Command Palette
Search for a command to run...
Meilleur Article ACL 25 ! L'Université Stanford Publie Un Ensemble De Données De Référence Tenant Compte Des Différences Pour Instaurer Une Équité Tenant Compte Des Différences ; l'auto-forçage Permet De Générer Des Vidéos En Streaming En Temps Réel Avec Une Latence Inférieure À La seconde.

Les modèles d’IA associent souvent le « traitement égal » traditionnel à l’équité.Dans les contextes juridiques et les scénarios d’évaluation des dommages, l’application mécanique du principe de « traitement non discriminatoire » pour parvenir à l’équité n’est pas une solution universelle.Une seule dimension d’équité peut facilement conduire à des résultats biaisés, ce qui suggère que les différences entre les groupes doivent être prises en considération.Il est donc de plus en plus crucial de promouvoir de grands modèles pour parvenir progressivement à un changement de paradigme de « l’équité sans distinction » à « l’équité fondée sur les différences perçues ».
Sur cette base,L'Université de Stanford a publié l'ensemble de données de référence Difference Aware Fairness, qui vise à mesurer les performances des modèles en matière de perception des différences et de connaissance du contexte.Les résultats de recherche pertinents ont été reconnus comme les 25 meilleurs articles de l'ACL. L'ensemble de données contient huit benchmarks, divisés en deux types : tâches descriptives et normatives, couvrant une variété de scénarios réels, notamment dans les domaines juridique, professionnel et culturel. Chaque benchmark contient 2 000 questions, dont 1 000 nécessitent une différenciation entre différents groupes, pour un total de 16 000 questions. La publication de ce benchmark améliore la dimension d'équité des modèles à grande échelle, fournissant un complément précieux pour combler le fossé entre développement technologique et valeur sociétale, et favorisant fortement l'évolution en profondeur de l'écosystème de l'IA vers une direction plus diversifiée et plus précise.
Le jeu de données de référence sur l'équité et la prise en compte des différences est désormais disponible sur le site officiel d'HyperAI. Téléchargez-le dès maintenant et essayez-le !
Utilisation en ligne :https://go.hyper.ai/XOx97
Du 28 juillet au 1er août, voici un bref aperçu des mises à jour du site officiel hyper.ai :
* Ensembles de données publiques de haute qualité : 10
* Sélection de tutoriels de haute qualité : 5
* Articles recommandés cette semaine : 5
* Interprétation des articles communautaires : 5 articles
* Entrées d'encyclopédie populaire : 5
* Principales conférences avec date limite en août : 9
Visitez le site officiel :hyper.ai
Ensembles de données publiques sélectionnés
1. Ensemble de données de référence biologique B3DB
B3DB est un ensemble de données biologiques de référence à grande échelle publié par l'Université McMaster au Canada. Il vise à fournir une référence pour la modélisation de la perméabilité de la barrière hémato-encéphalique des petites molécules. Cet ensemble de données est compilé à partir de 50 ressources publiées et fournit un sous-ensemble des propriétés physico-chimiques de ces molécules. Des valeurs numériques de logBB sont fournies pour certaines de ces molécules, tandis que l'ensemble de données contient des données numériques et catégorielles.
Utilisation directe :https://go.hyper.ai/0mPpP
2. Ensemble de données d'anime
Anime est un ensemble de données d'anime provenant de http://MyAnimeList.net La base de données vise à fournir une ressource riche, claire et facilement accessible aux data scientists, aux ingénieurs en apprentissage automatique et aux passionnés d'anime. Elle couvre plus de 28 000 œuvres d'anime uniques, offrant un aperçu des tendances du monde de l'anime.
