Command Palette
Search for a command to run...
10 Millions d'heures De Données Vocales ! Le Modèle Vocal Higgs Audio V2 Améliore Les Capacités Émotionnelles ; MathCaptcha10k Améliore La Technologie De Reconnaissance Des Codes De vérification.

« Que se passerait-il si 10 millions d'heures de données vocales étaient ajoutées à l'apprentissage d'un vaste modèle linguistique textuel ? » Fort de cette réflexion,Après des recherches, Li Mu et son équipe Boson AI ont officiellement publié le modèle de parole à grande échelle « Higgs Audio V2 ».
Les systèmes de synthèse vocale traditionnels utilisent souvent une sortie vocale mécanique, manquant d'adaptabilité émotionnelle et de rythme naturel. Les dialogues à plusieurs caractères nécessitent une segmentation manuelle, et il est difficile d'harmoniser le timbre avec les caractères à l'aide de modèles seuls. Higgs Audio V2, quant à lui, introduit des fonctionnalités innovantes rarement vues dans les systèmes de synthèse vocale traditionnels.Il comprend l'adaptation automatique du rythme pendant la narration, la possibilité de générer des dialogues multi-locuteurs, le clonage de voix sans échantillon et le fredonnement mélodique, ainsi que la génération simultanée de parole et de musique de fond, ce qui représente un bond en avant majeur dans les capacités de l'IA audio.
Il convient de mentionner que sur EmergentTTS-Eval,Le modèle a surpassé gpt-4o-mini-tts de 75,7% et 55,7% dans les catégories sentiment et question, respectivement.Cela reflète le fait que « l’interaction émotionnelle » est devenue une étape clé du modèle dans le domaine audio.
Le site officiel d'HyperAI vient de lancer « Higgs Audio V2 : Redéfinir le pouvoir expressif de la génération vocale ». Venez l'essayer !
Utilisation en ligne:https://go.hyper.ai/Ty0CM
Du 4 au 8 août, voici un bref aperçu des mises à jour du site officiel hyper.ai :
* Ensembles de données publiques de haute qualité : 10
* Sélection de tutoriels de qualité : 7
* Articles recommandés cette semaine : 5
* Interprétation des articles communautaires : 5 articles
* Entrées d'encyclopédie populaire : 5
* Principales conférences avec date limite en août : 2
Visitez le site officiel :hyper.ai
Ensembles de données publiques sélectionnés
1. Ensemble de données de questions-réponses sur la conduite autonome STRIDE-QA-Mini
STRIDE-QA-Mini est un jeu de données de type questions-réponses pour la conduite autonome, conçu pour étudier les capacités de raisonnement spatio-temporel des modèles de langage visuel (MLV) dans des scénarios de conduite autonome. Ce jeu de données contient 103 220 paires questions-réponses et 5 539 échantillons d'images. Les données proviennent de véritables images de caméras embarquées prises à Tokyo.
Utilisation directe :https://go.hyper.ai/9DVTI
2. Ensemble de données d'images de code de vérification arithmétique MathCaptcha10k
MathCaptcha10K est un ensemble de données d'images CAPTCHA arithmétiques conçu pour tester et entraîner les algorithmes de reconnaissance CAPTCHA, notamment lorsqu'ils sont traités avec des arrière-plans gênants et du texte déformé. Cet ensemble de données contient 10 000 exemples étiquetés et 11 766 exemples non étiquetés. Chaque exemple étiqueté contient une image CAPTCHA, les caractères exacts de l'image et sa réponse sous forme d'entier.
Utilisation directe :https://go.hyper.ai/QERJt

3. Ensemble de données synthétiques multimodales de questions-réponses CoSyn-400K
CoSyn-400K est un jeu de données synthétiques multimodales de type questions-réponses, publié conjointement par l'Université de Pennsylvanie et l'Allen Institute for Artificial Intelligence. Il vise à fournir des ressources de données synthétiques de haute qualité et évolutives pour l'entraînement de modèles multimodaux. Ce jeu de données contient plus de 400 000 paires de questions-réponses image-texte, permettant des tâches de réponse visuelle.
