Command Palette
Search for a command to run...
Une Nouvelle Étape Dans Le Domaine Des Interfaces cerveau-ordinateur : Les Pensées Parlent, Les Machines Interprètent
L’utilisation de réseaux neuronaux pour décoder les signaux neuronaux dans les zones cérébrales correspondantes lorsque les gens parlent, puis l’utilisation de réseaux neuronaux récurrents pour synthétiser les signaux en parole, peut aider les patients souffrant de troubles du langage à résoudre les problèmes de communication linguistique.
La « lecture des pensées » pourrait bien devenir une réalité.
Parler est une chose très courante pour la plupart des gens. Cependant, il y a encore beaucoup de personnes dans ce monde qui souffrent de ces maladies : accident vasculaire cérébral, traumatisme crânien, maladies neurodégénératives comme la maladie de Parkinson, la sclérose en plaques et la sclérose latérale amyotrophique (SLA ou maladie de Lou Gehrig), etc., et elles souffrent souvent dePerte irréversible de la capacité de parler.
Les scientifiques travaillent dur pour restaurer les fonctions humaines et réparer les nerfs, et l’interface cerveau-ordinateur (BCI) est un domaine clé.
L'interface cerveau-ordinateur fait référence à une connexion directe créée entre le cerveau humain ou animal et des appareils externes pour permettre l'échange d'informations entre le cerveau et l'appareil.
Mais il semble que l’interface cerveau-ordinateur ait toujours été un concept lointain. Aujourd'hui, un article publié dans la revue universitaire de renom NatureSynthèse vocale à partir du décodage neuronal des phrases parlées« (« Synthèse de la parole avec décodage neuronal des phrases parlées »), qui nous montre que la recherche dans le domaine des interfaces cerveau-ordinateur a fait un grand pas en avant.
Le sort des personnes souffrant de troubles de la parole
En fait, la recherche sur les interfaces cerveau-ordinateur se poursuit depuis plus de 40 ans. Cependant, les technologies les plus efficaces et les plus répandues cliniquement à ce jour ne sont que les technologies de restauration sensorielle telles que les implants cochléaires.
À ce jour, certaines personnes souffrant de graves troubles de la parole ne peuvent exprimer leurs pensées mot à mot qu’à l’aide d’appareils d’assistance.
Ces dispositifs d’assistance peuvent suivre des mouvements très subtils des yeux ou des muscles du visage et épeler des mots en fonction des gestes du patient.
Le physicien Stephen Hawking avait un jour installé un tel dispositif sur son fauteuil roulant.

À cette époque, Hawking s'appuyait sur les mouvements musculaires détectés par infrarouge pour émettre des commandes, confirmer les lettres scannées par le curseur de l'ordinateur et écrire les mots qu'il souhaitait. Ensuite, utilisez un appareil de synthèse vocale pour « prononcer » les mots. C'est à l'aide de ces technologies noires que nous sommes en mesure de lire son livre « Une brève histoire du temps ».
Cependant, avec un tel équipementLa génération de texte ou de parole synthétisée est laborieuse, sujette aux erreurs et très lente.Un maximum de 10 mots par minute est généralement autorisé. Hawking était déjà très rapide à l’époque, mais il ne pouvait épeler que 15 à 20 mots. La parole naturelle peut atteindre 100 à 150 mots par minute.
De plus, cette méthode est fortement limitée par la capacité de mouvement du corps de l'opérateur.
Pour résoudre ces problèmes, le domaine de l’interface cerveau-ordinateur étudie comment interpréter directement les signaux électriques correspondants du cortex cérébral en parole.
Les réseaux neuronaux interprètent les signaux cérébraux pour synthétiser la parole
Aujourd’hui, une avancée a été réalisée pour résoudre ce problème difficile.
Edward Chang, professeur de neurochirurgie à l'Université de Californie à San Francisco, et ses collègues ont proposé dans leur article « Synthèse de la parole à partir du décodage neuronal des phrases parlées » queL’interface cerveau-ordinateur créée peut décoder les signaux neuronaux générés lorsque les gens parlent et les synthétiser en parole.Le système peut générer 150 mots par minute, ce qui est proche de la vitesse de parole humaine normale.

