Command Palette
Search for a command to run...
Des Caractéristiques Architecturales À La Construction De l'écosystème, Muxi Dong Zhaohua Analyse En Profondeur La Pratique d'application Du TVM Sur Les GPU Domestiques

Le 5 juillet, le 7e Salon des technologies de compilation Meet AI, organisé par HyperAI, s'est conclu avec succès. De l'innovation fondamentale de l'architecture GPU à la conception de pointe de l'écologie de compilation multi-matériel ; de l'optimisation des opérateurs monopuces aux avancées de la compilation distribuée multi-nœuds… Des praticiens et des chercheurs du domaine de la compilation IA se sont réunis pour ce festival technologique de pointe. Le site de l'événement était bondé et l'ambiance conviviale était intense.
Suivez le compte public WeChat « HyperAI Super Neuro » et répondez au mot-clé « 0705 AI Compiler » pour obtenir le discours PPT du conférencier autorisé.
Lors de l'événement, l'architecte Zhang Ning d'AMD nous a donné une analyse approfondie des secrets d'optimisation des performances du compilateur Triton sur la plate-forme GPU AMD, révélant comment faire en sorte que le code Python contrôle facilement le noyau GPU hautes performances ; le directeur Dong Zhaohua de Muxi Integrated Circuit a apporté une expérience pratique dans les applications TVM sur les GPU nationaux, montrant les étincelles de collision entre les puces indépendantes et les cadres de compilation open source ; le chercheur Zheng Size de ByteDance a dévoilé le mystère de la distribution Triton et a partagé comment Python subvertit le plafond de performance des communications distribuées ; TileLang apporté par le Dr Wang Lei de l'Université de Pékin redéfinit la limite d'efficacité du développement des opérateurs.




Dans le discours d'ouverture « TVM Application Practice on Muxi GPU »,Dong Zhaohua, directeur principal de Muxi Integrated Circuit, a présenté les caractéristiques techniques de ses produits GPU, les solutions d'adaptation du compilateur TVM, les cas d'application pratiques et la vision de la construction écologique.Il a démontré les avancées technologiques et le potentiel d’application des GPU nationaux dans les domaines du calcul haute performance et de l’IA.
HyperAI a compilé et résumé le discours du professeur Dong Zhaohua sans en compromettre l'intention initiale. Voici la transcription de son discours.
Présentation du GPU Muxi
Muxi GPU comprend actuellement plusieurs gammes de produits, telles que les séries N, C et G, couvrant un large éventail de scénarios, de l'apprentissage et du raisonnement en IA au calcul scientifique. Grâce à une pile logicielle multi-niveaux, il s'intègre parfaitement aux frameworks courants. Module central de la pile logicielle, le compilateur est chargé de fournir une interface de programmation conviviale, d'optimiser les applications de haut niveau, de générer les codes machine correspondants aux différentes architectures machine et de les transmettre au GPU pour exécution. Après des ajustements précis par les ingénieurs, ses performances ont atteint un niveau international avancé et il a établi une relation d'adaptation correspondante avec les bibliothèques informatiques courantes du secteur.
Le GPU Muxi dispose d'une interface de fonctions riche au niveau des instructions.Notre interface MACA C, développée en interne, repose sur une extension du langage C, intègre des éléments grammaticaux spécifiques et offre une équivalence fonctionnelle avec les interfaces de programmation sous-jacentes des principaux fabricants, permettant aux développeurs d'effectuer rapidement la migration et l'adaptation. Parallèlement, elle offre des interfaces de programmation diversifiées telles que Python, Triton et Fortran, prend en charge les normes de programmation parallèle comme OpenACC et OpenCL et offre une excellente efficacité en matière de génération automatique de code parallélisé.
aussi,Le GPU Muxi adopte l'architecture GPGPU (unité de traitement graphique à usage général).Le système de compilation basé sur LLVM prend en charge l'optimisation complète des processus, des langages de haut niveau aux codes machine de bas niveau, prend en compte à la fois l'efficacité du développement et les performances matérielles, et fournit une pile logicielle hautes performances.
