Command Palette
Search for a command to run...
L'Université Nationale De Singapour a Mis En Œuvre Une Modélisation Fine Des Cohortes De Patients Basée Sur Des Données EHR Multidimensionnelles, Et La Précision De La Prédiction Du Séjour À l'hôpital a Augmenté De 16,3%

À l'ère du développement rapide des technologies de l'information médicale, les dossiers médicaux électroniques (DME) sont devenus un élément essentiel du système médical. Grâce à son architecture systématique, le DME stocke avec précision les dossiers médicaux des patients sous forme électronique.Couvrant tout, depuis les données démographiques de base jusqu'aux caractéristiques médicales dynamiques et variables dans le temps,Il fournit un support de données solide pour tous les aspects de la pratique médicale et joue un rôle irremplaçable dans des domaines clés tels que l’aide à la prise de décision clinique et l’optimisation de la gestion des patients.
En analysant la pratique clinique au plus fort de la pandémie de COVID-19 en 2020, les médecins ont identifié des tendances clés en constituant des cohortes de patients de différentes tranches d'âge : les patients âgés de 50 à 70 ans étaient plus susceptibles de présenter des symptômes graves tels que dyspnée et déclin cognitif, tandis que les patients âgés de 20 à 40 ans présentaient principalement des symptômes légers ou asymptomatiques. Cette analyse comparative de cohorte fournit non seulement une base directe pour la formulation de diagnostics et de plans de traitement, mais révèle également l'élément central de l'apprentissage de la représentation du DSE, longtemps négligé : les cohortes de patients.
Unité de base de la recherche médicale, les cohortes identifient des groupes de patients présentant des caractéristiques cliniques similaires grâce à des caractéristiques communes. Leur valeur dépasse largement la simple accumulation de données individuelles : elles permettent non seulement de découvrir les schémas pathologiques de populations spécifiques, comme la corrélation entre symptômes fébriles et infection à la COVID-19, mais aussi de fournir des données ciblées pour une intervention médicale de précision. Cependant, les méthodes traditionnelles de division des cohortes présentent de nombreuses limites et sont difficiles à satisfaire aux exigences du traitement des données des DSE.Si une division fine des files d’attente ne peut pas être obtenue, du bruit est facilement introduit et les informations précieuses au sein et entre les files d’attente ne peuvent pas être pleinement utilisées.
Dans ce contexte,L'Université nationale de Singapour et l'Université du Zhejiang ont proposé conjointement la méthode innovante NeuralCohort, qui a ouvert une nouvelle voie pour l'apprentissage de la représentation des DSE.Grâce à son architecture unique à deux modules, cette méthode devrait permettre de surmonter les difficultés actuelles, d'exploiter pleinement le potentiel des données du DSE et d'insuffler une dynamique puissante à l'analyse médicale. Ses perspectives d'application dans le domaine médical suscitent un vif intérêt. Elle devrait transformer en profondeur l'analyse des données médicales et les modèles de prise de décision clinique, et favoriser l'évolution du secteur médical vers un développement plus intelligent et plus précis.
Les résultats de recherche associés ont été sélectionnés pour l'ICML 2025 sous le titre « NeuralCohort : Apprentissage de la représentation neuronale sensible aux cohortes pour l'analyse des soins de santé ».
Points saillants de la recherche :
* NeuralCohort proposé dans cette étude est une méthode d'apprentissage de représentation neuronale prenant en compte les files d'attente qui se concentre sur la prise en charge de la génération de files d'attente à granularité fine
* NeuralCohort exploite de manière innovante les informations locales au sein de la cohorte et les informations globales entre les cohortes, des éléments clés qui n'ont pas été traités de manière adéquate dans les précédentes études d'analyse des dossiers médicaux électroniques.
* L'avantage de NeuralCohort réside dans son excellente compatibilité et sa capacité à s'intégrer facilement à divers modèles de base. Il peut être utilisé comme un plug-in polyvalent pour intégrer les informations de cohorte aux analyses médicales, améliorant ainsi les performances globales.

