Command Palette
Search for a command to run...
Modèle Léger 270M ! Gemma-3-270M-IT Se Concentre Sur l'interaction Texte Longue Et Légère ; Le Choix Idéal Pour Les Agents d'interface Utilisateur Multiplateformes ! AgentNet Couvre Plus De 200 sites web.

À mesure que l'échelle des paramètres des grands modèles continue d'augmenter, les exigences des utilisateurs en matière d'IA divergent progressivement : d'une part, ils ont besoin de modèles performants pour gérer des tâches complexes, et d'autre part, ils recherchent une expérience de conversation légère et pratique dans un environnement peu gourmand en ressources informatiques. Dans les longues conversations textuelles et les tâches quotidiennes,Les modèles traditionnels de grande taille nécessitent non seulement une puissance de calcul élevée, mais sont également sujets à des retards de réponse, à des pertes de contexte ou à des problèmes de génération incohérente, ce qui fait des modèles légers « utilisables, faciles à utiliser et fonctionnant bien » un problème qui doit être résolu de toute urgence.
Sur cette base, Google a lancé le modèle léger de réglage fin des instructions Gemma-3-270M-IT.Il ne dispose que de 270 millions de paramètres, mais il peut fonctionner sans problème dans un environnement de mémoire vidéo à carte unique de 1 Go, abaissant considérablement le seuil de déploiement local.Il prend également en charge une fenêtre contextuelle de 32 K jetons, ce qui lui permet de gérer de longues conversations textuelles et le traitement de documents. Grâce à des réglages spécifiques pour les sessions de questions-réponses quotidiennes et les tâches simples, le Gemma-3-270M-IT allie légèreté et efficacité, tout en garantissant la praticité des interactions conversationnelles.
Gemma-3-270M-IT montre une autre voie de développement : en plus de la tendance du « plus grand et plus fort »,Grâce à un support de contexte léger et long, il offre de nouvelles possibilités de déploiement en périphérie et d'applications inclusives.
Le site officiel d'HyperAI Hyperneuron a lancé la fonctionnalité « vLLM + Open WebUI deployment gemma-3-270m-it ». Venez l'essayer !
Utilisation en ligne:https://go.hyper.ai/kBjw3
Du 25 au 29 août, voici un bref aperçu des mises à jour du site officiel hyper.ai :
* Ensembles de données publiques de haute qualité : 12
* Sélection de tutoriels de haute qualité : 4
* Articles recommandés cette semaine : 5
* Interprétation des articles communautaires : 6 articles
* Entrées d'encyclopédie populaire : 5
* Principales conférences avec date limite en septembre : 5
Visitez le site officiel :hyper.ai
Ensembles de données publiques sélectionnés
1. Ensemble de données post-formation Nemotron-Post-Training-Dataset-v2 Ensemble de données post-formation
Nemotron-Post-Training-Dataset-v2 est une extension du corpus post-formation existant de NVIDIA. Cet ensemble de données étend les données SFT et RL à cinq langues cibles (espagnol, français, allemand, italien et japonais), couvrant des scénarios tels que les mathématiques, le codage, les STEM (sciences, technologie, ingénierie et mathématiques) et la conversation.
Utilisation directe : https://go.hyper.ai/lSIjR
2. Ensemble de données de pré-entraînement Nemotron-CC-v2
Nemotron-CC-v2 ajoute huit instantanés Common Crawl de 2024-2025 au corpus de pages web originales en anglais, et effectue une déduplication globale et un filtrage en anglais. Il utilise également Qwen3-30B-A3B pour synthétiser et reformuler le contenu des pages web, complété par des questions et réponses diversifiées, et traduit en 15 langues afin de renforcer le raisonnement logique multilingue et la préformation en connaissances générales.
Utilisation directe : https://go.hyper.ai/xRtbR
3.Ensemble de données d'échantillonnage Nemotron-Pretraining-Dataset-sample
L'échantillon de données de pré-formation Nemotron contient 10 sous-ensembles représentatifs sélectionnés à partir de différents composants du corpus complet SFT et de pré-formation, couvrant des données de questions-réponses de haute qualité, des extraits mathématiquement ciblés, des métadonnées de code et des données d'instructions de style SFT, adaptées à la révision et aux expériences rapides.
