Command Palette
Search for a command to run...
Tutoriel En Ligne | NVIDIA Met l'accent Sur Les Petits Modèles : Le Nemotron-Nano-9B-v2, Compact Et Compact, Est Six Fois Plus Rapide Que Le Qwen3.

Lorsque les grands modèles de langage ont été introduits, aviez-vous imaginé qu'un jour, ils seraient suffisamment compacts pour tenir dans une montre connectée ? Aujourd'hui, ce rêve devient progressivement réalité : des appareils comme les montres connectées accèdent aux modèles depuis le cloud, permettant des conversations vocales et des assistants intelligents. Cependant, le défi à venir ne réside pas seulement dans leur déploiement sur des appareils compacts, mais aussi dans le maintien des capacités de raisonnement et de l'efficacité du modèle tout en préservant sa légèreté.
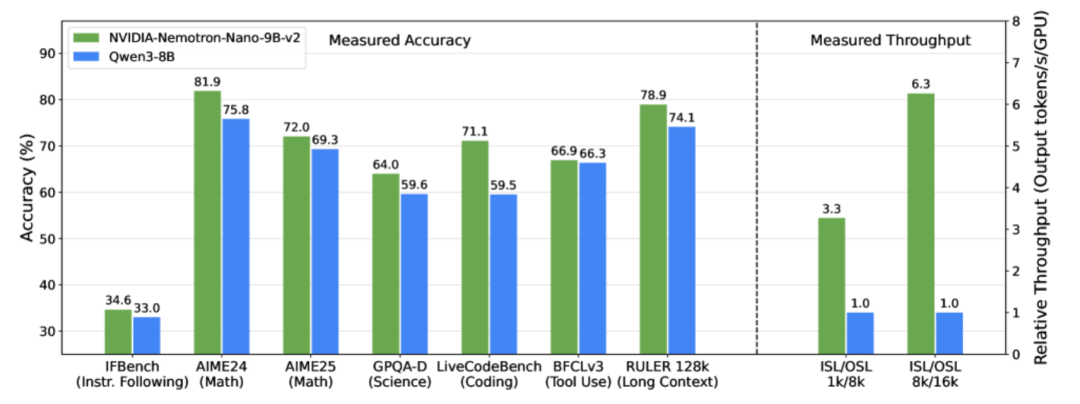
Pour résoudre ce problème, l'équipe NVIDIA a lancé le modèle de langage léger et volumineux NVIDIA-Nemotron-Nano-9B-v2 le 19 août 2025. En tant que version optimisée pour l'architecture hybride de la série Nemotron,Ce modèle combine de manière innovante le traitement efficace des séquences longues de Mamba avec les puissantes capacités de modélisation sémantique de Transformer, remplaçant la plupart des couches d'auto-attention par des couches d'espace d'état de Mamba-2, rendant le modèle plus rapide lors du traitement de longues trajectoires d'inférence.Avec seulement 9 milliards de paramètres, il prend en charge un contexte ultra-long de 128 000. Dans les tests de raisonnement complexes, il atteint une précision comparable, voire supérieure, à celle du modèle open source leader de même échelle, Qwen3-8B, et son débit est jusqu'à six fois supérieur à celui de ce dernier, marquant une avancée majeure dans le domaine du déploiement léger et de la compréhension de textes longs dans les grands modèles linguistiques.
En d’autres termes, Nemotron-Nano-9B-v2 représente plus qu’un simple « modèle dans un petit appareil ».Au lieu de cela, il vise à rendre les capacités de raisonnement puissantes véritablement légères et accessibles au public.Peut-être qu'à l'avenir, de grands modèles linguistiques seront capables de fournir aux gens des services intelligents à tout moment et en tout lieu, sous une forme « petite et précise ».
Publier des ensembles de données post-formation multilingues pour améliorer considérablement les capacités du modèle
Plutôt que de simplement construire un petit modèle, l'équipe de recherche a utilisé un modèle de référence à 12 B paramètres, le Nemotron-Nano-12B-v2-Base, et l'a pré-entraîné sur une grande quantité de données organisées et synthétiques. Elle a également ajouté des données de type SFT couvrant plusieurs domaines afin d'améliorer le raisonnement.
