Command Palette
Search for a command to run...
Les Primitives Au Niveau Des Tuiles Sont Intégrées À Des Mécanismes De Raisonnement automatique. L'initiateur De La Communauté TileAI Analyse En Profondeur La Technologie De Base Et Les Avantages De TileLang.

Le 5 juillet, la 7e édition du Salon des technologies Meet AI Compiler s'est clôturée avec succès à Pékin. Des experts du secteur ont partagé leurs dernières avancées et expériences pratiques et de mise en œuvre, tandis que des chercheurs universitaires ont détaillé les pistes de mise en œuvre et les avantages des technologies innovantes.
dans,Le Dr Lei Wang, fondateur de la communauté TileAI, a prononcé un discours intitulé « Bridge Programmability and Performance in Modern AI Workloads ».Le langage de programmation d'opérateur innovant TileLang est présenté de manière simple à comprendre, partageant ses concepts de conception de base et ses avantages techniques.
TileLang vise à améliorer l'efficacité de la programmation du noyau d'IA en découplant l'espace d'ordonnancement (y compris la liaison des threads, la mise en page, la tensorisation et le pipeline) du flux de données et en l'encapsulant dans un ensemble d'annotations et de primitives personnalisables. Cette approche permet aux utilisateurs de se concentrer sur le flux de données du noyau lui-même, tout en laissant la plupart des autres tâches d'optimisation au compilateur.
Les résultats de l’évaluation montrent queTileLang atteint des performances de pointe sur plusieurs noyaux clés.Il démontre pleinement son paradigme de programmation Block-Thread unifié et ses capacités de planification transparente, qui peuvent fournir les performances et la flexibilité requises pour le développement de systèmes d'IA modernes.
HyperAI a compilé et résumé le discours sans en compromettre l'intention initiale. Voici la transcription du discours.
Suivez le compte public WeChat « HyperAI Super Neuro » et répondez au mot-clé « 0705 AI Compiler » pour obtenir le discours PPT du conférencier autorisé.
Pourquoi avons-nous besoin d’un « nouveau DSL » ?
Ce partage présente principalement le nouveau DSL TileLang pour les charges de travail d'IA que notre équipe a open-source sur GitHub en janvier 2025.
Tout d’abord, j’aimerais vous parler de la raison pour laquelle nous avons besoin d’un nouveau DSL ?
D'un point de vue personnel, lors de mon stage chez Microsoft, j'ai participé à un projet appelé BitBLAS pour étudier le calcul en précision mixte. À l'époque, il reposait principalement sur la méthode TVM/Tensor IR et a finalement obtenu d'excellents résultats expérimentaux. Cependant, nous avons constaté de nombreux problèmes, notamment des difficultés de maintenance. Pour chaque opérateur, comme le calcul en précision mixte de la couche matricielle, j'ai écrit 500 lignes de primitives de planification. Bien que rédigé avec élégance,Mais je suis le seul à pouvoir comprendre ce code de planification, et il est difficile de trouver d'autres personnes pour le maintenir ou l'étendre.
De plus, j'ai constaté qu'il était difficile de décrire de nouvelles exigences ou optimisations basées sur le Schedule IR. Par exemple, lorsque je travaillais sur le noyau, j'ai écrit trois primitives de Schedule pour faciliter l'optimisation du programme, notamment Flash Attention, Linear Attention, etc. Ces opérateurs étaient difficiles à décrire à partir du Schedule. Par conséquent, j'ai pensé à l'époque que si le projet devait continuer à évoluer, l'utilisation du TIR pourrait ne pas fonctionner et que d'autres solutions seraient nécessaires.
Alors pourquoi pas Triton ?
J'ai aussi essayé Triton,Mais j’ai trouvé difficile de personnaliser un noyau hautes performances.Par exemple, lorsque j'écris l'opérateur Dequantize, je peux avoir besoin de contrôler le comportement de chaque thread. L'implémentation de la déquantification de chaque thread sur un noyau hautes performances reste très complexe.
