Command Palette
Search for a command to run...
Cette Décision a Aidé Fei-Fei Li À Établir Son Statut De Reine De l’IA.

En tant qu’ensemble de données le plus classique, ImageNet a conduit au développement rapide de la vision par ordinateur. Alors, quels défis cet ensemble de données a-t-il rencontrés lors de sa création ? Comment cela a-t-il affecté le développement de l’apprentissage profond ? Quel genre d’inspiration peut-il nous apporter aujourd’hui alors que l’apprentissage automatique est si populaire ?
Le célèbre informaticien Fei-Fei Li a déclaré à plusieurs reprises :L’intelligence artificielle va changer le monde, mais qui changera l’intelligence artificielle ?
La raison pour laquelle Fei-Fei Li joue un rôle important dans l'industrie et chaque mot qu'elle dit peut provoquer un émoi dans l'industrie n'est pas seulement due à ses nombreux résultats de recherche importants. Un point très important est qu’elle a initié la création du projet ImageNet, qui a joué un rôle important dans la promotion de l’ensemble de l’industrie.
ImageNet : l'ensemble de données qui a changé le développement de l'IA
La vision par ordinateur est l’une des meilleures directions pour le développement de l’IA à l’heure actuelle. ImageNet est un ensemble de données classique dans ce domaine. Il n’est pas exagéré de dire que sans ImageNet, la reconnaissance faciale serait aujourd’hui un luxe.
ImageNet a été introduit par Fei-Fei Li et al. dans un article au CVPR 2009. Le nombre et la qualité d'ImageNet sont sans précédent.Il contient 15 millions d'images annotées couvrant 22 000 catégories, visant à apprendre aux ordinateurs à reconnaître la diversité du monde..

Au cours de la dernière décennie, les articles de présentation d’ImageNet ont été publiés. 《ImageNet : une base de données d'images hiérarchique à grande échelle》L’impact est énorme. Sur Google Scholar, l'article est actuellementCité 11914 fois.
Un autre article décrit le défi des données ImageNet et les progrès de la recherche dans le domaine de la reconnaissance d’objets. 《Défi de reconnaissance visuelle à grande échelle ImageNet》, le nombre de citations a également atteint un niveau étonnant 11056 fois.

ImageNet est devenu une référence dans le domaine de la reconnaissance par vision par ordinateur et a également conduit l'industrie dans une ère d'ensembles de données de haute qualité : après 2010, de grandes entreprises telles que Google, Microsoft et plusieurs instituts de recherche ont commencé à lancer des ensembles de données de haute qualité.
ImageNet a également résisté à l’épreuve du temps. Lors de la conférence CVPR 2019,Récompensé pour la contribution la plus importante à la vision par ordinateur au cours de la dernière décennie——Le prix Longuet-Higgins a été décerné au journal qui a publié ImageNet sans aucun suspense.
Il y a dix ans, elle a anticipé l’importance des données
En 2009, la pensée dominante dans l’industrie portait encore sur les modèles, reflétés dans l’apprentissage automatique théorique codé à la main, et sur l’utilisation de méthodes mathématiques pour résoudre des problèmes courants.
Mais Fei-Fei Li a fait quelque chose de très « différent », comme elle l'a dit plus tard dans une interview,« La recherche doit s'inscrire dans la durée et avoir un impact. Ne vous contentez pas de suivre les tendances actuelles. Engagez-vous à mener des recherches solides et influentes. »