Utilisation directe :https://go.hyper.ai/MxrqC
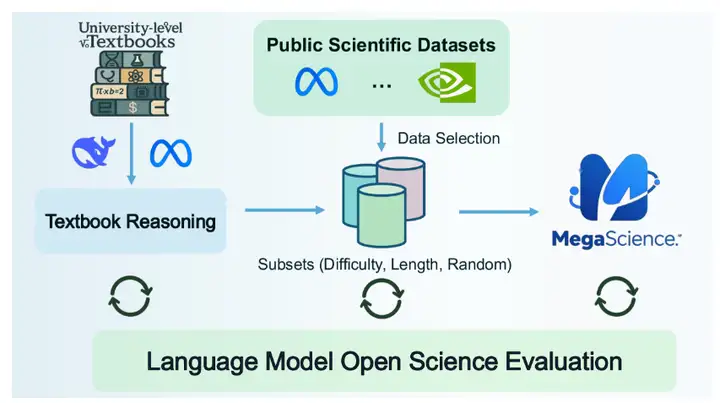
3. Ensemble de données de raisonnement scientifique MegaScience
MegaScience est un ensemble de données de raisonnement scientifique publié par l'Université Jiao Tong de Shanghai. Cet ensemble de données contient 1,25 million d'instances et est conçu pour prendre en charge le traitement automatique du langage naturel (TALN) et les modèles d'apprentissage automatique, notamment pour des tâches telles que la recherche documentaire, l'extraction d'informations, la synthèse automatique et l'analyse de citations dans le domaine de la recherche scientifique.
Utilisation directe :https://go.hyper.ai/694qh
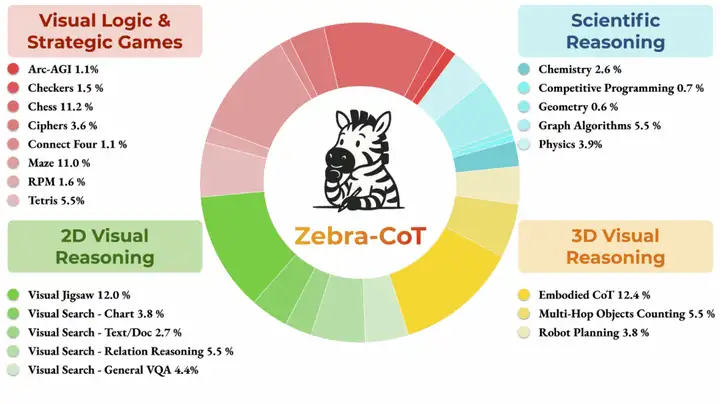
4. Ensemble de données d'inférence texte-image Zebra-CoT
Zebra-CoT est un ensemble de données de raisonnement visuo-linguistique publié conjointement par l'Université Columbia, l'Université du Maryland, l'Université de Californie du Sud et l'Université de New York. Il vise à aider les modèles à mieux comprendre les relations logiques entre images et texte. Largement utilisé dans des domaines tels que les questions-réponses visuelles et la génération de descriptions d'images, il contribue à améliorer les capacités et la précision du raisonnement. L'ensemble de données contient 182 384 échantillons répartis en quatre catégories principales : raisonnement scientifique, raisonnement visuel 2D, raisonnement visuel 3D, et jeux de logique et de stratégie visuels.
Utilisation directe :https://go.hyper.ai/y2a1e
5. Ensemble de données de raisonnement mathématique PolyMath
PolyMath est un ensemble de données de raisonnement mathématique publié conjointement par Alibaba et l'Université Jiao Tong de Shanghai. Il vise à promouvoir la recherche en mathématiques polyvalentes. Cet ensemble de données contient 500 questions de raisonnement mathématique de haute qualité, réparties en 125 questions pour chaque niveau de langue.
Utilisation directe :https://go.hyper.ai/yRVfY
6. Ensemble de données d'évaluation musicale SongEval
SongEval est un ensemble de données d'évaluation musicale publié conjointement par le Conservatoire de musique de Shanghai, l'Université polytechnique Northwestern, l'Université du Surrey et l'Université des sciences et technologies de Hong Kong. Il vise à réaliser des évaluations esthétiques de chansons complètes. Cet ensemble de données contient plus de 2 399 chansons (voix et instrumentales comprises), annotées par 16 évaluateurs experts selon cinq dimensions perceptuelles : cohérence globale, mémorisation, naturel du souffle vocal et du phrasé, clarté de la structure et musicalité globale. L'ensemble de données comprend environ 140 heures d'audio de haute qualité, incluant des chansons chinoises et anglaises et neuf genres majeurs.
