Command Palette
Search for a command to run...
Les Performances d'entraînement Ont Été Considérablement améliorées. Zheng Size, De Bytedance, Explique Le Framework Distribué Triton Pour Une Communication Distribuée Efficace Et Une Intégration Informatique Pour Les Grands modèles.

En 2025, le salon technologique Meet AI Complier, organisé par HyperAI, en est à sa 7e édition. Avec le soutien de partenaires communautaires et de nombreux experts du secteur, nous avons établi plusieurs bureaux à Pékin, Shanghai, Shenzhen et ailleurs afin d'offrir une plateforme de communication aux développeurs et aux passionnés, de dévoiler les secrets des technologies pionnières, de recueillir les retours d'expérience des développeurs de terrain, de partager des expériences pratiques de mise en œuvre technologique et d'écouter les idées innovantes sous différents angles.
Suivez le compte public WeChat « HyperAI Super Neuro » et répondez au mot-clé « 0705 AI Compiler » pour obtenir le discours PPT du conférencier autorisé.




Dans le discours d'ouverture « Triton-distributed : Programmation Python native pour les communications hautes performances »,Zheng Size, chercheur scientifique en semences chez ByteDanceIl analyse en détail la percée en matière d'efficacité de communication et d'adaptabilité multiplateforme de la formation distribuée par Triton dans les grands modèles, ainsi que la manière de parvenir à une intégration profonde de la communication et de l'informatique grâce à la programmation Python.Après le partage, la scène a rapidement été saturée de questions. Les discussions ont été interminables sur des détails tels que le framework FLUX, le modèle de programmation Tile, l'optimisation AllGather et ReduceScatter, etc. Les discussions ont porté sur les principales difficultés techniques et l'expérience pratique, favorisant ainsi efficacement l'alliance de la théorie et de la pratique.
HyperAI a compilé et résumé le discours de M. Zheng Size sans en compromettre l'intention initiale. Voici la transcription de son discours.
Les vrais défis de la formation distribuée
Dans le contexte de l’évolution rapide des grands modèles, la formation et le raisonnement sont tous deuxLes systèmes distribués sont devenus un élément indispensable.Nous avons également mené une exploration au niveau du compilateur dans cette direction et avons ouvert le projet en le nommant Triton-Distributed.
Les principales méthodes d'interconnexion matérielle actuelles incluent NVLink, PCIe et la communication réseau inter-nœuds. Dans des conditions idéales, la bande passante unidirectionnelle NVLink du H100 peut atteindre 450 Gbit/s, mais dans la plupart des déploiements domestiques, le H800 est le plus courant, dont la bande passante unidirectionnelle n'est que d'environ 200 Gbit/s, ce qui réduit considérablement les capacités de communication globales et la complexité de la topologie.Un défi évident que nous avons rencontré dans le projet était le goulot d’étranglement des performances du système causé par une bande passante insuffisante et une topologie de communication asymétrique.
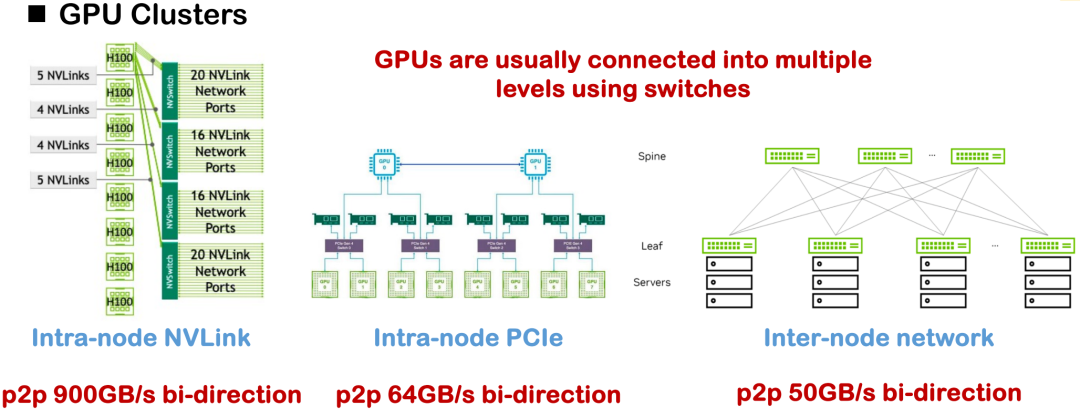
Dans ce contexte, les premières optimisations distribuées reposaient souvent sur un grand nombre d'opérateurs de communication implémentés manuellement, notamment des stratégies telles que le parallélisme tenseur, le parallélisme pipeline et le parallélisme données, qui nécessitaient toutes une écriture minutieuse de la logique de communication sous-jacente. Une pratique courante consiste à faire appel à des bibliothèques de communication telles que NCCL et ROCm CCL, mais ces solutions manquent souvent de polyvalence et de portabilité, et présentent des coûts de développement et de maintenance élevés.
Lors de l’analyse des goulots d’étranglement du système existant, nous avons résumé 3 faits clés :
Fait 1 : La bande passante matérielle est limitée et la latence de communication devient un goulot d’étranglement
La première limite est liée aux conditions matérielles de base. Si H100 est utilisé pour entraîner un modèle de grande taille, le délai de calcul est souvent nettement supérieur au délai de communication ; il n'est donc pas nécessaire de prêter une attention particulière au chevauchement des ordonnancements de calcul et de communication. Cependant, dans l'environnement H800 actuel, le délai de communication est considérablement allongé. Nous avons évalué que, dans certains scénarios, près de la moitié du temps d'entraînement sera absorbée par le délai de communication, ce qui entraînera une diminution significative de l'utilisation globale de l'échelle du modèle (MSU). Si le chevauchement des communications et du calcul n'est pas optimisé, le système sera confronté à de graves problèmes de gaspillage de ressources.