La deuxième est de savoir comment mettre en cache le tampon dans une étendue de mémoire appropriée.Par exemple, sur certains GPU, il est préférable de mettre les données en cache dans des registres pour les déquantifier, puis de les écrire en mémoire partagée ; sur d'autres, il est préférable de les réécrire directement en mémoire partagée. Cependant, cette opération est difficile à contrôler sur Triton.
enfin,Je pense que l'index de Triton est un peu compliqué.Par exemple, si vous devez mettre en cache une tuile en local, vous devez écrire le code indiqué sur le côté gauche de la figure ci-dessous, mais sur le Tensor IR, vous pouvez utiliser des indices pour indexer comme indiqué sur la droite, ce qui, je pense, est très bien.
Sur cette base, j'ai constaté que les DSL existants ne pouvaient pas répondre à mes besoins. Nous avons donc voulu créer un DSL innovant qui prend en charge davantage de backends et d'opérateurs personnalisés et qui offre de meilleures performances.Pour obtenir de meilleures performances, il est nécessaire d'optimiser divers espaces de conception tels que le carrelage et le pipeline.À cette fin, nous avons proposé le projet TileLang.
Qu'est-ce que TileLang ?
Pourquoi « Tile » ?
Premièrement, nous avons constaté l'importance du concept de Tile. Tant que le matériel intègre les concepts de cache, de registres et de mémoire partagée, l'écriture de programmes hautes performances nécessite de prendre en compte les blocs de calcul, c'est-à-dire Tile. Deuxièmement, comme tout le monde a tendance à écrire des programmes en Python, nous souhaitons concevoir un langage de programmation similaire à Python, aussi simple à écrire que Triton et plus performant.
À cette fin, nous avons conçu le cadre présenté sur le côté droit de la figure suivante :Si vous êtes un expert,Autrement dit, si vous connaissez bien CUDA ou le matériel, vous pouvez écrire directement du code de bas niveau ;Si vous êtes un développeur,Autrement dit, si vous pouvez écrire Triton et comprendre des concepts tels que Tile et register, vous pouvez écrire un programme de niveau Tile comme si vous écriviez Triton ;Si vous êtes un débutant qui ne connaît rien au matériel et ne connaît que les algorithmes,Vous pouvez ensuite écrire une expression de haut niveau comme l'écriture TRL, puis utiliser la planification automatique pour l'abaisser dans le code correspondant.
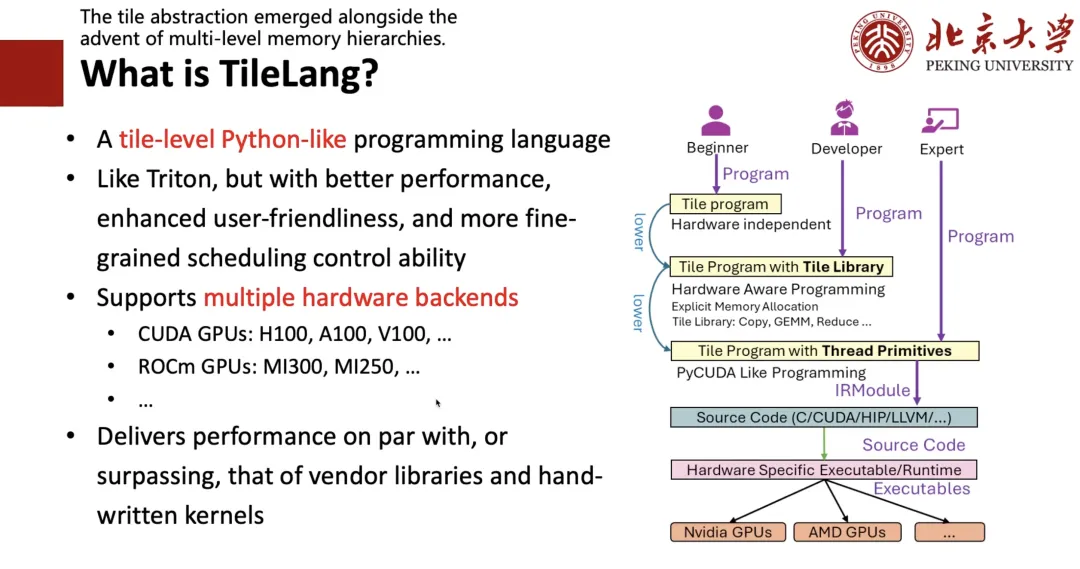
Comme le montre la figure ci-dessous, le programme Dequant à gauche est écrit par moi en utilisant TIR, qui peut être écrit de manière équivalente sous la forme de TileLang à droite, réalisant la coexistence du niveau 1 et du niveau 2.