L'équipe de chercheurs a recruté cinq patients épileptiques qui suivaient un traitement et leur a demandé de prononcer des centaines de phrases à voix haute pendant que leurs signaux d'électroencéphalogramme à haute densité (ECoG) étaient enregistrés et suivaient l'activité neuronale dans le cortex sensorimoteur ventral, le centre de production de la parole du cerveau.
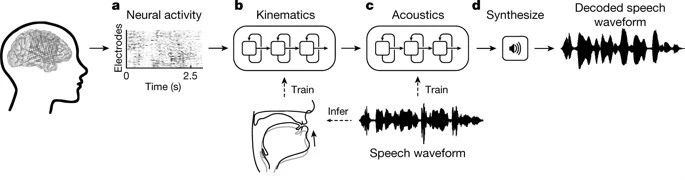
utiliserRéseaux de neurones récurrents (RNN), les chercheurs ont décodé les signaux neuronaux collectés en deux étapes.
Premièrement, ilsConvertir les signaux neuronaux en signaux qui représentent les mouvements des organes vocaux.Comprend les signaux cérébraux liés aux mouvements de la mâchoire, de la gorge, des lèvres et de la langue.
La deuxième étape consiste à convertir le signal en mots parlés en fonction des mouvements décodés des organes vocaux.

Au cours du processus de décodage, les chercheurs ont d’abord décodé les signaux électrogrammes continus provenant de la surface de trois régions du cerveau lorsque le patient parlait. Ces signaux d’électrogramme ont été enregistrés par des électrodes invasives.
Après le décodage, 33 types d'indicateurs caractéristiques du mouvement des organes vocaux sont obtenus, qui sont ensuite décodés en 32 paramètres de parole (y compris la hauteur, la sonorité, etc.), et enfin les ondes sonores de la parole sont synthétisées sur la base de ces paramètres.
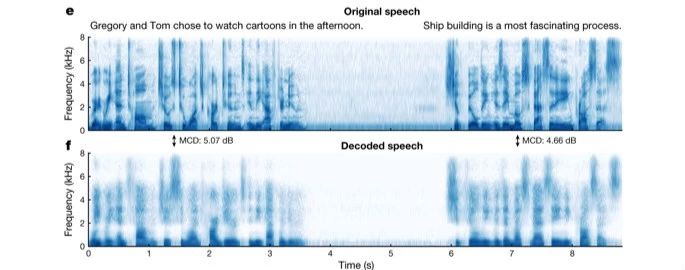
Pour analyser la précision de la parole synthétisée dans la reproduction de la parole réelle, les chercheurs ont comparé les caractéristiques sonores de la parole originale avec la parole synthétisée et ont constaté que la parole décodée par le réseau neuronal reproduisait assez complètement les phonèmes individuels des phrases originales prononcées par le patient, ainsi que les connexions naturelles et les pauses entre les phonèmes.
Les chercheurs ont ensuite utilisé le crowdsourcing pour demander aux internautes d’identifier la parole synthétisée par le décodeur. Le résultat final est que l’auditeur répète le contenu du discours synthétisé.Le taux de réussite est proche de 70%.
De plus, les chercheurs ont testé la capacité du décodeur à synthétiser la parole pour la parole silencieuse. Le testeur dit d’abord une phrase puis récite la même phrase en silence (avec des mouvements mais sans faire de bruit). Les résultats ont montré que le spectre vocal synthétisé par le décodeur pour les mouvements de parole silencieux était similaire au spectre vocal de la même phrase.
Jalon : Défis et attentes coexistent
« Cette étude montre pour la première fois que nous pouvons générer des phrases parlées complètes en fonction de l’activité cérébrale d’un individu », a déclaré Chang. « C'est passionnant. Cette technologie est à notre portée, et nous devrions être en mesure de concevoir des dispositifs cliniquement réalisables pour les patients souffrant de perte de langage. »
Gopala Anumanchipalli, premier auteur de l'article, a ajouté : « Je suis fier d'avoir réuni l'expertise en neurosciences, en linguistique et en apprentissage automatique pour participer à cette étape importante dans l'aide aux personnes souffrant de troubles neurologiques. »
Bien sûr, il reste encore de nombreux défis à relever pour parvenir véritablement à une synthèse vocale à 100 % dans l’interaction vocale de l’interface cerveau-ordinateur, comme par exemple si les patients peuvent accepter une chirurgie invasive pour installer des électrodes, si les ondes cérébrales de l’expérience sont les mêmes que celles des vrais patients, etc.
Cependant, à partir de cette étude, nous avons vuL’interface cerveau-ordinateur de synthèse vocale n’est plus seulement un concept.
Nous espérons qu’un jour, dans le futur, les personnes souffrant de troubles de la parole pourront retrouver la capacité de « parler » et d’exprimer leurs pensées le plus rapidement possible.