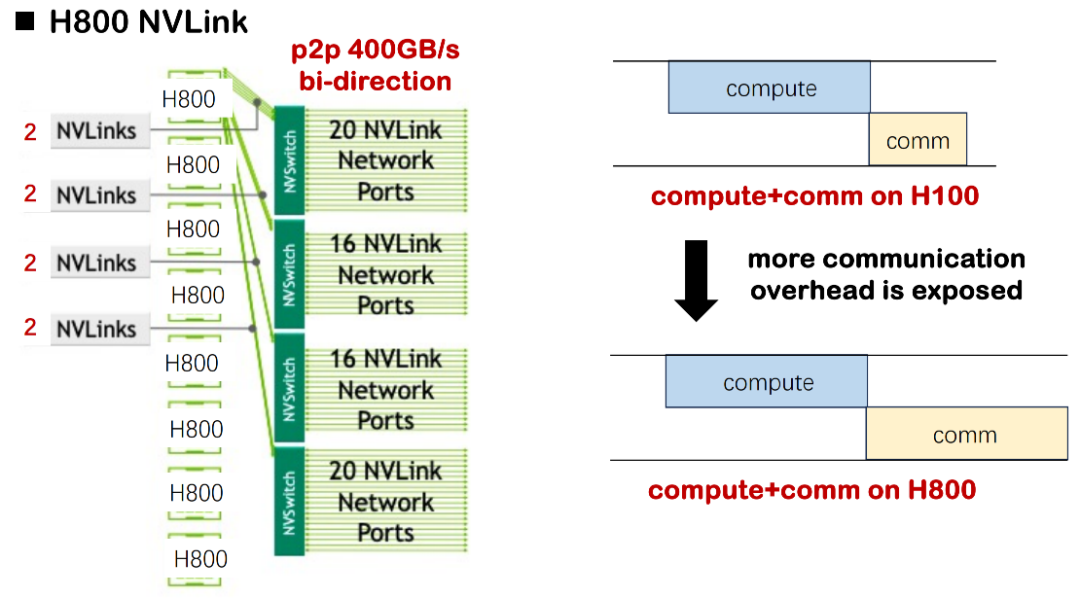
Dans les cas de petite et moyenne taille, cette perte est acceptable ; mais une fois que le modèle est étendu à des milliers de cartes, comme dans la pratique de formation de MegaScale ou DeepSeek, la perte de ressources accumulée atteindra des millions, voire des dizaines de millions de dollars, ce qui représente une pression sur les coûts très réelle pour les entreprises.
Il en va de même pour les scénarios d'inférence. Le premier déploiement d'inférence de DeepSeek utilisait jusqu'à 320 cartes. Malgré la compression et l'optimisation ultérieures, la latence de communication reste un problème majeur et inévitable des systèmes distribués. Par conséquent, planifier efficacement la communication et le calcul au niveau du programme et améliorer l'efficacité globale est devenu un enjeu crucial auquel nous devons nous attaquer de front.
Fait 2 : une surcharge de communication élevée affecte directement les performances du MFU
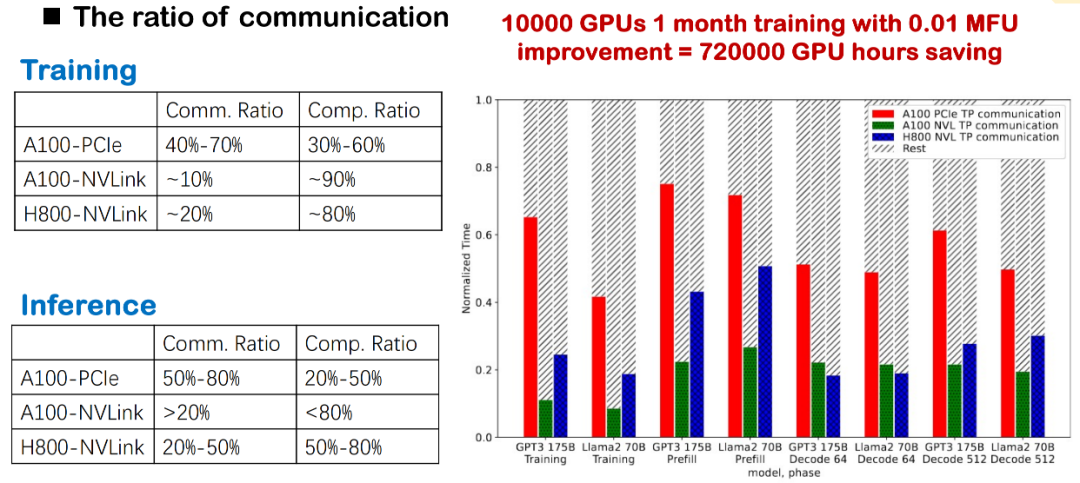
Dans l'entraînement et le raisonnement actuels des modèles à grande échelle, la surcharge de communication constitue toujours un goulot d'étranglement majeur. Nous avons observé que, que la couche sous-jacente utilise NVLink, PCIe ou différentes générations de GPU (comme A100 et H800), la proportion de communication est très élevée. En particulier dans les déploiements domestiques réels, en raison de limitations de bande passante plus évidentes, les retards de communication réduisent directement l'efficacité globale.
Pour l'entraînement de modèles de grande taille, cette communication inter-cartes haute fréquence réduira considérablement le MFU du système. Par conséquent, l'optimisation de la charge de communication est un point d'amélioration essentiel pour optimiser les performances d'entraînement et d'inférence, et constitue également l'un de nos axes prioritaires.
