Command Palette
Search for a command to run...
Rapport technique Ovis-U1
Rapport technique Ovis-U1
Résumé
Dans ce rapport, nous présentons Ovis-U1, un modèle unifié de 3 milliards de paramètres intégrant la compréhension multimodale, la génération d’images à partir de texte et des capacités d’édition d’images. Construit sur la base de la série Ovis, Ovis-U1 incorpore un décodeur visuel fondé sur la diffusion associé à un raffineur de jetons bidirectionnel, permettant des tâches de génération d’images comparables aux meilleurs modèles actuels tels que GPT-4o. Contrairement à certains modèles précédents qui utilisent un MLLM (modèle linguistique multimodal) gelé pour les tâches de génération, Ovis-U1 repose sur une nouvelle approche d’entraînement unifié partant d’un modèle linguistique. Par rapport à un entraînement exclusivement axé sur la compréhension ou la génération, l’entraînement unifié permet d’obtenir des performances supérieures, démontrant ainsi l’amélioration apportée par l’intégration de ces deux tâches. Ovis-U1 atteint un score de 69,6 sur le benchmark académique multimodal OpenCompass, dépassant ainsi des modèles de pointe récents tels que Ristretto-3B et SAIL-VL-1.5-2B. En génération d’images à partir de texte, il excelle avec des scores respectifs de 83,72 et 0,89 sur les benchmarks DPG-Bench et GenEval. Pour l’édition d’images, il obtient des résultats de 4,00 et 6,42 sur les benchmarks ImgEdit-Bench et GEdit-Bench-EN. En tant que première version de la série de modèles unifiés Ovis, Ovis-U1 repousse les limites de la compréhension, de la génération et de l’édition multimodales.
One-sentence Summary
The authors propose Ovis-U1, a 3B-parameter unified model developed by Alibaba Group's Ovis Team, which integrates multimodal understanding, text-to-image generation, and image editing through a novel unified training approach leveraging a diffusion-based visual decoder and bidirectional token refiner—outperforming prior models like Ristretto-3B and SAIL-VL-1.5-2B on key benchmarks and enabling advanced multimodal capabilities in academic and creative applications.
Key Contributions
- Ovis-U1 is a 3-billion-parameter unified multimodal model that integrates text-to-image generation, image editing, and multimodal understanding, addressing the challenge of building a single model capable of both perceiving and creating visual content through a novel diffusion-based visual decoder and bidirectional token refiner.
- The model employs a unified training approach across six stages using diverse multimodal data, which jointly enhances both understanding and generation performance, demonstrating that collaborative training improves capabilities beyond task-specific models.
- Ovis-U1 achieves state-of-the-art results on key benchmarks, scoring 69.6 on OpenCompass, 83.72 on DPG-Bench, 0.89 on GenEval, 4.00 on ImgEdit-Bench, and 6.42 on GEdit-Bench-EN, outperforming recent models like Ristretto-3B and SAIL-VL-1.5-2B despite its compact size.
Introduction
The authors leverage recent advances in multimodal large language models (MLLMs), particularly GPT-4o, to address the growing demand for unified systems capable of both understanding and generating visual content. Prior work often relied on specialized models for distinct tasks like image generation or visual understanding, leading to fragmented pipelines and limited cross-task synergy. The key challenge lies in designing a visual decoder that integrates seamlessly with a language model and training a unified architecture that jointly optimizes both understanding and generation. To overcome this, the authors introduce Ovis-U1, a 3-billion-parameter unified model featuring a diffusion Transformer-based visual decoder and a bidirectional token refiner to strengthen text-image interaction. The model is trained via a unified strategy across six stages using diverse multimodal data, enabling it to excel in text-to-image generation, image editing, and visual understanding—outperforming some task-specific models despite its compact size. This work demonstrates that collaborative training significantly enhances both modalities, paving the way for more efficient, general-purpose multimodal AI systems.
Dataset
- The dataset for Ovis-U1 is composed of three main types of multimodal data: multimodal understanding data, text-to-image generation data, and image+text-to-image generation data.
