Command Palette
Search for a command to run...
Google DeepMind Lance Perch 2.0, Couvrant Près De 15 000 Espèces, Établissant Un Nouvel État De l'art En Matière De Classification Et De Détection bioacoustiques.

La bioacoustique, outil essentiel reliant la biologie et l'écologie, joue un rôle essentiel dans la conservation et la surveillance de la biodiversité. Les premières recherches s'appuyaient sur des méthodes traditionnelles de traitement du signal, telles que l'appariement de modèles, qui ont progressivement révélé leurs limites en raison de leur inefficacité et de leur manque de précision face à des environnements acoustiques naturels complexes et à des données à grande échelle.
Ces dernières années, la croissance fulgurante de l'intelligence artificielle (IA) a permis à l'apprentissage profond et à d'autres méthodes de remplacer les approches traditionnelles, devenant ainsi des outils essentiels pour la détection et la classification des événements bioacoustiques. Par exemple, le modèle BirdNET, entraîné à partir de données acoustiques d'oiseaux étiquetées à grande échelle, a démontré des performances exceptionnelles en matière de reconnaissance des empreintes vocales d'oiseaux : il distingue non seulement avec précision les cris des différentes espèces, mais permet également, dans une certaine mesure, l'identification individuelle. Par ailleurs, des modèles tels que Perch 1.0, grâce à une optimisation et une itération continues, ont accumulé de nombreuses avancées dans le domaine de la bioacoustique, offrant un soutien technique solide à la surveillance et à la conservation de la biodiversité.
Il y a quelques jours,Perch 2.0, lancé conjointement par Google DeepMind et Google Research,Portant la recherche bioacoustique à de nouveaux sommets, Perch 2.0 place la classification des espèces au cœur de sa tâche d'entraînement. Il intègre non seulement davantage de données d'entraînement provenant de groupes non aviaires, mais utilise également de nouvelles stratégies d'augmentation des données et de nouveaux objectifs d'entraînement.Ce modèle a actualisé le SOTA actuel dans deux benchmarks bioacoustiques faisant autorité, BirdSET et BEANS.Il démontre un potentiel de performance puissant et de larges perspectives d’application.
Les résultats de recherche pertinents ont été publiés sous forme de pré-impression sur arXiv sous le titre « Perch 2.0 : The Bittern Lesson for Bioacoustics ».
Adresse du document :
https://arxiv.org/abs/2508.04665
Suivez le compte officiel et répondez « Bioacoustique » pour obtenir le PDF complet
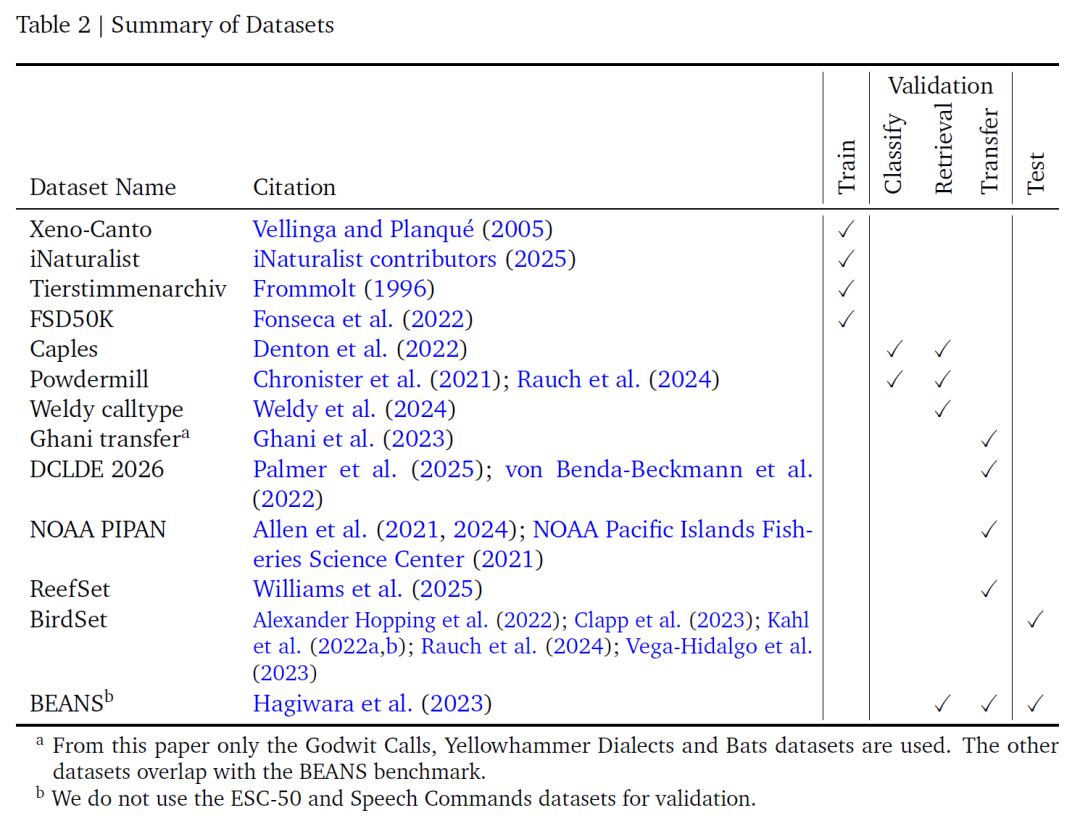
Ensemble de données : Benchmark de construction et d'évaluation des données de formation