Utilisation directe :https://go.hyper.ai/ohp0k
7. Ensemble de données de génération vidéo Vchitect T2V
Vchitect T2V est un jeu de données de génération vidéo publié par le Laboratoire d'intelligence artificielle de Shanghai. Il vise à améliorer la capacité des modèles à traduire le texte en contenu visuel, aidant ainsi les chercheurs et les développeurs à progresser dans la génération d'images, la compréhension sémantique et les tâches intermodales. Ce jeu de données contient 14 millions de vidéos de haute qualité, chacune accompagnée de sous-titres détaillés.
Utilisation directe :https://go.hyper.ai/vLs9z
8. Ensemble de données d'inscriptions latines LED
LED est le plus grand ensemble de données d'inscriptions latines lisibles par machine à ce jour, comprenant 176 861 inscriptions. Cependant, la plupart de ces inscriptions sont partiellement endommagées, seules 51 inscriptions TP3T produisant des images exploitables. Ces données proviennent de trois des bases de données d'inscriptions latines les plus complètes : la Base de données des inscriptions romaines (EDR), la Base de données des inscriptions de Heidelberg (EDH) et la Base de données Clauss-Slaby.
Utilisation directe :https://go.hyper.ai/O8noU
9. Ensemble de données de référence sur les sous-titres vidéo AutoCaption
L'ensemble de données AutoCaption est un ensemble de données de référence pour le sous-titrage vidéo publié par Tjunlp Labs. Il vise à promouvoir la recherche dans le domaine des modèles linguistiques multimodaux à grande échelle pour la génération de sous-titres vidéo. L'ensemble de données comprend deux sous-ensembles, totalisant 11 184 échantillons.
Utilisation directe :https://go.hyper.ai/pgOCw
10. Ensemble de données d'images interactives ArtVIP Machine
ArtVIP est un jeu de données d'images interactives de machines publié par le Centre d'innovation en robotique humanoïde de Pékin. Ce jeu de données contient 206 objets articulés répartis en 26 catégories. Il garantit un réalisme visuel grâce à des maillages géométriques précis et des textures haute résolution, une fidélité physique grâce à des paramètres dynamiques finement ajustés et est le premier à intégrer des comportements interactifs modulaires au sein des ressources, tout en permettant l'annotation des affordances au niveau du pixel.
Utilisation directe :https://go.hyper.ai/vGYek

Tutoriels publics sélectionnés
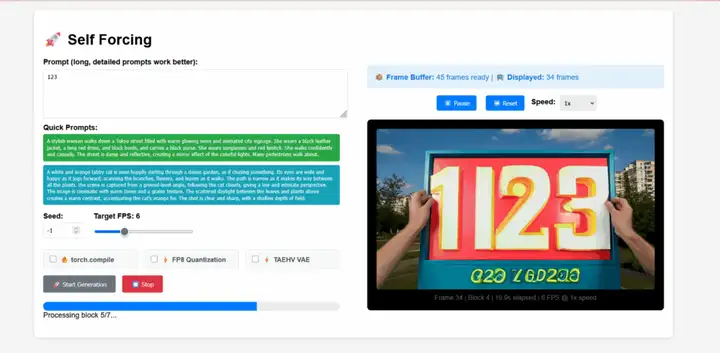
1. Génération vidéo en temps réel auto-forcée
L'auto-forçage est un nouveau paradigme d'entraînement pour les modèles de diffusion vidéo autorégressifs proposé par l'équipe de Xun Huang. Il résout le problème récurrent du biais d'exposition, selon lequel un modèle entraîné en contexte réel doit générer des séquences basées sur ses propres résultats imparfaits lors de l'inférence. Ce modèle permet de générer des flux vidéo en temps réel avec une latence inférieure à la seconde sur un seul GPU, tout en égalant, voire en surpassant, la qualité de génération des modèles de diffusion non causale nettement plus lents.