Adaptation TVM sur GPU Muxi
En tant que compilateur d'apprentissage profond open source, TVM peut convertir des modèles d'apprentissage profond en code exécutable efficacement sur différents matériels. L'équipe Muxi a développé une solution d'adaptation TVM complète, basée sur les caractéristiques de son propre GPU, pour optimiser l'ensemble du processus, de la définition du modèle à l'exécution matérielle.
Du point de vue de l’architecture du compilateur, un support complet a été obtenu.Et en théorie, il peut se connecter à quatre niveaux principaux.
Pour adapter l'interface C++, nous souhaitons la convertir en langage MACA. Ce processus est complexe et la mise en œuvre d'une conversion automatique basée sur des outils présente certains défis.
Si l'abstraction du code est élevée, l'adaptation inter-niveaux est plus facile. De plus, lors de la connexion à LLVM, il est important de prêter attention aux problèmes de compatibilité des versions : en raison du grand nombre de versions de LLVM, l'adaptation d'une version spécifique dépend de la prise en charge de la version correspondante, et les incompatibilités de versions peuvent entraîner des anomalies dans les processus de compilation.
En termes d'adaptation GPU de Muxi Arch :
tvm.Target ajoute MACA Target et ajoute la prise en charge de chaque étape : tout d'abord, ajoutez le pipeline de MACA Target dans transform/lower pour réutiliser le processus GPU général ; puis ajoutez les règles de planification de MACA Target dans l'étape de réglage ; enfin, ajoutez la prise en charge de CodeGenMACA et compilez le code MACAC.
De plus, l'utilisation de MACA Device et de MACA Runtime API est ajoutée à tvm.Device, y compris les opérations de mémoire sur MACA Device et le lancement du noyau lors de l'exécution.
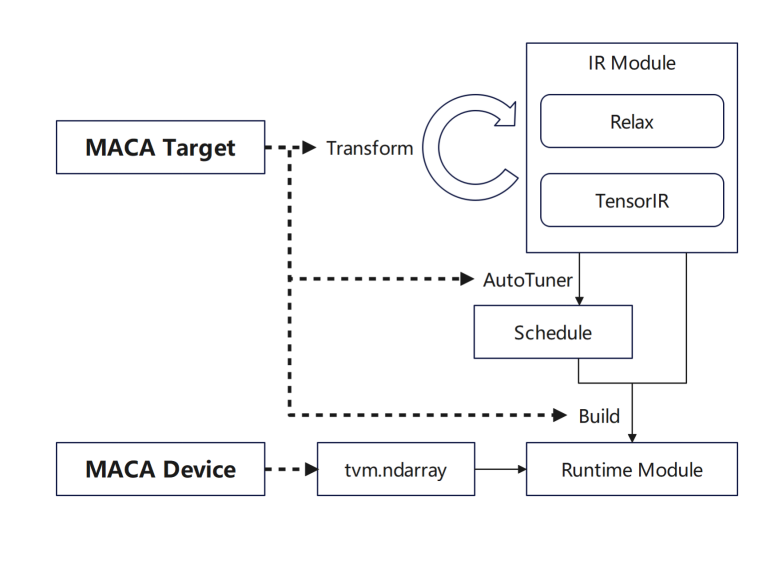
Désormais, la plupart de nos produits prennent en charge les sous-appareils au niveau TVM, et le backend effectue des actions d'optimisation pour différents produits en fonction des sous-appareils.Dans différents produits, le compilateur sélectionnera automatiquement la solution d’adaptation correspondante en fonction de la différence de type d’appareil ;Dans le même temps, dans les scénarios de compilation par lots, nous essayons de créer des configurations de sélection fixes pour différentes architectures.Au cours de la phase de compilation générale, le compilateur ajustera dynamiquement les règles de compilation liées aux fonctions pour différentes architectures en fonction de la configuration spécifique.
