Command Palette
Search for a command to run...
Le Moteur Double De Raisonnement Multimodal OmniGen2, Doté d'une Fonction d'autocorrection, Ouvre La Voie À Un Nouveau Paradigme Pour La Génération d'images ; 950 000 Étiquettes De Classification ! TreeOfLife-200M Ouvre Une Nouvelle Dimension De La Cognition Des espèces.

Ces dernières années, la technologie d'IA générative a réalisé des avancées significatives dans le domaine des images. Des modèles tels que la série Stable Diffusion et DALL-E3 ont permis une génération de texte-image de haute qualité grâce à des modèles de diffusion. Cependant, ces modèles ne disposent pas des capacités complètes de compréhension perceptuelle et de génération requises par les modèles généraux de génération visuelle. OmniGen a été conçu pour fournir une solution unifiée pour diverses tâches de génération, basée sur l'architecture du modèle de diffusion. Il offre des capacités de traitement multitâche et peut générer des images de haute qualité sans plug-in supplémentaire. Il est indéniable que le modèle présente encore des limites en matière de découplage multimodal et de diversité des données.
Pour surmonter ces difficultés et améliorer encore la flexibilité et l’expressivité du système, OmniGen2 a réalisé une avancée majeure.Il dispose de deux chemins de décodage indépendants pour les modalités texte et image.Il utilise des paramètres non partagés et un étiqueteur d'image distinct. Cette conception permet à OmniGen2 de s'appuyer sur des modèles de compréhension multimodaux existants sans réajuster l'entrée de l'autoencodeur variationnel, préservant ainsi les capacités de génération de texte d'origine.
Actuellement, le site officiel d'HyperAI a lancé le tutoriel « OmniGen2 : Exploring Advanced Multimodal Generation », venez l'essayer~
OmniGen2 : exploration de la génération multimodale avancée
Utilisation en ligne :https://go.hyper.ai/fKbUP
Du 30 juin au 4 juillet, le site officiel de hyper.ai est mis à jour :
* Ensembles de données publiques de haute qualité : 10
* Sélection de tutoriels de qualité : 7
* Articles recommandés cette semaine : 5
* Interprétation des articles communautaires : 5 articles
* Entrées d'encyclopédie populaire : 5
* Principales conférences avec date limite en juillet : 4
Visitez le site officiel :hyper.ai
Ensembles de données publiques sélectionnés
1. Ensemble de données de génération d'images ShareGPT-4o-Image
ShareGPT-4o-Image est un jeu de données de génération d'images à grande échelle et de haute qualité, visant à migrer les capacités de génération d'images de niveau GPT-4o vers des modèles multimodaux open source. Toutes les images de ce jeu de données sont générées par la fonction de génération d'images de GPT-4o, et les données contiennent un total de 92 256 échantillons de génération d'images de GPT-4o.
Utilisation directe :https://go.hyper.ai/5G48Y

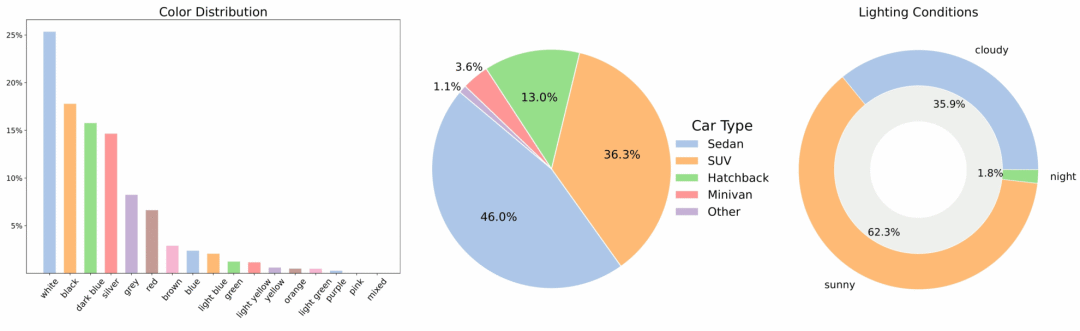
2. Ensemble de données vidéo de voiture multi-vues MAD-Cars
MAD-Cars est un vaste ensemble de données vidéo automobiles multi-vues, disponible dans la nature, qui élargit considérablement la portée des ensembles de données automobiles multi-vues publics existants. Cet ensemble de données contient environ 70 000 instances vidéo automobiles, avec une moyenne de 85 images par instance. La plupart des instances ont une résolution de 1920 × 1080, couvrant environ 150 marques de véhicules, incluant plusieurs modèles, couleurs et trois conditions d'éclairage.
