Command Palette
Search for a command to run...
Un Bond En Avant Dans La Capacité De Raisonnement ! GLM-4.1V-Thinking Favorise l'évolution De l'intelligence Cognitive ; 5 Millions d'exemples De Données De Raisonnement Étape Par Étape ! MathX-5M Ouvre Un Nouveau Champ Du Raisonnement mathématique.

Actuellement, les grands modèles multimodaux évoluent de l'« intelligence perceptive » vers l'« intelligence cognitive ». Des études antérieures ont tenté d'améliorer la capacité de raisonnement des modèles de langage visuel, mais elles se limitent généralement à des domaines spécifiques. Bien que des recherches pertinentes soient en cours, il manque encore un modèle universel de raisonnement multimodal.
Dans ce contexte, Zhipu AI et l'Université Tsinghua ont proposé conjointement GLM-4.1V-Thinking, un modèle de langage visuel (VLM) conçu pour promouvoir la compréhension et le raisonnement multimodaux généraux.Son innovation principale réside dans la stratégie « Apprentissage par renforcement avec échantillonnage de programmes (RLCS) ».Non seulement il atteint les performances les plus élevées du modèle de langage visuel au niveau des paramètres 10B,Dans 18 des tâches de la liste, le Qwen-2.5-VL-72B a les mêmes paramètres ou même plus de 8 fois.Il réalise également un bond en avant dans les capacités cognitives dynamiques des modèles multimodaux, passant de la « reconnaissance d'image » passive à la « réflexion » active, résolvant les points faibles du raisonnement tout en conservant les avantages d'un déploiement léger.
Actuellement, le site officiel d'HyperAI a lancé le tutoriel « GLM-4.1V-Thinking : Versatile Multimodal Reasoning through Scalable Reinforcement Learning », venez l'essayer~
GLM-4.1V-Pensée : Raisonnement multimodal polyvalent via l'apprentissage par renforcement évolutif
Utilisation en ligne :https://go.hyper.ai/B3Vzs
Du 7 au 11 juillet, le site officiel de hyper.ai est mis à jour :
* Ensembles de données publiques de haute qualité : 10
* Sélection de tutoriels de qualité : 7
* Articles recommandés cette semaine : 5
* Interprétation des articles communautaires : 5 articles
* Entrées d'encyclopédie populaire : 5
* Principales conférences avec date limite en juillet : 4
Visitez le site officiel :hyper.ai
Ensembles de données publiques sélectionnés
1. Ensemble de données de détection de drones VisDrone
VisDrone est un ensemble de données de référence pour la détection et le suivi visuels de cibles par drone à grande échelle, conçu pour faciliter le développement et l'évaluation de tâches de vision par ordinateur telles que la détection de cibles, le suivi d'objets et la segmentation d'images. Cet ensemble de données contient des images et des vidéos haute résolution collectées par drone en milieu urbain et périurbain dans diverses villes de Chine, couvrant six catégories (personnes, véhicules, bâtiments, animaux, etc.).
Utilisation directe :https://go.hyper.ai/hQ5lh

2. Ensemble de données de raisonnement mathématique MathX-5M
MathX est un ensemble de données de raisonnement mathématique conçu pour l'optimisation et le perfectionnement de modèles basés sur des instructions afin d'améliorer les capacités de réflexion. Cet ensemble de données constitue le corpus public de données de raisonnement mathématique le plus vaste et le plus complet à ce jour. Il comprend 5 millions d'exemples de raisonnement étape par étape soigneusement sélectionnés, chacun contenant : l'énoncé du problème, le raisonnement détaillé et la solution correcte vérifiée.
Utilisation directe :https://go.hyper.ai/h0eLq
3. Classification des fruits Ensemble de données d'images de classification des fruits
Fruit Classification est un jeu de données d'images de classification de fruits conçu pour entraîner des modèles de machine learning et de deep learning pour la reconnaissance et la classification des fruits. Ce jeu de données couvre 101 espèces de fruits, et chaque catégorie contient environ 400 images pour l'entraînement, 50 images pour la validation et 50 images pour les tests.