Exécutez en ligne :https://go.hyper.ai/j19Hx
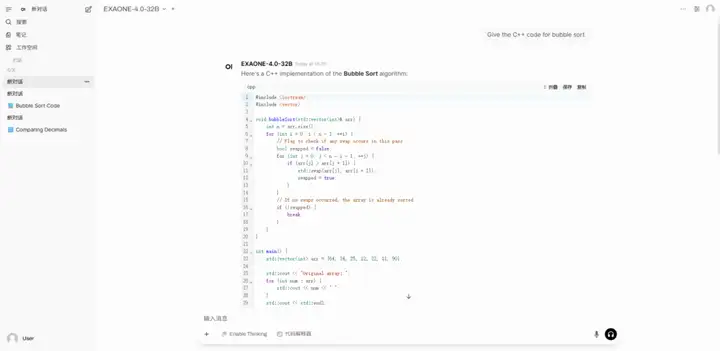
2. Déployer EXAONE-4.0-32B à l'aide de vLLM + Open WebUI
EXAONE-4.0 est un modèle d'IA de raisonnement hybride de nouvelle génération lancé par LG AI Research en Corée du Sud. Il s'agit également du premier modèle d'IA de raisonnement hybride de Corée du Sud. Ce modèle combine des capacités générales de traitement du langage naturel avec les capacités de raisonnement avancées vérifiées par EXAONE Deep, réalisant des avancées majeures dans des domaines complexes tels que les mathématiques, les sciences et la programmation.
Exécutez en ligne :https://go.hyper.ai/7XiZM
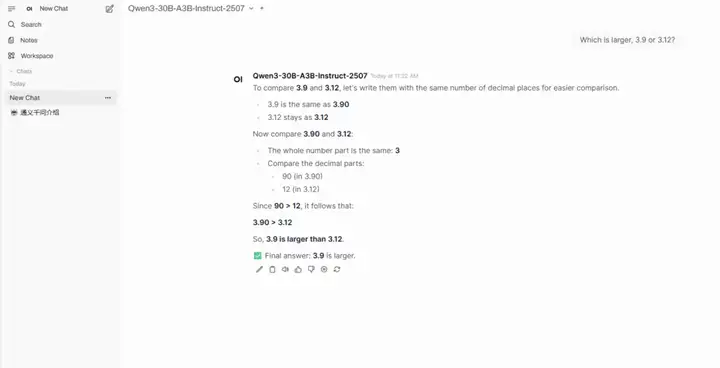
3. Déploiement en un clic de Qwen3-30B-A3B-Instruct-2507
Qwen3-30B-A3B-Instruct-2507 est un modèle de langage de grande taille développé par le laboratoire Tongyi Wanxiang d'Alibaba. Ce modèle est une version améliorée du mode non-pensant du Qwen3-30B-A3B. Son point fort est qu'avec seulement 3 milliards (3B) de paramètres activés, il affiche des performances impressionnantes, comparables à celles de Gemini 2.5-Flash (mode non-pensant) de Google et de GPT-4o d'OpenAI. Il s'agit d'une avancée significative en termes d'efficacité et d'optimisation des performances des modèles.
Exécutez en ligne :https://go.hyper.ai/hr1o6
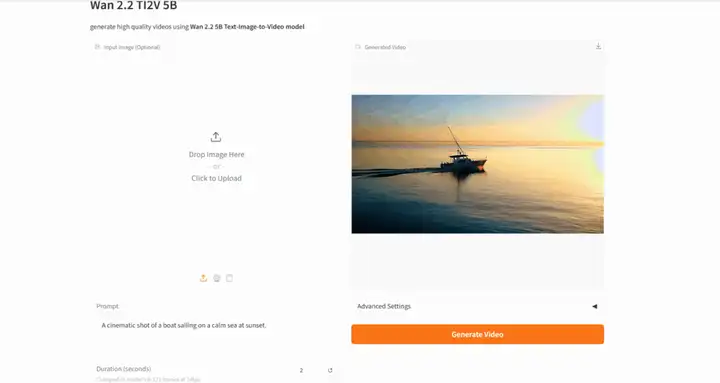
4. Wan2.2 : Modèle ouvert avancé de génération de vidéos à grande échelle
Wan-2.2 est un modèle avancé de génération vidéo IA open source développé par le laboratoire Tongyi Wanxiang d'Alibaba. Ce modèle intègre une architecture Mixture of Experts (MoE), améliorant ainsi la qualité de génération et l'efficacité de calcul. Il inaugure également un système de contrôle esthétique cinématographique, permettant un contrôle précis de l'éclairage, de la couleur, de la composition et d'autres effets esthétiques.