Utilisation directe :https://go.hyper.ai/xuB9I
3. Ensemble de données d'images de cultures de plantes et de cultures
L'ensemble de données « Plantes et cultures » est un ensemble complet d'images de cultures pour l'IA agricole. Il contient 100 000 images standardisées couvrant 139 cultures largement répandues dans le monde. Il couvre les différents stades de croissance des cultures, des semis à la floraison et à la fructification. Le contenu des images couvre plusieurs parties structurelles telles que les feuilles, les tiges et les fruits, avec des informations de représentation riches. Toutes les images sont unifiées en 224 × 224 pixels afin de réduire l'impact des différences de taille sur l'entraînement des modèles.
Utilisation directe :https://go.hyper.ai/PLVJp

4. Manuel multimodal - Ensemble de données de manuels multimodaux de 6,5 millions
Multimodal-Textbook-6.5M vise à améliorer le pré-apprentissage multimodal et à étendre la capacité du modèle à gérer les entrées visuelles et textuelles entrelacées. L'ensemble de données contient 6,5 millions d'images et 800 millions de données textuelles issues de vidéos pédagogiques. Toutes les images et tous les textes sont extraits de vidéos pédagogiques en ligne, couvrant six matières fondamentales telles que les mathématiques, la physique et la chimie.
Utilisation directe :https://go.hyper.ai/q8Iin
5. Ensemble de données de paires questions-réponses indiennes IndicVault
Indic Vault est un ensemble de données de questions-réponses en langage courant indien, adapté au paramétrage des chatbots et des assistants vocaux. Cet ensemble de données contient des paires de questions-réponses rédigées dans le langage courant contemporain utilisé en Inde en 2025, reprenant des expressions familières réelles utilisées dans les conversations quotidiennes, couvrant 20 catégories principales.
Utilisation directe :https://go.hyper.ai/JhEUR
6. Ensemble de données de référence pour la description vidéo DREAM-1K
L'ensemble de données contient 1 000 clips vidéo annotés de complexité variable, répartis en cinq catégories différentes, chacun contenant au moins un événement dynamique impossible à identifier précisément à partir d'une seule image. Chaque vidéo est accompagnée d'annotations manuelles détaillées couvrant tous les événements, actions et mouvements.
Utilisation directe :https://go.hyper.ai/AgOm0
7. Ensemble de données d'analyse de détection de tumeurs cérébrales par IRM cérébrale
L'IRM cérébrale contient des images IRM cérébrales multiséquences de haute qualité issues de différents patients. Ces images incluent des séquences pondérées en T1, T2, FLAIR et en diffusion. Cet ensemble de données couvre plusieurs types de tumeurs cérébrales et est comparé à des témoins sains, ce qui le rend idéal pour le développement et la validation de modèles avancés d'apprentissage automatique et d'applications de recherche clinique.
Utilisation directe :https://go.hyper.ai/oZWNu
8. Ensemble de données de raisonnement mathématique AceReason-1.1-SFT
Cet ensemble de données sert de données d'entraînement SFT pour le modèle de raisonnement mathématique et de code AceReason-Nemotron-1.1-7B. Toutes les réponses de cet ensemble de données sont générées par DeepSeek-R1. L'ensemble de données AceReason-1.1-SFT contient 2 668 741 échantillons mathématiques et 1 301 591 échantillons de code, couvrant des données provenant de plusieurs sources. L'ensemble de données a été nettoyé et les échantillons présentant des chevauchements de 9 grammes avec les échantillons de test des tests de mathématiques et de code ont été filtrés.
Utilisation directe :https://go.hyper.ai/WGl1k
9. Ensemble de données de vision biologique TreeOfLife-200M
TreeOfLife-200M est le plus vaste et le plus diversifié des ensembles de données publics, compatibles avec l'apprentissage automatique, pour les modèles de vision par ordinateur biologique. Cet ensemble de données contient près de 214 millions d'images, couvrant 952 000 catégories d'espèces, et intègre des images et des métadonnées provenant de quatre principaux fournisseurs de données sur la biodiversité.