Ensuite, je présenterai les problèmes à prendre en compte dans la conception de TileLang.
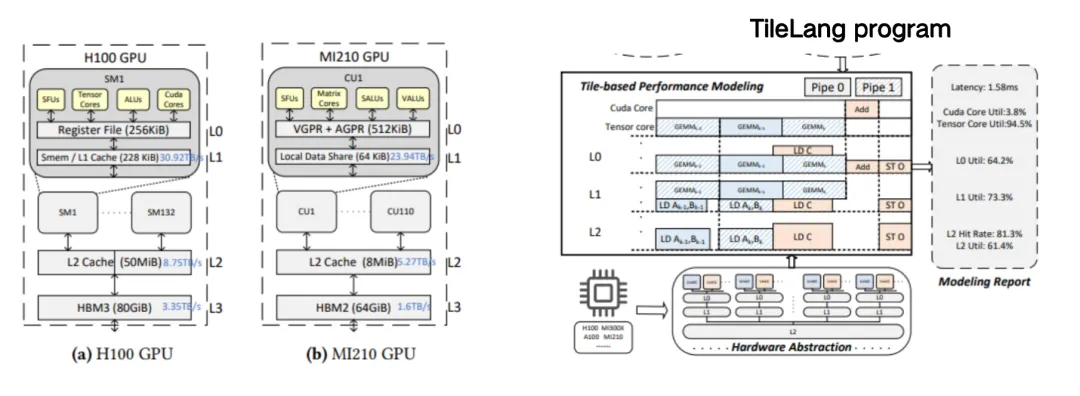
La partie gauche de la figure ci-dessous représente l'implémentation TileLang de DeepSeek MLA, qui compte environ 50 lignes de code. Dans ce noyau, nous constatons que les utilisateurs doivent gérer de nombreux aspects, comme le nombre de blocs (blocs de threads) à spécifier pour exécuter des tâches de calcul en parallèle lors du démarrage d'un noyau GPU (fonction noyau), et le nombre de threads à attribuer à chaque bloc. C'est ce que nous appelons la configuration Tile, c'est-à-dire que chaque code ci-dessous possède un contexte. Les utilisateurs doivent contrôler l'étendue mémoire du tampon, ainsi que la disposition de la mémoire partagée ou des registres, et prêter attention aux pipelines, etc. Toutes ces opérations nécessitent l'aide du compilateur.

À cette fin, nous divisons l’espace d’optimisation en deux catégories :L’une d’elles est l’inférence.Autrement dit, le compilateur aide directement l’utilisateur à trouver une meilleure solution ;L'un est recommandé,C'est-à-dire, sélectionner un plan par recommandation.
Après avoir considéré tous les espaces d’optimisation,Nous avons compressé une implémentation FlashMLA hautes performances qui comprenait à l'origine plus de 500 blocs de code en seulement 50 lignes de code TileLang, tout en conservant les performances de 95%.
Ensuite, je vais présenter TileLang depuis le tout début.
Comme le montre la figure ci-dessous, les étudiants familiarisés avec TIR devraient être capables de déterminer qu'il s'agit d'une expression TIR. Nous pouvons ensuite programmer avec PyCUDA en utilisant TIR. Par exemple, si nous écrivons deux boucles négatives Python, nous pouvons les générer en expressions CUDA grâce à TIR Codegen.
Si nous utilisons des primitives de thread, comme la vectorisation, nous pouvons implémenter la vectorisation CUDA et, plus précisément, la liaison de threads. Tous ces programmes sont déjà présents dans TIR, et les utilisateurs peuvent écrire des programmes comme CUDA, mais l'écriture en Python reste plus complexe.
