Command Palette
Search for a command to run...
Zhang Ning, Architecte IA AMD : Analyse Du Compilateur AMD Triton Sous Différents Angles Pour Contribuer À La Création d'un Écosystème Open Source

Le 5 juillet, le 7e Salon des technologies du compilateur Meet AI, organisé par HyperAI, s'est tenu comme prévu. Malgré la chaleur torride du milieu de l'été, l'enthousiasme du public était toujours au rendez-vous. La salle était bondée, et beaucoup d'entre eux se sont même levés pour écouter chaque séance de partage. De nombreux intervenants d'AMD, de Muxi Integrated Circuits, de ByteDance et de l'Université de Pékin se sont relayés sur scène, apportant des analyses approfondies du secteur et des tendances, de la compilation de base à la mise en œuvre, le tout riche en informations pratiques !
Suivez le compte public WeChat « HyperAI Super Neuro » et répondez au mot-clé « 0705 AI Compiler » pour obtenir le discours PPT du conférencier autorisé.




Langage de programmation conçu pour simplifier le développement de noyaux GPU hautes performances, Triton est devenu un outil clé du cadre de raisonnement et d'entraînement LLM en simplifiant la programmation complexe en calcul parallèle. Son principal avantage réside dans l'équilibre entre efficacité du développement et performances matérielles : il évite l'exposition des détails matériels sous-jacents et libère la puissance de calcul du GPU grâce à l'optimisation du compilateur. Cette fonctionnalité l'a rapidement rendu populaire au sein de la communauté open source.
En tant qu'entreprise leader dans le domaine des GPU, AMD a pris l'initiative de soutenir le langage Triton et de contribuer au code source de la communauté open source afin de promouvoir la compatibilité entre fournisseurs de l'écosystème Triton. Cette initiative renforce non seulement l'influence technique d'AMD dans le domaine du calcul haute performance, mais offre également aux développeurs internationaux des options de programmation GPU plus flexibles grâce à un modèle de collaboration open source, notamment pour l'entraînement et le raisonnement de modèles volumineux, ouvrant ainsi une nouvelle voie à l'optimisation de la puissance de calcul.
Dans un discours intitulé « Soutenir la communauté open source, analyser le compilateur AMD Triton », Zhang Ning, un architecte IA d'AMD, a interprété systématiquement la technologie de base, le support de l'architecture sous-jacente et les réalisations de construction écologique du compilateur AMD Triton, en se concentrant sur les contributions techniques de l'entreprise à la communauté open source.Il offre aux développeurs une perspective complète pour comprendre en profondeur la programmation GPU hautes performances et l'optimisation du compilateur.
HyperAI a compilé et résumé le discours du professeur Zhang Ning sans en compromettre l'intention initiale. Voici la transcription de son discours.
Triton : programmation efficace, compilation en temps réel, itération flexible
Triton a été proposé par OpenAI et est un langage de programmation et un compilateur open source conçu pour simplifier le développement de noyaux GPU hautes performances.Il est largement utilisé dans les cadres de formation au raisonnement des LLM. Ses principales caractéristiques sont les suivantes :
* Une programmation efficace peut simplifier le développement du noyau, permettant aux développeurs d'écrire efficacement du code GPU sans avoir à comprendre en profondeur l'architecture sous-jacente complexe du GPU ;
* La compilation en temps réel, prenant en charge la compilation juste à temps, peut générer et optimiser dynamiquement le code GPU pour s'adapter aux différentes exigences matérielles et de tâches ;
* La structure flexible de l'espace d'itération, basée sur un programme en blocs et un thread scalaire, améliore la flexibilité de l'espace d'itération, facilite la gestion des opérations clairsemées et optimise la localité des données.
