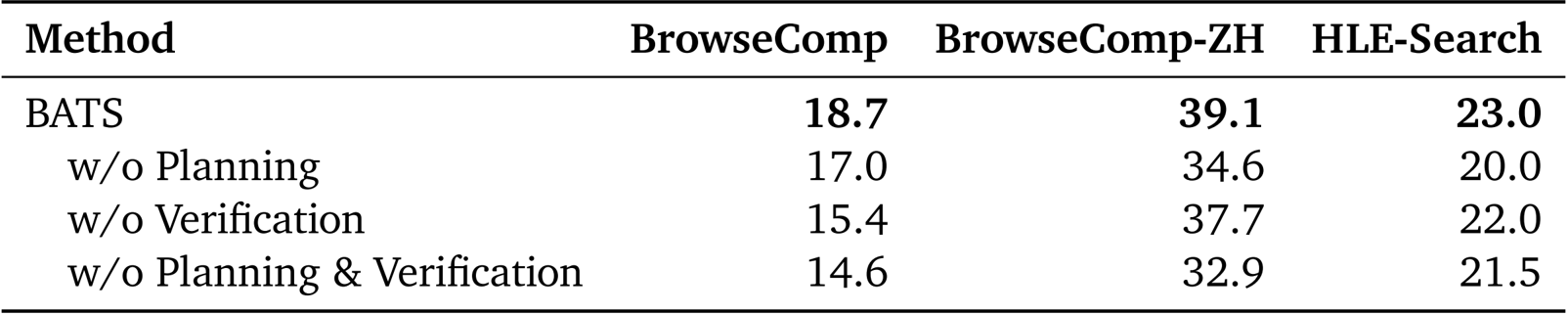
The authors propose BATS, a Budget-Aware Test-time Scaling framework for tool-augmented agents operating under explicit budget constraints. The core design principle of BATS is budget awareness, which is integrated throughout the agent's reasoning and action selection process. As shown in the framework diagram, the agent begins by receiving a question and a per-tool budget. The process starts with internal reasoning, which is augmented by a structured planning module that generates a tree-structured plan. This plan acts as a dynamic checklist, recording step status, resource usage, and allocation, and guiding future actions. The agent then iterates through a loop of reasoning, tool calls, and processing tool responses, continuously updating its internal state based on the new information and the remaining budget. When a candidate answer is proposed, a self-verification module evaluates the reasoning trajectory and the current budget status. This module performs a constraint-by-constraint backward check to assess whether the answer satisfies the question's requirements. Based on this analysis and the remaining budget, the verifier makes a strategic decision: to declare success if all constraints are satisfied, to continue exploration if the plan is salvageable and budget permits, or to pivot to a new direction if the current path is a dead end or the budget is insufficient. If the decision is to continue or pivot, the module generates a concise summary of the trajectory, which replaces the raw history in context to reduce length and maintain grounding. The iterative process terminates when any budgeted resource is exhausted. Finally, an LLM-as-a-judge selects the best answer from all verified attempts. 
The BATS framework incorporates budget awareness through a lightweight, plug-and-play module called the Budget Tracker. This module is designed to be a simple, prompt-level addition that surfaces real-time budget states within the agent's reasoning loop. At the beginning of the process, the tracker provides a brief policy guideline describing the budget regimes and corresponding tool-use recommendations. At each subsequent iteration, the tracker appends a budget status block showing the remaining and used budgets for each available tool. This persistent awareness enables the agent to condition its subsequent reasoning steps on the updated resource state, shaping its planning, tool-use strategy, and verification behavior. The authors demonstrate that this explicit budget signal allows the model to internalize resource constraints and adapt its strategy without requiring additional training. 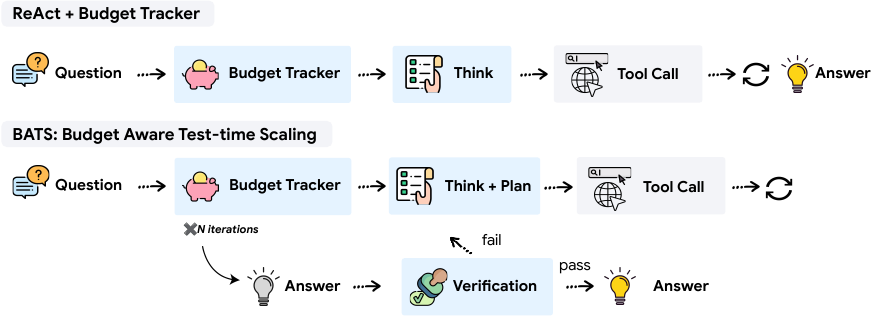