Adresse du document :
https://openreview.net/forum?id=bqQVa6VRvm
Autres articles sur les frontières de l'IA :
https://go.hyper.ai/owxf6
Système de données DSE : intégration d'informations médicales multidimensionnelles et prise en charge d'ensembles de données de recherche clinique
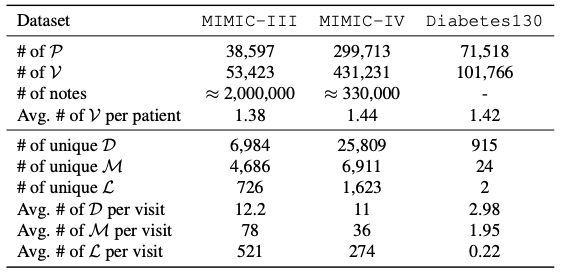
Le système de données de base impliqué dans cette étude est basé sur les dossiers médicaux électroniques (DME).Sa structure de données intègre les informations médicales du patient tout au long du cycle.Elle comprend des dossiers détaillés d'hospitalisation, de consultation externe et d'urgence, ainsi que des informations multidimensionnelles telles que le diagnostic clinique, le plan de traitement, l'historique des médicaments, les résultats d'examens, les comptes rendus d'imagerie et les notes cliniques. Cette base de données structurée suit l'état de santé des patients de manière longitudinale et fournit un support complet pour la prise de décision clinique, la médecine personnalisée et la recherche en santé des populations. Comme le montre le tableau ci-dessous, les ensembles de données spécifiques utilisés dans cette étude comprennent :
L'ensemble de données MIMIC-III est une ressource médicale importante accessible au public, couvrant 53 423 dossiers d'hospitalisation uniques.Il concerne les patients adultes âgés de 16 ans et plus admis à l'unité de soins intensifs du Beth Israel Dekaney Medical Center entre 2001 et 2012, et contient également 2 083 180 notes cliniques anonymisées, fournissant des informations approfondies sur l'évolution de la maladie des patients, le processus de traitement et la prise de décision clinique.
L'ensemble de données MIMIC-IV se concentre sur les informations d'admission des patients collectées entre 2008 et 2022.Il adopte une structure d'organisation des données modulaire, mettant l'accent sur la traçabilité et l'indépendance des sources de données, ce qui permet aux chercheurs de faire appel de manière flexible à différentes sources de données et à leurs données conjointes en fonction de leurs besoins.
L'ensemble de données Diabetes130 collecte des données sur les soins cliniques auprès de 130 hôpitaux américains et réseaux de soins de santé intégrés entre 1999 et 2008., en se concentrant sur l'analyse des modèles dans le domaine du traitement du diabète, ses thèmes de données uniques et son accumulation de données à long terme fournissent un support de données précis pour une recherche approfondie sur les modèles historiques de soins du diabète, l'optimisation des plans de traitement pour les patients diabétiques et la réalisation de services médicaux sûrs et personnalisés.
Modèle NeuralCohort : un cadre d'apprentissage de représentation de DSE basé sur deux modules et prenant en compte les cohortes
Afin d'intégrer efficacement les cohortes de patients pour améliorer l'effet d'apprentissage de la représentation des données du dossier médical électronique (DME), NeuralCohort se compose de deux modules principaux : le module de synthèse de cohorte pré-contextuelle et le module d'apprentissage de cohorte bi-échelle.