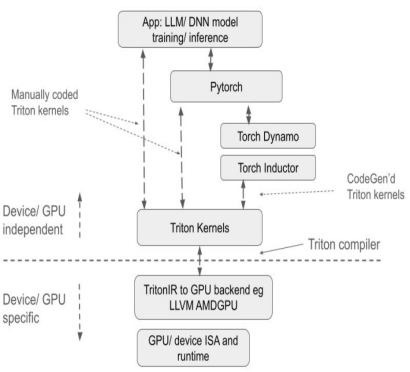
Par rapport aux solutions traditionnelles, Triton présente des avantages significatifs :
d'abord,En tant que projet open source, Triton fournit un environnement de programmation basé sur Python. Les utilisateurs peuvent implémenter le noyau GPU en développant du code Python Triton sans se soucier des détails de l'architecture GPU sous-jacente, ce qui réduit considérablement la difficulté de développement et améliore significativement l'efficacité du développement produit par rapport à d'autres méthodes de programmation GPU telles que AMD HIP. Son compilateur utilise diverses stratégies d'optimisation basées sur les caractéristiques de l'architecture GPU pour convertir le code Python en code assembleur GPU optimisé, réaliser la compilation automatique des opérations tensorielles de niveau supérieur en instructions GPU sous-jacentes et garantir un fonctionnement efficace du code sur le GPU.
Deuxièmement,Triton offre une bonne compatibilité multi-matériel. Le même code peut théoriquement s'exécuter sur divers matériels, notamment les GPU NVIDIA et AMD, ainsi que les GPU domestiques compatibles avec Triton. En termes de performances et de flexibilité, il offre une meilleure flexibilité d'optimisation que des plateformes comme PyTorch, et peut masquer les détails du fonctionnement GPU sous-jacent par rapport à CUDA, permettant ainsi aux développeurs de se concentrer davantage sur l'implémentation des algorithmes.