Fait 3 : L'écart entre programmabilité et performance
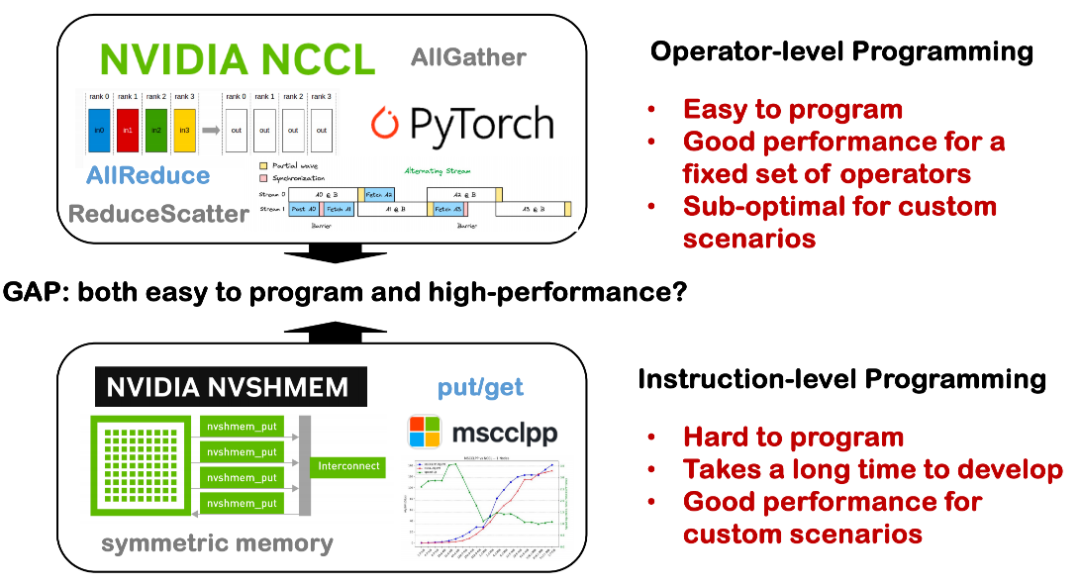
Actuellement, il existe encore un écart important entre programmabilité et performances dans les systèmes distribués. Par le passé, nous accordions davantage d'attention aux capacités d'optimisation des compilateurs monocarte, notamment pour obtenir d'excellentes performances sur une seule carte. Mais lorsqu'on étend le système à une seule machine avec plusieurs cartes, voire à un système distribué sur plusieurs nœuds, la situation se complique.
D'une part, la communication distribuée implique de nombreux détails techniques sous-jacents, tels que NCCL, MPI et la topologie, dispersés dans diverses bibliothèques dédiées et dont le seuil d'utilisation est élevé. Dans de nombreux cas, les développeurs doivent implémenter manuellement la logique de communication, planifier manuellement les calculs et la synchronisation, ce qui entraîne des coûts de développement et des taux d'erreur élevés. D'autre part, l'existence d'outils capables de gérer automatiquement la planification complexe des communications et l'optimisation des opérateurs dans des conditions distribuées peut aider les développeurs à réduire considérablement le seuil de développement et à améliorer la disponibilité et la maintenabilité des systèmes distribués. C'est l'un des problèmes que nous espérons résoudre avec Triton-Distributed.
Sur la base des trois problèmes pratiques mentionnés ci-dessus, nous avons proposé trois directions principales dans Triton-Distributed :
Premièrement, promouvoir le mécanisme de chevauchement de la communication et de l’informatique.Dans les scénarios distribués où la surcharge de communication devient de plus en plus importante, nous espérons planifier autant que possible des fenêtres parallèles de calcul et de communication pour améliorer l'efficacité globale du système.
Deuxièmement, il est nécessaire d’intégrer et d’adapter en profondeur les modes de calcul et de communication des grands modèles.Par exemple, nous essayons d'intégrer les modèles de communication courants tels que AllReduce et Broadcast dans le modèle avec le modèle de calcul pour réduire l'attente synchrone et compresser le chemin d'exécution.
Enfin, nous pensons que ces optimisations devraient être effectuées par le compilateur plutôt que de compter sur les développeurs pour écrire à la main des implémentations CUDA hautement personnalisées.Rendre le développement des systèmes distribués plus abstrait et plus efficace est la direction vers laquelle nous travaillons.
Analyse de l'architecture distribuée Triton : Python natif pour une communication haute performance
Nous espérons obtenir un chevauchement lors de l'apprentissage distribué, mais sa mise en œuvre est complexe. Conceptuellement, le chevauchement consiste à effectuer simultanément des calculs et des communications via plusieurs flux afin de masquer les retards de communication. Cette opération est plus facile dans les scénarios où il n'y a pas de dépendance entre les opérateurs, mais en parallèle tenseur (TP) ou en parallèle expert (EP), AllGather doit être terminé avant l'exécution de GEMM. Ces deux méthodes se situent sur le chemin critique, et le chevauchement est très difficile.
Les méthodes courantes incluent actuellement : premièrement, la division de la tâche en plusieurs micro-lots et l'obtention d'un chevauchement avec l'indépendance des lots ; deuxièmement, le fractionnement à une granularité plus fine (par exemple, la granularité des tuiles) au sein d'un même lot et l'obtention d'effets parallèles grâce à la fusion de noyaux. Nous avons également exploré ce type de mécanisme de fractionnement et d'ordonnancement dans Flux. Parallèlement, le mode de communication lors de l'entraînement de grands modèles est extrêmement complexe. Par exemple, DeepSeek doit personnaliser la communication All-to-All lors de l'exécution de MoE afin de prendre en compte la bande passante et l'équilibrage de charge. Par exemple, dans les scénarios de raisonnement et de quantification à faible latence, les bibliothèques générales comme NCCL ont du mal à répondre aux exigences de performance et nécessitent souvent des noyaux de communication manuscrits, ce qui augmente les coûts de personnalisation.
Par conséquent, nous croyonsLa capacité d'optimisation de la fusion communication-informatique doit être prise en charge par la couche compilateur pour faire face à des structures de modèles complexes et à des environnements matériels divers, et éviter la charge de développement engendrée par une implémentation manuelle répétée.
Abstraction primitive de communication à deux couches
Dans la conception de notre compilateur, nous avons adopté une structure abstraite de primitives de communication à deux couches pour prendre en compte à la fois la capacité d'expression d'optimisation de la couche supérieure et la faisabilité du déploiement sous-jacent.