En 2006, Fei-Fei Li était professeur d'informatique à l'Université de l'Illinois à Urbana-Champaign. Elle a constaté que l’ensemble de la communauté étudiait de meilleures stratégies de spécification d’algorithmes, mais sous-estimait le rôle des données.
Grâce à une analyse sereine, elle a vu les inconvénients d’une telle démarche :Si les données utilisées sont produites à des fins de recherche et ne peuvent pas refléter le monde réel, même le meilleur algorithme n’aura aucun sens.
Cela l’a déterminée à travailler sur les données.
Il y a dix ans, les ordinateurs reconnaissaient les objets en capturant leurs caractéristiques et en donnant ensuite des résultats. Mais cela présente de nombreux inconvénients. Par exemple, le modèle abstrait par ordinateur fait souvent des erreurs lorsqu’il s’agit du même objet dans plusieurs postures et angles.
Le plus gros problème est l’unicité des données de formation. Si l'ordinateur ne reçoit qu'un seul type d'image, il sera entraîné à avoir une cognition « stéréotypée », et dès qu'il y aura un léger changement, il ne sera pas capable de le reconnaître.
Fei-Fei Li a découvert avec brio que ce problème constituerait le plus gros goulot d’étranglement de la vision par ordinateur.
La naissance d'ImagNet : une série de rebondissements
Pour résoudre ce problème, la réflexion de Fei-Fei Li s'est tournée vers les gens. Selon sa compréhension,Un enfant de trois ans est capable de reconnaître et de distinguer des objets parce qu’il a vu un grand nombre d’objets à travers ses yeux et a collecté un grand nombre d’images.
Si un grand nombre d’images étiquetées sont « transmises » à un ordinateur, l’IA pourrait être capable d’apprendre à reconnaître des images. Si nous développons selon cette idée, la clé réside dans les données, mais comment établir un système complet ?
À ce moment-là, un WordNet Le projet est apparu dans la vision de Fei-Fei Li.
Il s’agit d’une architecture anglaise construite sur la base d’une classification du vocabulaire. Chaque mot sera affiché en fonction de sa relation avec d’autres mots. L’ensemble du projet couvre les mots d’un grand nombre d’objets dans le monde.
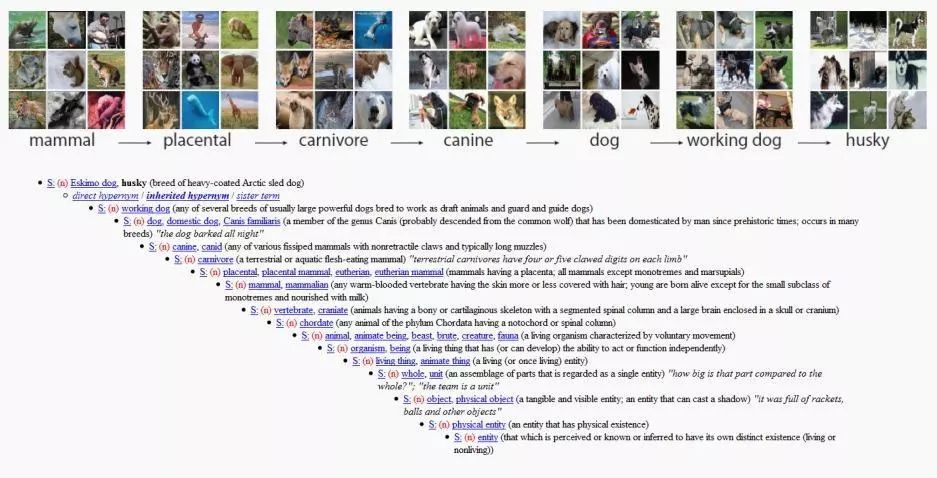
Après avoir rencontré la chercheuse de WordNet, la professeure Christiane Fellbaum, en 2006, Fei-Fei Li a eu la réponse : elle voulait imiter l'approche de WordNet et créer un grand ensemble de données pour fournir des exemples d'images pour chaque mot.
L'année suivante, alors qu'elle travaillait à l'Université de Princeton, Fei-Fei Li a lancé ImageNet projet et a commencé à former une équipe pour mener à bien cet énorme travail. Leurs objectifs sont :Obtenez suffisamment d’images annotées pour créer un système d’images complet et volumineux.