Utilisation directe :https://go.hyper.ai/aNjiz
4. Ensemble de données de génération audio non verbale NonverbalTTS
NonverbalTTS est un ensemble de données de génération audio non verbale publié par VK Lab et Yandex. Il vise à promouvoir la recherche sur la synthèse vocale expressive (TTS) et à soutenir les modèles de génération de parole naturelle intégrant émotions et sons non verbaux.
Utilisation directe :https://go.hyper.ai/0Gz9V
5. Édition d'images GPT - Ensemble de données de génération d'images de 1,5 M
GPT Image Edit-1.5M est un jeu de données de génération d'images publié par l'Université de Californie à Santa Cruz et l'Université d'Édimbourg. Il vise à fournir une ressource de données multimodales complète pour l'entraînement et l'évaluation des modèles d'édition d'images. Ce jeu de données contient plus de 1,5 million de triplets de haute qualité (instruction, image source, image éditée).
Utilisation directe :https://go.hyper.ai/ohpmD

6. Ensemble de données de séquences protéiques UniRef50
L'ensemble de données de séquences protéiques UniRef50 est issu de la base de connaissances UniProt et des séquences UniParc par clustering itératif. Ce processus itératif garantit que les séquences représentatives d'UniRef50 sont de haute qualité, non redondantes et diversifiées, offrant une couverture étendue de l'espace des séquences protéiques pour les modèles de langage protéique.
Utilisation directe :https://go.hyper.ai/EcUF5
7. Ensemble de données de référence sur la perception des différences d'équité et de conscience des différences
Difference-Aware Fairness est un ensemble de données de référence sur la perception des différences publié par l'Université de Stanford. Il vise à mesurer les performances des modèles en matière de perception des différences et de perception du contexte. L'article correspondant a été publié à l'ACL 2025 et a reçu le prix du meilleur article.
Utilisation directe :https://go.hyper.ai/wwBos
8. Ensemble de données SFT russe T-Wix
T-Wix est un ensemble de données SFT contenant 499 598 échantillons de langue russe, conçus pour améliorer les capacités du modèle, de la résolution de problèmes algorithmiques et mathématiques à la conversation, à la pensée logique et aux modèles de raisonnement.
Utilisation directe :https://go.hyper.ai/p0sgT
9. Ensemble de données de raisonnement multi-domaines vérifié par WebInstruct
WebInstruct-verified est un ensemble de données de raisonnement multi-domaines publié conjointement par l'Université de Waterloo et le Vector Institute. Il vise à améliorer les capacités de raisonnement des étudiants en LLM dans divers domaines, tout en préservant leurs points forts en mathématiques. Cet ensemble de données contient environ 230 000 questions de raisonnement avec différents formats de réponses, notamment des questions à choix multiples et des jeux de données d'expressions numériques, répartis de manière équilibrée entre les domaines.
Utilisation directe :https://go.hyper.ai/oCgsZ
10. Ensemble de données d'inférence financière Finance-Instruct-500k
Finance-Instruct-500k est un ensemble de données de raisonnement financier conçu pour l'entraînement de modèles linguistiques avancés pour les tâches financières, le raisonnement et le dialogue multi-tours. Cet ensemble de données contient plus de 500 000 enregistrements de haute qualité issus du domaine financier, couvrant les questions-réponses financières, le raisonnement, l'analyse des sentiments, la classification thématique, la reconnaissance d'entités nommées multilingues et l'IA conversationnelle.
Utilisation directe :https://go.hyper.ai/03UVH
Tutoriels publics sélectionnés
1. Higgs Audio V2 : redéfinir le pouvoir expressif de la génération vocale
Higgs Audio V2 est un modèle vocal à grande échelle publié par Li Mu et son équipe chez Boson AI. Il atteint des performances de pointe sur les benchmarks de synthèse vocale traditionnels, notamment Seed-TTS Eval et l'Emotional Speech Dataset (ESD). Ce modèle présente des capacités rarement observées dans les systèmes précédents, notamment l'adaptation prosodique automatique pendant la narration et la génération instantanée de conversations multi-locuteurs naturelles en plusieurs langues.