La première couche est une primitive de niveau relativement élevé, qui complète principalement la planification du calcul au niveau de la granularité des tuiles et fournit une interface abstraite pour la communication.Il utilise des opérations push/get entre les rangs comme abstractions de communication et distingue chaque comportement de communication via un mécanisme d'identification de balise, ce qui permet au planificateur de suivre plus facilement les flux de données et les dépendances.
La deuxième couche est plus proche de l’implémentation sous-jacente et utilise un système primitif similaire à la norme Open Shared Memory (OpenSHMEM).Cette couche est principalement utilisée pour mapper des bibliothèques de communication existantes ou des backends matériels afin de mettre en œuvre des comportements de communication réels.
aussi,Dans le scénario multi-rangs, nous devons également introduire des mécanismes de contrôle de barrière et de signal pour la synchronisation entre les rangs.Par exemple, lorsque vous devez informer d'autres rangs que vos données ont été écrites, ou lorsque vous attendez que les données d'un certain rang soient prêtes, ce type de signal de synchronisation est très critique.

Architecture du compilateur et modélisation sémantique
Concernant la pile de compilation, notre processus global repose toujours sur le framework de compilation Triton original. À partir du code source, Triton convertit d'abord le code utilisateur en arbre syntaxique abstrait (AST), puis le traduit en Triton IR. Dans la version distribuée de Triton que nous avons créée, nousLe Triton IR original a été étendu et une nouvelle couche IR pour la sémantique distribuée a été ajoutée.Cette IR distribuée introduit la modélisation sémantique des opérations de synchronisation, telles que wait et notify, afin de décrire les dépendances de communication entre les rangs. Parallèlement, nous concevons également un ensemble d'interfaces sémantiques pour OpenSHMEM afin de prendre en charge les appels de communication de bas niveau.
Lors de la phase de génération de code, cette sémantique peut être mappée à des appels externes à la bibliothèque de communication sous-jacente. Nous lions directement ces appels à la version bitcode de la bibliothèque (et non au code source) fournie par OpenSHMEM via la couche intermédiaire LLVM afin d'assurer une communication efficace en mémoire partagée entre les rangs. Cette méthode contourne la limitation de Triton qui ne prend pas en charge l'accès direct à une bibliothèque externe depuis le code source, permettant ainsi aux appels liés à la mémoire partagée de finaliser la résolution des symboles et la liaison en douceur lors de la compilation.
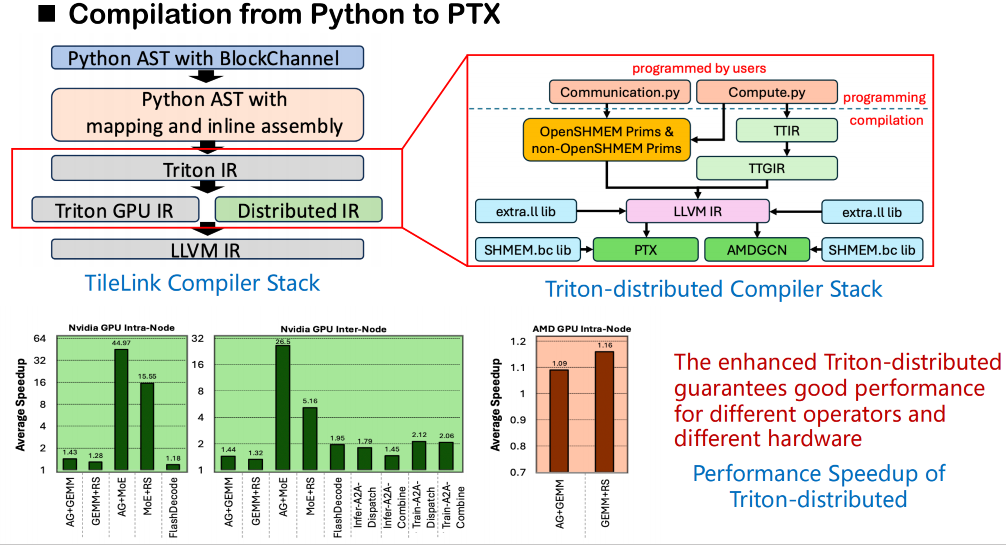
Mécanisme de mappage entre les primitives de haut niveau et l'exécution de bas niveau
Dans Triton-distributed, nous avons conçu un système de primitives de communication couvrant l'abstraction de haut niveau et le contrôle de bas niveau.Prenons l'exemple de consumer_tile_wait : il suffit aux développeurs de déclarer l'identifiant de la tuile à attendre, et le système déduit automatiquement le rang et le décalage spécifiques de la cible de communication en fonction de la sémantique de l'opérateur actuel (comme AllGather) pour finaliser la logique de synchronisation. Les primitives de haut niveau masquent les détails des sources de données spécifiques et de la transmission du signal, améliorant ainsi l'efficacité du développement.
En revanche, les primitives de bas niveau offrent des capacités de contrôle plus fines. Les développeurs doivent spécifier manuellement les pointeurs de signal, les portées (GPU ou système), la sémantique mémoire (acquisition, libération, etc.) et les valeurs attendues. Bien que ce mécanisme soit plus complexe, il convient aux scénarios exigeant une latence de communication et une précision de planification extrêmement élevées.