Utilisation directe : https://go.hyper.ai/xzwY5
4. Ensemble de données de code Nemotron-Pretraining-Code-v1
Nemotron-Pretraining-Code-v1 est un ensemble de données de code à grande échelle, organisé et compilé sur GitHub. Ce jeu de données a été filtré par déduplication en plusieurs étapes, application des licences et contrôles qualité heuristiques. Il contient des paires questions-réponses de code générées par LLM dans 11 langages de programmation.
Utilisation directe: https://go.hyper.ai/DRWAw
5. Ensemble de données de réglage fin supervisé Nemotron-Pretraining-SFT-v1
Nemotron-Pretraining-SFT-v1 est conçu pour les STEM (sciences, technologie, ingénierie et mathématiques), les études, le raisonnement logique et les scénarios multilingues. Il est généré à partir de supports mathématiques et scientifiques de haute qualité et combine des textes universitaires de niveau master avec des données SFT pré-entraînées pour construire des questions complexes à choix multiples et analytiques (avec réponses/réflexions complètes), couvrant une variété de tâches, notamment les mathématiques, le codage, la culture générale et le raisonnement logique.
Utilisation directe : https://go.hyper.ai/g568w
6. Ensemble de données de pré-entraînement mathématique Nemotron-CC-Math
Nemotron-CC-Math est un jeu de données pré-entraîné de haute qualité et à grande échelle, axé sur les mathématiques. Contenant 133 milliards de jetons, il préserve la structure des équations et du code tout en unifiant le contenu mathématique dans un format LaTeX modifiable. Il s'agit du premier jeu de données à couvrir de manière fiable un large éventail de formats mathématiques (y compris ceux à longue traîne) à l'échelle du web.
Utilisation directe : https://go.hyper.ai/aEGc4
7. Ensemble de données de génération d'images synthétiques Echo-4o-Image
L'ensemble de données Echo-4o-Image, généré par GPT-4o, contient environ 179 000 exemples répartis sur trois types de tâches : exécution d'instructions complexes (environ 68 000 exemples) ; génération de fantaisie hyperréaliste (environ 38 000 exemples) ; et génération d'images multi-références (environ 73 000 exemples). Chaque exemple est constitué d'une grille d'images 2×2 d'une résolution de 1 024×1024, contenant des informations structurées sur le chemin d'accès à l'image, ses caractéristiques (attributs/sujets) et l'invite générée.
Utilisation directe : https://go.hyper.ai/uLJEh

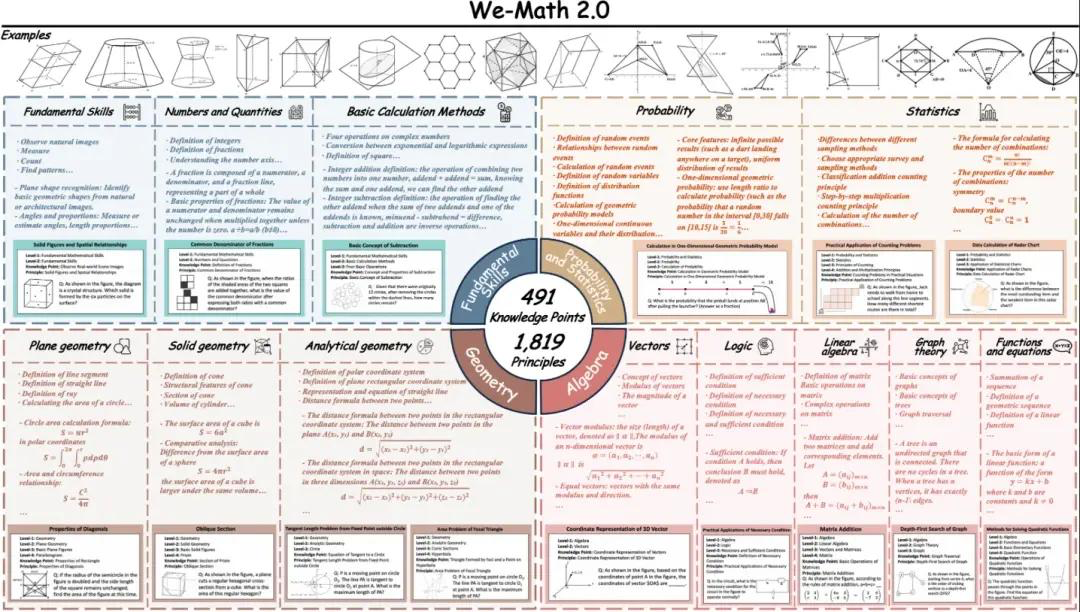
8. Ensemble de données de référence pour le raisonnement mathématique visuel standard We-Math2.0
La norme We-Math2.0 établit un espace d'étiquetage unifié autour de 1 819 principes définis avec précision. Chaque problème est explicitement étiqueté avec le principe et rigoureusement organisé, ce qui permet une couverture globale large et équilibrée, mettant notamment en valeur les sous-domaines et types de problèmes mathématiques jusqu'alors sous-représentés. L'ensemble de données utilise une conception à double expansion : plusieurs figures par problème et plusieurs questions par figure.