Cette étude a intégré quatre ensembles de données audio étiquetés pour la formation du modèle : Xeno-Canto, iNaturalist, Tierstimmenarchiv et FSD50K.Ensemble, ils constituent le support de données fondamental pour l'apprentissage des modèles. Comme le montre le tableau ci-dessous, Xeno-Canto et iNaturalist sont d'importants référentiels de science citoyenne : le premier est accessible via une API publique, tandis que le second est dérivé de fichiers audio classés « de qualité recherche » sur la plateforme GBIF. Tous deux contiennent un grand nombre d'enregistrements acoustiques d'oiseaux et d'autres créatures. Tierstimmenarchiv, les archives sonores animalières du Musée d'histoire naturelle de Berlin, se concentre également sur la bioacoustique. Enfin, FSD50K complète ces archives avec une variété de sons non aviaires.
Ces quatre catégories de données contiennent un total de 14 795 catégories.Parmi ceux-ci, 14 597 étaient des espèces, et les 198 restants étaient des événements sonores non spécifiques. Cette riche couverture de catégories assure non seulement un apprentissage approfondi des signaux bioacoustiques, mais élargit également l'applicabilité du modèle en incluant des données sonores non liées aux oiseaux. Cependant, comme les trois premiers ensembles de données utilisaient des systèmes de classification des espèces différents, l'équipe de recherche a cartographié et unifié manuellement les noms des catégories et supprimé les enregistrements de chauves-souris qui ne pouvaient être représentés par les paramètres du spectrogramme sélectionnés afin de garantir la cohérence et l'applicabilité des données.
Considérant que les durées d'enregistrement des différentes sources de données varient considérablement (de moins d'une seconde à plus d'une heure, la plupart d'entre elles étant de 5 à 150 secondes), et que le modèle est fixé avec des clips de 5 secondes en entrée,L'équipe de recherche a conçu deux stratégies de sélection de fenêtres :La stratégie de fenêtre aléatoire intercepte aléatoirement 5 secondes lors de la sélection d'un enregistrement. Bien que cela puisse inclure des segments où l'espèce cible n'a pas émis de sons, ce qui peut générer du bruit d'étiquetage, la plage reste généralement acceptable. La stratégie du pic d'énergie reprend le principe de Perch 1.0 et utilise la transformée en ondelettes pour sélectionner la zone de 6 secondes présentant la plus forte énergie de l'enregistrement. 5 secondes sont ensuite sélectionnées aléatoirement dans cette zone afin d'améliorer la validité de l'échantillon, en partant du principe que « les zones à forte énergie sont plus susceptibles de contenir les sons de l'espèce cible ».Cette méthode est cohérente avec la logique de conception des détecteurs de modèles tels que BirdNET et peut capturer des signaux acoustiques efficaces avec plus de précision.
Pour améliorer encore l'adaptabilité du modèle aux environnements acoustiques complexes, l'équipe de recherche a adopté une variante d'augmentation des données de mixup.Générer un signal composite en mixant plusieurs fenêtres audio :Tout d'abord, le nombre de signaux audio mixtes est déterminé par échantillonnage selon la distribution bêta-binomiale, puis les pondérations sont échantillonnées selon la distribution symétrique de Dirichlet. Les signaux multiples sélectionnés sont pondérés, additionnés et les gains normalisés.