Comparée à l'API PyTorch, elle se concentre davantage sur l'implémentation spécifique des opérations de calcul, permettant aux développeurs de définir avec souplesse des méthodes de segmentation des blocs de threads, d'effectuer des opérations de lecture et d'écriture de données au niveau bloc/tuile, et d'exécuter des primitives de calcul liées au matériel. Elle est particulièrement adaptée au développement de stratégies d'optimisation des performances telles que la fusion d'opérateurs et le réglage des paramètres.
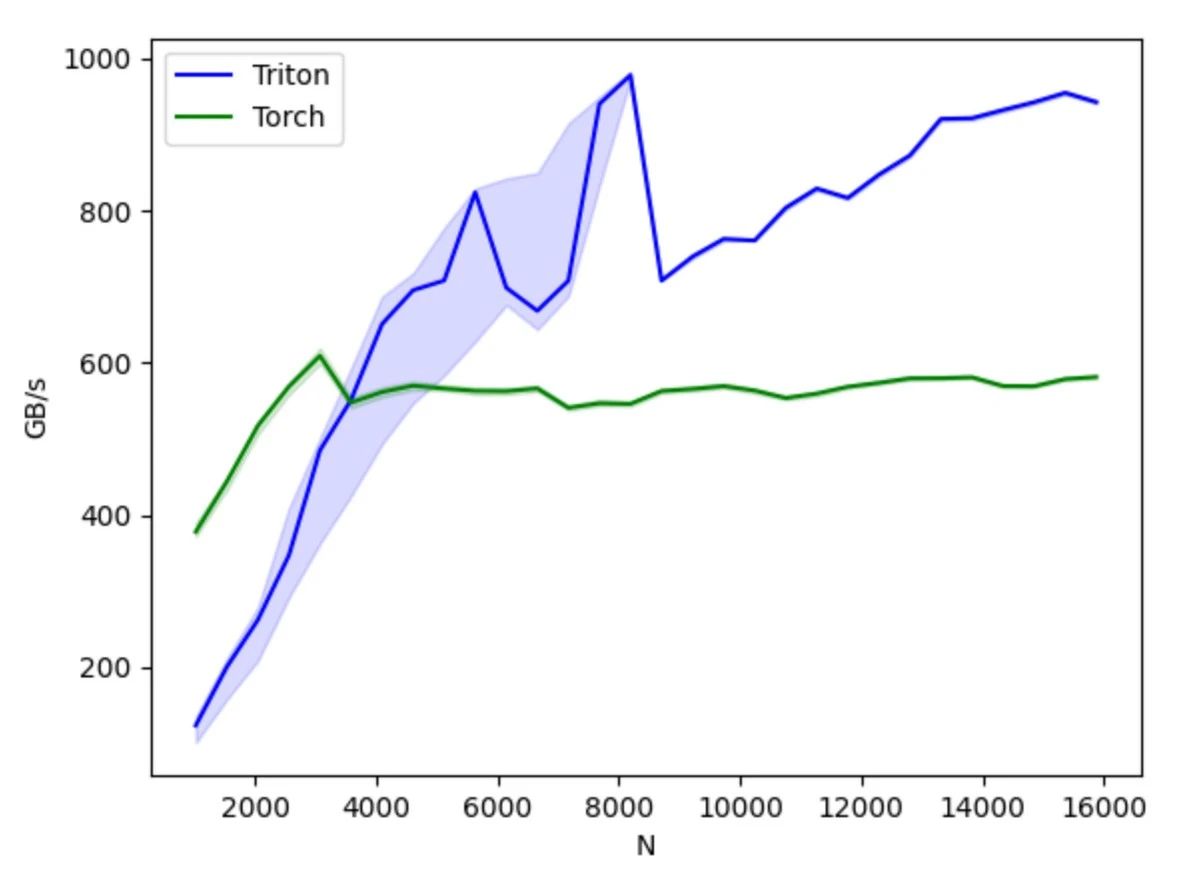
Comparé à CUDA, Triton masque le contrôle des opérations au niveau des threads et laisse le compilateur prendre en charge automatiquement des détails tels que le stockage partagé, le parallélisme des threads, l'accès à la mémoire fusionnée et la disposition des tenseurs. Cela réduit la complexité du modèle de programmation parallèle tout en améliorant l'efficacité du développement du code GPU, permettant ainsi un équilibre optimal entre efficacité du développement et performances du programme. Les développeurs peuvent se concentrer sur la conception et l'implémentation de l'algorithme sans se soucier des détails matériels sous-jacents ni des techniques d'optimisation de la programmation. En maîtrisant les principes simples de la programmation parallèle, ils peuvent développer rapidement du code GPU avec de meilleures performances.
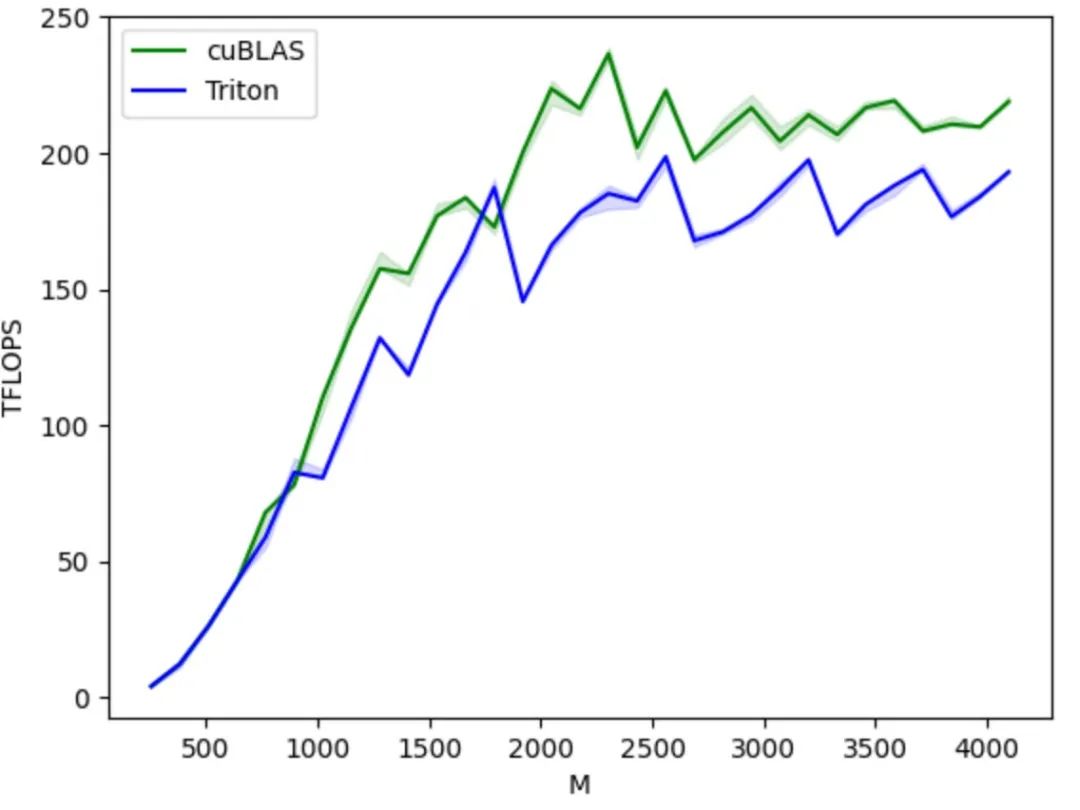
D'un point de vue écologique, il repose sur l'environnement Python et utilise le type de données tenseur défini par PyTorch. Ses fonctions s'intègrent parfaitement à l'écosystème PyTorch. Comparé à CUDA, un environnement fermé, le code source et l'écosystème ouverts de Triton facilitent également le portage sur leurs propres puces par les fabricants de puces d'IA et l'utilisation de la communauté open source pour améliorer leur chaîne d'outils, favorisant ainsi le développement sain de l'écosystème Triton.