Utilisation directe : https://go.hyper.ai/VlqK1
9. Ensemble de données de tâches d'opération de bureau AgentNet
AgentNet est le premier ensemble de données à grande échelle sur les trajectoires d'utilisation des ordinateurs de bureau. Il est conçu pour prendre en charge et évaluer les agents de manipulation d'interface utilisateur graphique multiplateformes et les modèles vision-langage-action. Cet ensemble de données contient 22 600 trajectoires d'utilisation de tâches informatiques annotées manuellement sur Windows, macOS et Ubuntu, ainsi que sur plus de 200 applications et sites web. Les scénarios se répartissent en quatre catégories : bureautique, professionnel, quotidien et système.
Utilisation directe : https://go.hyper.ai/3DGDs
10. Ensemble de données de référence pour la collecte d'informations WideSearch
WideSearch est le premier ensemble de données de référence spécialement conçu pour la collecte d'informations sur un large éventail de domaines. Ce référentiel comprend 200 questions de haute qualité (100 en anglais et 100 en chinois), soigneusement sélectionnées et analysées à partir de requêtes réelles d'utilisateurs. Ces questions proviennent de plus de 15 domaines différents.
Utilisation directe : https://go.hyper.ai/36kKj
11. Ensemble de données de génération de codes multimodaux MCD
MCD contient environ 598 000 exemples/paires de haute qualité, organisés selon un format de suivi de commandes. Il couvre une variété de modalités d'entrée (texte, images, code) et de sortie (code, réponses, explications), ce qui le rend idéal pour les tâches de compréhension et de génération de code multimodal. Les données incluent : du code HTML amélioré, des graphiques, des questions/réponses et des algorithmes.
Utilisation directe : https://go.hyper.ai/yMPeD
12. Ensemble de données post-formation Llama-Nemotron Ensemble de données post-formation
L'ensemble de données post-entraînement Llama-Nemotron est un ensemble de données post-entraînement à grande échelle conçu pour améliorer les capacités mathématiques, de programmation, de raisonnement général et de suivi des instructions des modèles de la famille Llama-Nemotron pendant les phases post-entraînement (par exemple, SFT et RL). Cet ensemble de données combine les données des phases de réglage fin supervisé et d'apprentissage par renforcement.
Utilisation directe : https://go.hyper.ai/Vk0Pk
Tutoriels publics sélectionnés
1. Microsoft VibeVoice-1.5B redéfinit la technologie TTSlimite
VibeVoice-1.5B est un nouveau modèle de synthèse vocale (TTS) qui génère des conversations audio expressives, longues et multi-locuteurs, comme des podcasts. VibeVoice traite efficacement les longues séquences audio tout en conservant une haute fidélité et prend en charge la synthèse vocale jusqu'à 90 minutes avec jusqu'à quatre locuteurs différents.