- Multimodal understanding data combines publicly available sources—COYO, Wukong, Laion, ShareGPT4V, and CC3M—with in-house data. A custom preprocessing pipeline filters out noisy samples, improves caption quality, and balances data ratios for optimal training.
- Text-to-image generation data is drawn from Laion5B and JourneyDB. From Laion5B, samples with an aesthetic score above 6 are selected, and the Qwen model generates detailed image descriptions, forming the Laion-aes6 dataset.
- Image+text-to-image generation data includes four subtypes:
- Image editing: uses OmniEdit, UltraEdit, and SeedEdit.
- Reference-image-driven generation: leverages Subjects200K and SynCD for subject-driven tasks, and Style-Booth for style-driven tasks.
- Pixel-level controlled generation: includes canny-to-image, depth-to-image, inpainting, and outpainting from MultiGen_20M.
- In-house data: supplements public sources with custom data for style-driven generation, content removal, style translation, de-noising, de-blurring, colorization, and text rendering.
- The model is trained using a mixture of these data subsets, with carefully tuned ratios to balance task coverage and training stability.
- Data processing includes aesthetic filtering, automated caption generation via Qwen, and metadata construction to align image and text modalities. No explicit cropping is mentioned, but all data undergoes standard preprocessing to ensure consistency and quality.
Method
The authors leverage a unified architecture for Ovis-U1, a 3-billion-parameter model designed to integrate multimodal understanding, text-to-image generation, and image editing. The overall framework, illustrated in Figure 1, is built upon a large language model (LLM) backbone and incorporates specialized modules for visual processing and generation. The model's architecture is structured to enable seamless interaction between textual and visual modalities across both understanding and generation tasks.
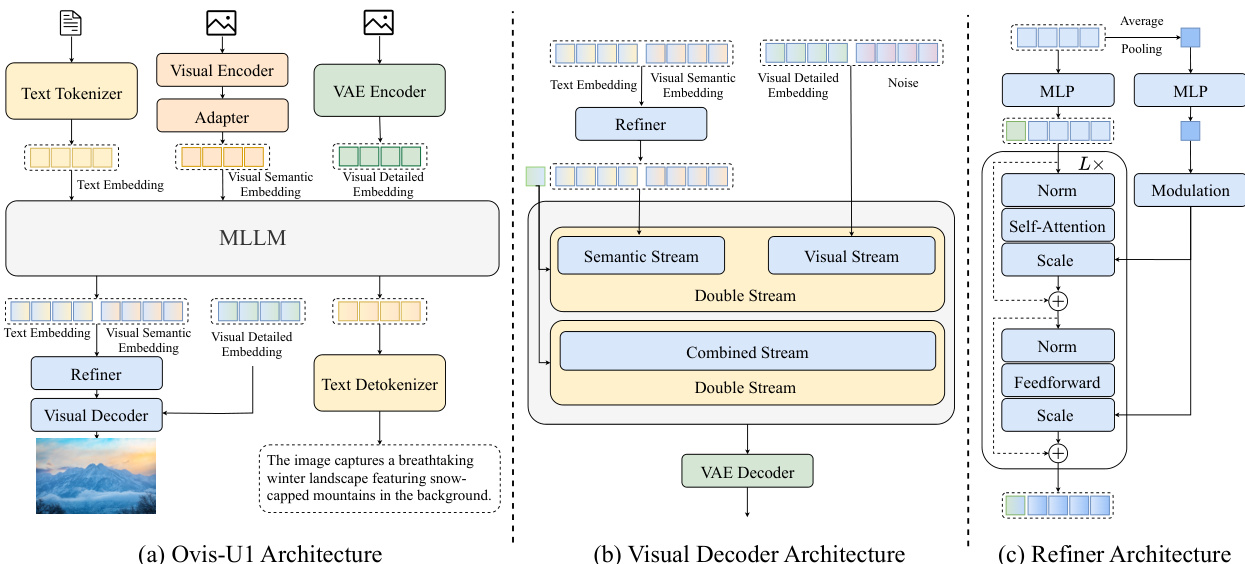
The core of the model is a multimodal large language model (MLLM) that processes both text and visual embeddings. The text input is first tokenized by a text tokenizer, producing text embeddings that are fed into the MLLM. For visual inputs, a vision encoder processes the image, and its output is passed through a visual adapter to generate visual semantic embeddings. These embeddings are then combined with the text embeddings within the MLLM. The visual adapter employs a pixel shuffle operation for spatial compression, followed by a linear head and a softmax function to map features into a probability distribution over a visual vocabulary. The final visual embedding is derived as a weighted average from a learnable embedding table based on this distribution. The MLLM generates a sequence of tokens, which are then processed by a text detokenizer to produce the final output text. For image generation, the MLLM's output is passed to a visual decoder, which reconstructs the image.