Utilisation directe :https://go.hyper.ai/a8gfG

4. Ensemble de données d'images de races de chiens
Dog Breeds Image est un ensemble de données contenant des images de différentes races canines, conçu pour faciliter l'entraînement et l'évaluation des modèles de classification canine. Cet ensemble de données contient des milliers (plus de 17 000) d'images de différentes races canines, dont plus de 100 (terriers, chiens courants, mastiffs, épagneuls, bichons frisés, etc.), conçues pour faciliter le développement de systèmes de reconnaissance des races canines.
Utilisation directe :https://go.hyper.ai/DoFA3

5. Espèces de champignons Ensemble de données d'identification des espèces de champignons
Mushroom est un ensemble de données de reconnaissance d'espèces de champignons. Il contient des images de plus de 100 espèces. Les données contiennent les caractéristiques physiques de chaque champignon, telles que la couleur, la forme, l'odeur, la texture de surface, etc., et indiquent si chaque champignon est toxique ou comestible. Ces images illustrent la morphologie des champignons à différents stades et conditions de croissance, ce qui les rend idéales pour les tâches de classification fine.
Utilisation directe :https://go.hyper.ai/ws0pi

6. Ensemble de données d'entraînement texte-image 2M Text-to-Image
Text-to-Image-2M est un jeu de données de paires texte-image de haute qualité, conçu pour affiner les modèles texte-image. Ce jeu de données contient environ 2 millions d'échantillons et est divisé en deux sous-ensembles principaux : data_512_2M (2 millions d'images et d'annotations de résolution 512×512) et data_1024_10K (10 000 images et annotations haute résolution 1024×1024), offrant des options flexibles pour l'entraînement de modèles répondant à différentes exigences de précision.
Utilisation directe :https://go.hyper.ai/lTBaT
7. Ensemble de données de reconnaissance d'images synthétiques CIFAKE
CIFAKE est un ensemble de données synthétiques permettant d'identifier les images générées par l'IA. Il s'agit d'un ensemble de données d'images de classification binaire présentant une valeur pratique importante pour renforcer la robustesse des technologies de traitement d'images et améliorer la capacité de reconnaissance des contenus générés par l'IA, notamment dans les domaines de la diffusion de l'information et de la surveillance des réseaux sociaux. Cet ensemble de données contient 60 000 images réelles et 60 000 images générées par l'IA. Il est conçu pour évaluer la capacité des modèles de vision par ordinateur à identifier les images générées par l'IA.
Utilisation directe :https://go.hyper.ai/wxeA3

8. II-Ensemble de données publiques sur le raisonnement médical SFT
II-Medical SFT est un ensemble de données de raisonnement médical public conçu pour soutenir le réglage fin supervisé de grands modèles de langage (LLM) pour les tâches de raisonnement médical. Cet ensemble de données contient environ 2,2 millions d'échantillons, couvrant des scénarios médicaux multi-sources, répondant aux besoins de réglage fin de modèles médicaux complexes et visant à aider les modèles à développer des fonctionnalités clés telles que le diagnostic différentiel, la prise de décision fondée sur des données probantes, la communication avec les patients et les plans de traitement basés sur des recommandations.
Utilisation directe :https://go.hyper.ai/TGMjl
Traffic Sign Detection est un ensemble de données de détection de panneaux de signalisation adapté à la recherche sur la reconnaissance des panneaux de signalisation pour la conduite autonome, les systèmes d'aide à la conduite et les villes intelligentes. Cet ensemble de données contient environ 9 000 images de panneaux de signalisation clairement étiquetées et environ 4 969 images de Street View, couvrant différentes scènes dans plusieurs pays. Les images sont classées en plusieurs catégories et divisées en ensembles d'apprentissage, de validation et de test, fournissant des annotations précises des cadres de délimitation.