Contrairement au mixage initial, cette méthode utilise une moyenne pondérée de vecteurs cibles multi-hot plutôt que de vecteurs one-hot, garantissant ainsi une identification fiable de tous les sons de la fenêtre (quelle que soit leur intensité). Le réglage des paramètres pertinents comme hyperparamètres peut améliorer la capacité du modèle à distinguer les sons qui se chevauchent et à améliorer la précision de la classification.
L’évaluation du modèle est basée sur deux références faisant autorité : BirdSet et BEANS. BirdSet contient six jeux de données de paysages sonores entièrement annotés provenant des États-Unis continentaux, d'Hawaï, du Pérou et de la Colombie. Aucun réglage fin n'est effectué lors de l'évaluation, et les résultats du classificateur d'apprentissage prototype sont directement utilisés ; BEANS couvre 12 tâches de test inter-catégories (impliquant des oiseaux, des mammifères terrestres et marins, des anoures et des insectes). Seul son jeu d'apprentissage est utilisé pour entraîner les sondes linéaires et prototypes, et le réseau d'intégration n'est pas non plus ajusté.
Perch 2.0 : un modèle de pré-entraînement bioacoustique haute performance
L'architecture du modèle Perch 2.0 se compose d'un frontal, d'un modèle d'intégration et d'un ensemble de têtes de sortie.Ces éléments fonctionnent ensemble pour réaliser le processus complet, du signal audio à l’identification des espèces.
dans,Le front-end est responsable de la conversion de l'audio brut en une forme de fonctionnalité que le modèle peut traiter.Il reçoit un échantillon audio mono échantillonné à 32 kHz et, pour un segment de 5 secondes (contenant 160 000 points d'échantillonnage), il génère un spectrogramme log-mel contenant 500 images et 128 bandes mel par image grâce à un traitement avec une longueur de fenêtre de 20 ms et une longueur de saut de 10 ms, couvrant la plage de fréquences de 60 Hz à 16 kHz, fournissant des fonctionnalités de base pour une analyse ultérieure.
Le réseau d'intégration adopte l'architecture EfficientNet-B3Il s'agit d'un réseau résiduel convolutif de 120 millions de paramètres, qui maximise l'efficacité des paramètres grâce à une conception convolutive séparable en profondeur. Comparé à l'EfficientNet-B1 de 78 millions de paramètres utilisé dans la version précédente de Perch, il est plus grand pour s'adapter à la croissance des données d'apprentissage.
Après traitement via le réseau d'intégration, on obtient une intégration spatiale de forme (5, 3, 1536) (les dimensions correspondent respectivement aux canaux temporel, fréquentiel et de caractéristiques). Après avoir calculé la moyenne des dimensions spatiales, on obtient une intégration globale de 1536 dimensions, qui sert de caractéristique principale pour la classification ultérieure.
Le responsable de sortie est responsable de tâches spécifiques de prédiction et d'apprentissage.Il se compose de trois parties : le classificateur linéaire projette l'intégration globale dans un espace de catégories de 14 795 dimensions et, grâce à l'apprentissage, rend les intégrations de différentes espèces linéairement séparables, améliorant ainsi l'effet de détection linéaire lors de l'adaptation à de nouvelles tâches ; le classificateur d'apprentissage de prototypes prend l'intégration spatiale en entrée, apprend quatre prototypes pour chaque catégorie et utilise le prototype présentant l'activation maximale pour la prédiction. Cette conception est dérivée de l'AudioProtoPNet dans le domaine de la bioacoustique ; la tête de prédiction de source est un classificateur linéaire qui prédit la source d'enregistrement originale du clip audio en fonction de l'intégration globale. L'ensemble d'apprentissage contenant plus de 1,5 million d'enregistrements sources, il réalise un calcul efficace grâce à une projection de rang bas de 512, servant à l'apprentissage de la perte de prédiction de source auto-supervisée.