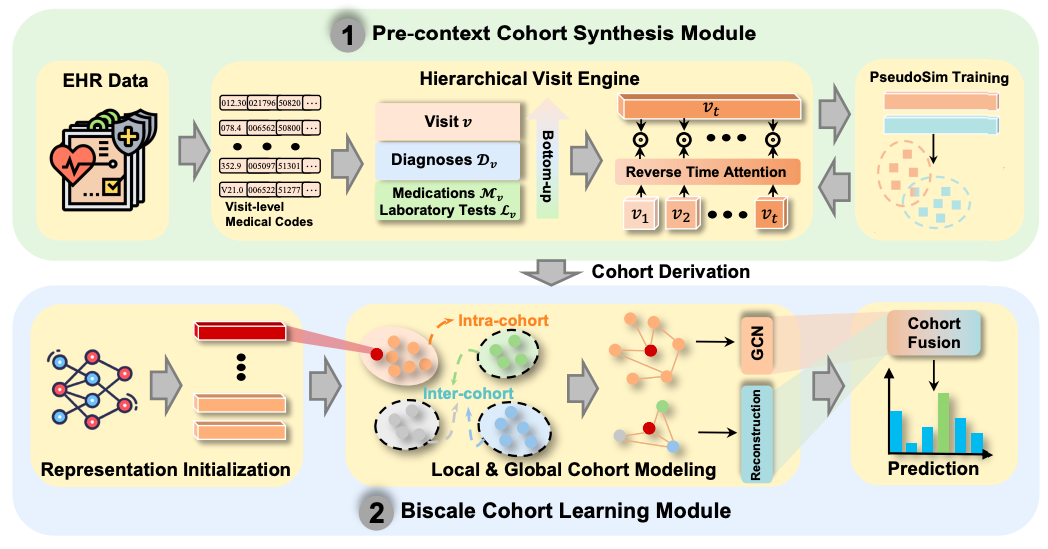
Dans le module de synthèse de file d'attente pré-contexte,Le modèle NeuralCohort a introduit pour la première fois un moteur de visite hiérarchique.Il peut gérer des structures ontologiques complexes de codes de diagnostic, telles que l'arborescence de la CIM-9. En combinant la représentation des chemins et la mesure de similarité sémantique, le module peut distinguer efficacement les termes médicaux associés hiérarchiquement, comme les différents codes du diabète et de ses complications. Parallèlement, le modèle peut intégrer les caractéristiques hiérarchiques des codes de diagnostic, de médicament et de test.Et utilisez le mécanisme d'attention temporelle inversée (Reverse Time Attention),Les informations de visite historiques sont agrégées de manière dynamique avec la visite actuelle comme point d'ancrage pour capturer la dépendance temporelle de la séquence de visite.
Pour remédier à l'inefficacité de l'annotation manuelle traditionnelle de la similarité des patients, le module a introduit de manière innovante la tâche d'entraînement PseudoSim, généré des pseudo-étiquettes à l'aide de codes diagnostiques et optimisé la représentation des patients grâce à l'estimation neuronale d'information mutuelle. Enfin, la dérivation de cohorte a été réalisée à l'aide de la divergence de Jensen-Shannon et de la distribution t de Student, fournissant un schéma structuré de regroupement des patients pour les analyses ultérieures.
Le module d'apprentissage de file d'attente à double échelle est dédié à l'exploration des caractéristiques communes au sein de la file d'attente et des différentes caractéristiques entre différentes files d'attente..Dans la modélisation de cohorte locale, le modèle traite chaque cohorte comme une structure graphique et construit une matrice d'adjacence en utilisant la similarité cosinus des représentations des patients. Le réseau neuronal graphique agrège les informations des nœuds couche par couche pour capturer les schémas d'interaction des patients d'une même cohorte.
La modélisation de cohorte globale utilise une architecture encodeur-décodeur pour maintenir l'intégrité sémantique de la cohorte grâce à la perte de reconstruction, tout en combinant la perte de contraste pour renforcer la séparation des caractéristiques des différentes cohortes et assurer la distinction entre les cohortes.