Exécutez en ligne :https://go.hyper.ai/AG6CE
5. PE3R : un cadre pour une perception efficace et une reconstruction 3D
PE3R (Perception-Efficient 3D Reconstruction) est un framework open source innovant de reconstruction 3D, publié par le XML Lab de l'Université nationale de Singapour (NUS). Il intègre des technologies de perception multimodale pour une modélisation de scènes efficace et intelligente. Développé à partir de multiples résultats de recherche de pointe en vision par ordinateur, il reconstruit rapidement des scènes 3D à partir d'images 2D uniquement. Sur une carte graphique RTX 3090, le temps de reconstruction moyen d'une scène est de seulement 2,3 minutes, soit une amélioration de plus de 65% par rapport aux méthodes traditionnelles.
Exécutez en ligne :https://go.hyper.ai/3BnDy

Recommandation de papier de cette semaine
1. Optimisation des politiques renforcées par les agents
Dans les scénarios de raisonnement réels, les grands modèles de langage (LLM) bénéficient souvent d'outils externes pour les aider à résoudre leurs tâches. Cependant, les algorithmes d'apprentissage par renforcement existants peinent à concilier les capacités de raisonnement à long terme inhérentes au modèle avec sa maîtrise des interactions multi-tours avec les outils. Pour combler cette lacune, cet article propose l'optimisation de la politique de renforcement des agents (ARPO), un nouvel algorithme d'apprentissage par renforcement des agents conçu spécifiquement pour l'entraînement d'agents multi-tours basés sur les LLM. Il permet d'améliorer les performances avec seulement la moitié du budget d'utilisation des outils des méthodes existantes, offrant ainsi une solution évolutive pour aligner les agents basés sur les LLM sur des environnements dynamiques temps réel.
Lien vers l'article :https://go.hyper.ai/lPyT2
Générer des mondes 3D immersifs et interactifs à partir de texte ou d'images reste un défi fondamental en vision par ordinateur et en graphisme. Les méthodes de génération de mondes existantes souffrent de limitations telles qu'une cohérence 3D insuffisante et une faible efficacité de rendu. Pour y remédier, cet article propose un cadre innovant, HunyuanWorld 1.0, permettant de générer des scènes 3D immersives, explorables et interactives à partir de texte et d'images.
Lien vers l'article :https://go.hyper.ai/aMbdz
Malgré les progrès récents en matière de génération de texte en code à l'aide de grands modèles de langage (LLM), de nombreuses méthodes existantes s'appuient uniquement sur des signaux en langage naturel, peinant à saisir efficacement la structure spatiale des mises en page et l'intention de conception visuelle. À l'inverse, le développement d'interfaces utilisateur concrètes est intrinsèquement multimodal et commence souvent par des esquisses ou des prototypes visuels. Pour combler cette lacune, cet article propose ScreenCoder, un framework multi-agents modulaire qui permet la génération d'interfaces utilisateur en code à travers trois phases interprétables : localisation, planification et génération.
Lien vers l'article :https://go.hyper.ai/k4p58
4. ARC-Hunyuan-Video-7B : Compréhension vidéo structurée de courts métrages du monde réel
Les modèles multimodaux à grande échelle actuels ne disposent pas des capacités de compréhension vidéo temporellement structurées, détaillées et approfondies nécessaires, pourtant essentielles à une recherche et une recommandation vidéo efficaces, ainsi qu'aux applications vidéo émergentes. Cette étude propose ARC-Hunyuan-Video, un modèle multimodal qui traite les signaux visuels, audio et textuels de bout en bout à partir d'entrées vidéo brutes pour une compréhension structurée. Ce modèle offre une description et un résumé vidéo horodatés multigranulaires, des réponses à des questions vidéo ouvertes, une localisation temporelle vidéo et un raisonnement vidéo.
Lien vers l'article :https://go.hyper.ai/ogYbH
5. Deep Researcher avec diffusion en temps de test
Lors de l'utilisation d'algorithmes courants de mise à l'échelle du temps de test pour générer des rapports de recherche complexes et longs, leurs performances sont souvent freinées. Inspiré par la nature itérative du processus de recherche humaine, cet article propose le Test-Time Diffusion Deep Researcher (TTD-DR). Le TTD-DR démarre le processus par une ébauche préliminaire (un cadre actualisable) qui sert de base évolutive pour orienter la recherche. Cette conception centrée sur l'ébauche rend la rédaction du rapport plus rapide et cohérente, tout en réduisant la perte d'informations lors de la recherche itérative.