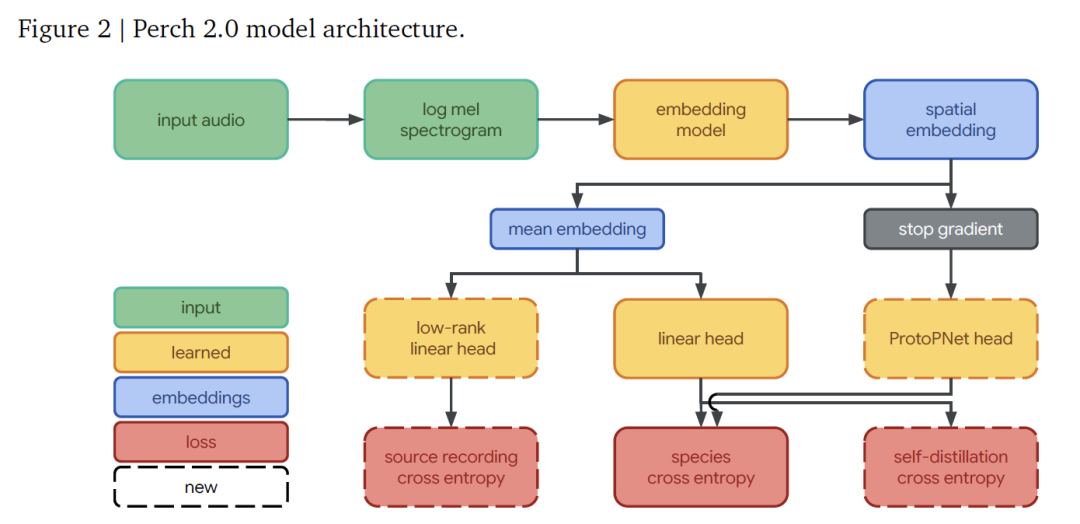
La formation du modèle est optimisée de bout en bout grâce à trois objectifs indépendants :
* L'entropie croisée pour la classification des espèces utilise l'activation softmax et la perte d'entropie croisée pour les classificateurs linéaires, attribuant des poids uniformes aux catégories cibles ;
Dans le mécanisme d'auto-distillation, le classificateur d'apprentissage prototype agit comme un « enseignant » dont les prédictions guident le classificateur linéaire « étudiant » tout en maximisant la différence de prototype grâce à la perte orthogonale, et le gradient n'est pas rétropropagé au réseau d'intégration ;
* La prédiction de la source est utilisée comme objectif auto-supervisé, traitant les enregistrements originaux comme des catégories indépendantes pour la formation, poussant le modèle à capturer des caractéristiques saillantes.
La formation est divisée en deux phases :La première phase s'est concentrée sur la formation du prototype de classificateur d'apprentissage (sans auto-distillation, jusqu'à 300 000 étapes) ; la deuxième phase a permis l'auto-distillation (jusqu'à 400 000 étapes), toutes deux utilisant l'optimiseur Adam.
La sélection des hyperparamètres repose sur l'algorithme Vizier.Lors de la première étape, le taux d'apprentissage, le taux d'abandon, etc. sont recherchés, et le modèle optimal est déterminé après deux cycles de sélection. Lors de la deuxième étape, le poids de perte par autodistillation est augmenté et la recherche se poursuit. Les deux méthodes d'échantillonnage par fenêtre sont utilisées tout au long de la recherche.
Les résultats montrent que la première étape privilégie le mélange de 2 à 5 signaux, avec une pondération de perte de prédiction de source de 0,1 à 0,9 ; l'étape d'autodistillation tend à avoir un faible taux d'apprentissage, à utiliser moins de mélange et à attribuer une pondération élevée de 1,5 à 4,5 à la perte d'autodistillation. Ces paramètres confirment les performances du modèle.
Évaluation de la capacité de généralisation de Perch 2.0 : performances de base et valeur pratique
L'évaluation de Perch 2.0 porte sur sa capacité de généralisation, en examinant ses performances dans les paysages sonores d'oiseaux (qui diffèrent sensiblement des enregistrements d'entraînement) et dans les tâches d'identification non spécifiques (comme l'identification du type de cri), ainsi que sa transférabilité à des groupes non aviaires tels que les chauves-souris et les mammifères marins. Sachant que les praticiens doivent souvent traiter peu de données étiquetées, voire aucune,Le principe fondamental de l’évaluation est de vérifier l’efficacité du « réseau embarqué gelé ».Autrement dit, en extrayant les fonctionnalités en une seule fois, de nouvelles tâches telles que le clustering et l'apprentissage sur de petits échantillons peuvent être rapidement adaptées.
La phase de sélection du modèle vérifie la praticabilité sous trois aspects :
* Performances du classificateur pré-entraîné, utilisant ROC-AUC pour évaluer les capacités de prédiction d'espèces prêtes à l'emploi sur un ensemble de données d'oiseaux entièrement annotées ;
* Récupération d'un échantillon, en utilisant la distance cosinus pour mesurer le clustering et les performances de recherche ;
* Migration linéaire, simulation de scénarios de petits échantillons pour tester l'adaptabilité.