Par la suite, l'équipe a mené une post-formation en plusieurs étapes, notamment SFT (réglage fin supervisé), IFeval RL (instruction après évaluation), DPO (optimisation directe des préférences) et RLHF (apprentissage par renforcement par rétroaction humaine), pour rendre le modèle plus précis et robuste en termes de mathématiques, de code, d'appels d'outils et de dialogues à long contexte.L'ensemble de données post-formation associé a été mis à jour et publié sous le nom de « Nemotron-Post-Training-Dataset-v2 ».Étendez les données SFT et RL à cinq langues cibles (espagnol, français, allemand, italien et japonais), couvrant des scénarios tels que les mathématiques, le codage, les STEM (sciences, technologie, ingénierie et mathématiques) et le dialogue, pour améliorer les capacités de raisonnement et de suivi des commandes du modèle.
Adresse du jeu de données :
S'appuyant sur la stratégie de compression et de distillation Minitron, l'équipe de recherche a utilisé une méthode de recherche d'architecture neuronale légère pour évaluer l'importance des composants du modèle (tels que chaque couche et le réseau neuronal à propagation directe), puis les élaguer. Grâce à la distillation et au réentraînement, l'équipe a affiné les capacités du modèle original pour en faire le modèle élagué. Finalement, ils ont compressé le modèle de 12 octets dans le Nemotron-Nano-9B-v2 de 9 octets, réduisant ainsi considérablement l'utilisation des ressources tout en préservant la précision des inférences.
« Déploiement de NVIDIA-Nemotron-Nano-9B-v2 avec vLLM + Open WebUI » est désormais disponible dans la section « Tutoriels » du site web HyperAI (hyper.ai). Venez découvrir ce grand modèle de langage, compact mais précis !
Lien du tutoriel :
Essai de démonstration