The visual decoder is a diffusion transformer, specifically a modified MMDiT architecture, which serves as the backbone for image generation. As shown in the figure below, the decoder operates on a double-stream architecture, processing both a semantic stream and a visual stream. The semantic stream receives the text embedding and the visual semantic embedding, which are concatenated to form a conditional input. The visual stream processes the visual detailed embedding, which is derived from the context image via a VAE encoder, and the noise input. These two streams are combined in a combined stream, which is then processed by the decoder to generate the final image. The decoder is initialized randomly and trained from scratch, with a reduced number of layers and attention heads compared to its larger counterparts to achieve a 1B parameter size. The VAE model from SDXL is used to encode and decode images, and it is frozen during training to preserve its generative capabilities.
To enhance the interaction between visual and textual information, the authors introduce a bidirectional token refiner. This module, detailed in the figure below, consists of two stacked transformer blocks with a modulation mechanism. The refiner takes as input the features from the last and second-to-last layers of the MLLM, which capture different levels of information granularity. By concatenating these features, the refiner can promote richer interaction between the visual and textual embeddings. The refiner also incorporates a learnable [CLS] token, which is concatenated with the MLLM's output embedding to capture global information, effectively replacing the need for an external CLIP model. The refiner's output is then fed back into the MLLM to refine the embeddings for improved generation quality.
Experiment
- Evaluated on image understanding, text-to-image generation, and image editing tasks using standardized benchmarks: OpenCompass Multi-modal Academic Benchmarks, CLIPScore, DPG-Bench, GenEval, ImgEdit-Bench, and GEdit-Bench-EN.
- On OpenCompass benchmarks, Ovis-U1 achieved an average score surpassing all 3B-parameter models, including InternVL2.5-2B, SAIL-VL-2B, and Qwen2.5-VL-3B, despite having only ~2B parameters dedicated to understanding.
- On GenEval and DPG-Bench, Ovis-U1 outperformed OmniGen2 and other open-source models, achieving competitive results with a 1B visual decoder, demonstrating strong text-to-image generation capability.
- On ImgEdit-Bench and GEdit-Bench-EN, Ovis-U1 achieved state-of-the-art performance, outperforming specialized image editing models such as Instruct-Pix2Pix, MagicBrush, and UltraEdit.
- Ablation studies confirmed the effectiveness of the token refiner design, with CLS-based refiners showing superior performance, and highlighted the benefits of unified training in enhancing both understanding and generation.
- Unified training improved understanding by 1.14 points on OpenCompass and boosted text-to-image generation by 0.77 on DPG-Bench through integration of image editing data.
- Classifier-free guidance experiments showed robust performance across varying CFG settings, with optimal configurations achieving a score of 4.13 on ImgEdit-Bench (CFG_img=2, CFG_txt=7.5), exceeding the baseline across benchmarks.
- Qualitative results demonstrated strong reasoning, fine-grained detail recognition, and high-fidelity image synthesis with precise, artifact-free editing.