Budget-aware planning in BATS is achieved through a combination of constraint decomposition and structured dynamic planning. The agent is instructed to first perform constraint decomposition, categorizing the clues in the question into two types: exploration, which expands the candidate space, and verification, which validates specific properties. This initial step is critical for selecting an appropriate starting point and conserving budget. The agent then generates and maintains an explicit, tree-structured plan throughout execution. This plan acts as a dynamic checklist, recording step status, resource usage, and allocation, while guiding future actions. Completed, failed, or partial steps are never overwritten, ensuring a full execution trace and preventing redundant tool calls. The planning module adjusts exploration breadth and verification depth based on the current remaining budget, allowing BATS to maintain a controlled and interpretable search process while efficiently allocating available tool calls across exploration and verification subtasks. 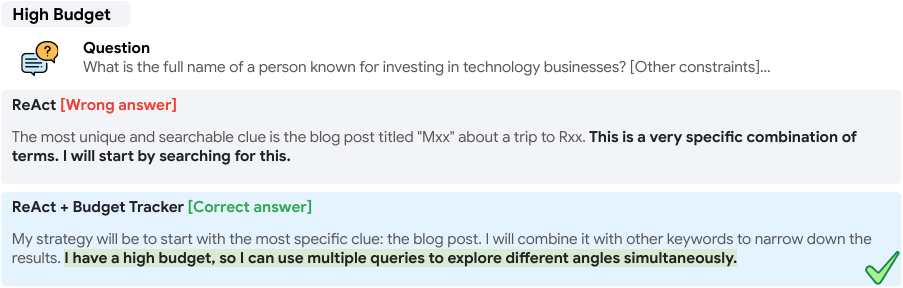
The self-verification module in BATS re-evaluates the reasoning trajectory and corresponding resource usage to make a strategic decision. This process begins with a constraint-by-constraint backward check, assessing each constraint to determine if it has been satisfied, contradicted, or remains unverifiable. Based on this analysis and the budget status, the module makes one of three decisions: SUCCESS if all constraints are satisfied; CONTINUE if several constraints remain unverifiable but the trajectory appears promising and the budget is sufficient; or PIVOT if contradictions are identified or the remaining budget cannot support further investigation. When the decision is to continue or pivot, the module generates a concise summary that replaces the raw trajectory in context. This includes key reasoning steps, intermediate findings, failure causes, and suggestions for optimization. By compressing the reasoning trajectory into a compact and informative summary, the verifier reduces context length while ensuring that subsequent attempts remain grounded in previously acquired information. This allows BATS to terminate useless trajectories early, continue promising ones efficiently, and maintain reliable progress toward the correct answer within strict budget constraints. 
Experiment
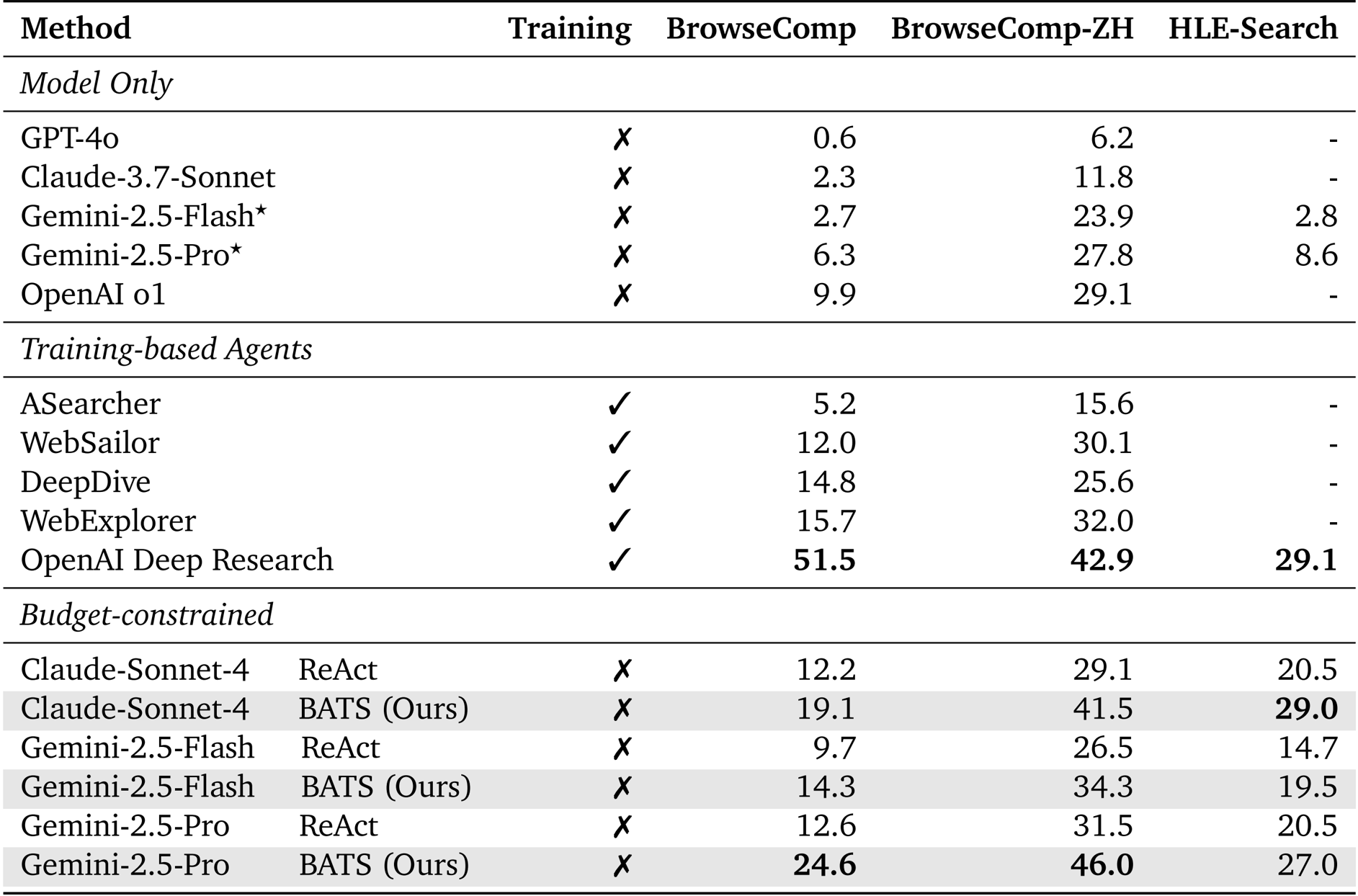
- Evaluated the Budget Tracker and BATS framework on BrowseComp, BrowseComp-ZH, and HLE-Search datasets, comparing them against ReAct and general-purpose base models.