Utilisation directe :https://go.hyper.ai/VfwUw

10. Ensemble de données de référence sur les métamatériaux mécaniques UniMate
Le jeu de données UniMate est un jeu de référence pour les métamatériaux mécaniques, contenant 15 000 échantillons. Chaque échantillon contient une structure topologique tridimensionnelle, des informations de densité et les propriétés mécaniques homogénéisées correspondantes, couvrant des scénarios de faible densité (ρ = 0,1) à moyenne densité (ρ = 0,5). La structure topologique respecte la symétrie cubique et la périodicité.
Utilisation directe :https://go.hyper.ai/1ki2l
Tutoriels publics sélectionnés
Cette semaine, nous avons résumé 3 types de tutoriels publics de haute qualité
*Tutoriel de déploiement de grands modèles : 1
*Tutoriels d'IA pour la science : 2
*Tutoriels multimodaux : 4
Tutoriel sur le déploiement de grands modèles
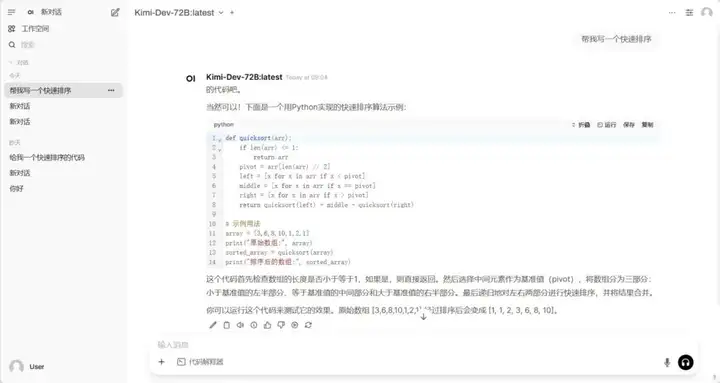
1. Ollama+Open WebUI déploie Kimi-Dev-72B-GGUF
Kimi-Dev-72B est un modèle de langage open source conçu pour les tâches d'ingénierie logicielle. Il comprend principalement des fonctions telles que la réparation de code, la génération de code de test (TestWriter), l'automatisation du processus de développement et l'intégration d'outils de développement.
Exécutez en ligne :https://go.hyper.ai/t6ps1
Tutoriel sur l'IA pour la science
Le modèle d'État permet de prédire la réponse des cellules souches, des cellules cancéreuses et des cellules immunitaires aux médicaments, aux cytokines ou aux interventions génétiques. Les résultats expérimentaux montrent que ce modèle est nettement plus performant que les méthodes classiques actuelles pour prédire les modifications du transcriptome après intervention.
Exécutez en ligne :https://go.hyper.ai/4AM6P
2. HealthGPT : assistant médical IA
HealthGPT est un modèle de langage visuel médical à grande échelle (Med-LVLM) qui implémente un cadre unifié pour les tâches de compréhension et de génération visuelles médicales grâce à une technologie d'adaptation hétérogène des connaissances. Il utilise une technologie innovante d'adaptation hétérogène de bas rang (H-LoRA) pour stocker les connaissances des tâches de compréhension et de génération visuelles dans des plug-ins indépendants afin d'éviter les conflits entre les tâches.
Exécutez en ligne :https://go.hyper.ai/KiBWB
Tutoriel multimodal
GLM-4.1V-Thinking est un modèle de langage visuel (MLV) conçu pour améliorer la compréhension et le raisonnement multimodaux généraux. En combinant l'apprentissage par renforcement et l'échantillonnage de programmes (RLCS), il permet d'améliorer considérablement les compétences dans diverses tâches, notamment la résolution de problèmes STEM, la compréhension vidéo, la reconnaissance de contenu, la programmation, la résolution de coréférences, les agents basés sur des interfaces utilisateur graphiques et la compréhension de documents longs.