1. Saisissez l'URL hyper.ai dans votre navigateur. Après être arrivé sur la page d'accueil, cliquez sur la page Tutoriels, sélectionnez vLLM + Ouvrir l'interface Web pour déployer NVIDIA-Nemotron-Nano-9B-v2, puis cliquez sur Exécuter ce tutoriel en ligne.
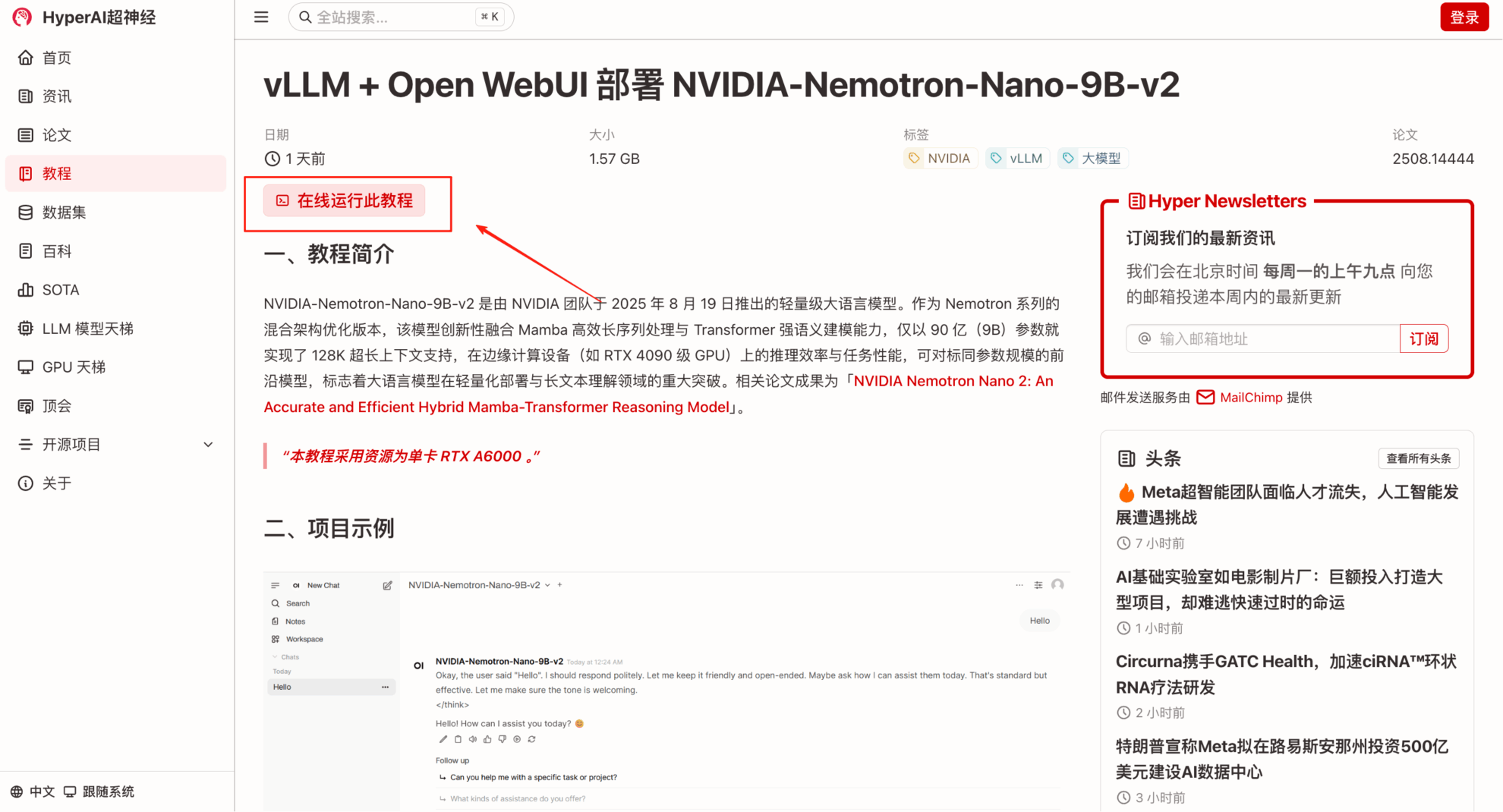
2. Une fois la page affichée, cliquez sur « Cloner » dans le coin supérieur droit pour cloner le didacticiel dans votre propre conteneur.
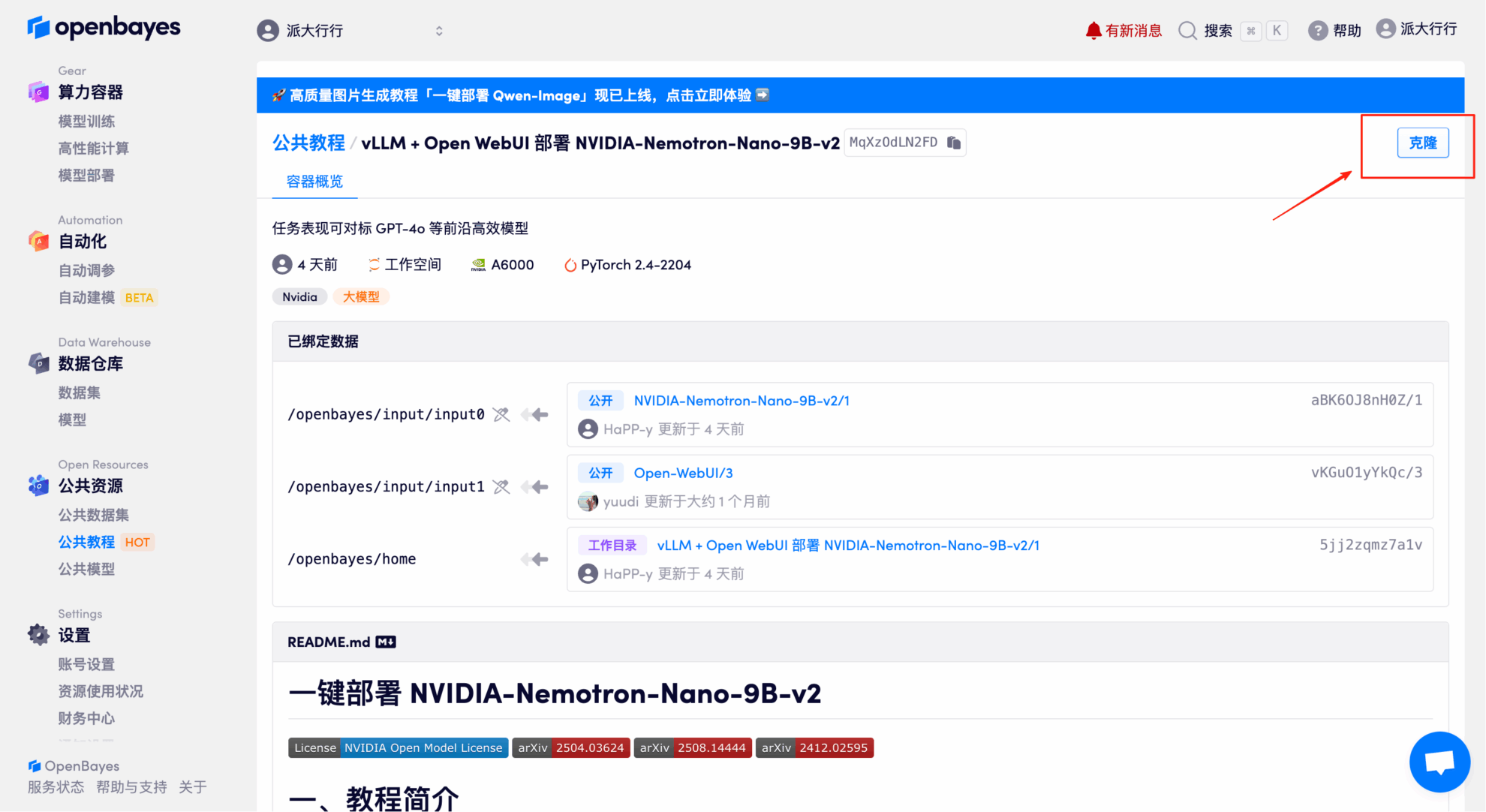
3. Sélectionnez les images NVIDIA RTX A6000 48 Go et PyTorch, puis cliquez sur Continuer. La plateforme OpenBayes propose quatre options de facturation : paiement à l'utilisation ou forfait journalier, hebdomadaire ou mensuel. Les nouveaux utilisateurs peuvent s'inscrire via le lien d'invitation ci-dessous pour recevoir 4 heures de carte graphique RTX 4090 et 5 heures de temps processeur gratuits !