Enfin, la représentation initiale du réseau fédérateur, la représentation locale au sein de la file d'attente et la représentation globale entre les files d'attente sont fusionnées via le mécanisme d'attention inter-domaines pour former une représentation finale contenant des informations sur la file d'attente à plusieurs niveaux. Lors de l'apprentissage du modèle, la fonction de perte intègre la perte d'apprentissage par pseudo-similarité, la perte de dérivation de file d'attente, la perte de comparaison de file d'attente et la perte de tâches en aval. L'optimisation multi-objectifs est réalisée par l'ajustement des paramètres de pondération. Cela permet à NeuralCohort non seulement d'apprendre des caractéristiques individuelles précises des patients, mais aussi de capturer des schémas de groupes de files d'attente cliniquement interprétables, offrant ainsi une solution alliant précision et interprétabilité pour les tâches d'analyse de données médicales, et devrait favoriser une prise de décision médicale scientifique et précise.
Vérification expérimentale multidimensionnelle : la précision du modèle NeuralCohort a été augmentée de 16,3%, améliorant considérablement la prise de décision dans la gestion des patients
Pour évaluer l’effet d’optimisation de NeuralCohort sur l’apprentissage de la représentation des dossiers médicaux électroniques (DME), l’équipe de recherche a construit un cadre expérimental complet.
Les chercheurs ont choisi Med2Vec, MiME et ClinicalBERT, trois modèles représentatifs de l'analyse de données médicales, comme cadres de référence. Parallèlement, afin de réaliser une comparaison efficace, sept algorithmes d'intégration de cohortes traditionnels, tels que KNN et K-Means, ont été intégrés à l'expérience comme méthodes de comparaison.
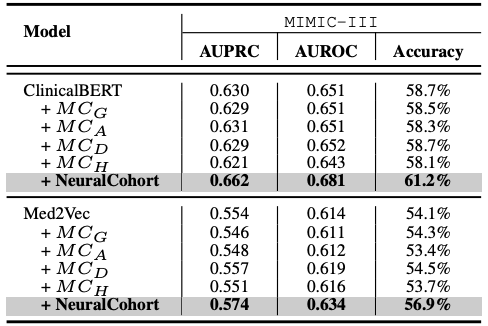
La conception expérimentale se concentre sur deux tâches clés de prédiction médicale : la prédiction de la réadmission à l’hôpital et la prédiction du séjour de longue durée (LOS).Ces deux tâches sont cruciales pour la gestion des ressources médicales et l'amélioration de la qualité des soins aux patients. Afin d'évaluer de manière exhaustive les performances du modèle, les chercheurs ont utilisé trois indicateurs d'évaluation largement reconnus, l'AUPRC, l'AUROC et la précision, et ont mené cinq séries d'expériences répétées afin d'obtenir des résultats statistiques stables et fiables, évaluant ainsi systématiquement la capacité de généralisation du modèle.
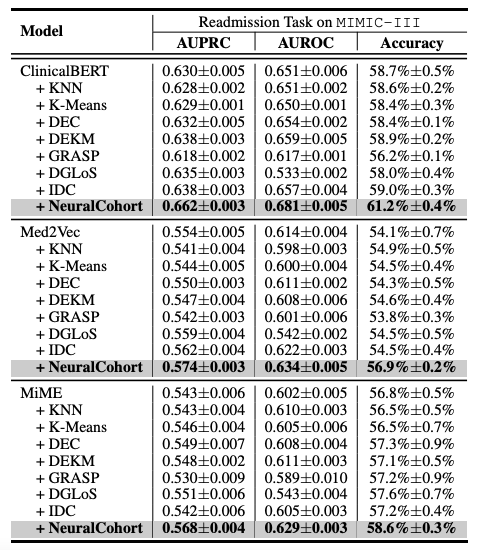
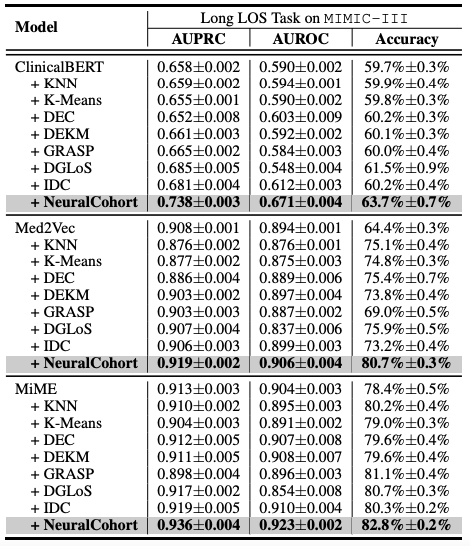
Les résultats expérimentaux globaux sont présentés dans le tableau suivant. NeuralCohort obtient de bons résultats dans deux tâches de prédiction du jeu de données MIMIC-III. Comparé au modèle de référence traditionnel,L'indicateur AUPRC a été amélioré jusqu'à 8,0%, l'indicateur AUROC a été amélioré de 8,1% et la précision a été significativement supérieure de 16,3%.