Exécutez en ligne :https://go.hyper.ai/BqZJD
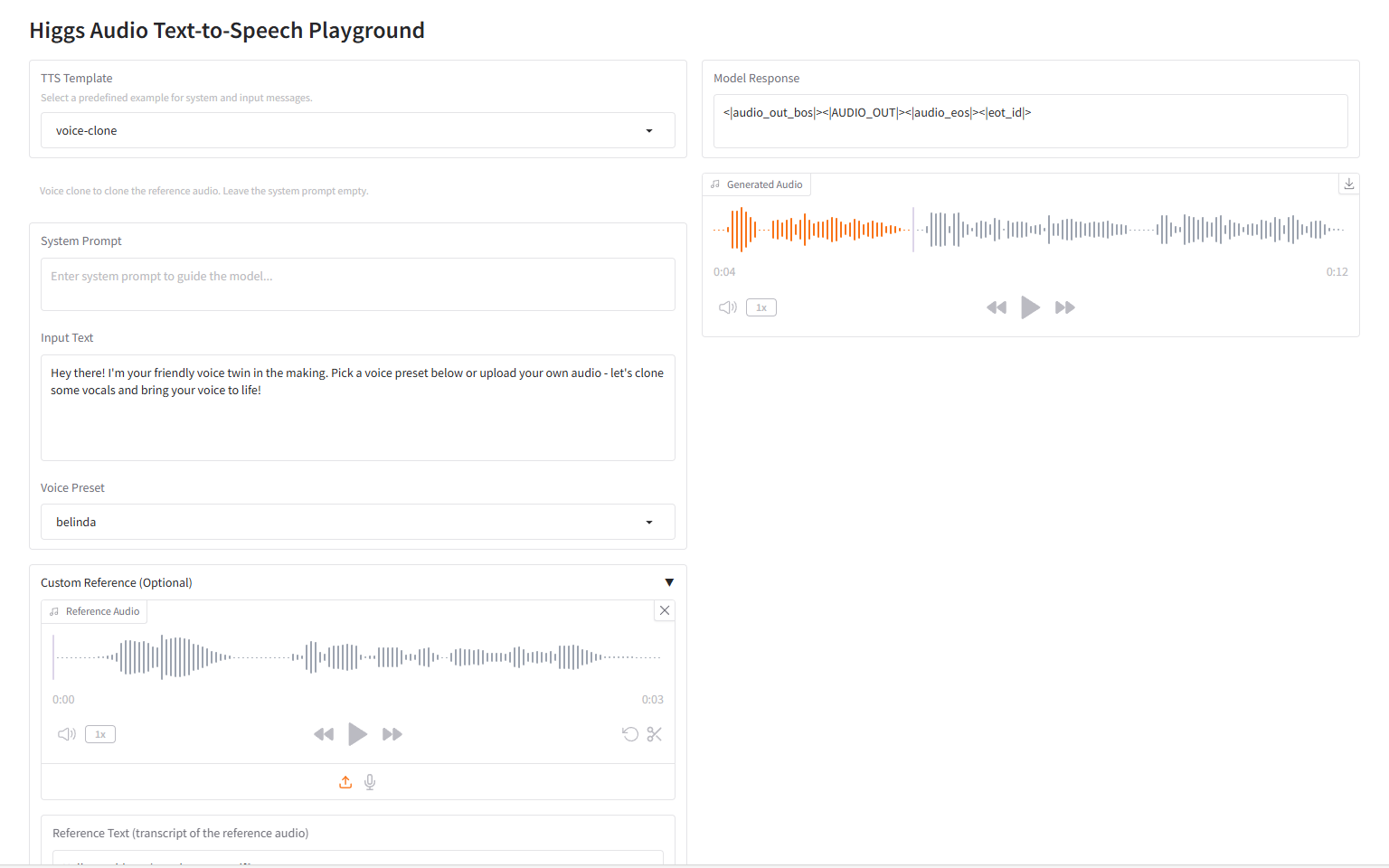
2. Ovis-U1-3B : Modèle de compréhension et de génération multimodale
Ovis-U1-3B est un modèle unifié multimodal développé par l'équipe Ovis du groupe Alibaba. Ce modèle intègre trois fonctionnalités clés : la compréhension multimodale, la conversion texte-image et l'édition d'images. Grâce à une architecture avancée et à un apprentissage collaboratif unifié, il permet une synthèse d'images haute fidélité et une interaction texte-image efficace.