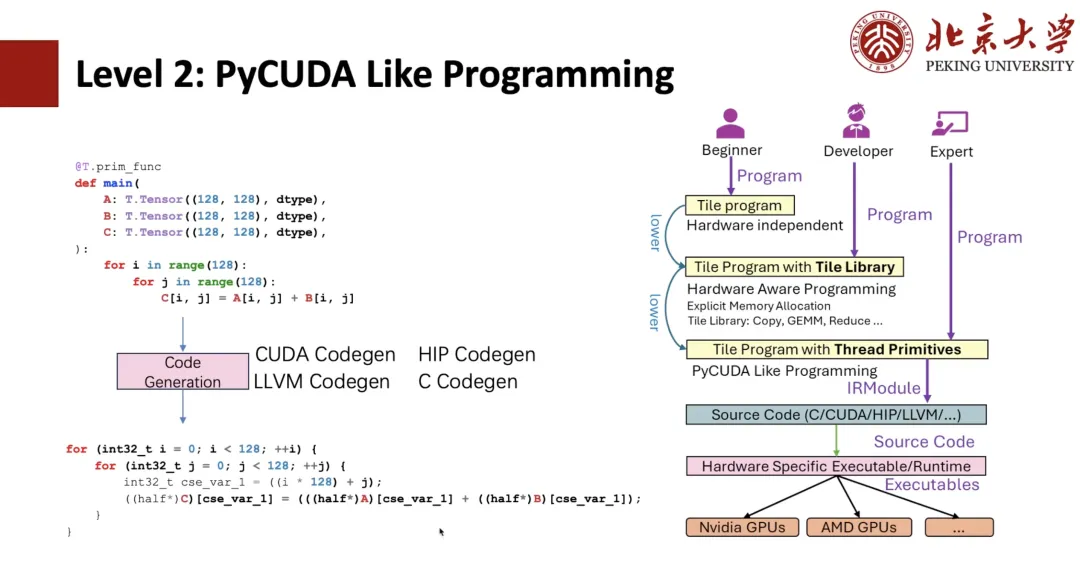
Afin de faciliter l'opération pour les utilisateurs,La méthode d'écriture de la bibliothèque de tuiles de niveau 1 a été proposée.Par exemple, nous donnons un contexte de noyau avec 128 threads, puis nous encapsulons Copy avec « T.Parallel ». Après l'inférence du compilateur, il peut déduire la forme haute performance présentée précédemment, puis générer du code en code CUDA. Pour plus d'élégance, vous pouvez écrire directement « T.copy » et développer Copy dans l'expression « T.Parallel ».
T.Parallel peut non seulement effectuer des copies, mais aussi des calculs complexes, et implémenter automatiquement la vectorisation et la liaison de threads. Actuellement, outre la copie, nous proposons également une collection de bibliothèques de tuiles telles que Reduce, Fill, Clear, etc. Grâce à cette bibliothèque, vous pouvez ensuite écrire un opérateur performant comme Triton.
Donc,Le concept de base qui prend en charge « T.Parallel » est la disposition de la mémoire.