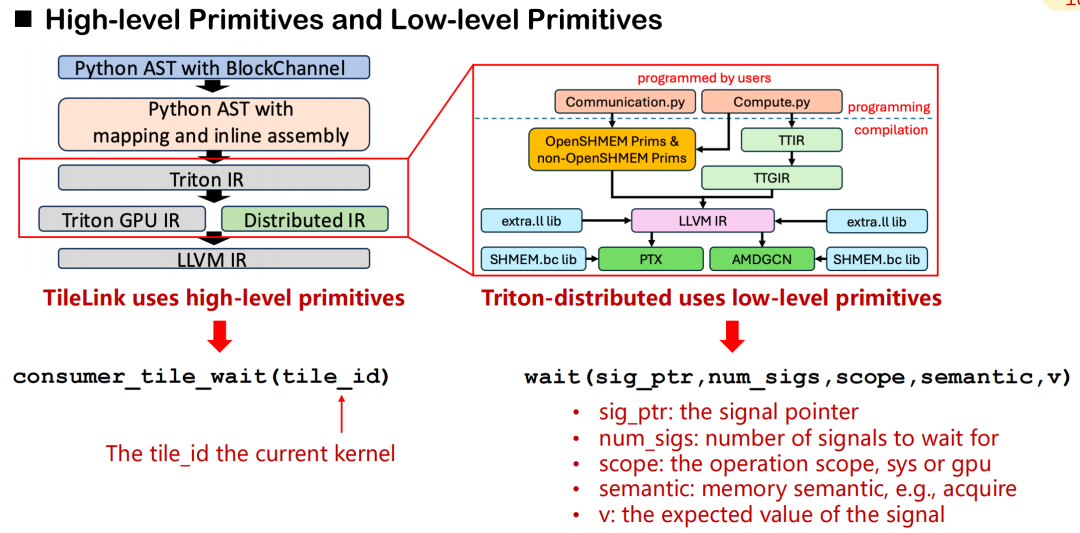
Les primitives de haut niveau peuvent être grossièrement divisées en deux catégories : le contrôle des signaux et le contrôle des données. Dans la sémantique du contrôle des signaux,Nous définissons principalement trois types de rôles : producteur, consommateur et pair.La synchronisation est assurée par des signaux de lecture et d'écriture, similaires au mécanisme de poignée de main des communications distribuées. Pour la transmission des données, Triton-Distributed propose deux primitives : push et pull, qui correspondent à l'envoi actif de données à la carte distante ou à l'extraction de données de la carte distante vers la carte locale.
Toutes les primitives de communication de bas niveau respectent la norme OpenSHMEM et prennent actuellement en charge NVSHMEM et ROCSHMEM. Il existe une relation de correspondance claire entre les primitives de haut et de bas niveau, et le compilateur est responsable de la conversion automatique des interfaces concises en instructions de synchronisation et de transmission de bas niveau. Grâce à ce mécanisme,Triton-distributed conserve non seulement les capacités de haute performance de la planification des communications, mais réduit également considérablement la complexité de la programmation distribuée.
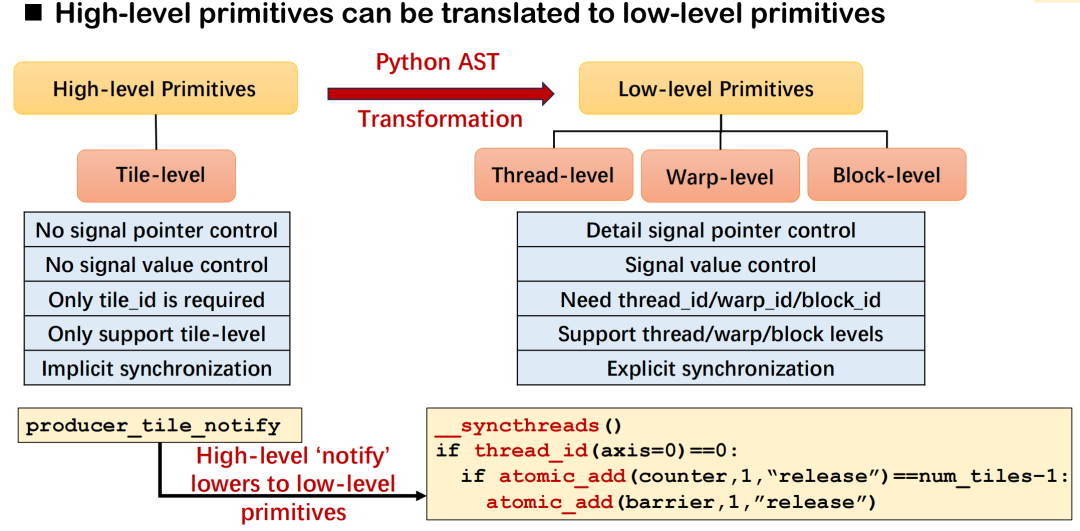
Dans la distribution Triton, l'objectif de conception des primitives de communication de haut niveau (telles que notify et wait) est de décrire les exigences de synchronisation entre cartes avec une sémantique concise. Le compilateur est chargé de les traduire en logique d'exécution sous-jacente correspondante. Prenons l'exemple de notify : it et wait forment une paire de sémantiques de synchronisation : la première sert à envoyer des notifications, et la seconde à attendre la fin de la préparation des données. Les développeurs n'ont qu'à spécifier l'identifiant de la tuile, et le système peut automatiquement déduire les détails sous-jacents, tels que les cibles de communication et les décalages de signal, en fonction du type d'opérateur et de la topologie de communication.
L'implémentation sous-jacente spécifique varie selon l'environnement de déploiement. Par exemple, dans un scénario avec 8 GPU, ce type de synchronisation peut être réalisé via _syncthreads() et atomic_dd au sein d'un thread ; dans un déploiement multi-machines, il s'appuie sur des primitives telles que signal_up fournies par NVSHMEM ou ROCSHMEM pour effectuer des opérations équivalentes. Ensemble, ces mécanismes constituent la relation de correspondance entre la sémantique de haut niveau et les primitives de bas niveau, et offrent une grande polyvalence et une bonne évolutivité.
Prenons l'exemple d'un scénario de communication GEMM ReduceScatter : supposons que le système comporte quatre GPU et que la position cible de chaque tuile est déterminée par des métadonnées précalculées (telles que l'allocation des tuiles et le numéro de barrière pour chaque rang). Il suffit aux développeurs d'ajouter une instruction de notification au noyau GEMM écrit en Triton, et le noyau ReduceScatter utilise l'attente pour recevoir les données de manière synchrone.
L'ensemble du processus peut être exprimé en Python et prend en charge le mode noyau de démarrage à double flux, avec une logique de communication claire et une planification simplifiée. Ce mécanisme améliore non seulement l'expressibilité de la programmation de communication inter-cartes, mais réduit également considérablement la complexité de l'implémentation sous-jacente, offrant ainsi un support solide pour l'entraînement et le raisonnement efficaces de grands modèles distribués.