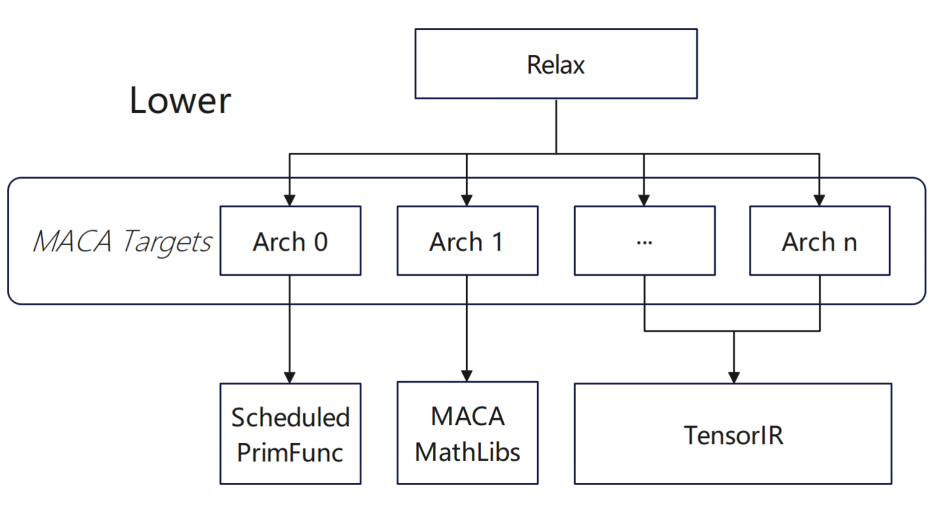
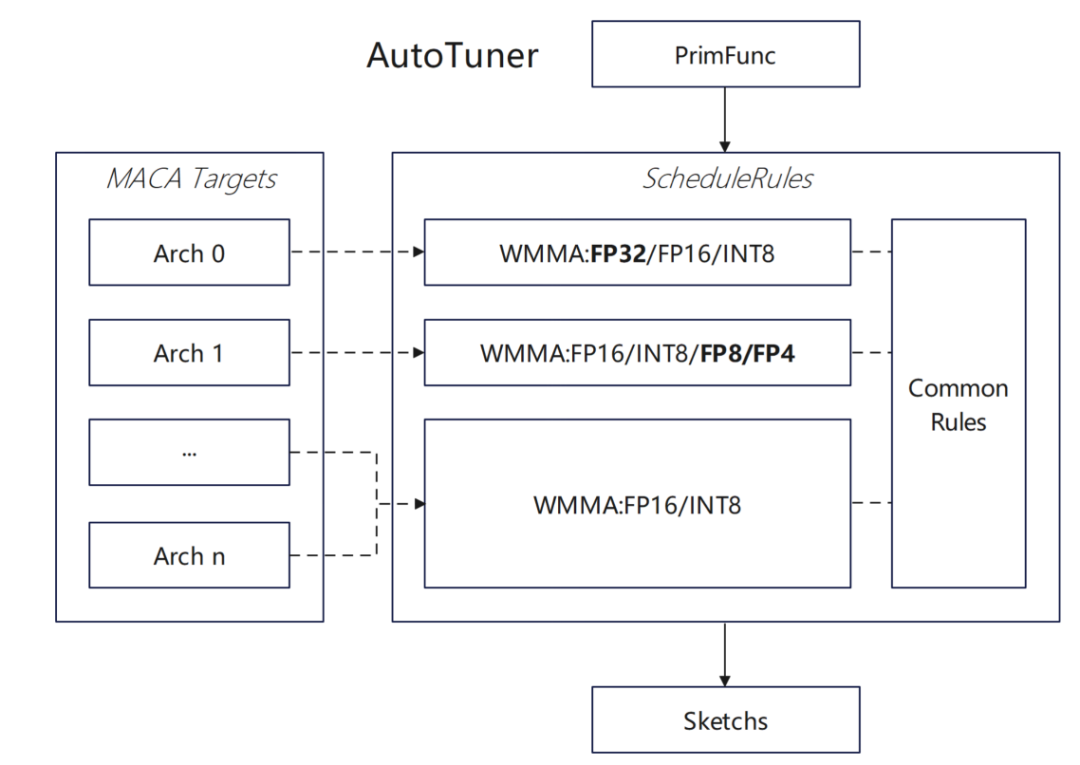
En termes d'adaptation de l'opérateur, nous avons réalisé une configuration de niveau supérieur, comprenant principalement :
* Dans le programme inférieur, ajoutez un programme à PrimFunc via la primitive de planification TIR
* Dans le module Split Mixed, ajoutez la cible et d'autres informations, injectez le maca intégré et ajoutez des instructions de synchronisation pour MACA
* Lorsque CodeGenMACA, incluez les fichiers d'en-tête dont dépend MACA, générez l'utilisation de l'API wmma maca à partir des instructions liées à tir.mma et déclarez et utilisez des variables de différents types.