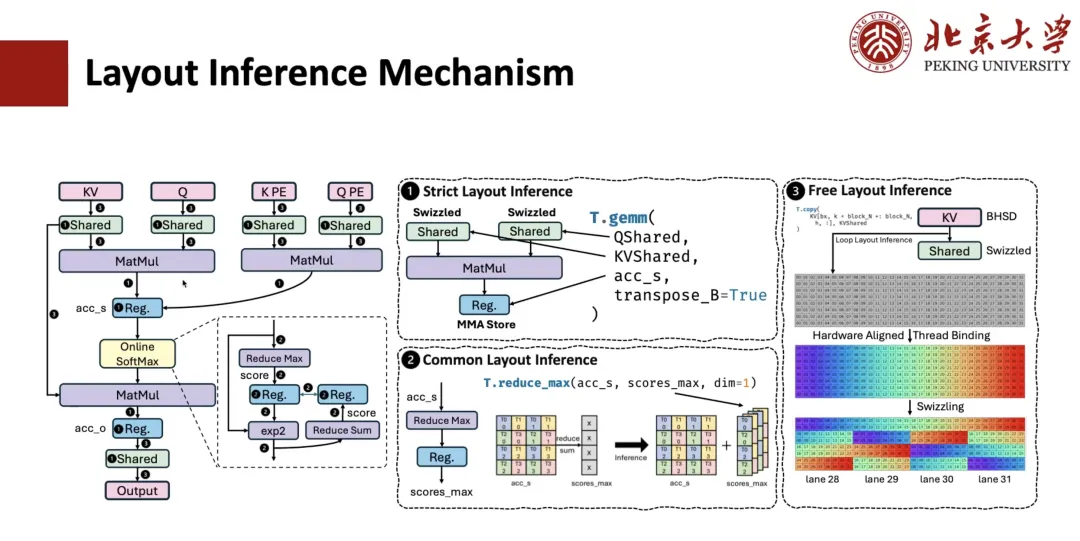
Dans TileLang, nous prenons en charge l'indexation de tableaux multidimensionnels à l'aide d'interfaces de haut niveau, telles que A[i, k]. Cet index de haut niveau est finalement converti en adresse mémoire physique via une série de couches d'abstraction logicielles et matérielles. Afin de modéliser ce processus de conversion d'index,Nous avons introduit la mise en page pour décrire comment les données sont organisées et mappées dans la mémoire.
Comment la dérivation de la mise en page pour les calculs MLA est-elle mise en œuvre ? Ce processus comprend généralement trois étapes.
La première étape est l’inférence de mise en page stricte.Par exemple, des opérateurs comme la multiplication matricielle ont de fortes contraintes sur la disposition des données et doivent respecter la disposition spécifiée ; la disposition des registres qui y sont connectés est donc également déterminée. Si une mémoire partagée est impliquée et que nous savons que cet opérateur doit effectuer une opération de débordement, la disposition mémoire correspondante sera également déterminée.
La deuxième étape est l’inférence de disposition commune.Par exemple, pour les expressions liées à la disposition déterminée à l'étape précédente, leur disposition doit également être déterminée. Par exemple, supposons une opération de réduction de accum_s à scope_max, où la disposition de QMS est spécifiée via la couche matricielle ; nous pouvons alors en déduire la disposition de scope_max. Grâce à ce niveau de raisonnement général, la disposition de la plupart des expressions intermédiaires peut être déterminée.
La troisième étape est l’inférence de mise en page libre.Autrement dit, la disposition libre restante est déduite. Comme elle n'est pas fortement contrainte, des stratégies d'inférence de disposition adaptées au matériel sont généralement adoptées pour déduire la solution de disposition optimale en fonction du mode d'accès et de la portée mémoire.
Ce qui suit décrit comment Pipeline effectue la dérivation.
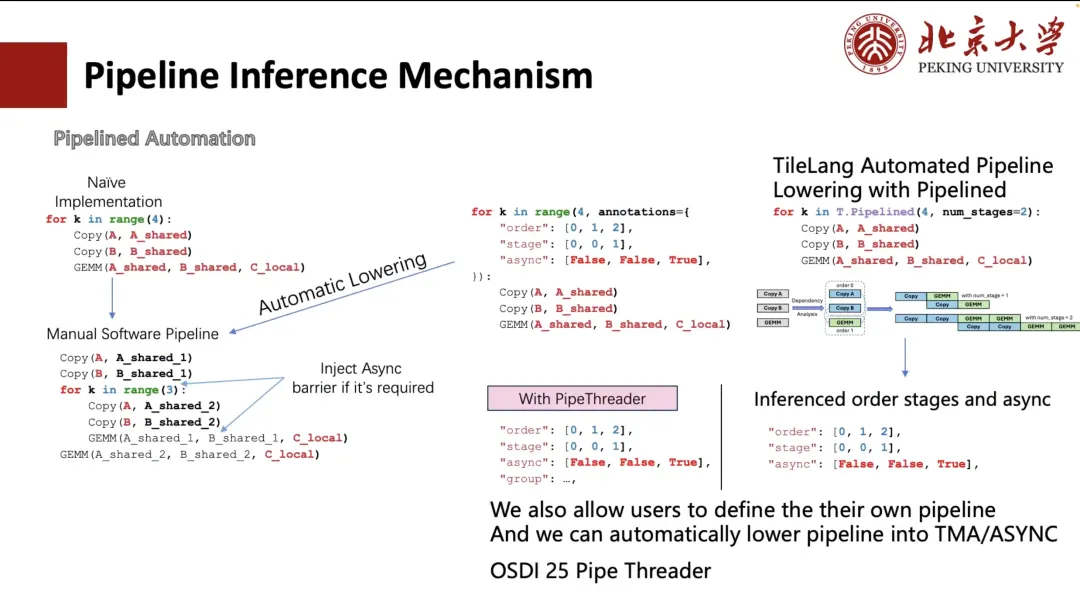
En général, nous pouvons étendre manuellement le pipeline, mais cette méthode d'écriture est fastidieuse et peu conviviale. TVM a donc cherché à simplifier le processus grâce à l'annotation. Les utilisateurs n'ont qu'à spécifier l'ordre d'exécution et l'étape de planification de la boucle.TVM peut transformer automatiquement la boucle en une structure équivalente au déroulement manuel (comme indiqué dans le coin inférieur gauche de la figure ci-dessous).