Optimisation multidimensionnelle par chevauchement : du mécanisme de planification à la connaissance de la topologie
Bien que Triton-distributed ait fourni une interface primitive de communication de haut niveau relativement concise, certains obstacles techniques subsistent dans le processus d'écriture et d'optimisation du noyau. Nous avons constaté que, malgré une bonne expressivité de la conception primitive, le nombre d'utilisateurs réellement capables de l'appliquer avec souplesse et de l'optimiser en profondeur reste limité. En substance, l'optimisation de la communication reste une tâche qui repose fortement sur l'expérience des ingénieurs et la compréhension de la planification, et qui doit encore être contrôlée manuellement par les développeurs. Pour ce faire, nous avons résumé quelques pistes d'optimisation clés. Voici des stratégies d'implémentation typiques dans Triton-distributed.
Push vs. Pull : direction du flux de données et contrôle du nombre de barrières
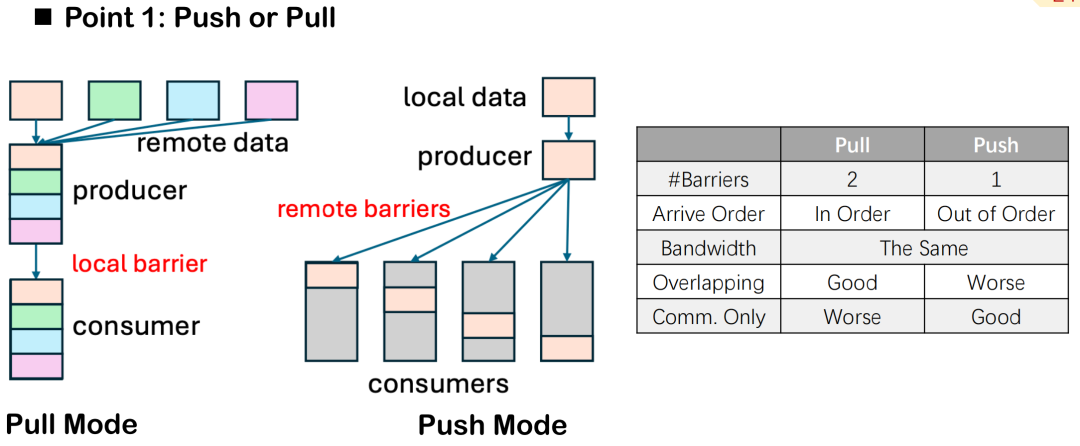
Dans l'optimisation du chevauchement de la communication et du calcul,Triton-distributed propose deux méthodes de transmission de données : push et pull.Bien que la différence sémantique entre eux ne soit que la direction de « l'envoi actif » et de « l'extraction passive », dans l'exécution distribuée réelle, il existe des différences évidentes dans leurs performances et leurs capacités de contrôle de planification.
Prenons l'exemple du nombre de barrières : le mode pull nécessite généralement deux barrières : l'une garantit que les données locales sont prêtes avant leur extraction par l'autre partie, et l'autre protège les données contre toute modification par la tâche locale pendant tout le cycle de communication, évitant ainsi les incohérences de données ou les conflits de lecture-écriture. En mode push, une seule barrière doit être définie après l'écriture des données à l'extrémité distante pour synchroniser tous les appareils, ce qui simplifie le contrôle global.
Cependant, le mode pull présente également des avantages. Il permet aux nœuds locaux de contrôler activement l'ordre d'extraction des données, planifiant ainsi plus précisément le timing des communications et le chevauchement des calculs. Pour maximiser l'effet de chevauchement et assurer le parallélisme entre les communications et les calculs, le mode pull offre une plus grande flexibilité.
En général, si l'objectif principal est d'améliorer le chevauchement, le mode pull est recommandé ; dans certaines tâches de communication pure, comme un noyau AllGather ou ReduceScatter séparé, le mode push est plus courant en raison de sa simplicité et de sa surcharge plus faible.
Swizzling Scheduling : ajustement dynamique de l'ordre en fonction de la localisation des données
Le chevauchement des communications et des calculs dépend non seulement du choix des primitives, mais aussi de la stratégie d'ordonnancement. Parmi celles-ci, Swizzling est une méthode d'optimisation de l'ordonnancement basée sur la reconnaissance topologique, qui vise à réduire les temps d'inactivité lors des calculs inter-cartes. D'un point de vue distribué, chaque carte GPU peut être considérée comme une unité d'exécution indépendante. Étant donné que chaque carte contient initialement des fragments de données différents, si toutes les cartes commencent à calculer à partir du même index de tuile, certains rangs devront attendre que les données soient prêtes, ce qui entraînera de longues périodes d'inactivité en phase d'exécution et réduira l'efficacité globale du calcul.
L'idée centrale de Swizzling est :Le décalage de calcul de départ est ajusté dynamiquement en fonction de l'emplacement des données locales existantes sur chaque carte.Par exemple, dans le scénario AllGather, chaque carte peut prioriser le traitement de ses propres données et lancer simultanément des extractions depuis des tuiles distantes, permettant ainsi une planification simultanée des communications et des calculs. Si toutes les cartes démarrent le traitement à partir de la tuile 0, seul le rang 0 peut démarrer immédiatement le calcul, et les rangs restants subiront des retards en série dus à l'attente des données.
Dans des situations plus complexes, comme le scénario ReduceScatter inter-machines, la stratégie Swizzling doit être conçue en fonction de la topologie du réseau. Prenons l'exemple de deux nœuds : une méthode d'ordonnancement raisonnable consiste à : donner la priorité au calcul des données requises par l'autre nœud, déclencher la communication point à point inter-machines le plus tôt possible ; et, pendant la transmission, calculer en parallèle les données requises par le nœud local afin de maximiser le chevauchement entre la communication et le calcul.