Utilisation directe :https://go.hyper.ai/UKC0H
10. Ensemble de données de génération de raisonnement médical VL-Health
VL-Health est le premier ensemble de données complet pour la compréhension et la génération de données médicales multimodales. Il intègre 765 000 échantillons de tâches de compréhension et 783 000 échantillons de tâches de génération, couvrant 11 modalités médicales et de multiples scénarios pathologiques.
Utilisation directe :https://go.hyper.ai/GvKlu
Tutoriels publics sélectionnés
Cette semaine, nous avons compilé 3 types de tutoriels publics de haute qualité :
*Tutoriels de génération et d'édition d'images : 3
*Tutoriels de génération 3D : 2
* Tutoriels de génération audio : 2
Tutoriel sur la génération et l'édition d'images
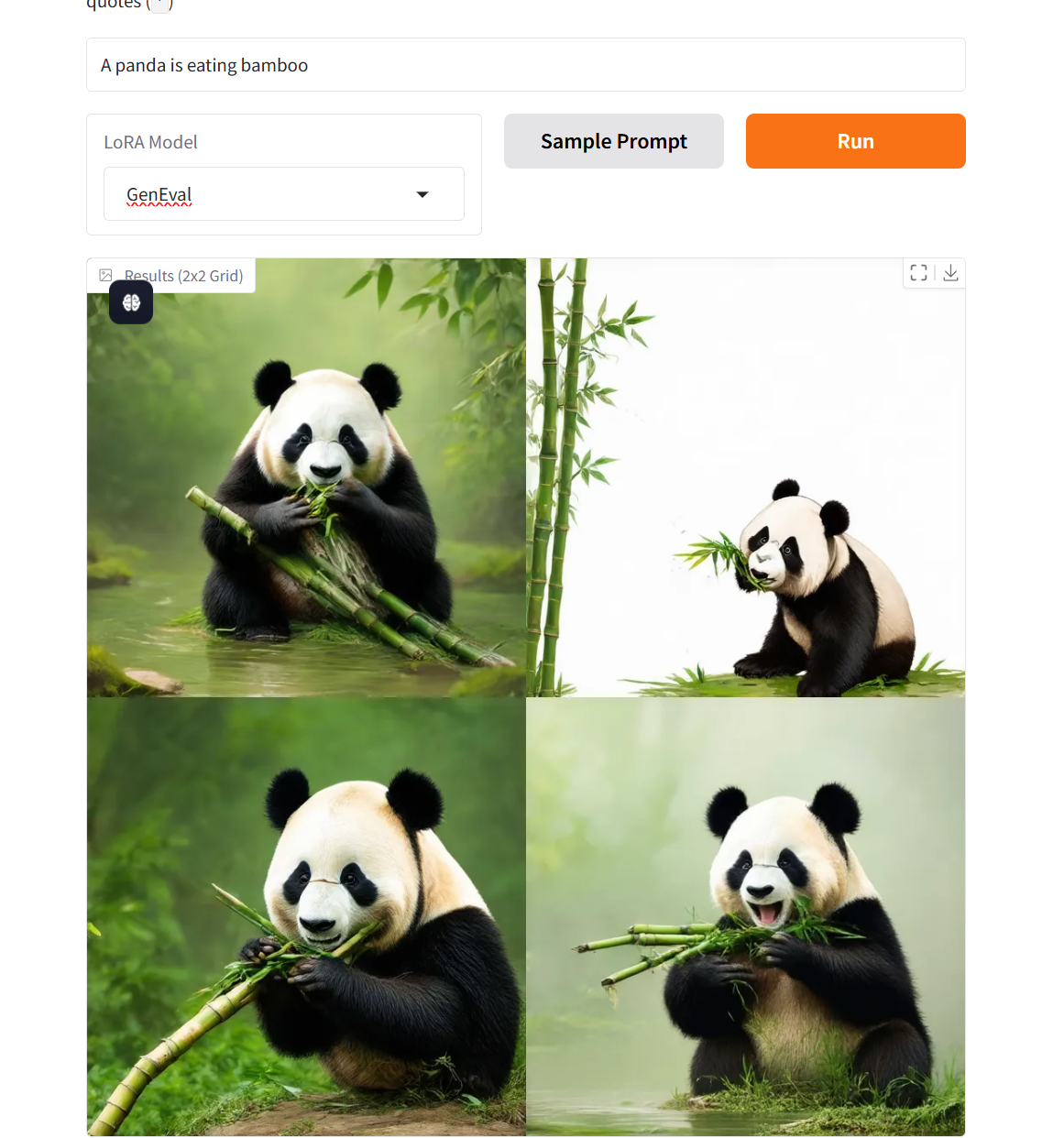
1. OmniGen2 : exploration de la génération multimodale avancée
OmniGen2 vise à fournir une solution unifiée pour de multiples tâches de génération, notamment la conversion de texte en image, l'édition d'images et la génération de contexte. La conception de paramètres non partagés et de tokeniseurs d'images distincts permet à OmniGen2 de s'appuyer sur des modèles de compréhension multimodaux existants sans réadapter les entrées VAE, tout en conservant les capacités de génération de texte d'origine.