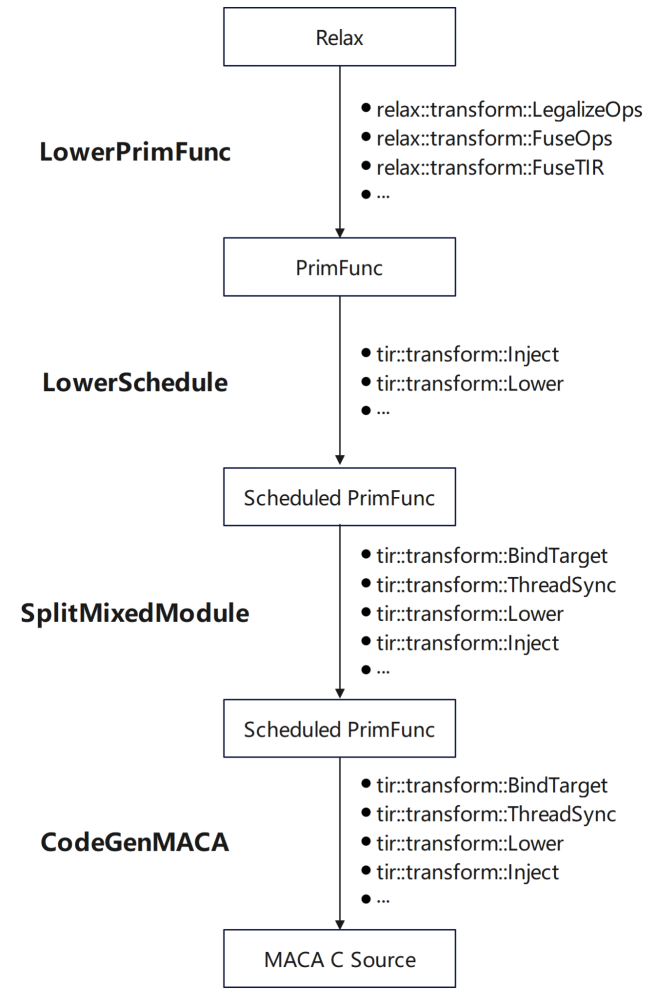
Au cours du processus d'adaptation, afin d'obtenir de meilleures performances, nous avons effectué un traitement spécial en fonction de ses caractéristiques :
* Impossible d'activer la tensorisation pendant le réglage : le groupe de paramètres de l'opérateur conv2d n'est pas 1 et l'implémentation de la bibliothèque d'opérateurs MACA est directement utilisée dans TOPI ;
* Opérateurs personnalisés après l'importation du modèle onnx : L'opérateur Multi Head AttentionV1 est hautement optimisé dans l'environnement d'exécution MACA onnx. L'appel à l'opérateur est encapsulé dans contrib, ce qui permet à TVM d'utiliser directement l'implémentation de l'opérateur hautes performances optimisée manuellement après l'importation du modèle onnx.