Processus de compilation AMD Triton
Le compilateur Triton se compose de trois modules clés : le module front-end, le module optimiseur et le module de génération de code machine back-end, comme illustré dans la figure suivante :
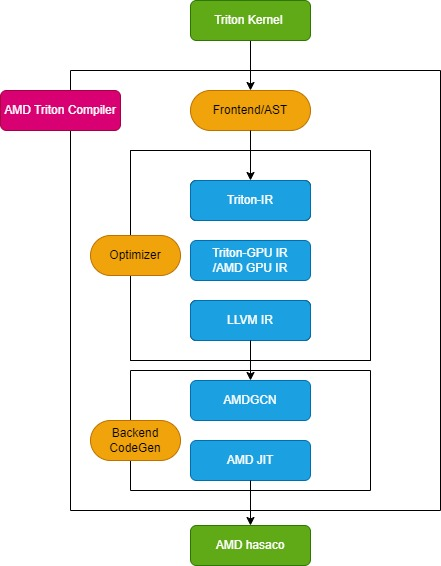
Module frontal
Le module frontal parcourt l'arbre de syntaxe abstraite (AST) de la fonction noyau Python Triton pour créer la représentation intermédiaire Triton (Triton-IR), et sa fonction noyau est convertie en Triton-IR.Par exemple, la fonction noyau add_kernel marquée par le décorateur @triton.jit sera convertie en IR correspondante dans ce module. La fonction d'entrée du décorateur JIT vérifie d'abord la valeur de la variable d'environnement TRITON_INTERPRET. Si la variable est vraie, InterpretedFunction est appelée pour exécuter le noyau Triton en mode interprété ; si elle est fausse, JITFunction est exécutée pour compiler et exécuter le noyau Triton sur le périphérique réel.
Le point d'entrée pour la compilation du noyau est la fonction de compilation Triton, appelée avec les informations sur le périphérique cible et les options de compilation. Ce processus crée le gestionnaire de cache du noyau, démarre le pipeline de compilation et remplit les métadonnées du noyau. De plus, il charge les dialectes spécifiques au backend, tels que TritonAMDGPUDialect pour les plateformes AMD, ainsi que les modules LLVM spécifiques au backend qui gèrent la compilation LLVM-IR. Une fois toutes les préparations terminées, la fonction ast_to_ttir est appelée pour générer le fichier Triton-IR pour le noyau.
Module d'optimisation
Le module d'optimisation est divisé en 3 parties principales : l'optimisation Triton-IR, l'optimisation Triton-GPU IR et l'optimisation LLVM-IR.
* Optimisation Triton-IR
Sur les plateformes AMD, le pipeline d'optimisation Triton-IR est défini par la fonction make_ttir. À ce stade, les optimisations sont indépendantes du matériel et incluent l'inlining, l'élimination des sous-expressions courantes, la normalisation, l'élimination du code mort, le mouvement du code invariant en boucle et le déroulement de la boucle.