Exécutez en ligne :https://go.hyper.ai/fKbUP

2. FLUX.1-Kontext-dev : Édition d'images en un clic pilotée par texte
L'édition d'image de FLUX.1 Kontext est une édition d'image au sens large, qui prend non seulement en charge l'édition d'image locale (modification ciblée d'éléments spécifiques de l'image sans affecter le reste), mais assure également la cohérence des caractères (conservation d'éléments uniques dans l'image tels que des caractères de référence ou des objets pour les maintenir cohérents dans plusieurs scènes et environnements).
Exécutez en ligne :https://go.hyper.ai/PqRGn

3. Démonstration du modèle de graphique de texte de correspondance de flux Flow-GRPO
Ce modèle a été le pionnier de l'intégration du cadre d'apprentissage par renforcement en ligne et de la théorie de l'appariement de flux, et a réalisé des progrès révolutionnaires dans le test de référence GenEval 2025 : la précision de génération combinée du modèle SD 3.5 Medium est passée de la valeur de référence de 63% à 95%, et l'indice d'évaluation de la qualité de génération a dépassé GPT-4o pour la première fois.
Exécutez en ligne :https://go.hyper.ai/v7xkq
Tutoriel de génération 3D
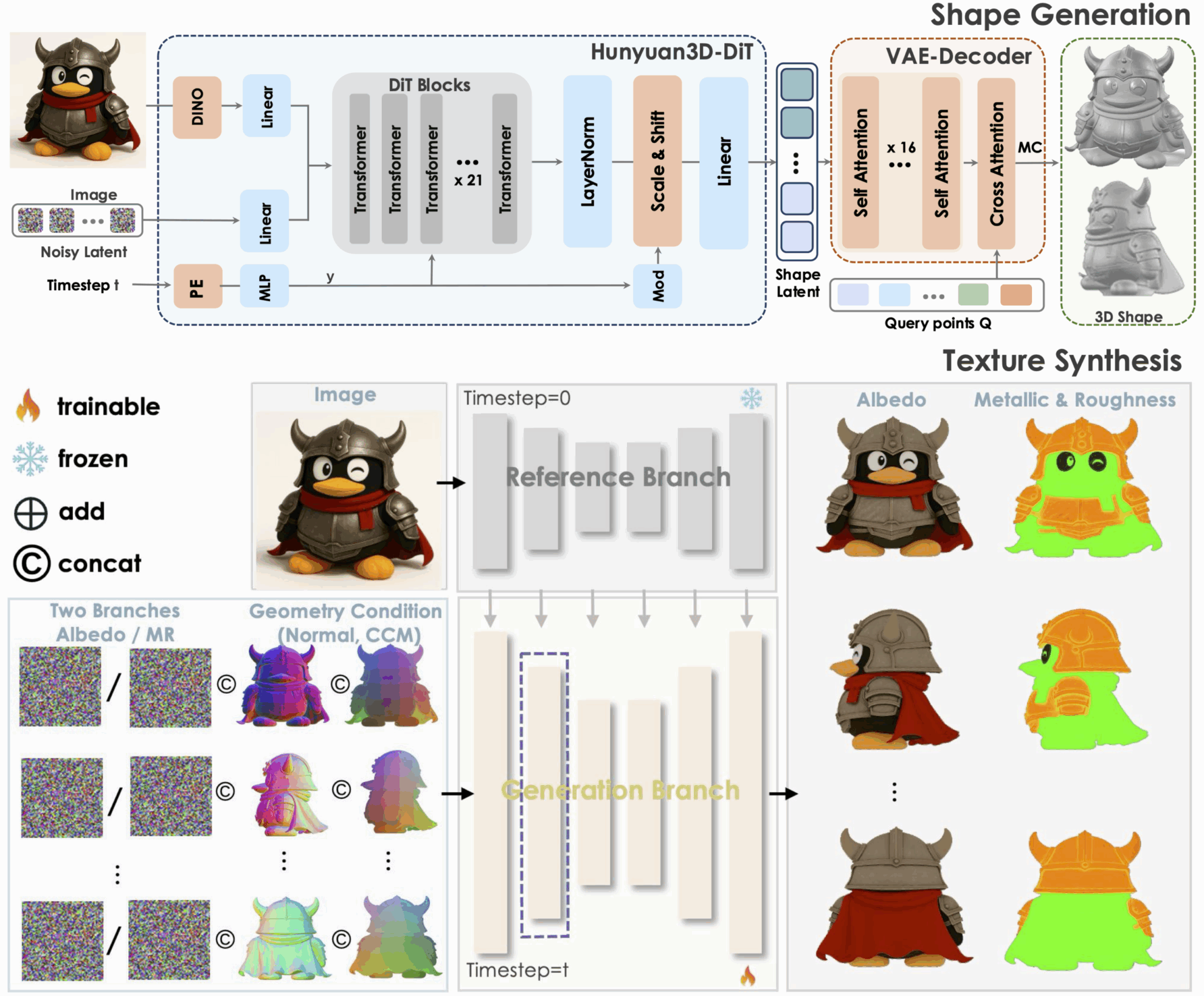
1. Hunyuan3D-2.1 : modèle génératif 3D prenant en charge les textures de rendu physique
Tencent Hunyuan3D-2.1 est un modèle de génération 3D open source de qualité industrielle et un système de création d'actifs 3D évolutif. Il favorise le développement de technologies de génération 3D de pointe grâce à deux innovations clés : un framework entièrement open source et une synthèse de textures de rendu physique. Parallèlement, il ouvre entièrement le traitement des données, les codes d'apprentissage et de raisonnement, etc., fournissant une base reproductible pour la recherche universitaire et réduisant les coûts de développement récurrents pour une mise en œuvre industrielle.