Opération en ligne:https://go.hyper.ai/Ofjb1
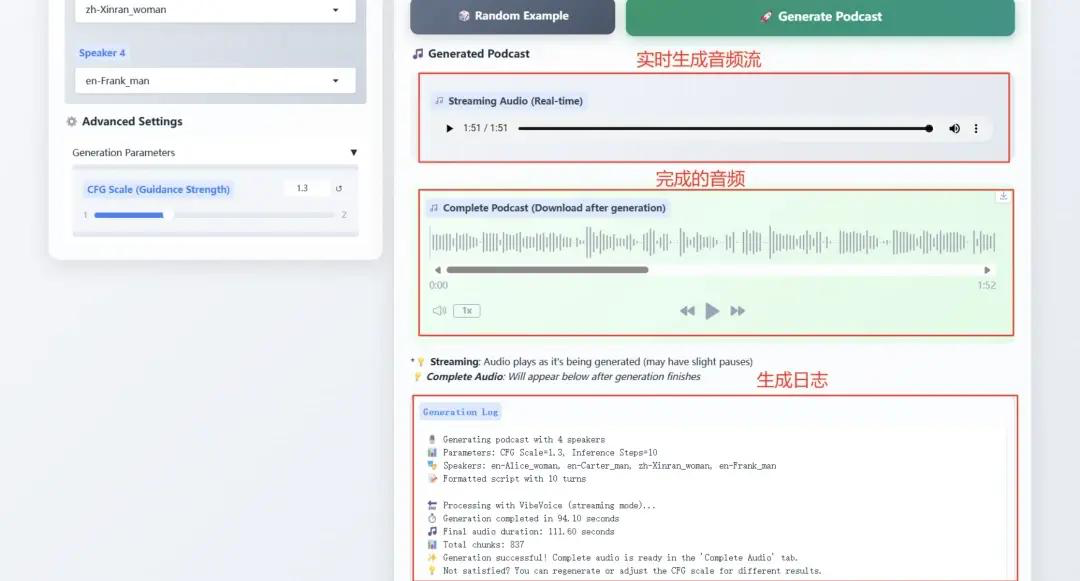
2. Déploiement vLLM + Open WebUI de NVIDIA-Nemotron-Nano-9B-v2
NVIDIA-Nemotron-Nano-9B-v2 combine de manière innovante le traitement efficace des séquences longues de Mamba et les puissantes capacités de modélisation sémantique de Transformer, permettant une prise en charge de contextes ultra-longs de 128 000 avec seulement 9 milliards (9 B) de paramètres. Son efficacité d'inférence et ses performances sur les périphériques d'informatique de pointe (tels que les GPU RTX 4090) sont comparables à celles des modèles de pointe avec la même échelle de paramètres.
Exécutez en ligne : https://go.hyper.ai/cVzPp
3. Déploiement vLLM + Open WebUI gemma-3-270m-it
Gemma-3-270m-it est construit avec 270M (270 millions) de paramètres, privilégiant une interaction conversationnelle efficace et un déploiement léger. Ce modèle léger et performant ne nécessite qu'un Go ou plus de mémoire graphique sur une seule carte graphique, ce qui le rend adapté aux périphériques et aux scénarios à faibles ressources. Il prend en charge les conversations à plusieurs tours et est spécialement optimisé pour les questions-réponses quotidiennes et les instructions de tâches simples. Il se concentre sur la génération et la compréhension de texte et prend en charge une fenêtre contextuelle de 32 000 jetons, ce qui lui permet de gérer de longues conversations textuelles.
Exécutez en ligne : https://go.hyper.ai/kBjw3

4. vLLM+Open WebUI Deployment Seed-OSS-36B-Instruct
Seed-OSS-36B-Instruct a utilisé 12 000 milliards (12 téraoctets) de jetons pour son entraînement et a obtenu des performances exceptionnelles sur plusieurs benchmarks open source courants. L'une de ses caractéristiques les plus emblématiques est sa capacité native à contexte long, avec une longueur de contexte maximale de 512 000 jetons, lui permettant de gérer des documents et des chaînes de raisonnement extrêmement longs sans compromettre les performances. Cette longueur est deux fois supérieure à celle de la dernière famille de modèles GPT-5 d'OpenAI et équivaut à environ 1 600 pages de texte.