Actuellement, ce type d'optimisation de l'ordonnancement est encore contrôlé par le programmeur afin d'éviter que le compilateur ne sacrifie des chemins de performance clés lors de l'optimisation générale. Nous sommes également conscients que la compréhension de détails tels que Swizzling représente un seuil pour les développeurs. À l'avenir, nous espérons fournir davantage de cas pratiques et de codes modèles pour aider les développeurs à maîtriser plus rapidement le modèle de développement d'opérateurs distribués et à construire progressivement un écosystème de programmation distribué Triton ouvert et efficace.

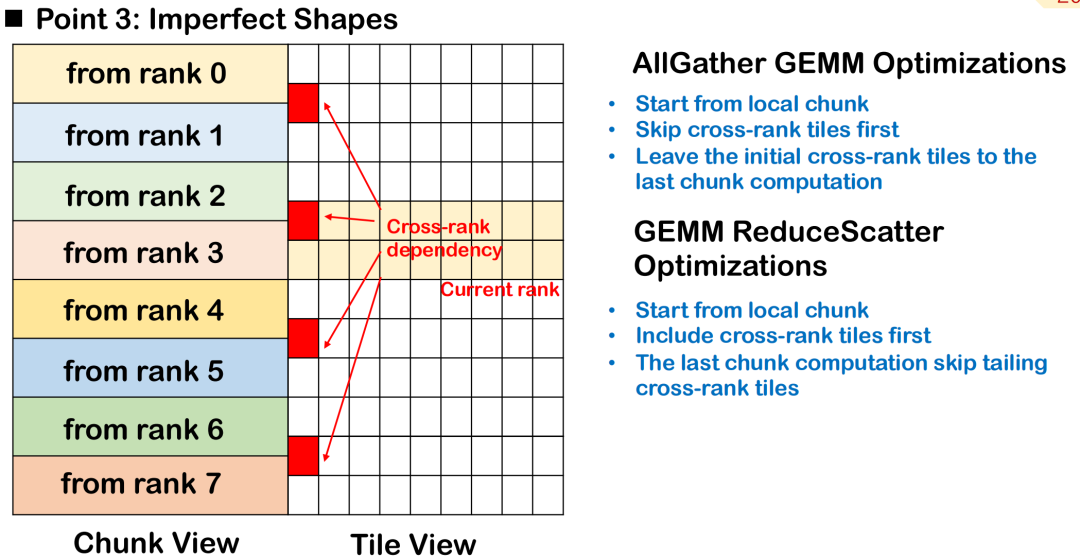
Ordonnancement de blocs imparfait : priorités de traitement sur les tuiles de rang
Dans les scénarios réels de formation et d'inférence de grands modèles, la forme d'entrée de l'opérateur est souvent irrégulière, en particulier lorsque la longueur du jeton n'est pas fixe, et il est difficile de garder les blocs de tuiles nets et uniformes.Ce pavage imparfait entraînera la répartition de certaines tuiles sur plusieurs rangs, c'est-à-dire que les données d'une même tuile seront distribuées sur plusieurs appareils, augmentant ainsi la complexité de la planification et de la synchronisation.
Prenons l'exemple d'AllGather GEMM : supposons qu'une tuile contienne des données locales et distantes. Si le calcul démarre à partir de cette tuile, il doit attendre que les données distantes soient transmises en premier, ce qui introduira des bulles supplémentaires et affectera le parallélisme du calcul global. Une meilleure approche consiste à ignorer cette tuile à rangs croisés, à donner la priorité au traitement des données entièrement disponibles localement et à programmer la tuile en attente d'une entrée distante en dernier, afin d'optimiser le chevauchement entre la communication et le calcul.
Dans le scénario ReduceScatter, l'ordre de planification doit être inversé. Puisque les résultats de calcul des tuiles inter-rangs doivent être envoyés au nœud distant le plus rapidement possible, la meilleure stratégie consiste à prioriser les tuiles utilisées par les nœuds distants, afin de finaliser la transmission des données inter-machines au plus vite et de réduire la dépendance à distance.
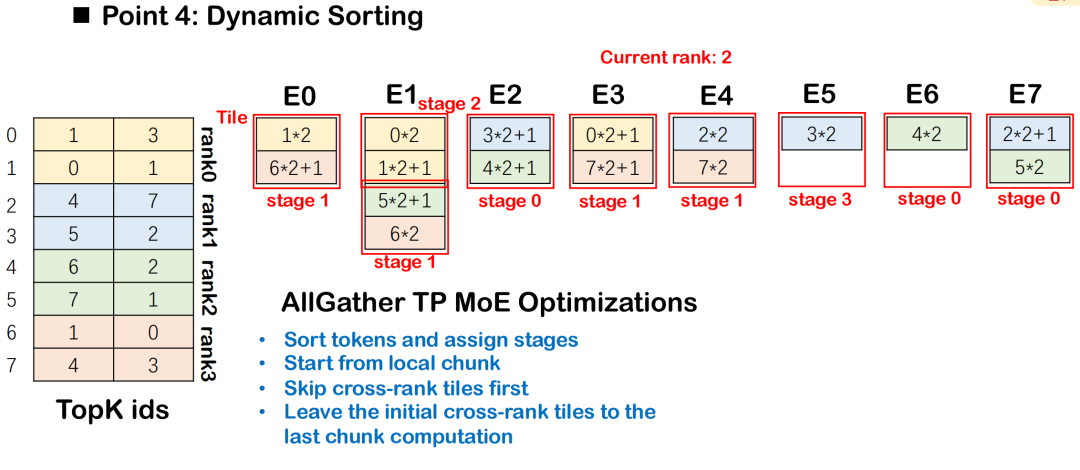
Stratégie de tri dynamique sous MoE
Dans le modèle MoE (Mixture-of-Experts), les jetons doivent être distribués à plusieurs experts en fonction des résultats de routage, généralement accompagnés d'une communication tous-à-tous et de calculs GEMM de groupe. Afin d'améliorer l'efficacité du chevauchement des communications et des calculs, Triton-distributed introduit le tri dynamique, qui planifie les tâches de calcul par étapes selon leur intensité de dépendance aux données de communication, en donnant la priorité à celles qui en dépendent le moins.