Exécutez en ligne :https://go.hyper.ai/0H91Z
2. Direct3D‑S2 : un framework pour le rendu 3D haute résolution
Direct3D-S2 est un framework de génération 3D haute résolution qui améliore considérablement l'efficacité de calcul du transformateur de diffusion et réduit significativement les coûts d'apprentissage grâce à une représentation volumique clairsemée et à un mécanisme innovant d'attention spatiale clairsemée. Ce framework surpasse les méthodes existantes en termes de qualité et d'efficacité de génération, offrant un support technique solide pour la création de contenu 3D haute résolution.
Exécutez en ligne :https://go.hyper.ai/67LQM

Tutoriel sur la génération audio
1. PlayDiffusion : modèle d'édition audio local open source
PlayDiffusion encode l'audio en séquences de jetons discrets, masque les parties à modifier et utilise un modèle de diffusion pour débruiter les zones masquées après la mise à jour du texte, afin d'obtenir un montage audio de haute qualité. Il préserve parfaitement le contexte, garantit la cohérence et le naturel de la parole et prend en charge une synthèse vocale efficace, offrant une cohérence temporelle et une évolutivité élevées.
Exécutez en ligne :https://go.hyper.ai/WTlI4
2. OuteTTS : moteur de génération vocale
OuteTTS est un projet open source de synthèse vocale. Son innovation principale réside dans l'utilisation de méthodes de modélisation du langage pur pour générer une parole de haute qualité sans recourir à des adaptateurs complexes ou à des modules externes dans les systèmes de synthèse vocale traditionnels. Ses principales fonctions incluent la synthèse vocale et le clonage vocal.