Exécutez en ligne : https://go.hyper.ai/aKw9w

💡Nous avons également créé un groupe d'échange de tutoriels Stable Diffusion. Bienvenue aux amis pour scanner le code QR et commenter [tutoriel SD] pour rejoindre le groupe pour discuter de divers problèmes techniques et partager les résultats de l'application ~

Recommandation de papier de cette semaine
1. Au-delà de Pass@1 : le jeu autonome avec synthèse de problèmes variationnels soutient RLVR
Cet article propose une stratégie de synthèse pour les problèmes variationnels auto-exécutés afin d'améliorer l'apprentissage par renforcement de récompense vérifiable pour les grands modèles de langage. Si le RLVR traditionnel améliore Pass@1, il réduit la diversité générative en raison de l'effondrement de l'entropie, limitant ainsi les performances de Pass@k. Le SvS atténue l'effondrement de l'entropie et maintient la diversité d'apprentissage en synthétisant des problèmes variationnels équivalents basés sur des solutions correctes.
Lien vers l'article : https://go.hyper.ai/IU71P
2. Mémento : Affiner les agents LLM sans affiner les LLM
Cet article propose un nouveau paradigme d'apprentissage pour les agents adaptatifs à grands modèles de langage, qui élimine le besoin d'affiner le LLM sous-jacent. Les méthodes existantes souffrent souvent de deux limites : elles sont soit trop rigides, soit coûteuses en calcul. L'équipe de recherche parvient à une adaptation continue à faible coût grâce à l'apprentissage par renforcement en ligne basé sur la mémoire. Elle formalise ce processus sous la forme d'un processus de décision markovien amélioré par la mémoire (M-MDP) et introduit une stratégie de sélection de cas neuronaux pour guider les décisions d'action.
Lien vers l'article : https://go.hyper.ai/sl9Yj
3. TreePO : combler le fossé entre l'optimisation et l'efficacité des politiques et l'efficience des inférences grâce à la modélisation heuristique basée sur les arbres
Cet article propose TreePO, un algorithme de déploiement autoguidé qui traite la génération de séquences comme un processus de recherche arborescent. TreePO repose sur une stratégie d'échantillonnage dynamique des arbres et un décodage de segments de longueur fixe, exploitant l'incertitude locale pour générer des branches supplémentaires. En amortissant la charge de calcul sur les préfixes courants et en éliminant les chemins de faible valeur dès le début, TreePO réduit efficacement la charge de calcul de chaque mise à jour tout en préservant, voire en améliorant, la diversité de l'exploration.
Lien vers l'article : https://go.hyper.ai/J8tKk
4. Rapport technique VibeVoice
Cet article propose un nouveau modèle de synthèse vocale, VibeVoice, qui génère de longs discours multi-locuteurs par diffusion du jeton suivant. Son tokeniseur vocal continu améliore le taux de compression de 80 fois par rapport à Encodec, améliorant significativement l'efficacité du traitement des longues séquences tout en préservant la qualité sonore. Ce modèle permet de synthétiser jusqu'à 90 minutes de discours conversationnel pour un maximum de quatre locuteurs dans un contexte de 64 kHz, recréant ainsi fidèlement l'atmosphère de la communication et surpassant les modèles open source et commerciaux existants.
Lien vers l'article : https://go.hyper.ai/pokVi
5. CMPhysBench : une référence pour l'évaluation des grands modèles de langage en physique de la matière condensée
Cet article présente CMPhysBench, une nouvelle référence pour l'évaluation des capacités des grands modèles de langage en physique de la matière condensée. CMPhysBench comprend plus de 520 problèmes de niveau master soigneusement sélectionnés, couvrant des sous-domaines représentatifs et des cadres théoriques fondamentaux de la physique de la matière condensée, tels que le magnétisme, la supraconductivité et les systèmes fortement corrélés.
Lien vers l'article : https://go.hyper.ai/uo8de
Autres articles sur les frontières de l'IA :https://go.hyper.ai/iSYSZ
Interprétation des articles communautaires
Lors de la troisième « École d'été sur l'IA pour la bio-ingénierie » organisée par l'Université Jiao Tong de Shanghai, Li Mingchen, chercheur postdoctoral au sein du groupe de recherche de Hong Liang à l'Institut des sciences naturelles de l'Université Jiao Tong de Shanghai, a partagé avec tout le monde les dernières avancées de la recherche et les avancées technologiques dans le modèle de base des protéines et des génomes sous le thème « Modèle de base des protéines et du génome ».