Une analyse plus approfondie a révélé que le modèle de base n’a pas réussi à obtenir des gains de performance constants.La raison principale est qu’il est insuffisant pour modéliser des informations de file d’attente à granularité fine.Par exemple, les algorithmes KNN et K-Means ne fonctionnent pas dans un espace de caractéristiques sensible à la similarité, le graphe global construit par DGLoS est grossier, GRASP se concentre uniquement sur la modélisation entre cohortes, et DEC, DEKM et IDC ne peuvent pas modéliser efficacement la sémantique médicale. Ces défauts entraînent une mauvaise performance du modèle de base pour simuler les similarités entre patients et peuvent même introduire du bruit dans le modèle principal, réduisant ainsi les performances globales.
Comparé aux méthodes traditionnelles de construction de cohortes médicales, NeuralCohort présente également des avantages significatifs. Les méthodes traditionnelles divisent généralement les cohortes en fonction de caractéristiques limitées telles que le sexe, l'âge, le diagnostic de diabète et d'hypertension. Les cohortes générées par cette méthode sont relativement grossières, ce qui complique l'exploration des modèles de cohortes. De plus, il est facile de regrouper des patients différents au sein d'une même cohorte, ce qui introduit du bruit. En revanche, NeuralCohort utilise la représentation séquentielle des visites des patients au sein et entre les cohortes pour fonctionner à un niveau plus fin.Cela a amélioré la similarité clinique des patients de la cohorte dans l’ensemble de données MIMIC-III de 23,5%.
Comparaison de la cohorte traditionnelle et de la NeuralCohort sur l'ensemble de données MIMIC-III
L'analyse d'interprétabilité révèle également les avantages de NeuralCohort. Le score de Calinski-Harabasz montre que la cohorte générée par NeuralCohort améliore le score CH de 18,7% à 25,4% dans la tâche LOS à long terme par rapport à des méthodes telles que K-Means. L'analyse visuelle basée sur t-SNE montre également que la représentation directement issue du modèle de base présente un chevauchement significatif des clusters, tandis que NeuralCohort, comme le montre la figure ci-dessous, injecte des informations sur la cohorte.La discrimination des huit cohortes cibles a été améliorée par 41.2%, parmi lesquelles les limites caractéristiques des groupes cliniques typiques tels que la cohorte des maladies cardiovasculaires et la cohorte des maladies métaboliques chroniques étaient particulièrement claires.

En termes cliniques,NeuralCohort est capable d’identifier les caractéristiques spécifiques à la cohorte qui sont directement corrélées aux résultats cliniques, améliorant ainsi considérablement la prise en charge des patients.Par exemple, les caractéristiques uniques des quatre cohortes identifiées par les tests t couvraient différents types de populations de patients tels que les maladies cardiovasculaires, les maladies métaboliques et sanguines chroniques, les problèmes rénaux et urinaires et les maladies chroniques et aiguës complexes.
L'identification de ces caractéristiques permet aux hôpitaux d'allouer des ressources plus spécifiquement, telles que des lits de télémétrie, des consultations de cardiologie, des éducateurs en diabète, des équipes rénales, etc., et de formuler des mesures d'intervention correspondantes, telles que l'utilisation opportune de diurétiques, le titrage de l'insuline et la planification des examens d'imagerie, améliorant ainsi considérablement l'efficacité de l'hôpital et la qualité des soins aux patients.