Exécutez en ligne :https://go.hyper.ai/eQVHL
💡Nous avons également créé un groupe d'échange de tutoriels Stable Diffusion. Bienvenue aux amis pour scanner le code QR et commenter [tutoriel SD] pour rejoindre le groupe pour discuter de divers problèmes techniques et partager les résultats de l'application ~

Recommandation de papier de cette semaine
1. GLM-4.1V-Pensée : Vers un raisonnement multimodal polyvalent avec un apprentissage par renforcement évolutif
Cet article présente GLM-4.1V-Thinking, un modèle de langage visuel (MLV) conçu pour améliorer la compréhension et le raisonnement multimodaux généraux. Nous proposons une méthode combinant l'apprentissage par renforcement et l'échantillonnage de programmes scolaires afin d'exploiter pleinement le potentiel du modèle, permettant ainsi d'atteindre des capacités complètes dans des tâches aussi diverses que la résolution de problèmes STEM, la compréhension de vidéos, la reconnaissance de contenu, la programmation, la résolution de coréférences, les agents basés sur des interfaces graphiques et la compréhension de documents longs. GLM-4.1V-9B-Thinking atteint des performances de pointe parmi les modèles open source de même taille, et affiche également des performances comparables, voire supérieures, à celles des modèles fermés tels que GPT-4o sur des tâches complexes comme la compréhension de documents longs et le raisonnement STEM.
Lien vers l'article :https://go.hyper.ai/5UuYG
2. Rapport technique Ovis-U1
Cet article présente Ovis-U1, un modèle unifié de 3 milliards de paramètres intégrant la compréhension multimodale, la conversion de texte en image et l'édition d'images. S'appuyant sur les fondements de la famille Ovis, Ovis-U1 combine un décodeur visuel diffus et un affineur de marquage bidirectionnel, ce qui le rend comparable aux modèles leaders tels que GPT-4o pour les tâches de génération d'images. Ovis-U1 obtient un score de 69,6 au benchmark académique multimodal OpenCompass, surpassant ainsi les modèles de pointe récents tels que Ristretto-3B et SAIL-VL-1.5-2B.
Lien vers l'article :https://go.hyper.ai/7Q8JV
3. BlenderFusion : montage visuel 3D et composition générative
Cet article propose BlenderFusion, un framework de synthèse visuelle générative qui synthétise de nouvelles scènes en recombinant objets, caméras et arrière-plans. Ce framework suit un pipeline calque-édition-synthèse : les entrées visuelles sont segmentées et converties en entités 3D modifiables ; éditées à l'aide de commandes 3D dans Blender ; et fusionnées en une scène cohérente grâce à un compositeur génératif. Les résultats expérimentaux montrent que BlenderFusion surpasse largement les méthodes précédentes pour les tâches complexes d'édition de scènes composites.
Lien vers l'article :https://go.hyper.ai/YoirX
4. SciArena : une plateforme d'évaluation ouverte pour les modèles fondamentaux dans la littérature scientifique
Cet article présente SciArena, une plateforme ouverte et collaborative d'évaluation de modèles de base pour des tâches de littérature scientifique. Contrairement aux benchmarks traditionnels de compréhension et de synthèse de la littérature scientifique, SciArena implique directement la communauté scientifique et adopte une méthode d'évaluation similaire à Chatbot Arena, où les modèles sont comparés par vote communautaire. Actuellement, la plateforme prend en charge 23 modèles de base open source et propriétaires et a recueilli plus de 13 000 votes de chercheurs reconnus dans de nombreux domaines scientifiques.
Lien vers l'article :https://go.hyper.ai/oPbpP
5. SPIRAL : Le jeu autonome sur des jeux à somme nulle encourage le raisonnement via l'apprentissage par renforcement multi-agents et multi-tours
Cet article présente SPIRAL, un cadre d'apprentissage autonome dans lequel les modèles apprennent en jouant à des jeux à somme nulle à plusieurs tours contre des versions d'eux-mêmes en constante amélioration, éliminant ainsi le besoin de supervision humaine. Pour permettre un apprentissage autonome à grande échelle, les chercheurs ont mis en œuvre un système d'apprentissage par renforcement multi-agents, multi-tours et entièrement en ligne, et ont proposé une estimation des avantages conditionnée par les rôles pour stabiliser l'apprentissage multi-agents. L'apprentissage autonome pour les jeux à somme nulle utilisant SPIRAL peut produire des capacités de raisonnement largement transférables.