Exécutez en ligne :https://go.hyper.ai/qPF8a
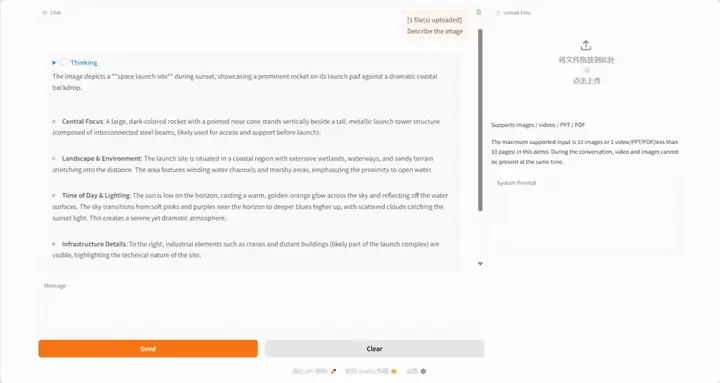
2. EX-4D : Générer une vue libre à partir d'une vidéo monoculaire
EX-4D est un nouveau framework de génération vidéo 4D capable de générer des vidéos 4D de haute qualité à des points de vue extrêmes à partir d'une entrée vidéo monoculaire. Ce framework repose sur une représentation unique de maillage étanche profond (DW-Mesh) qui modélise explicitement les zones visibles et occultées afin de garantir la cohérence géométrique dans des poses de caméra extrêmes. Il utilise une stratégie de masque d'occlusion simulé pour générer des données d'apprentissage efficaces basées sur la vidéo monoculaire, ainsi qu'un adaptateur de diffusion vidéo léger basé sur LoRA pour synthétiser des vidéos physiquement cohérentes et temporellement cohérentes. EX-4D surpasse largement les méthodes existantes à des points de vue extrêmes et offre une nouvelle solution pour la génération vidéo 4D.
Exécutez en ligne :https://go.hyper.ai/WyAPN

3. MonSter : libérer le potentiel de la profondeur monoculaire et de la vision stéréo
MonSter intègre la profondeur monoculaire et la correspondance stéréo dans une architecture à deux branches pour une amélioration mutuelle itérative. Cette amélioration mutuelle itérative permet à MonSter d'évoluer de structures grossières au niveau de l'objet vers une géométrie au niveau du pixel, exploitant pleinement le potentiel de la correspondance stéréo.
Exécutez en ligne :https://go.hyper.ai/a9Ekd
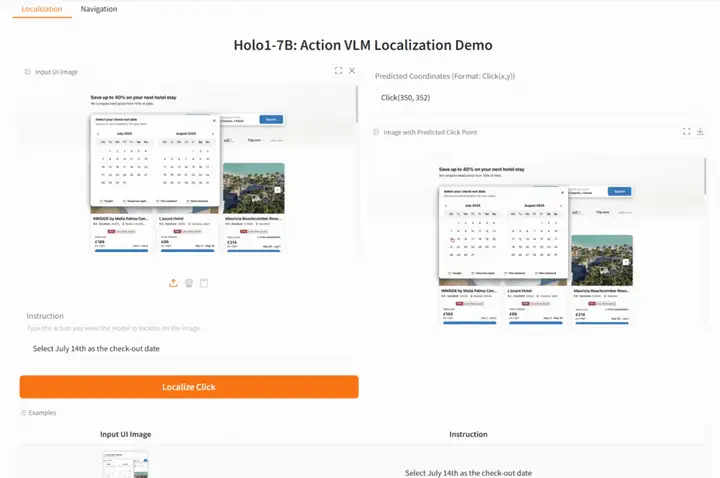
4. Holo1-7B : positionnement précis des éléments de l'interface utilisateur en langage naturel
Holo1-7B est un modèle de langage visuel d'action (MLV) pour le système d'agent web Surfer-H. Il est conçu pour interagir avec les interfaces web comme un utilisateur humain. Intégré à une architecture d'agent plus large, Holo1 peut servir de modèle de politique, de modèle de localisation ou de modèle de vérification, aidant les agents à comprendre et à manipuler les environnements numériques.