Pour nous,Les opérateurs d'optimisation personnalisés des fournisseurs sont plus susceptibles d'être implémentés dans Python et MAC A :
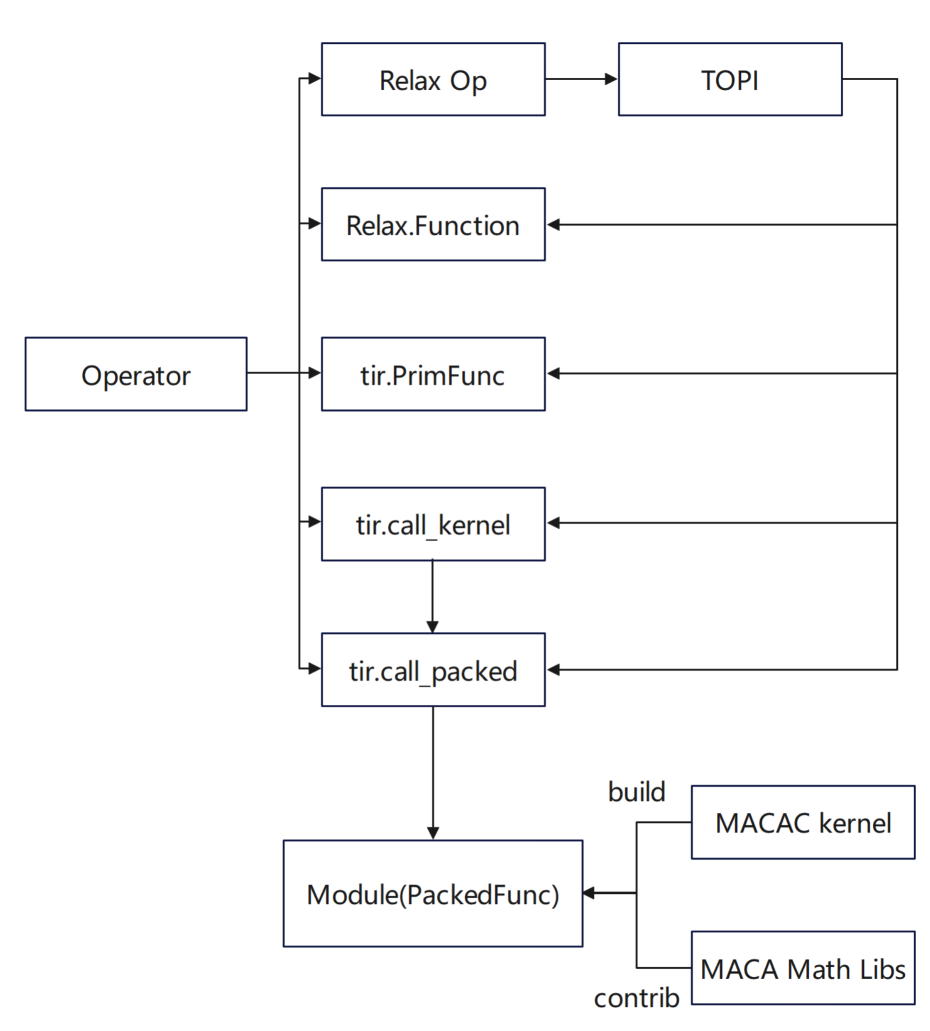
* Dans l'interface Python, Relax.Function est défini en combinant des opérateurs de base ; tir.PrimFunc utilise tir pour définir l'implémentation de l'opérateur et ajouter des planifications selon les besoins
* Dans l'interface MACA C, tir.call_packed encapsule l'implémentation de la bibliothèque d'opérateurs hautes performances et l'utilise ; tir.call_kernel utilise le code du noyau implémenté dans MACA C et le compile dans un appel PackedFunc via la pile TVM.
De plus, afin de tirer pleinement parti des caractéristiques matérielles du GPU Muxi,L'équipe a optimisé en profondeur l'algorithme de planification TVM :
* Ajout de la prise en charge du type WMMA float32 pour la cible MACA :
Tout d'abord, prenez en charge l'API wmma de type float32 dans MACA, ajoutez une règle de tensorisation automatique de type float32 dans MACA ScheduleRules, afin que TVM puisse identifier et utiliser automatiquement le matériel WMMA, et ajoutez l'optimisation de tensorisation float32 correspondante dans le framework d'optimisation dlight pour améliorer l'efficacité du fonctionnement de la matrice.