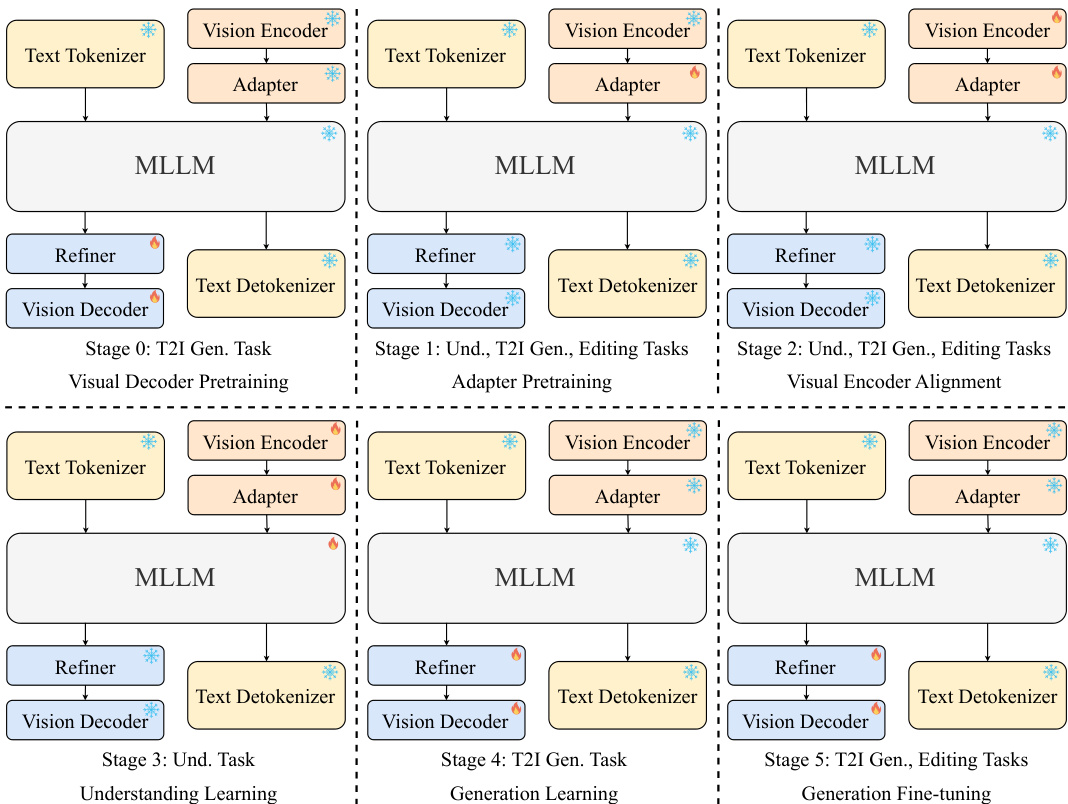
The authors use a modular architecture with a total of 3.64 billion parameters, where the LLM and vision decoder are the dominant components. The model is trained across multiple stages, with the vision encoder and refiner being trained in stages 2, 3, 4, and 5, while the LLM is trained only in stage 3.

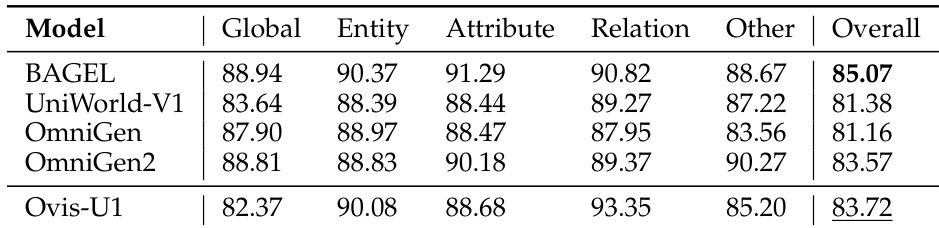
The authors use the OpenCompass Multi-modal Academic Benchmarks to evaluate the understanding capabilities of various models, including Ovis-U1. Results show that Ovis-U1 achieves an overall score of 83.72, outperforming models like BAGEL and UniWorld-V1 but falling slightly behind OmniGen2, which scores 83.57.