Exécutez en ligne :https://go.hyper.ai/6oQuF

Recommandation de papier de cette semaine
1. MemOS : un système d'exploitation de mémoire pour les systèmes d'IA
Cet article propose MemOS, un système d'exploitation mémoire qui traite la mémoire comme une ressource système gérable. Il unifie la représentation, l'ordonnancement et l'évolution de la mémoire en texte brut, par activation et au niveau des paramètres, permettant ainsi un stockage et une récupération rentables. En tant qu'unité de base, MemCube encapsule le contenu de la mémoire et ses métadonnées, telles que les informations de provenance et de version. Les MemCubes peuvent être combinés, migrés et fusionnés au fil du temps, permettant une conversion flexible entre différents types de mémoire et reliant la récupération à l'apprentissage basé sur les paramètres. MemOS établit un cadre système centré sur la mémoire qui apporte contrôlabilité, plasticité et évolutivité aux LLM, jetant ainsi les bases de leur apprentissage continu et de leur modélisation personnalisée.
Lien vers l'article :https://go.hyper.ai/PgtHH
2. SingLoRA : Adaptation de rang bas à l'aide d'une matrice unique
Cet article propose une nouvelle méthode, SingLoRA, qui redéfinit l'adaptation de bas rang en exprimant les mises à jour de pondération comme la décomposition d'une matrice unique de bas rang et de sa transposée. Cette conception simple élimine intrinsèquement le conflit d'échelle entre les matrices, assure la stabilité du processus d'optimisation et réduit le nombre de paramètres d'environ la moitié. Les chercheurs ont analysé SingLoRA dans le cadre de réseaux de neurones de largeur infinie et ont démontré que sa conception assure intrinsèquement la stabilité de l'apprentissage des caractéristiques, et ont vérifié ces avantages par des expériences approfondies.
Lien vers l'article :https://go.hyper.ai/kUu4u
3. Devrions-nous encore pré-entraîner les encodeurs avec la modélisation du langage masqué ?
Des recherches ont montré que les modèles de décodeur pré-entraînés avec des modèles de langage causal (CLM) peuvent être efficacement réutilisés pour les tâches d'encodage, mais la raison de cette amélioration des performances reste obscure. Cet article explore cette question à travers une série d'expériences d'ablation pré-entraînement à grande échelle et soigneusement contrôlées, démontrant expérimentalement qu'une stratégie d'entraînement en deux étapes – appliquant d'abord les CLM, puis les MLM – permet d'obtenir les meilleures performances avec un budget de ressources de calcul fixe. Cette stratégie est d'autant plus attractive lorsqu'elle est initialisée à partir de modèles CLM pré-entraînés issus du vaste écosystème de modèles de langage existant.
Lien vers l'article :https://go.hyper.ai/eN7kf
4. Une enquête sur le raisonnement latent
Afin de promouvoir la recherche sur le raisonnement latent, cet article offre un aperçu complet de ce domaine émergent. En explorant le rôle fondamental des couches de réseaux neuronaux comme matrice de calcul du raisonnement, en étudiant diverses méthodes de raisonnement latent et en discutant de paradigmes avancés (tels que le raisonnement latent à profondeur illimitée obtenu par des modèles de diffusion masquée), il vise à clarifier le cadre conceptuel du raisonnement latent et à indiquer les futures orientations de recherche aux frontières de la cognition LLM.
Lien vers l'article :https://go.hyper.ai/kIuD8
5. Agent KB : Exploiter l'expérience inter-domaines pour la résolution de problèmes d'agent
Cet article présente Agent KB, un framework d'expérience hiérarchique qui permet la résolution de problèmes complexes par les agents grâce à un nouveau pipeline « Raison-Récupération-Affinage ». Nos résultats montrent qu'Agent KB offre une infrastructure modulaire et indépendante du framework, permettant aux agents d'apprendre de leurs expériences passées et de généraliser leurs stratégies efficaces à de nouvelles tâches.