* Optimisation IR Triton-GPU
Sur la plateforme AMD, le processus d'optimisation Triton-IR est défini par la fonction make_ttgir afin d'améliorer les performances du GPU. En nous basant sur les caractéristiques des GPU AMD et notre expérience en matière d'optimisation, nous avons également développé un processus d'optimisation spécifique, illustré dans la figure suivante :
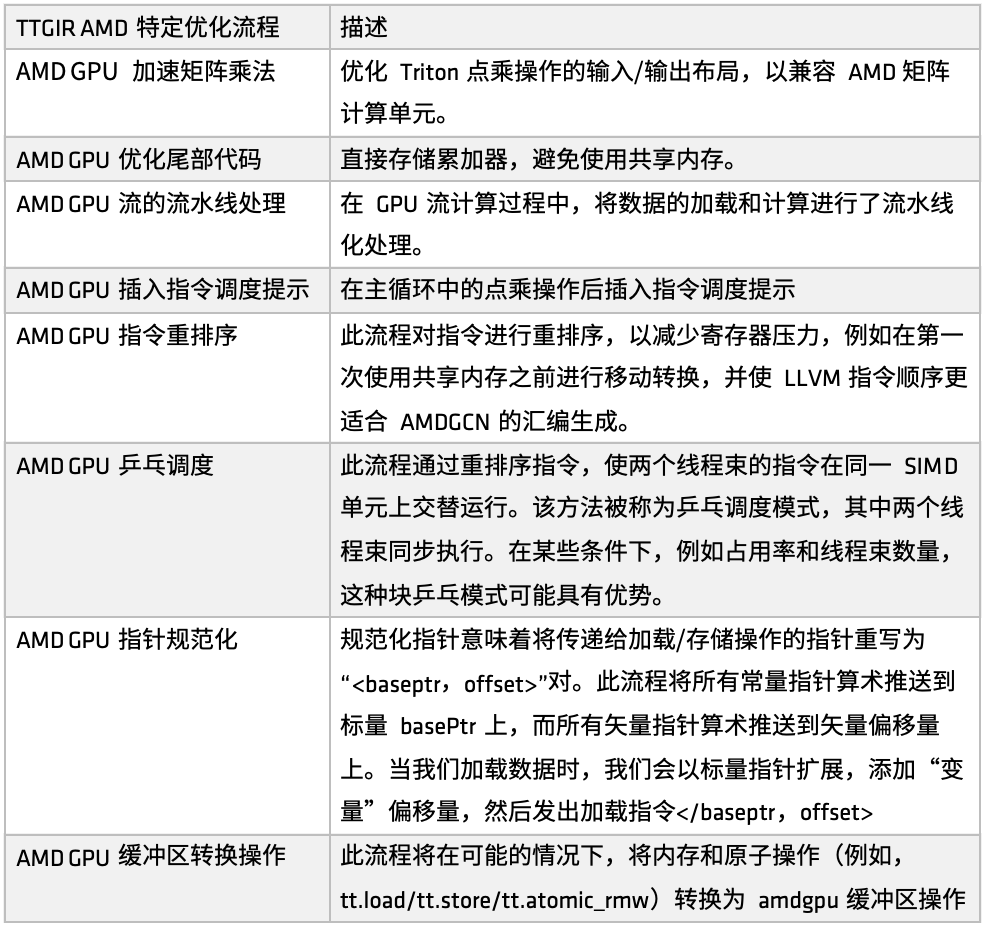
Tout d’abord, la multiplication matricielle accélérée pour les GPU AMD,L'optimisation se concentre sur la disposition des entrées/sorties de la multiplication de points dans Triton, améliorant ainsi sa compatibilité avec les unités de calcul matricielles d'AMD (telles que Matrix). Cette optimisation implique un traitement de correspondance important pour l'architecture CDNA, ce qui représente une part relativement importante de l'implémentation. Si vous souhaitez optimiser en profondeur le code généré par Triton sur la plateforme AMD, cette partie de l'implémentation mérite d'être étudiée.
Deuxièmement, dans l’étape de traitement de la queue,La stratégie d'optimisation consiste à stocker directement l'accumulateur, évitant ainsi l'utilisation de la mémoire partagée, réduisant la pression d'accès à la mémoire partagée et améliorant l'efficacité globale.