- BATS consistently outperformed baselines using Gemini-2.5-Pro, achieving 24.6% accuracy on BrowseComp and 46.0% on BrowseComp-ZH without additional fine-tuning.
- The Budget Tracker demonstrated superior efficiency, matching ReAct's accuracy while using 40.4% fewer search calls and reducing overall costs by 31.3%.
- In test-time scaling experiments, the method avoided the performance plateaus observed in ReAct, successfully leveraging larger budgets to improve results in both sequential and parallel settings.
- Ablation studies validated the necessity of planning and verification modules, showing that removing verification caused a significant accuracy drop from 18.7% to 15.4% on BrowseComp.
- Cost-efficiency analysis revealed that BATS reached over 37% accuracy for approximately 0.23,whereastheparallelmajorityvotebaselinerequiredover0.50 to achieve comparable results.
The authors use the Budget Tracker to enhance the performance of ReAct-based agents under constrained tool budgets. Results show that adding the Budget Tracker consistently improves accuracy across all models and datasets, demonstrating that explicit budget awareness enables more strategic and effective tool use.
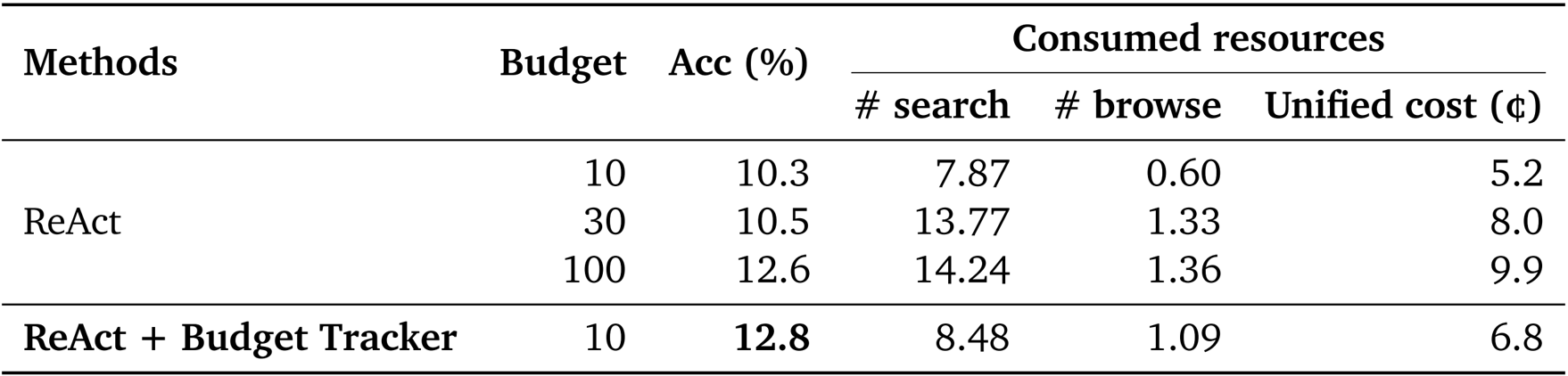
Results show that ReAct + Budget Tracker achieves higher accuracy (12.8%) than ReAct with a budget of 100 (12.6%) while using fewer search and browse tool calls and a lower unified cost. This demonstrates that explicit budget awareness enables more efficient and effective use of resources, allowing the agent to achieve better performance with significantly reduced tool usage and cost.
The authors use the Budget Tracker to enhance agent performance under constrained tool budgets, showing that BATS consistently outperforms the ReAct baseline across all datasets and models. Results show that BATS achieves higher accuracy with fewer tool calls and lower unified costs, demonstrating more efficient resource utilization and improved scalability.
The authors use BATS, a budget-aware framework, to evaluate the impact of its planning and verification modules on performance across three datasets. Results show that removing either module reduces accuracy, with the verification module having a more significant effect, particularly on BrowseComp, indicating both components are essential for effective agent behavior.