* Évaluer l’impact de la copie asynchrone sur l’algorithme de planification :
Optimisez plusieurs calculs wmma depuis le chargement d'un groupe et le calcul d'un groupe jusqu'au chargement asynchrone du groupe de données suivant et au calcul synchrone du groupe de données actuel, améliorez l'efficacité du pipeline et activez la logique d'optimisation du pipeline logiciel dans MACA ScheduleRules, et ajoutez l'injection d'instructions de copie asynchrone et la génération de code pour la cible MACA
Nous avons également fait quelques tentatives pour prendre en charge de nouveaux types de données :Activez l'adaptation de la cible MACA dans le système DataType ; prenez en charge la logique de tensorisation automatique du type Float8 dans MACA ScheduleRules et étendez la prise en charge de TVM pour les types de données personnalisés tels que Float8 ; implémentez la prise en charge de la conversion de type Float8 et de la génération de code d'opération dans CodeGenMACA et complétez les définitions d'opération associées dans maca_half_t.h.
Application TVM sur GPU Muxi
En termes de conception du framework, l'équipe a mis en œuvre deux méthodes d'accès :L'une consiste à importer directement le modèle de torche et à l'exécuter dans le frontend Relay, et l'autre consiste à utiliser torch.compile pour utiliser TVM comme backend.Il permet une connexion efficace entre le framework de niveau supérieur et le matériel sous-jacent.
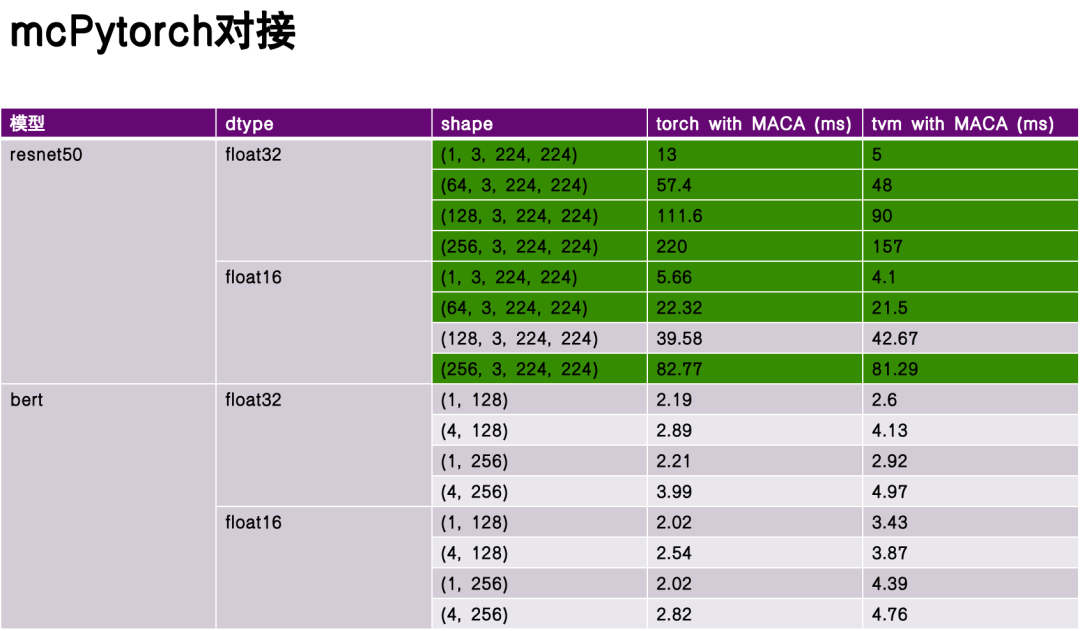
Dans la phase d'évaluation des performances, j'ai sélectionné ReseNet50 et Bert comme modèles de référence et comparé les performances de la compilation et de l'exécution de Torch et TVM sans optimisation approfondie.Les données expérimentales montrent que le TVM présente des avantages significatifs dans certains aspects et que ses performances surpassent celles de la torche dans certains scénarios.Cela est dû à la flexibilité de la représentation intermédiaire TVM (IR) et à son optimisation ciblée pour les caractéristiques matérielles.