Voir le rapport complet : https://go.hyper.ai/Ynjdj
En combinant des outils de chimioinformatique avec la nouvelle base de données de solubilité organique BigSolDB, l'équipe de recherche du MIT a amélioré les architectures des modèles FASTPROP et CHEMPROP, permettant au modèle d'entrer simultanément des molécules de soluté et de solvant, ainsi que des paramètres de température, pour un apprentissage direct de la régression sur logS. Dans un scénario rigoureux d'extrapolation de soluté, le modèle optimisé a obtenu une réduction de 2 à 3 fois de la RMSE et une augmentation de 50 fois de la vitesse d'inférence par rapport au modèle de pointe développé par Vermeire et al.
Voir le rapport complet : https://go.hyper.ai/cj9RX
NVIDIA a annoncé le lancement officiel du kit de développement Jetson AGX Thor, à partir de 3 499 $. Le module Thor T5000 de production est désormais disponible pour les entreprises. Surnommé le « cerveau du robot », Jetson AGX Thor vise à équiper des millions de robots dans des secteurs tels que la fabrication, la logistique, le transport, la santé, l'agriculture et la vente au détail.
Voir le rapport complet : https://go.hyper.ai/1XLXn
Une équipe de recherche du Département de génie chimique et de chimie appliquée de l'Université de Toronto, au Canada, a proposé une méthode d'apprentissage automatique multimodale qui exploite les informations disponibles après la synthèse des MOF : le PXRD et les produits chimiques utilisés, afin d'identifier les MOF présentant un potentiel différent de celui initialement prévu pour les applications. Cette recherche accélère le lien entre la synthèse des MOF et les scénarios d'application.
Voir le rapport complet : https://go.hyper.ai/cqX1t
Lors de la Conférence académique nationale sur le calcul haute performance 2025CCF, le chercheur Zhang Zhengde, responsable de l'AI4S au Centre de calcul de l'Institut de physique des hautes énergies, a systématiquement élaboré le plan de construction de données AI-Ready efficace et de haute qualité, basé sur l'état actuel des données scientifiques provenant d'installations à grande échelle, ainsi que sur l'application d'agents intelligents et de cadres multi-agents dans l'annotation et la fourniture de données.
Voir le rapport complet : https://go.hyper.ai/u7F9L
Articles populaires de l'encyclopédie
1. DALL-E
2. Fusion de tri réciproque RRF
3. Front de Pareto
4. Compréhension linguistique multitâche à grande échelle (MMLU)
5. Apprentissage contrastif
Voici des centaines de termes liés à l'IA compilés pour vous aider à comprendre « l'intelligence artificielle » ici :https://go.hyper.ai/wiki
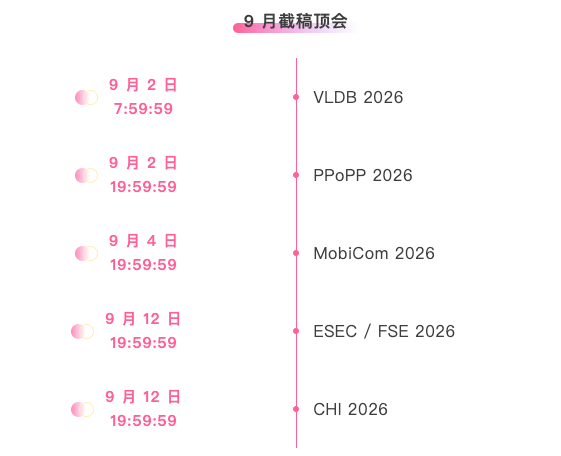
Suivi unique des principales conférences universitaires sur l'IA :https://go.hyper.ai/event
Voici tout le contenu de la sélection de l’éditeur de cette semaine. Si vous avez des ressources que vous souhaitez inclure sur le site officiel hyper.ai, vous êtes également invités à laisser un message ou à soumettre un article pour nous le dire !
À la semaine prochaine !