Ensuite, dans le processus de calcul de flux GPU, le traitement par pipeline du chargement et du calcul a été introduit.Autrement dit, pendant l'exécution de la tâche précédente, la mémoire correspondante est appelée pour charger les données, créant ainsi un mode d'exécution parallèle du chargement et du calcul. Ce mécanisme a donné de bons résultats dans de nombreux scénarios utilisateur. Grâce à l'optimisation du pipeline, des conseils d'ordonnancement des instructions sont également introduits pour guider le flux d'instructions après la fin de l'opération de calcul ou à distance, améliorant ainsi l'efficacité de la réponse au niveau des instructions.
Par la suite, AMD a mis en œuvre plusieurs ensembles de réorganisation des instructions à des fins différentes.Y compris : soulager la pression du registre, éviter l'allocation et la libération de ressources redondantes, optimiser la connexion entre la charge et le processus de calcul, etc. Une partie de la réorganisation est étroitement intégrée au mécanisme de pipeline, et l'autre partie se concentre sur l'ajustement de l'ordre des instructions de LLVM IR pour mieux servir les règles de génération de l'assemblage AMDGCN.
En plus des conseils de réorganisation et de planification des instructions,Nous avons également introduit une autre stratégie d’optimisation de la planification : la planification ping-pong.Grâce au mécanisme de planification circulaire, deux threads warps sont exécutés en alternance sur la même unité SIMD pour éviter l'inactivité et l'attente, améliorant ainsi l'utilisation des ressources informatiques.
De plus, AMD a réalisé des optimisations dans la normalisation des pointeurs et les conversions d'opérations de tampon.L’objectif principal de cette optimisation est de mapper efficacement les instructions à des applications métier spécifiques et d’obtenir une exécution des instructions atomiques plus efficace.
Ces processus d'optimisation convertissent d'abord le Triton-IR en Triton-GPU IR. Au cours de ce processus, les informations de disposition sont intégrées à l'IR. Prenons l'exemple de la figure suivante, où le tenseur est représenté sous la forme d'une disposition #blocked.

Si nous essayons un autre exemple de multiplication de matrice Triton, le flux d'optimisation ci-dessus introduit l'accès à la mémoire partagée pour améliorer les performances, ce qui est une solution d'optimisation courante pour la multiplication de matrice, tout en utilisant la disposition amd_mfma conçue pour l'accélérateur AMD MFMA.
enfin,Lors de la vérification expérimentale, j'ai pris comme exemple une couche matricielle de multiplication matricielle plus complexe. Lors de la validation du mappage GPR (Registre à Usage Général), un grand nombre d'instructions matérielles ont été insérées, telles que MFMA, transposition, appels de mémoire partagée, etc. En réduisant les conflits de banques, en appliquant des opérations de brassage et en combinant la réorganisation des instructions et les stratégies de traitement par pipeline, toutes ces optimisations seront automatiquement ajoutées lors du processus de conversion Triton IR afin d'obtenir une meilleure adaptabilité matérielle et des performances accrues.

* Optimisation LLVM-IR
Sur les plateformes AMD, le processus d'optimisation est défini par la fonction make_llir. Cette fonction comprend deux parties : l'optimisation au niveau de l'IR et la configuration du compilateur LLVM du GPU AMD. Pour l'optimisation au niveau de l'IR, le processus d'optimisation spécifique au GPU AMD inclut des optimisations liées à la mémoire LDS/partagée et des optimisations générales au niveau LLVM-IR, comme illustré dans la figure suivante :
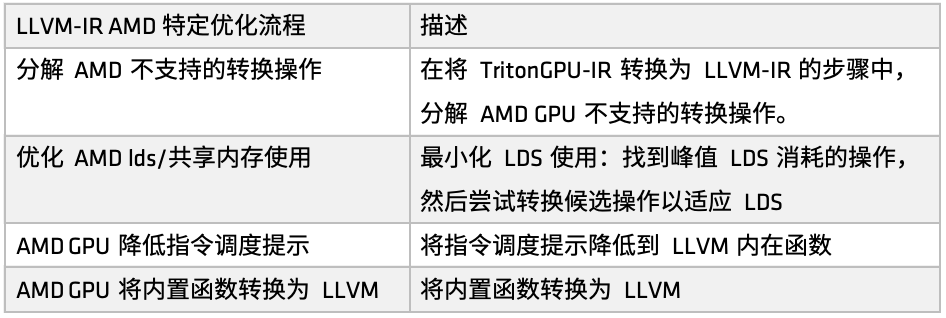
d'abord,Décomposer certaines opérations de conversion non prises en charge par AMD. Par exemple, lors de la conversion d'un GPU Triton IR en LLVM-IR, si nous rencontrons des chemins de conversion actuellement non pris en charge, nous décomposerons ces opérations en sous-opérations plus élémentaires afin de garantir le bon déroulement du processus de conversion.