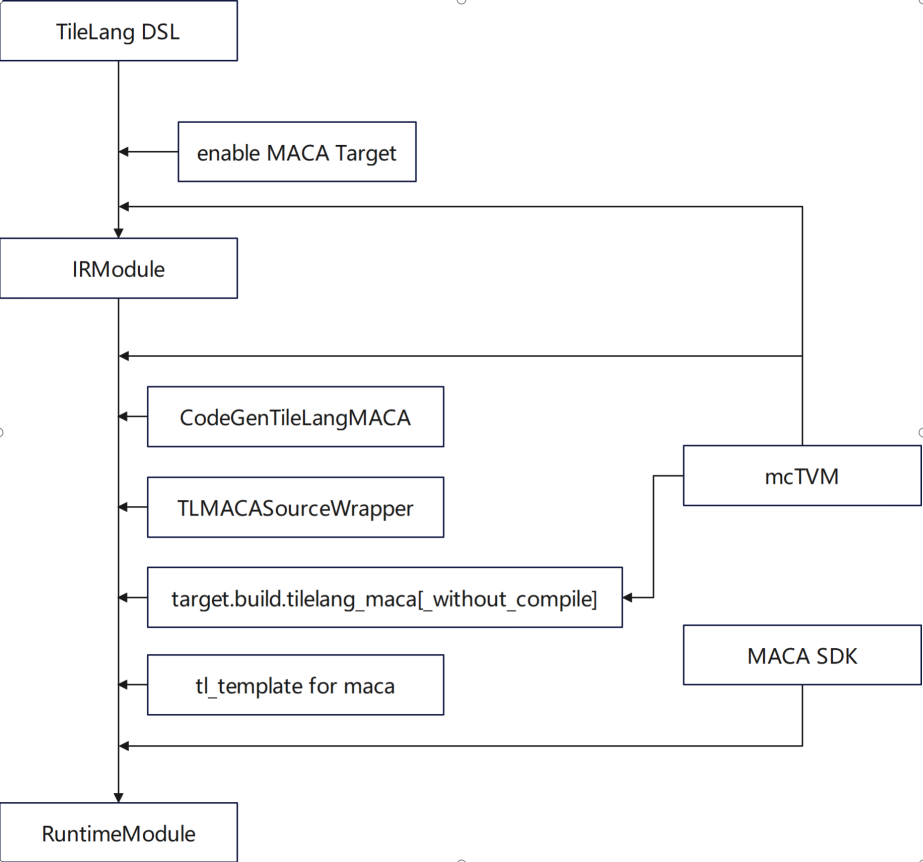
TileLang est un langage spécifique à un domaine (DSL) dans l'écosystème TVM, axé sur l'optimisation raffinée du calcul tensoriel.Notre équipe a réalisé une adaptation fonctionnelle approfondie dans les aspects suivants :* Prise en charge de l'utilisation de la cible MACA * Ajout de CodeGenTileLangMACA pour générer le code du noyau C MACA * Remplacer et utiliser mcTVM comme dépendance * Ajouter la logique de traitement de la cible MACA dans libgen, l'adaptateur et le wrapper * Ajouter la définition de la cible MACA à l'aide de gemm dans tl_template
En termes d'optimisation, le travail s'articule principalement autour de l'implémentation de gemm dans tl_template et de l'implémentation d'algorithmes s'adaptant aux caractéristiques du GPU Muxi.
En termes d'interaction entre les fournisseurs et la communauté, la conception et le développement de TileLang doivent équilibrer trois principes :
En termes de conception linguistique,La première chose à résoudre est l’équilibre entre l’abstraction et la haute performance.Plus précisément, face à plusieurs unités de calcul, le compilateur doit offrir un mécanisme de sélection de stratégie flexible, permettant aux développeurs possédant une connaissance approfondie des caractéristiques matérielles sous-jacentes de spécifier des chemins de génération de code spécifiques, tout en aidant les développeurs ordinaires à réaliser une programmation efficace grâce à des interfaces abstraites sans avoir à se soucier des détails sous-jacents. Cet équilibre est l'élément clé sur lequel TileLang, en tant que DSL, doit se concentrer lors de la phase de conception.