Exécutez en ligne :https://go.hyper.ai/oSA7p

3. Neta Lumina : modèle de génération d'images de style 2D de haute qualité
Neta Lumina est un modèle de génération d'images de style Anime de haute qualité, publié par Neta.art. Basé sur Lumina-Image-2.0, le projet open source de l'équipe Alpha-VLLM du Laboratoire d'intelligence artificielle de Shanghai, ce modèle exploite d'importantes quantités d'images de style Anime de haute qualité et des données étiquetées multilingues pour lui fournir de puissantes capacités de compréhension et d'interprétation de la demande.
Exécutez en ligne :https://go.hyper.ai/nxCwD

4. Qwen-Image : un modèle d'image avec des capacités avancées de rendu de texte
Qwen-Image est un modèle à grande échelle pour la génération et l'édition d'images de haute qualité, développé par l'équipe Alibaba Tongyi Qianwen. Ce modèle réalise des avancées majeures en matière de rendu de texte, offrant une sortie haute fidélité au niveau des paragraphes multilignes, en chinois et en anglais, et reproduisant avec précision des scènes complexes et des détails au millimètre près.
Exécutez en ligne :https://go.hyper.ai/8s00s

5. MediCLIP : Détection d'anomalies dans des images médicales de petits échantillons à l'aide de CLIP
MediCLIP, publié par l'Université de Pékin, est une méthode efficace de détection d'anomalies d'images médicales en quelques clichés, qui atteint des performances de pointe avec un nombre très réduit d'images médicales normales. Le modèle intègre des repères apprenables, des adaptateurs et des tâches réalistes de synthèse d'anomalies d'images médicales.
Exécutez en ligne :https://go.hyper.ai/3BnDy
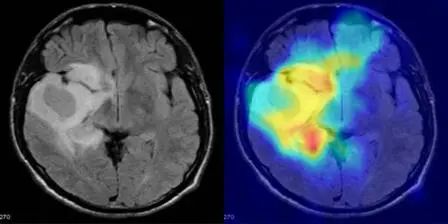
6. Modèle d'Énée : démonstration de restauration d'inscriptions romaines antiques
Aeneas est un réseau neuronal génératif multimodal développé par Google DeepMind en collaboration avec plusieurs universités. Il est utilisé pour la restauration textuelle, l'attribution géographique et l'attribution chronologique des inscriptions latines et grecques anciennes. La sortie de ce modèle marque une nouvelle ère dans l'épigraphie numérique. Son potentiel dans des domaines tels que la restauration de textes anciens, l'attribution géographique et chronologique et l'aide à la recherche historique est énorme, et il devrait accélérer la découverte scientifique et les applications interdisciplinaires.
Exécutez en ligne :https://go.hyper.ai/8ROfT

7. Déploiement en un clic de Qwen3-Coder-30B-A3B-Instruct
Qwen3-Coder-30B-A3B-Instruct est un modèle de langage étendu développé par le laboratoire Tongyi Wanxiang d'Alibaba. Il affiche des performances remarquables dans les modèles ouverts de codage proxy, d'utilisation de navigateurs proxy et d'autres tâches de codage de base, et peut gérer efficacement des tâches de codage dans plusieurs langages de programmation. Ses puissantes capacités de compréhension contextuelle et de raisonnement logique en font un excellent choix pour le développement de projets complexes et l'optimisation de code.