Collaboration industrie-recherche, écosystème d'innovation bidirectionnel en matière de DSE
Dans le domaine de l'apprentissage de la représentation des dossiers de santé électroniques (DSE) et de l'analyse de cohorte, les communautés universitaires et commerciales mondiales encouragent la libération profonde de la valeur des données médicales grâce à des avancées technologiques de pointe et à des innovations dans la pratique clinique, insufflant un nouvel élan au développement de la médecine de précision.
Le modèle MHGRL proposé par l'équipe du professeur Wang Xiaoli de l'Université de Xiamen intègre la structure interne du DSE avec les connaissances médicales externes en construisant un graphe hétérogène multimodal.La précision de la prédiction des maladies a été considérablement améliorée sur des ensembles de données tels que MIMIC-III.Le mécanisme d'attention inversée dans le temps adopté par ce modèle renforce la corrélation entre la visite actuelle et l'enregistrement historique, ce qui fait écho au module de synthèse de file d'attente pré-contextuelle de NeuralCohort dans la logique technique, et tous deux reflètent l'accent mis sur la modélisation des informations de séries chronologiques.
Le modèle GEMS construit par l’équipe de l’Université Cornell est basé sur 8 millions de données réelles de DSE.L'étude a démontré l'application directe de l'analyse de cohorte à la prise de décision clinique. L'étude a capturé le vecteur de caractéristiques à 104 dimensions des patients atteints d'un cancer du poumon avancé grâce à un encodeur de réseau neuronal graphique, puis l'a combiné à un module de clustering pour identifier trois sous-phénotypes présentant des différences significatives de survie. Son indice C pour la prédiction de la survie globale a atteint 0,665, dépassant largement le modèle de référence traditionnel. Son approche technique est très cohérente avec le module d'apprentissage de cohorte à double échelle de NeuralCohort en termes de méthodologie, et tous deux se concentrent sur l'extraction de caractéristiques de cohorte cliniquement significatives à partir de données complexes.
Le monde des affaires a également obtenu des résultats remarquables et transforme des technologies de pointe issues du monde universitaire en outils d'application clinique pratiques. Par exemple, le programme PATH, fruit d'une collaboration entre le NHS britannique et Hippocratic AI,Grâce à la collecte automatisée des antécédents médicaux et à la vérification des références par des agents conversationnels, la période d'attente pour les consultations spécialisées peut être raccourcie par 35%.Ce système de triage intelligent basé sur le DMP intègre un module d'analyse de cohorte permettant d'identifier en temps réel les groupes de patients à haut risque. Par exemple, il peut extraire des données cliniques des caractéristiques complexes telles que « bronchopneumopathie chronique obstructive avec exacerbation aiguë » grâce au traitement du langage naturel et ajuster dynamiquement les priorités des patients.
En résumé, le monde universitaire a construit des modèles de cohorte plus précis grâce à l'innovation algorithmique, élargissant ainsi continuellement la profondeur et l'étendue de l'exploration des données médicales. Le monde des affaires, s'appuyant sur ses capacités de transformation technologique, a transformé ces technologies de pointe en outils cliniques applicables, améliorant ainsi l'efficacité et la qualité des services médicaux. Cet écosystème d'innovation bidirectionnel devrait non seulement aider les médecins à obtenir un diagnostic plus précis, mais aussi à détecter les signaux d'alerte précoces des risques individuels liés aux caractéristiques de groupe, à promouvoir la transformation des modèles de services médicaux, du traitement des maladies à la gestion de la santé, et à soutenir fortement l'optimisation et la modernisation du système médical mondial.
Articles de référence :
1.https://cdmc.xmu.edu.cn/info/1002/3683.htm
2.https://mp.weixin.qq.com/s/Z1Wl0FIPHpwrvnNDCE5KwA
3.https://mp.weixin.qq.com/s/neCUoGm75mTPwjvlND5_sg