Lien d'invitation exclusif HyperAI (copier et ouvrir dans le navigateur) :
https://openbayes.com/console/signup?r=Ada0322_NR0n
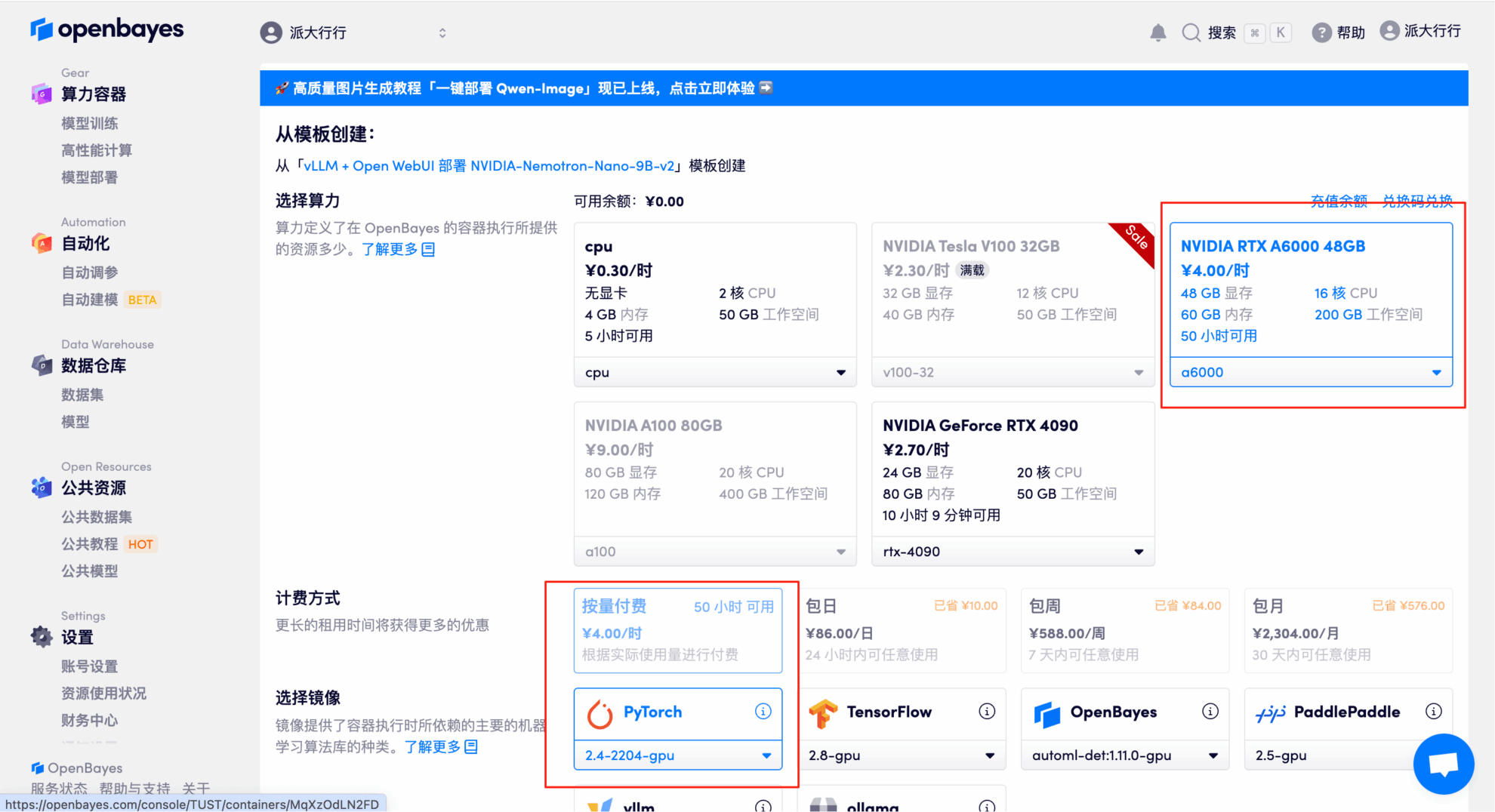
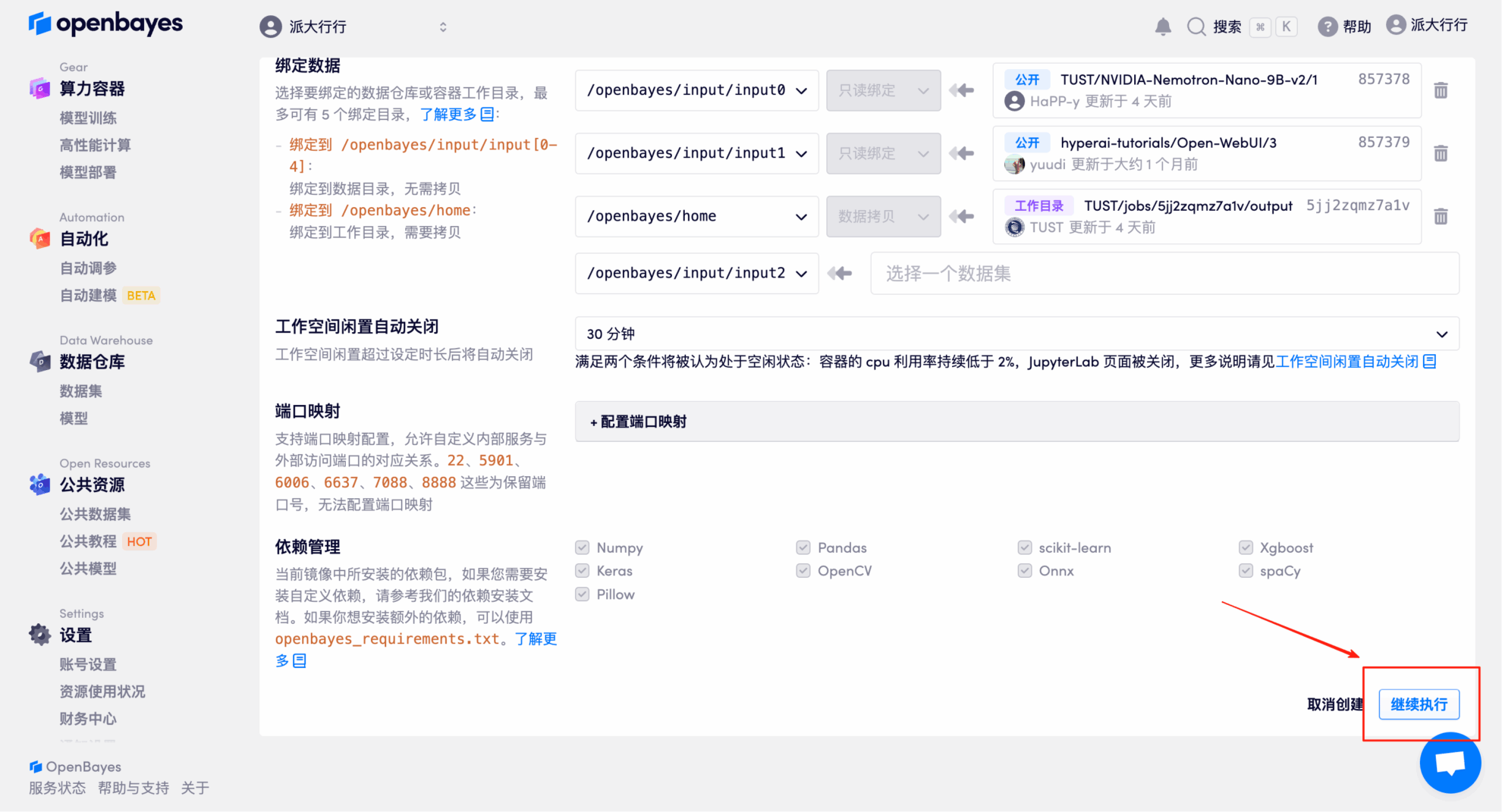
4. Attendez que les ressources soient allouées. Le premier clonage prendra environ 3 minutes. Lorsque le statut passe à « En cours d'exécution », cliquez sur la flèche à côté de « Adresse API » pour accéder à la page de démonstration. Veuillez noter que les utilisateurs doivent s'authentifier avec leur nom réel avant d'utiliser l'adresse API.