The authors use the OpenCompass Multi-modal Academic Benchmarks to evaluate the understanding capabilities of various models, including Ovis-U1. Results show that Ovis-U1 achieves the highest average score of 69.6 across all benchmarks, outperforming larger models such as GPT-4o and setting a new benchmark for models in the 3B parameter range.
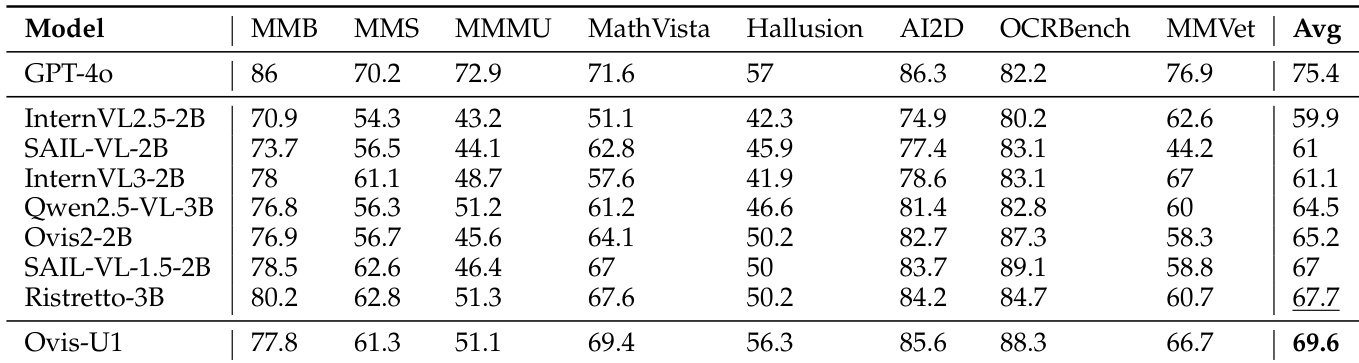
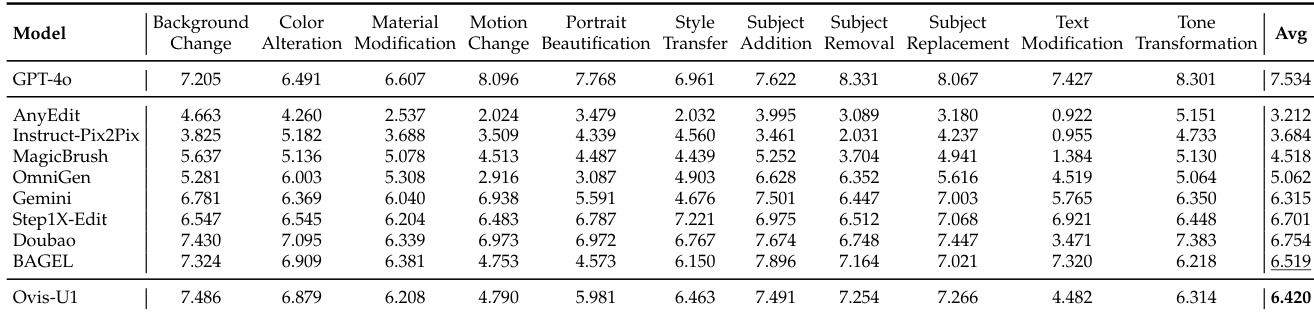
The authors use the GEdit-Bench and ImgEdit benchmarks to evaluate image editing capabilities, comparing Ovis-U1 against several state-of-the-art models. Results show that Ovis-U1 achieves the highest average score of 6.420 across all editing tasks, outperforming models like GPT-4o and BAGEL, demonstrating strong performance in handling diverse image editing instructions.
The authors use the OpenCompass Multi-modal Academic Benchmarks to evaluate the understanding capabilities of various models, including Ovis-U1. Results show that Ovis-U1 achieves the highest overall score of 0.89, outperforming models such as GPT-4o and OmniGen2 across multiple subtasks.