Cet ordre garantit que le calcul de chaque étape peut commencer avec le blocage de communication le plus faible possible, obtenant ainsi un meilleur chevauchement entre All-to-All et Group GEMM.La planification globale commence à partir de la tuile avec le moins de dépendances de données et s'étend progressivement aux tuiles avec des dépendances complexes, maximisant ainsi la concurrence d'exécution.
Accélération de la communication basée sur le matériel
Triton-distributed prend également en charge l'optimisation de la communication en combinaison avec des capacités matérielles spécifiques.En particulier, avec l'architecture NVSwitch, son accélérateur SHARP intégré permet d'effectuer des calculs de communication à faible latence. Ce module peut exécuter des opérations telles que Broadcast et AllReduce dans la puce de commutation afin d'accélérer l'agrégation des données sur le chemin de transmission, réduisant ainsi la latence et la consommation de bande passante. Les instructions correspondantes ont été intégrées à la distribution Triton, et les utilisateurs disposant du matériel correspondant peuvent les appeler directement pour construire un noyau de communication plus performant.
Optimisation de la compilation AOT : réduction de la latence d'inférence
Triton-distributed introduit le mécanisme AOT (Ahead-of-Time), spécifiquement optimisé pour les exigences extrêmement sensibles à la latence dans les scénarios d'inférence. Triton utilise la méthode de compilation JIT (Just-In-Time) par défaut, ce qui entraîne une surcharge de compilation et de cache importante lors de la première exécution de la fonction.
Le mécanisme AOT permet aux utilisateurs de précompiler des fonctions en bytecode avant leur exécution, puis de les charger et de les exécuter directement pendant la phase d'inférence, évitant ainsi le processus de compilation JIT et réduisant ainsi efficacement les délais de compilation et de mise en cache. Sur cette base, Triton-distributed a étendu le mécanisme AOT et prend désormais en charge la compilation et le déploiement AOT dans les environnements distribués, améliorant ainsi les performances de l'inférence distribuée.
Mesure de la performance et reproduction des cas
Nous avons effectué un test complet des performances de Triton-distributed dans des scénarios multi-plateformes et multi-tâches, couvrant NVIDIA H800, AMD GPU, GPU 8 cartes et clusters multi-machines, et comparé les solutions d'implémentation distribuées grand public telles que PyTorch et Flux.
Sur 8 cartes GPU,Triton-distributed permet une accélération significative par rapport à l'implémentation PyTorch dans les tâches AG GEMM et GEMM RS.Comparée à la solution Flux optimisée manuellement, elle offre également de meilleures performances grâce à de multiples optimisations telles que l'ordonnancement Swizzling, le déchargement des communications et la compilation AOT. Parallèlement, comparée à la combinaison PyTorch + RCCL sur la plateforme AMD, bien que l'accélération globale soit légèrement inférieure, elle permet également une optimisation significative. Les principales limitations proviennent de la faible puissance de calcul du matériel de test et de la topologie sans commutateur.
Dans la tâche AllReduce,Triton-distributed présente des accélérations significatives par rapport à NCCL dans les configurations matérielles que nous avons testées pour une variété de tailles de messages, de petites à grandes, avec une accélération moyenne d'environ 1,6 fois.Dans le scénario Attention, nous avons principalement testé l'opération d'attention de type gather-KV. Comparées à l'implémentation native de PyTorch Touch, les performances de Triton distribué sur 8 cartes GPU sont environ 5 fois supérieures ; elles sont également supérieures à celles de l'implémentation open source Ring Attention, avec une amélioration d'environ 2 fois.
Tests inter-machines :AG GEMM est 1,3 fois plus rapide et GEMM RS est 1,4 fois plus rapide, ce qui est légèrement inférieur à Flux, mais présente plus d'avantages en termes de flexibilité de forme et d'évolutivité.Nous avons également testé le décodage d'un seul jeton dans des scénarios d'inférence à haut débit. La latence a été contrôlée entre 20 et 30 microsecondes dans un contexte de 1 M de jetons, et le système est compatible avec NVLink et PCIe.
De plus, nous avons reproduit la logique de planification distribuée de DeepEP, en alignant principalement ses stratégies de routage « All-to-All » et de distribution de contexte. Dans les scénarios comportant moins de 64 cartes, les performances de la distribution Triton sont globalement identiques à celles de DeepEP, et légèrement supérieures dans certaines configurations.
Enfin, nous proposons également une démonstration de pré-remplissage et de décodage basée sur Qwen-32B, qui prend en charge le déploiement et l'exploitation sur 8 cartes GPU. Le test réel montre que l'accélération de l'inférence peut être multipliée par 1,2 environ.
Construire un écosystème de compilation distribué ouvert
Nous sommes actuellement confrontés au défi des scénarios de chevauchement personnalisés, pour lesquels nous avons principalement eu recours à l'optimisation manuelle pour les résoudre dans le passé, ce qui demande beaucoup de travail et est coûteux.Nous avons proposé et ouvert le framework distribué Triton.Bien qu'il soit implémenté sur la base de Triton, quel que soit le compilateur ou la bibliothèque de communication sous-jacente utilisée par chaque entreprise, il peut être intégré pour créer un écosystème distribué ouvert.
Ce domaine est encore relativement peu développé en Chine, et même dans le monde. Nous espérons exploiter la puissance de la communauté pour inciter davantage de développeurs à participer, que ce soit à la conception syntaxique, à l'optimisation des performances ou à la prise en charge de nouveaux types de périphériques, afin de promouvoir conjointement le progrès technologique. Nous avons enfin obtenu de bonnes performances, et tous les exemples associés sont open source. N'hésitez pas à soulever activement des problèmes de communication et à nous réjouir de voir de nouveaux partenaires nous rejoindre pour bâtir un avenir meilleur !