Lien vers l'article :https://go.hyper.ai/n7J4m
Autres articles sur les frontières de l'IA :https://go.hyper.ai/iSYSZ
Interprétation des articles communautaires
Une équipe de recherche de Virginia Tech et de Meta AI a proposé un modèle unifié appelé UNIMATE, qui résout les principaux goulots d'étranglement de la conception actuelle des métamatériaux par l'IA grâce à une architecture de modèle innovante. Ce modèle permet également, pour la première fois, la modélisation unifiée et le traitement collaboratif des trois éléments fondamentaux de la conception des métamatériaux, à savoir la structure topologique tridimensionnelle, les conditions de densité et les propriétés mécaniques.
Voir le rapport complet :https://go.hyper.ai/1x8iJ
L'Université du Zhejiang, en collaboration avec des équipes de l'Université des sciences et technologies électroniques de Chine et d'autres institutions, a proposé le modèle HealthGPT. Grâce à un cadre innovant d'adaptation des connaissances hétérogènes, ils ont réussi à construire le premier modèle de langage visuel à grande échelle unifiant la compréhension et la génération multimodales médicales, ouvrant ainsi une nouvelle voie au développement de l'IA médicale. Les résultats associés ont été sélectionnés pour l'ICML 2025.
Voir le rapport complet :https://go.hyper.ai/F7W6a
Dans son discours intitulé « Construction et application d'un système informatique intelligent pour les protéines », le professeur associé Zhang Shugang, de l'École d'informatique de l'Université océanique de Chine, a présenté de manière systématique les avancées technologiques apportées par l'informatique intelligente, en mettant l'accent sur les défis traditionnels de la recherche sur les protéines et en mettant en avant les résultats de recherche de son équipe dans les domaines de l'annotation fonctionnelle, de l'identification des interactions et de l'optimisation de la conception. Cet article est une transcription du discours du professeur associé Zhang Shugang.
Voir le rapport complet :https://go.hyper.ai/rTgSi
Une équipe de l'Université technique de Munich (Allemagne) et de l'Université de Zurich (Suisse) a proposé une nouvelle méthode de génération d'images satellites utilisant la diffusion stable 3 (SD3), conditionnée par des indices climatiques géographiques, et a créé le jeu de données de télédétection le plus vaste et le plus complet à ce jour, EcoMapper. Ce jeu de données collecte plus de 2,9 millions de données d'images satellites RVB provenant de 104 424 sites à travers le monde grâce à Sentinel-2, couvrant 15 types de couverture terrestre et les relevés climatiques correspondants, jetant ainsi les bases de deux méthodes de génération d'images satellites utilisant un modèle SD3 optimisé.
Voir le rapport complet :https://go.hyper.ai/1zpeD
Science a publié un rapport exclusif indiquant que le financement du CASP par les National Institutes of Health (NIH) a été épuisé, et bien que l'Université de Californie à Davis (UC Davis), qui est responsable de la gestion des fonds du projet, ait fourni un soutien d'urgence, il sera également épuisé le 8 août, et le CASP est confronté à la crise de la suspension.
Voir le rapport complet :https://go.hyper.ai/3kTMU
Articles populaires de l'encyclopédie
1. KAN
2. Fonction sigmoïde
3. Boucle homme-machine HITL
4. L'amélioration de la récupération génère RAG
5. Ajustement précis du renforcement
Voici des centaines de termes liés à l'IA compilés pour vous aider à comprendre « l'intelligence artificielle » ici :
Date limite de juillet pour le sommet
11 juillet 7:59:59 POPL 2026
15 juillet 7:59:59 SODA 2026
18 juillet 7:59:59 SIGMOD 2026
19 juillet 7:59:59 ICSE 2026
Suivi unique des principales conférences universitaires sur l'IA :https://go.hyper.ai/event
Voici tout le contenu de la sélection de l’éditeur de cette semaine. Si vous avez des ressources que vous souhaitez inclure sur le site officiel hyper.ai, vous êtes également invités à laisser un message ou à soumettre un article pour nous le dire !
À la semaine prochaine !