Les scores de ces tâches sont calculés par moyenne géométrique et les résultats finaux des 19 sous-ensembles de données reflètent la facilité d'utilisation réelle du modèle.
Sur la base des deux benchmarks BirdSet et BEANS, les résultats de l'évaluation de cette étude sont présentés dans le tableau suivant :Perch 2.0 présente des performances exceptionnelles dans de nombreux indicateurs, notamment ROC-AUC, qui est le meilleur à l'heure actuelle.Et aucun réglage fin n'est requis ; ses stratégies d'entraînement par fenêtre aléatoire et par fenêtre de pic d'énergie ont des performances similaires, probablement parce que l'auto-distillation atténue l'impact du bruit de l'étiquette.
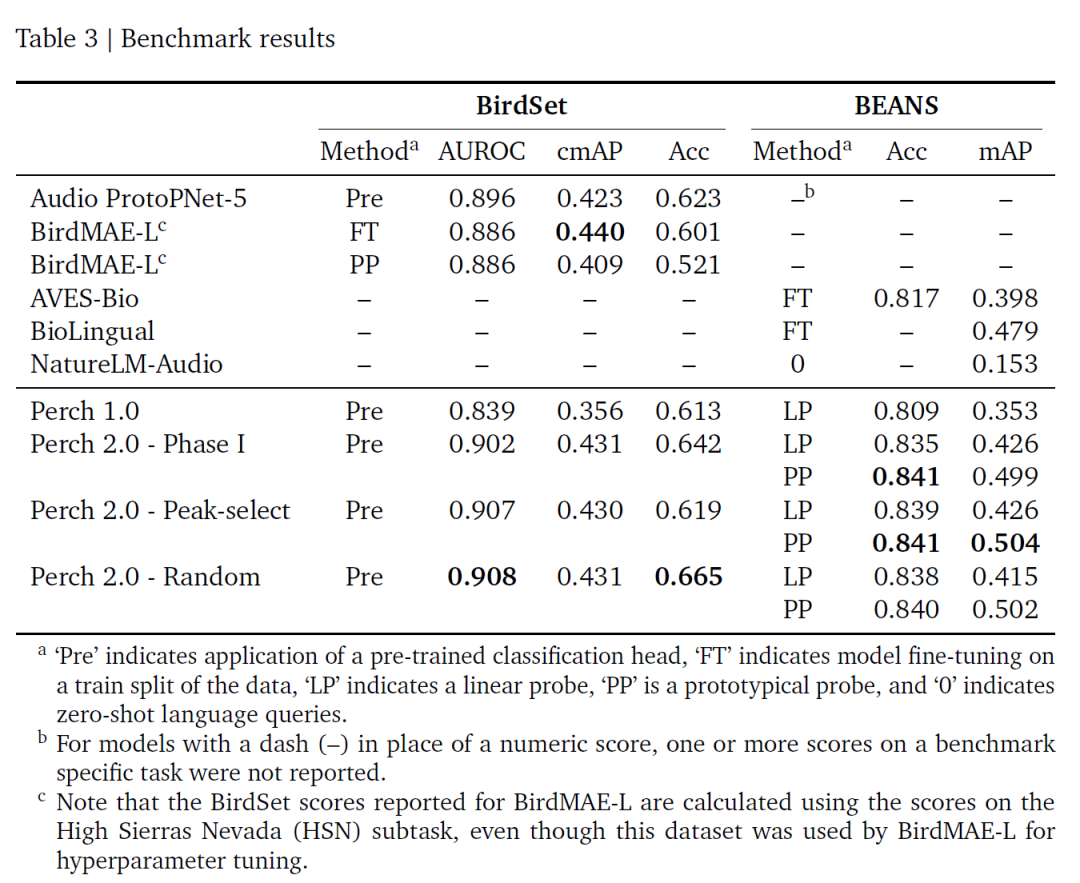
Globalement, Perch 2.0 repose sur l'apprentissage supervisé et est étroitement lié aux propriétés bioacoustiques. La percée de Perch 2.0 montre queL’apprentissage par transfert de haute qualité ne nécessite pas de modèles de très grande taille ; des modèles supervisés affinés, combinés à une augmentation des données et à des objectifs auxiliaires, peuvent donner de bons résultats.Sa conception à intégration fixe (qui élimine le besoin de réglages fins répétés) réduit le coût du traitement des données à grande échelle et permet une modélisation agile. Les futures orientations dans ce domaine comprendront la construction de benchmarks d'évaluation réalistes, le développement de nouvelles tâches utilisant des métadonnées et l'exploration de l'apprentissage semi-supervisé.