Mais la tâche était si énorme qu’ils voulaient initialement embaucher des étudiants pour trouver, filtrer et étiqueter des images en ligne et les ajouter à l’ensemble de données.
Mais Fei-Fei Li s’est vite rendu compte que cette méthode de collecte d’images était trop lente. Selon une estimation approximative, si une personne continue à marquer sans s’arrêter, sans manger ni boire, cela prendra des décennies.
Par hasard, Fei-Fei Li a découvert un autre tournant. Ils l'ont découvert par le biais d'une introduction.Amazon Mechanical Turk est une méthode de crowdsourcing en ligne.Sur cette plateforme, les employeurs peuvent embaucher de nombreuses personnes en ligne pour effectuer des notations simples.
En fin de compte, en utilisant le service de crowdsourcing d’Amazon,49 000 personnes de 167 pays ont passé deux ans et demiil est temps de terminer cet énorme projet.
Malgré de multiples défis tels que le manque de soutien, le financement insuffisant et le manque de main-d'œuvre, ImageNet est né grâce à sa persévérance.
En tant que nouveauté, ImageNet n’a pas été pris au sérieux au début. Lors de la conférence CVPR de 2009, l'article d'ImageNet n'a été utilisé que comme affiche de recherche et affiché dans un endroit discret.
Cette situation a été complètement inversée avec le concours de défis dérivé d'ImageNet.
Concours ILSVRC : Faites d'ImageNet un succès
Un an après la sortie d'ImageNet, grâce aux efforts de Fei-Fei Li et d'autres, Lancement du défi de reconnaissance visuelle à grande échelle ImageNet (ILSVRC).
L'ILSVRC est également connu sous le nom de concours ImageNet, qui a lieu chaque année depuis 2010. Dans ce concours, les participants utilisent l'ensemble de données ImageNet comme référence pour évaluer leurs performances en matière de détection d'objets à grande échelle et de classification d'images.
Bientôt, l’événement est devenu les Jeux olympiques des compétitions d’algorithmes de dépistage. Les grandes institutions l’ont utilisé comme terrain d’entraînement pour tester les avantages et les inconvénients de leurs propres algorithmes. Tout à coup, diverses avancées et réalisations ont émergé.
Mais le point fort du concours ImageNet est qu’il a favorisé l’essor des réseaux neuronaux et de l’apprentissage profond.
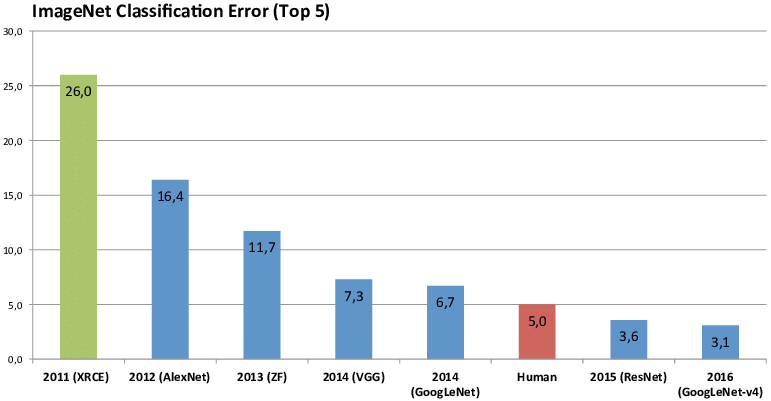
Hinton a conduit son équipe à participer au concours ImageNet 2012. Cette année-là, la méthode d’apprentissage profond utilisée par l’équipe de Hinton était bien en avance sur toutes les autres méthodes dans la compétition de reconnaissance d’images. Le modèle de structure de réseau neuronal convolutionnel profond qu'ils ont soumis Alexnet a amélioré ses performances de 10,8 %, soit 41% de plus que la deuxième place.