Cependant, cela reste complexe et problématique pour les utilisateurs. C'est pourquoi, dans TileLang, nous le réduisons à « num_stage ». Il suffit aux utilisateurs de spécifier la valeur « num_stage » pour que le système analyse automatiquement les dépendances dans le calcul et la planification, et les répartisse en conséquence. Sur GPU ou la plupart des autres appareils, seuls Copy et GEMM permettent une exécution véritablement asynchrone, notamment l'opération Copy, qui prend en charge la transmission asynchrone via des mécanismes tels que ASYNC ou TMA.
donc,Lors de la planification, nous séparerons l’opération de copie en une étape distincte.Et dérivez automatiquement la division des étapes appropriée pour l'ensemble du pipeline. Bien entendu, les utilisateurs peuvent également choisir de spécifier manuellement la méthode de planification, comme les deux configurations personnalisées illustrées dans la figure de gauche.
De plus, nous prenons également en charge l'inférence automatique de mise en page et l'optimisation de la planification en fonction des fonctionnalités matérielles (comme les modules TMA sur A100 et H100). Cette partie du travail est issue de notre projet Pipe Threader, qui sera publié à l'OSDI 25 cette année.
Ensuite, je vais partager avec vous l’inférence des instructions.
Prenons l'exemple de la multiplication matricielle : de nombreuses instructions matérielles peuvent être appelées pour « T.GEMM ». Par exemple, avec une précision INT8, il est possible d'utiliser des instructions DP4A ou une implémentation INT8 basée sur TensorCore. De plus, chaque instruction prend en charge plusieurs formes ; le choix de la configuration de tuiles optimale parmi ces implémentations est donc crucial.
À cette fin, TileLang propose deux modes d'utilisation :
La première est que TileLang permet aux utilisateurs d’écrire de l’ASM en appelant PTX.L'inconvénient de cette méthode est son immense espace de combinaison : pour être compatible avec tous les PTX, il faut écrire beaucoup de code et gérer la mise en page. Cependant, cette méthode est très libre et je l'apprécie personnellement beaucoup.
Mais nous utilisons maintenant la deuxième méthode.Autrement dit, « T.GEMM » est suivi d'une bibliothèque de tuiles telle que CUTE/CK-TILE.Il fournit une interface de bibliothèque au niveau des tuiles, couramment utilisée pour la multiplication de matrices, mais son inconvénient est sa très longue compilation due à l'expansion des modèles. Sur RTX 4090, la compilation d'une Flash Attention peut prendre 10 secondes, dont plus de 90% sont consacrées à l'expansion des modèles. Un autre problème est son isolement important par rapport au front-end Python.
Alors nous pensons,La bibliothèque de tuiles est une direction sur laquelle nous nous concentrerons à l’avenir.Autrement dit, grâce à la syntaxe native de Tile, diverses bibliothèques de niveau Tile telles que « T.GEMM » et « T.GEMMSP » sont prises en charge.