L'intersection de la bioacoustique et de l'intelligence artificielle
À l'intersection de la bioacoustique et de l'intelligence artificielle, des axes de recherche tels que l'apprentissage par transfert inter-catégories, la conception de cibles auto-supervisées et l'optimisation de réseaux d'intégration fixes ont suscité une exploration approfondie dans les milieux universitaires et commerciaux du monde entier.
La technologie d'entraînement contradictoire virtuel à distance cosinus (CD-VAT) développée par l'équipe de l'Université de Cambridge améliore la discriminabilité des plongements acoustiques grâce à la régularisation de la cohérence.Récupère une amélioration du taux d'erreur égale de 32,51 % TP3T sur une tâche de vérification de locuteur à grande échelle,Fournit un nouveau paradigme pour l’apprentissage semi-supervisé en reconnaissance vocale.
Le MIT et le CETI collaborent sur la recherche sur l'empreinte vocale des cachalots.Grâce à l'apprentissage automatique, un « alphabet sonore » composé de rythme, de mètre, de trémolo et d'ornementation est séparé.La complexité de leur système de communication s'est révélée bien plus grande que prévu : la tribu des cachalots des Caraïbes orientales possède à elle seule au moins 143 combinaisons de vocalisations distinctes, et sa capacité de transport d'informations dépasse même la structure de base du langage humain.
La technologie d'imagerie photoacoustique développée par l'ETH Zurich dépasse la limite de diffraction acoustique en chargeant des microcapsules avec des nanoparticules d'oxyde de fer.Réaliser une imagerie en super-résolution des microvaisseaux des tissus profonds (résolution jusqu'à 20 microns),Il a démontré le potentiel de la surveillance dynamique multiparamétrique dans les sciences du cerveau et la recherche sur les tumeurs.
en même temps,Le projet open source BirdNET a accumulé 150 millions d'enregistrements dans le monde.BirdNET-Lite est devenu un outil de référence pour la surveillance écologique. Sa version allégée, BirdNET-Lite, peut fonctionner en temps réel sur des appareils périphériques comme Raspberry Pi, permettant l'identification de plus de 6 000 espèces d'oiseaux et offrant une solution économique pour la recherche sur la biodiversité.
Le système de reconnaissance de chants d'oiseaux par IA déployé par la société japonaise Hylable dans le parc Hibiya combine un réseau multi-microphones avec DNN.Obtenez une sortie simultanée de la localisation de la source sonore et de l'identification des espèces, avec un taux de précision de plus de 95%.Son cadre technique a été étendu aux domaines de l’évaluation écologique des espaces verts urbains et de la construction d’installations sans obstacles.
Il convient de noter queLe projet Zoonomia de Google DeepMind explore les mécanismes évolutifs des points communs acoustiques entre les espèces en intégrant des données génomiques et acoustiques de 240 espèces de mammifères.L'étude a révélé que la distribution énergétique harmonique des aboiements joyeux des chiens (rapport énergétique harmonique 3-5 : 0,78 ± 0,12) est très similaire à celle des sifflements sociaux des dauphins (0,81 ± 0,09). Cette corrélation biologique moléculaire fournit non seulement une base pour la migration de modèles inter-espèces, mais inspire également une nouvelle voie de modélisation pour une « IA d'inspiration biologique » – intégrant les informations de l'arbre évolutif à l'apprentissage des réseaux embarqués, dépassant ainsi les limites des modèles bioacoustiques traditionnels.
Ces explorations apportent une nouvelle dimension à l'alliance de la bioacoustique et de l'intelligence artificielle. Lorsque la profondeur de la recherche universitaire rencontre l'ampleur des applications industrielles, les signaux de vie autrefois cachés dans les canopées des forêts tropicales et les récifs des grands fonds sont mieux captés et interprétés, se transformant ainsi en guides d'action pour la protection des espèces menacées et en solutions intelligentes pour une coexistence harmonieuse entre villes et nature.
Liens de référence :
1.https://mp.weixin.qq.com/s/ZWBg8zAQq0nSRapqDeETsQ
2.https://mp.weixin.qq.com/s/UdGi6iSW-j_kcAaSsGW3-A
3.https://mp.weixin.qq.com/s/57sXpOs7vRhmopPubXTSXQ
Scannez le code QR correspondant pour accéder aux articles AI4S de haute qualité de 2023 à 2024 par domaine, y compris des rapports d'interprétation approfondis⬇️