Lien vers l'article :https://go.hyper.ai/D4gUK
Autres articles sur les frontières de l'IA :https://go.hyper.ai/iSYSZ
Interprétation des articles communautaires
Une équipe dirigée par Shi Boxin de l'Université de Pékin, en collaboration avec OpenBayes Bayesian Computing, a lancé PanoWan, un framework pour la génération de vidéos panoramiques guidées par texte. Cette approche, grâce à son architecture modulaire minimaliste et efficace, transfère de manière transparente les priors génératifs des modèles texte-vidéo pré-entraînés au domaine panoramique.
Voir le rapport complet :https://go.hyper.ai/9UWXl
Une équipe de recherche de l'Universiti Putra Malaysia (UPM) et de l'Université de Nouvelle-Galles du Sud (UNSW) à Sydney a développé conjointement un cadre intelligent pour la classification automatique et l'estimation de la valeur marchande des objets en céramique, basé sur le modèle YOLOv11. Ce modèle optimisé permet d'identifier les attributs clés de la céramique, tels que les motifs décoratifs, les formes et le savoir-faire, et de prédire les prix du marché à partir de caractéristiques visuelles extraites et de données d'enchères multisources. Il offre ainsi une solution évolutive pour l'authentification intelligente des céramiques et la conservation des objets numériques.
Voir le rapport complet :https://go.hyper.ai/XcuLz
Une équipe de recherche de l'Université de Pennsylvanie, aux États-Unis, a intégré quatre bases de données majeures sur les venins afin de constituer une base de données mondiale. Elle a ensuite appliqué un modèle d'apprentissage profond de type séquence-fonction appelé APEX, spécifiquement utilisé pour explorer systématiquement les candidats antibactériens potentiels dans le protéome du venin. Ils ont finalement sélectionné 386 peptides candidats présentant un potentiel antibactérien et une faible similarité de séquence avec les AMP connus.
Voir le rapport complet :https://go.hyper.ai/u067l
Une équipe de recherche conjointe de NVIDIA, du Lawrence Berkeley National Laboratory, de l'Université de Californie à Berkeley et du California Institute of Technology a lancé FourCastNet 3 (FCN3), un système de prévision météorologique probabiliste basé sur l'apprentissage automatique, qui combine le traitement du signal sphérique avec un cadre d'ensembles de Markov cachés. Il peut produire une prévision à 15 jours en 60 secondes sur un seul GPU NVIDIA H100.
Voir le rapport complet :https://go.hyper.ai/JQh25
Le laboratoire Tongyi Wanxiang d'Alibaba a récemment publié en open source son modèle avancé de génération vidéo par IA, Wan2.2. Ce modèle, qui intègre une architecture Mixture of Experts (MoE), améliore efficacement la qualité de génération et l'efficacité de calcul, permettant un fonctionnement efficace sur les cartes graphiques grand public telles que la NVIDIA RTX 4090. Il a également été le pionnier d'un système de contrôle esthétique cinématographique, permettant un contrôle précis de l'éclairage, de la couleur, de la composition et d'autres effets esthétiques.
Voir le rapport complet :https://go.hyper.ai/RgFmY
Articles populaires de l'encyclopédie
1. DALL-E
2. Fusion de tri réciproque RRF
3. Front de Pareto
4. Compréhension linguistique multitâche à grande échelle (MMLU)
5. Apprentissage contrastif
Voici des centaines de termes liés à l'IA compilés pour vous aider à comprendre « l'intelligence artificielle » ici :

Suivi unique des principales conférences universitaires sur l'IA :https://go.hyper.ai/event
Voici tout le contenu de la sélection de l’éditeur de cette semaine. Si vous avez des ressources que vous souhaitez inclure sur le site officiel hyper.ai, vous êtes également invités à laisser un message ou à soumettre un article pour nous le dire !
À la semaine prochaine !