Perspectives d'avenir
Enfin, j’aimerais vous présenter quelques travaux futurs de notre équipe.
Le premier est Tile Sight, qui est spécifiquement conçu pour accélérer l’optimisation des performances des noyaux complexes à grande échelle (tels que FlashAttention et FlashMLA) dans les grands modèles de langage.Il s'agit d'un framework de réglage automatique léger qui vise à générer et à évaluer des configurations de tuiles efficaces (c'est-à-dire des stratégies de mosaïque ou des conseils de planification) pour plusieurs backends tels que les GPU, les CPU et les accélérateurs, aidant les développeurs à trouver rapidement des stratégies de planification avec des performances supérieures et à réduire le temps de réglage manuel.
Grâce au modèle personnalisé ci-dessus, il est plus facile pour les utilisateurs d'écrire un noyau complexe, tel que MLA. Ce modèle personnalisé peut guider les utilisateurs pour placer chaque cache sur le partage correspondant.
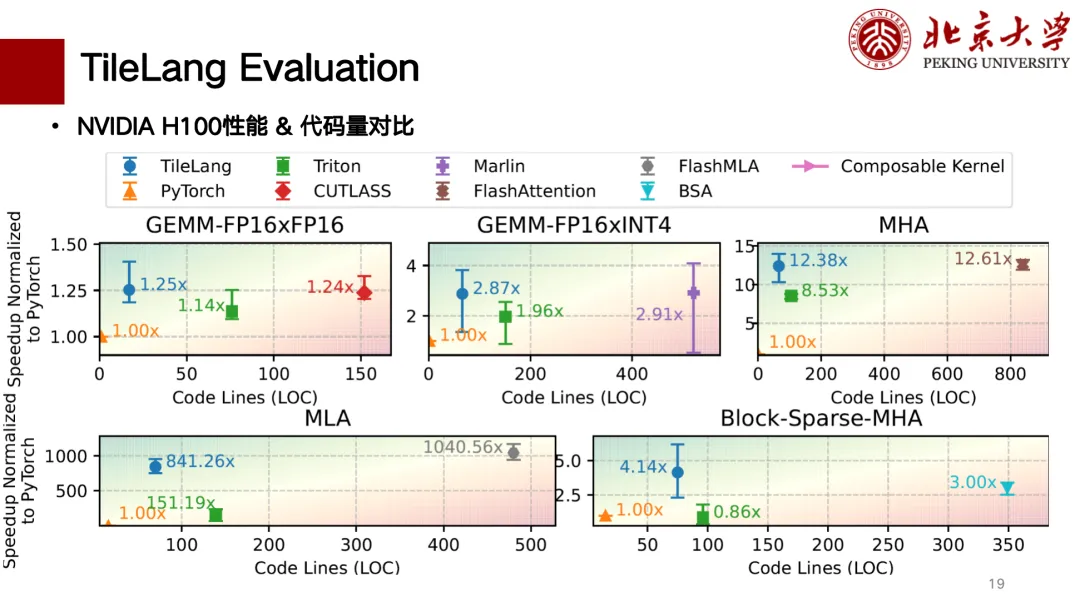
Vous trouverez ci-dessous une évaluation partielle des performances de TileLang. Nous avons principalement terminé la prise en charge des cartes H et A. La figure ci-dessous présente un tableau comparatif de corrélation entre le nombre de lignes de code et les performances. Les performances sont meilleures en haut à gauche. Parmi ces dernières, pour la multiplication matricielle, TileLang atteint des performances similaires à celles de CUTLASS. De plus, des opérateurs tels que MLA, Flash Attention, Block Sparse, etc., offrent également des performances similaires à celles de CUTLASS. Le nombre de lignes de code est relativement faible et l'écriture est relativement propre.
Certains utilisateurs de l'écosystème TileLang l'utilisent déjà. Par exemple, l'opérateur de quantification principal du modèle BitNet basse précision de Microsoft est développé sur la base de TileLang, et BitBLAS de Microsoft est également entièrement basé sur TileLang. Concernant la prise en charge des puces domestiques, nous avons également pris en charge Suanneng TPU et Ascend NPU.