Quel est le concept de ceci ? À cette époque, l'amélioration des performances du 1% serait considérée comme une « contribution majeure », et le réseau neuronal, une méthode en sommeil depuis plus de dix ans, a en fait dépassé 10 points de pourcentage, ce qui a instantanément provoqué un énorme tremblement de terre.

Jusqu’à présent, les réseaux neuronaux profonds n’avaient jamais été entraînés avec des données à une telle échelle. Après AlexNet, les excellentes capacités des réseaux neuronaux profonds ont été pleinement démontrées avec l'aide d'ImagNet.
Deux ans plus tard, toutes les équipes participant au défi ImageNet ont utilisé l’apprentissage profond.
La compétition se termine, la recherche continue
En 2017, huit ans plus tard, le défi ImagNet a accompli sa mission : les taux d’erreur de reconnaissance des ordinateurs étaient inférieurs à ceux des humains. L'identification d'images matures ne représentait plus un défi et le nouveau voyage a mis en évidence la compréhension des images, de sorte que le concours s'est conclu avec succès.
Porté par ImageNet et le Challenge,La précision de l’ordinateur dans la classification des objets est passée de 71,8 % à 97,3 %., dépassant de loin le niveau humain.
En repensant au processus de création d’ImageNet, ce n’était pas une tâche courante à l’époque. Cependant, ce travail de « contre-tendance », grâce à la persévérance de Fei-Fei Li et d’autres, a finalement favorisé le progrès historique de l’IA. Parallèlement, Fei-Fei Li a également laissé la marque la plus significative dans le domaine de la vision par ordinateur grâce à ImageNet.
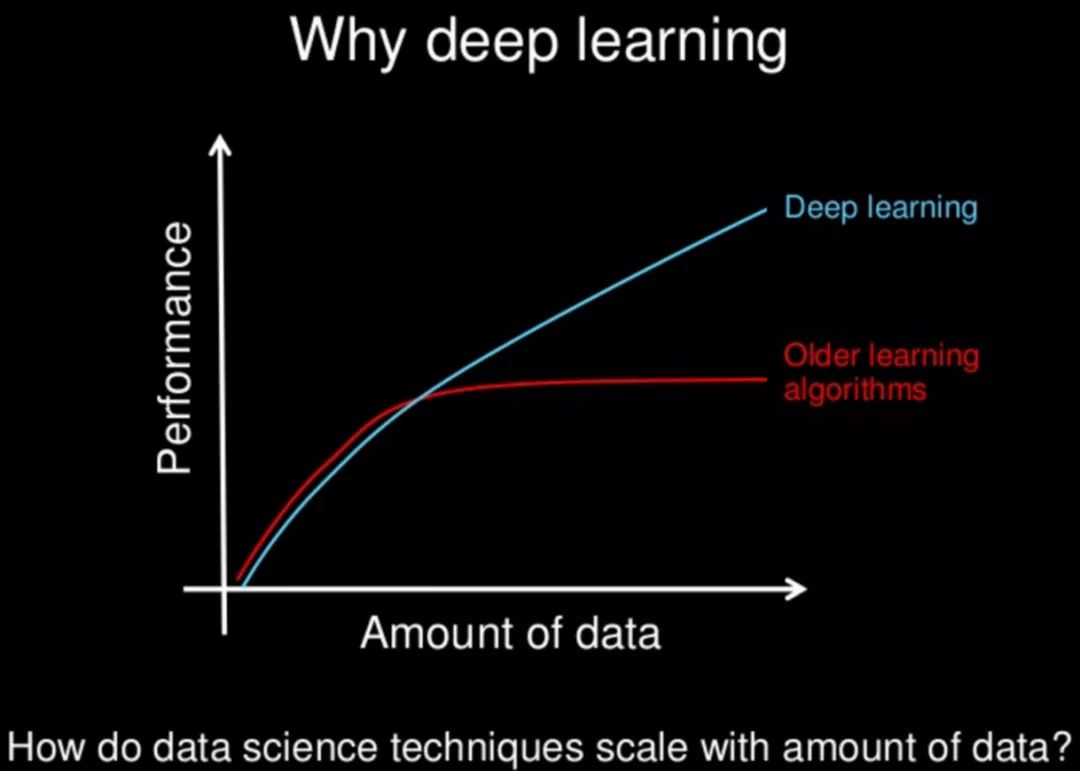
Si les données sont comparées au « carburant de fusée » de l’apprentissage automatique, ImageNet est sans aucun doute le premier et le plus important baril de carburant.
Comme l'a dit l'équipe de Fei-Fei Li,« Vous n’êtes pas obligé de faire la chose la plus populaire, mais vous devez faire quelque chose en laquelle vous croyez et qui aura un impact. »

Références :
1. Les données qui ont transformé la recherche en IA, et peut-être le monde
2. Comment nous apprenons aux ordinateurs à comprendre les images
4. Il n'y a eu qu'une seule avancée majeure en matière d'IA
5. Publications et citations d'ImageNet
6. Défi de reconnaissance visuelle à grande échelle
-- sur--