Exécutez en ligne :https://go.hyper.ai/vYf3s
💡Nous avons également créé un groupe d'échange de tutoriels Stable Diffusion. Bienvenue aux amis pour scanner le code QR et commenter [tutoriel SD] pour rejoindre le groupe pour discuter de divers problèmes techniques et partager les résultats de l'application ~

Recommandation de papier de cette semaine
1. Rapport technique Qwen-Image
Qwen-Image, un modèle de génération d'images fondamental de la famille Qwen, a permis des avancées significatives dans le rendu de textes complexes et l'édition précise d'images. Pour relever les défis posés par ce type de rendu, les chercheurs ont conçu un pipeline complet de traitement de données incluant l'acquisition, le filtrage, l'annotation, la synthèse et l'équilibrage de données à grande échelle. Le modèle atteint des performances de pointe sur de nombreux benchmarks, démontrant pleinement ses puissantes capacités en matière de génération et d'édition d'images.
Lien vers l'article :https://go.hyper.ai/HWjVM
2. Seed Diffusion : un modèle de langage de diffusion à grande échelle avec inférence à grande vitesse
Cet article propose Seed Diffusion Preview, un modèle de langage à grande échelle basé sur un mécanisme de diffusion à états discrets offrant une vitesse d'inférence extrêmement rapide. Grâce à son mécanisme de génération parallèle et non séquentiel, le modèle de diffusion discrète améliore considérablement l'efficacité de l'inférence et atténue efficacement la latence inhérente au décodage traditionnel jeton par jeton.
Lien vers l'article :https://go.hyper.ai/NvrNm
3. Cognitive Kernel-Pro : un cadre pour la formation des agents de recherche approfondie et des modèles de fondation d'agents
Les agents d'IA généraux sont de plus en plus considérés comme un cadre fondamental pour la prochaine génération d'intelligence artificielle, permettant le raisonnement complexe, l'interaction en réseau, la programmation et la recherche autonome. Dans cette étude, les chercheurs proposent Cognitive Kernel-Pro, un cadre d'agent intelligent multi-modules, entièrement open source et largement gratuit, conçu pour démocratiser le développement et l'évaluation d'agents d'IA avancés.
Lien vers l'article :https://go.hyper.ai/65j3v
4. Au-delà du fixe : débruitage à longueur variable pour les modèles de langage de diffusion volumineux
Dans cet article, les chercheurs proposent une nouvelle stratégie de débruitage sans apprentissage, DAEDAL, qui permet une extension dynamique et adaptative de la longueur des DLLM. Des expériences approfondies sur divers DLLM démontrent que DAEDAL égale et, dans certains cas, surpasse les performances de modèles de base à longueur fixe soigneusement optimisés, tout en améliorant significativement l'efficacité de calcul et en obtenant un ratio de jetons effectifs plus élevé.
Lien vers l'article :https://go.hyper.ai/p7WxK
5. Skywork UniPic : modélisation autorégressive unifiée pour la compréhension et la génération visuelles
Cet article présente Skywork UniPic, un modèle autorégressif de 1,5 milliard de paramètres qui unifie la compréhension d'images, la génération de texte en image et l'édition d'images au sein d'une architecture unique, sans recourir à des adaptateurs spécifiques à une tâche ni à des connecteurs intermodules. En démontrant qu'une fusion multimodale haute fidélité peut être obtenue sans coûts de ressources prohibitifs, Skywork UniPic établit un paradigme pratique pour une IA multimodale haute fidélité et déployable.