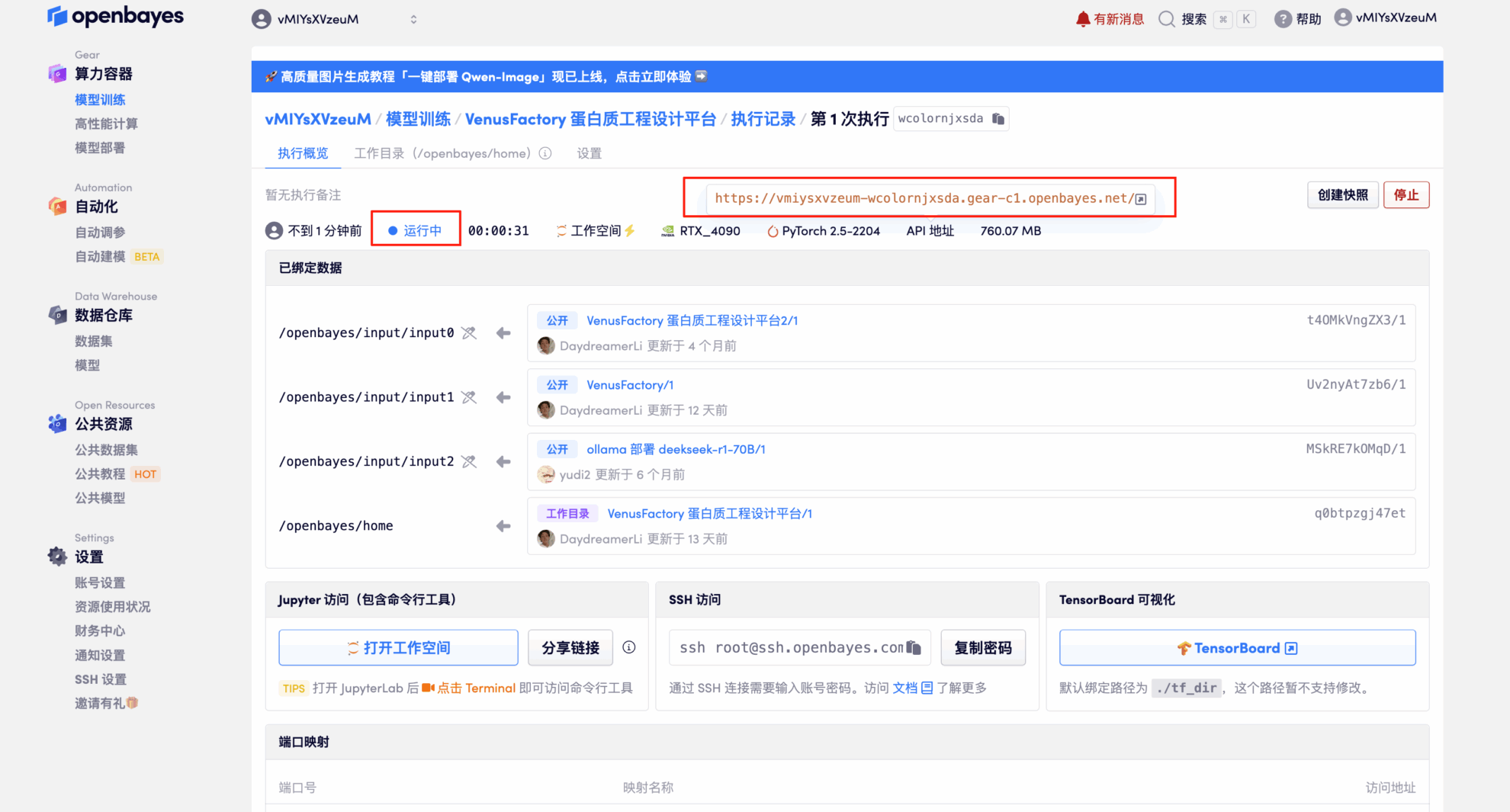
Démonstration d'effet
Après avoir accédé à la page d'exécution de la démonstration, entrez Prompt dans la boîte de dialogue et cliquez sur Exécuter.
Le temps se rafraîchit progressivement après le début de l'automne. Nemotron-Nano-9B-v2 nous donne quelques conseils pour rester au chaud en ce début d'automne.



Le tutoriel ci-dessus est celui recommandé par HyperAI cette fois-ci. Bienvenue à tous pour le découvrir !
Lien du tutoriel :
Obtenez des articles de haute qualité et des articles d'interprétation approfondis dans le domaine de l'IA4S de 2023 à 2024 en un seul clic⬇️