Lien vers l'article :https://go.hyper.ai/2wJPd
Autres articles sur les frontières de l'IA :https://go.hyper.ai/iSYSZ
Interprétation des articles communautaires
L'équipe de recherche de l'Université Jiao Tong de Shanghai, en collaboration avec l'Université des Sports de Shanghai et l'Université Tsinghua, a créé « Spirit Realm », le premier système d'intervention sportive intelligent en réalité virtuelle au monde, destiné au contrôle du poids des adolescents en surpoids ou obèses. Ce système utilise un agent jumeau coach virtuel, piloté par apprentissage par renforcement profond et basé sur l'architecture Transformer, pour fournir un accompagnement sportif sûr et immersif. Ses performances biomécaniques et sa réponse cardiaque à l'exercice ne diffèrent pas significativement de celles des sports du même type pratiqués en conditions réelles.
Voir le rapport complet :https://go.hyper.ai/Q3KKv
Récemment, des articles de recherche de 14 universités du monde entier ont révélé que des instructions cachées accompagnaient les évaluateurs d'IA pour donner des avis positifs. Ce rapport a suscité de vives discussions au sein de la communauté universitaire et a attiré l'attention sur les risques et les enjeux éthiques liés au recours à des évaluateurs d'IA. L'équipe de Xie Saining a également été accusée de dissimuler des commentaires positifs, et ce dernier a publié un long article en réponse, appelant à l'attention sur l'évolution de l'éthique de la recherche scientifique à l'ère de l'IA.
Voir le rapport complet :https://go.hyper.ai/LZ0TJ
L'Université nationale de Singapour et l'Université du Zhejiang ont proposé conjointement une méthode innovante, NeuralCohort, qui a ouvert une nouvelle voie pour l'apprentissage de la représentation des DSE et exploité pleinement le potentiel des données du DSE. Cette méthode exploite simultanément les informations intra-cohortes locales et inter-cohortes globales, éléments clés qui n'avaient pas été pleinement pris en compte dans les précédentes études d'analyse des dossiers médicaux électroniques.
Voir le rapport complet :https://go.hyper.ai/1b8lG
Le 7e Salon technologique Meet AI Compiler 2025 s'est clôturé avec succès à Beijing Zhongguancun le 5 juillet. Zhang Ning, architecte IA chez AMD, a prononcé une conférence intitulée « Aider la communauté open source, analyser le compilateur AMD Triton ». En mettant l'accent sur les contributions techniques de l'entreprise à la communauté open source, il a analysé de manière systématique la technologie de base, le support de l'architecture sous-jacente et les avancées en matière de construction écologique du compilateur AMD Triton, offrant aux développeurs une perspective complète pour une compréhension approfondie de la programmation GPU hautes performances et de l'optimisation des compilateurs. Cet article est une transcription des points saillants de la présentation de Zhang Ning.
Voir le rapport complet :https://go.hyper.ai/jJLD8
À l'ère des médias sociaux et du contenu visuel, la retouche photo est passée d'une simple compétence de conception à un besoin quotidien. Le désir des utilisateurs d'outils pratiques et efficaces n'a jamais cessé, et la retouche photo en une seule phrase devient progressivement une réalité grâce aux progrès technologiques. FLUX.1-Kontext-dev, récemment open source, a atteint des performances comparables à celles de nombreux modèles à code source fermé tels que GPT-image-1, avec seulement 12 B de paramètres.
Voir le rapport complet :https://go.hyper.ai/EJIIa
Articles populaires de l'encyclopédie
1. DALL-E
2. Fusion de tri réciproque RRF
3. Front de Pareto
4. Compréhension linguistique multitâche à grande échelle (MMLU)
5. Apprentissage contrastif
Voici des centaines de termes liés à l'IA compilés pour vous aider à comprendre « l'intelligence artificielle » ici :

Suivi unique des principales conférences universitaires sur l'IA :https://go.hyper.ai/event
Voici tout le contenu de la sélection de l’éditeur de cette semaine. Si vous avez des ressources que vous souhaitez inclure sur le site officiel hyper.ai, vous êtes également invités à laisser un message ou à soumettre un article pour nous le dire !
À la semaine prochaine !