Lien vers l'article :https://go.hyper.ai/FiVaf
Autres articles sur les frontières de l'IA :https://go.hyper.ai/iSYSZ
Interprétation des articles communautaires
Une équipe de recherche de l'Université du Nevada à Las Vegas a proposé une méthode d'analyse multivariée appelée ICA-Var, basée sur un processus d'apprentissage automatique non supervisé. Elle extrait les covariations et les schémas de mutation évolutifs des données sur les eaux usées grâce à une analyse en composantes indépendantes, permettant ainsi une détection plus précoce et plus précise des variants.
Voir le rapport complet :https://go.hyper.ai/z1vVo
L'équipe Qwen a rendu Qwen3-Coder-Flash open source, un outil offrant des performances supérieures à celles des modèles open source pour le codage proxy, l'utilisation de navigateurs proxy et d'autres tâches de codage de base. Il gère efficacement des tâches de codage dans plusieurs langages de programmation. Parallèlement, ses puissantes capacités de compréhension du contexte et de raisonnement logique lui permettent d'être performant dans le développement de projets complexes et l'optimisation de code.
Voir le rapport complet :https://go.hyper.ai/FmOep
Pour résoudre le problème du ciblage des protéines naturellement désordonnées, David Baker et son équipe ont proposé une stratégie de conception de protéines, appelée Logos, qui permet aux protéines de se lier à des régions naturellement désordonnées dans diverses conformations étendues, les chaînes latérales s'insérant dans des poches de liaison complémentaires. Cette étude s'appuie sur le modèle de diffusion RF pour réorganiser les poches et les généraliser à un large éventail de séquences, permettant ainsi la reconnaissance universelle des régions protéiques désordonnées à partir d'un modèle de peptide cible-protéine de liaison conçu à cet effet.
Voir le rapport complet :https://go.hyper.ai/F0lti
Le groupe de recherche de Zhou Hao à l'Institut des industries intelligentes de l'Université Tsinghua, en collaboration avec le Laboratoire d'intelligence artificielle de Shanghai, a proposé le modèle protéique fondamental AMix-1 basé sur les réseaux de flux bayésiens. Pour la première fois, ils ont utilisé la méthodologie systématique de la loi d'échelle de pré-apprentissage, de la capacité émergente, de l'apprentissage en contexte et de la mise à l'échelle en fonction du temps de test pour construire un modèle protéique fondamental, introduisant ainsi le paradigme efficace des grands modèles de langage dans la conception des protéines. Leur efficacité et leur polyvalence ont été vérifiées par la mise à l'échelle en fonction du temps de test et des expériences réelles.
Voir le rapport complet :https://go.hyper.ai/X9iMe
OpenAI a officiellement publié GPT-5, améliorant encore ses performances dans les trois cas d'utilisation les plus courants de ChatGPT : l'écriture, la programmation et la santé. GPT-5 est un système unifié composé d'un modèle intelligent et efficace pour répondre à la plupart des questions (GPT-5-main), d'un modèle de raisonnement approfondi pour les problèmes plus complexes (GPT-5-thinking) et d'un routeur temps réel qui décide rapidement du modèle à utiliser en fonction du type de conversation, de la complexité de la question, des outils requis et de l'intention explicite de l'utilisateur.
Voir le rapport complet :https://go.hyper.ai/gFHQg
Articles populaires de l'encyclopédie
1. DALL-E
2. Fusion de tri réciproque RRF
3. Front de Pareto
4. Compréhension linguistique multitâche à grande échelle (MMLU)
5. Apprentissage contrastif
Voici des centaines de termes liés à l'IA compilés pour vous aider à comprendre « l'intelligence artificielle » ici :https://go.hyper.ai/wiki
Date limite d'août pour le sommet
21 août 11:59:59 ASPLOS 2026
27 août 7:59:59 Symposium sur la sécurité USENIX 2025
Suivi unique des principales conférences universitaires sur l'IA :https://go.hyper.ai/event
Voici tout le contenu de la sélection de l’éditeur de cette semaine. Si vous avez des ressources que vous souhaitez inclure sur le site officiel hyper.ai, vous êtes également invités à laisser un message ou à soumettre un article pour nous le dire !
À la semaine prochaine !