Lors de la configuration du compilateur AMD GPU LLVM, initialisez d'abord la bibliothèque cible et le contexte LLVM, définissez les paramètres de compilation sur le module LLVM, puis définissez la convention d'appel pour le noyau HIP AMD GPU et configurez certaines propriétés LLVM-IR telles que amdgpu-flat-work-group-size, amdgpu-waves-per-eu et denormal-fp-math-f32, et enfin exécutez les optimisations LLVM et définissez le niveau d'optimisation sur OPTIMIZE_O3.
Documentation de référence sur la configuration des propriétés :
https://llvm.org/docs/AMDGPUUsage.html
Module de génération de code machine backend
Le module de génération de code machine back-end est principalement responsable de la conversion du code intermédiaire en un fichier binaire exécutable sur le matériel. Cette étape se divise en deux étapes : la génération du code assembleur AMDGCN et la construction du fichier ELF AMD hsaco final.
Tout d'abord, appelez la fonction translateLLVMIRToASM pour générer le code assembleur AMD à l'étape make_amdgcn. Ce processus finalise le mappage du code intermédiaire vers le jeu d'instructions de l'architecture cible, jetant ainsi les bases de la génération binaire ultérieure. Ensuite, le compilateur utilise la fonction assemble_amdgcn et le module de liaison ROCm pour générer un fichier binaire AMD hsaco ELF (Executable and Linkable Format) à l'étape make_hsaco. Ce fichier est le binaire final exécutable directement sur le GPU AMD et contient l'intégralité des instructions et métadonnées côté périphérique.
Grâce à ces deux étapes, le compilateur convertit efficacement la représentation intermédiaire de haut niveau en code exécutable GPU de bas niveau, garantissant que le programme peut s'exécuter sans problème sur des GPU tels que la série AMD Instinct et utiliser pleinement les performances du matériel sous-jacent.
Cloud pour développeurs de GPU AMD
AMD ouvre officiellement sa plateforme cloud GPU hautes performances, AMD Developer Cloud, aux développeurs mondiaux et aux communautés open source.Son objectif est de permettre à chaque développeur d'avoir un accès sans entrave aux ressources informatiques de classe mondiale, d'accéder facilement aux ressources GPU de la série AMD Instinct MI et de démarrer rapidement avec l'IA et les tâches de calcul haute performance.
Dans AMD Developer Cloud, les développeurs peuvent choisir de manière flexible les ressources informatiques en fonction de leurs besoins :
* Petit : 1 GPU série MI (192 Go VRAM)
* Grand : 8 GPU de la série MI (1536 Go de VRAM)
La plateforme minimise le seuil de configuration et permet aux utilisateurs de démarrer instantanément le Jupyter Notebook basé sur le cloud, sans installation complexe. La configuration est simple et rapide, avec un simple compte GitHub ou une adresse e-mail. De plus, AMD Developer Cloud fournit des conteneurs Docker préconfigurés intégrant des frameworks logiciels d'IA grand public. Cela réduit le temps de configuration de l'environnement tout en conservant une grande flexibilité, permettant aux développeurs de personnaliser le code en fonction des besoins spécifiques du projet.
Les développeurs sont invités à découvrir AMD Developer Cloud en personne, à exécuter leur code et à valider leurs idées. La plateforme vous offrira une puissance de calcul stable, puissante et flexible pour accélérer l'innovation et la mise en œuvre.
Lien vers AMD Developer Cloud :
https://www.amd.com/en/developer/resources/cloud-access/amd-developer-cloud.html
Obtenez le PPT :Suivez le compte public WeChat « HyperAI Super Neuro » et répondez au mot-clé « 0705 AI Compiler » pour obtenir le discours PPT du conférencier autorisé.