Deuxièmement,La configuration personnalisée du fournisseur et la standardisation du DSL doivent être prises en compte.Le compilateur doit prendre en charge la configuration d'options d'optimisation multi-niveaux, permettant par exemple aux utilisateurs avancés d'ajuster les stratégies de compilation sous-jacentes, telles que le niveau de déroulement de boucle et la pression héritée, via des paramètres, afin d'obtenir de meilleurs résultats de génération de code. Parallèlement, pour différentes architectures matérielles, le compilateur doit fournir des conseils d'optimisation ciblés et des mécanismes d'annotation pour aider les développeurs à sélectionner le chemin de compilation optimal en fonction des caractéristiques matérielles et améliorer l'efficacité du développement.
troisième,La continuité de l’interface entre les générations de produits doit être assurée.Lors du processus d'itération des compilateurs et des chaînes d'outils de langage, la rétrocompatibilité de la conception des interfaces doit être assurée : la logique de compilation et le code généré de la version actuelle peuvent continuer à fonctionner efficacement sur la prochaine génération de produits matériels, évitant ainsi les coûts de reconstruction de code liés aux itérations d'architecture. Cette continuité est le fondement de la construction écologique, qui permet une accumulation « additive » des fonctions de la chaîne d'outils de compilation plutôt qu'une perte « soustractive » due à des incompatibilités. Parallèlement, elle permet de réduire les coûts d'apprentissage et de migration pour l'utilisateur et d'éviter les confusions d'utilisation.
Défis et opportunités
Enfin, je voudrais évoquer les défis et les opportunités auxquels est confronté le développement actuel de l’industrie.Les défis se reflètent principalement dans les aspects suivants :
La première est que les cadres et les algorithmes basés sur les applications évoluent rapidement.Avec le développement rapide de domaines tels que l'apprentissage en profondeur, le cycle de mise à jour des frameworks et algorithmes de niveau supérieur continue de se raccourcir, et l'augmentation des fonctionnalités et des performances a exercé une pression sur l'adaptation des compilateurs - la communauté des compilateurs doit établir un mécanisme d'adaptation efficace pour répondre rapidement aux besoins de support des nouveaux opérateurs et des nouveaux modèles informatiques.
Deuxièmement, l’architecture matérielle continue d’évoluer.Actuellement, le compilateur prend en charge les fonctionnalités de certaines architectures GPU. Si de nouvelles architectures matérielles apparaissent à l'avenir, le compilateur devra également être capable de prendre en charge des fonctionnalités matérielles hétérogènes.
La troisième est que les paradigmes de programmation continuent d’évoluer.Du C/C++ traditionnel aux modèles émergents de programmation fonctionnelle et de programmation hétérogène, définir la chaîne écologique liée à Python est un grand défi.
Finalement, c'est un équilibre entre précision, performance et consommation d'énergie.Dans les applications pratiques, les compilateurs doivent non seulement prêter attention aux performances du code, mais aussi à la consommation d'énergie du matériel, qui est tout aussi importante. Ces facteurs sont liés à la sélection des instructions et à la conception de l'architecture.
avenir,Nous aimerions faire une co-construction avec la communauté :
En termes de stratégie open source, nous prévoyons d'ouvrir les composants clés du framework et de la bibliothèque d'opérateurs, notamment des modules informatiques clés tels que FlashMLA. Grâce à ce modèle open source, nous favoriserons l'optimisation itérative de la chaîne d'outils du compilateur et créerons un effet d'échelle écologique.
Deuxièmement, nous espérons que les applications, les frameworks, les bibliothèques d'opérateurs, les compilateurs et les architectures matérielles du secteur bénéficieront de possibilités de coopération plus étroites. Grâce à des échanges techniques réguliers (tels que des forums sectoriels), nous nous concentrerons sur des questions fondamentales telles que les difficultés d'optimisation de la compilation et les stratégies d'ordonnancement des opérateurs, favoriserons la coopération inter-domaines et explorerons les innovations technologiques.
Muxi se concentre également sur la co-construction de l'écosystème. Ses initiatives de construction comprennent : la création d'un forum communautaire technique pour recueillir les commentaires des développeurs et les rapports de problèmes sur les chaînes d'outils de compilation ; l'organisation de concours thématiques pour les opérateurs et les frameworks ; la fourniture de benchmarks et la co-construction de suites de tests et de benchmarks spécifiques à chaque domaine avec la communauté.








