Command Palette
Search for a command to run...
Tutoriel Inclus : Nouvelle Avancée Dans Le Domaine De La Modélisation IRM En Milieu Médical ! HealthGPT Atteint Une Précision De 99,71 TP3T Pour La Compréhension Des Modalités Complexes d'IRM, Et Un Seul Modèle Peut Gérer Plusieurs Tâches De génération.

Le diagnostic et la recherche médicaux modernes dépendent fortement de l'interprétation et de la génération d'images médicales. De l'identification des lésions sur les radiographies à la conversion d'images de l'IRM au scanner, chaque étape impose des exigences strictes aux capacités de traitement multimodal des systèmes d'IA. Cependant, le développement actuel des modèles de langage visuel médical (MLVM) se heurte à deux obstacles : d'une part,La particularité des données médicales conduit à la rareté de données annotées de grande qualité et à grande échelle.La taille des ensembles de données d'imagerie médicale accessibles au public ne représente généralement qu'un dix-millième de celle des ensembles de données généraux, ce qui rend difficile la construction d'un modèle unifié à partir de zéro. D'autre part,La contradiction inhérente entre la compréhension et la génération de tâches est difficile à concilier——Les tâches de compréhension nécessitent une généralisation sémantique abstraite, tandis que les tâches de génération exigent une mémorisation précise des détails. L'apprentissage hybride traditionnel entraîne souvent une dégradation des performances, car on « perd une chose au profit d'une autre ».
Du point de vue de l'évolution technologique, les premiers LVLM médicaux tels que Med-Flamingo et LLaVA-Med se concentraient principalement sur les tâches de compréhension visuelle, réalisant une interprétation sémantique des images médicales grâce à l'alignement image-texte, mais manquaient de capacités de génération de « visualisation ». Les LVLM unifiés à usage général tels qu'Unified-IO 2 et Show-o, bien qu'ils disposent de fonctions de génération, sont peu performants dans les tâches professionnelles en raison d'une adaptation insuffisante des données médicales. Le prix Nobel de chimie 2024 a été décerné pour des avancées dans le domaine de la prédiction de la structure des protéines par l'IA, confirmant indirectement le potentiel de l'IA dans le domaine des sciences de la vie et faisant prendre conscience à la communauté universitaire que la création de LVLM médicaux dotés à la fois de capacités de compréhension et de génération est devenue la clé pour surmonter le goulot d'étranglement actuel des applications de l'IA médicale.
À cet égard,L'Université du Zhejiang et l'Université des sciences et technologies électroniques de Chine ont proposé conjointement le modèle HealthGPT, grâce à un cadre innovant d'adaptation des connaissances hétérogènes,A construit avec succès le premier modèle de langage visuel à grande échelle qui unifie la compréhension et la génération multimodales médicales.Cela a ouvert une nouvelle voie pour le développement de l’IA médicale, et les résultats associés ont été sélectionnés pour l’ICML 2025.
Adresse du document :
En réponse aux deux défis majeurs que sont la limitation des données médicales et le conflit de tâches, l'équipe de recherche a proposé une solution progressive à trois niveaux :
Tout d’abord, la technologie d’adaptation hétérogène de bas rang (H-LoRA) est conçue.Grâce au mécanisme de découplage des tâches, les connaissances de compréhension et de génération sont stockées dans des « plugins » indépendants, évitant ainsi le problème de conflit de l'optimisation conjointe traditionnelle ;
Deuxièmement, développer un cadre de perception visuelle hiérarchique (HVP),Utilisez la capacité d'extraction de fonctionnalités hiérarchiques de Vision Transformer pour fournir des fonctionnalités sémantiques abstraites pour comprendre les tâches et conserver des fonctionnalités visuelles détaillées pour les tâches de génération, réalisant ainsi une régulation des fonctionnalités « à la demande ».
Enfin, une stratégie d’apprentissage en trois étapes (TLS) est construite.De l'alignement multimodal à la fusion hétérogène de plug-ins, puis au réglage fin des instructions visuelles, le modèle est progressivement doté de capacités de traitement multimodal spécialisées.
Ensemble de données : Graphique de connaissances médicales multimodales de VL-Health
Pour soutenir la formation HealthGPT,L'équipe de recherche a construit le premier ensemble de données complet VL-Health pour la compréhension et la génération de données médicales multimodales.L'ensemble de données intègre 765 000 échantillons de tâches de compréhension et 783 000 échantillons de tâches de génération, couvrant 11 modalités médicales (y compris la tomodensitométrie, l'IRM, les rayons X, l'OCT, etc.) et plusieurs scénarios de maladies (des maladies pulmonaires aux tumeurs cérébrales).
Adresse du jeu de données :
https://hyper.ai/cn/datasets/40990
Pour ce qui est des tâches de compréhension, VL-Health intègre des jeux de données professionnels tels que VQA-RAD (questions de radiologie), SLAKE (amélioration des connaissances par annotation sémantique) et PathVQA (réponses aux questions de pathologie), et complète des données multimodales à grande échelle telles que LLaVA-Med et PubMedVision afin de garantir que le modèle maîtrise l'ensemble des fonctionnalités, de la reconnaissance d'images de base au raisonnement pathologique complexe. Les tâches de génération se concentrent principalement sur quatre axes principaux : conversion de modalité, super-résolution, génération de texte-image et reconstruction d'images.
* Conversion modale :Sur la base des données appariées CT-IRM de SynthRAD2023, la capacité de conversion intermodalité du modèle est formée ;
* Super résolution :Utilisation de l'IRM cérébrale haute résolution de l'ensemble de données IXI pour améliorer la précision de la reconstruction des détails de l'image ;
* Génération texte-image :Images et rapports radiographiques basés sur MIMIC-CXR, réalisant la génération de la description textuelle à l'image ;
* Reconstruction d'image :Adaptation de l'ensemble de données LLaVA-558k pour former les capacités d'encodage-décodage d'images du modèle.
Au cours de la phase de traitement des données, l’équipe a effectué un prétraitement standardisé des images médicales, notamment l’extraction de tranches, l’enregistrement d’images et l’amélioration des données.Et unifier tous les échantillons dans le format « commande-réponse »,Facilite l'instruction suite à la formation du modèle.
Architecture du modèle : conception de la chaîne complète, de la perception visuelle à la génération autorégressive
HealthGPT adopte une architecture en couches de « encodeur visuel-noyau LLM-plug-in H-LoRA » pour obtenir un traitement efficace des informations multimodales :
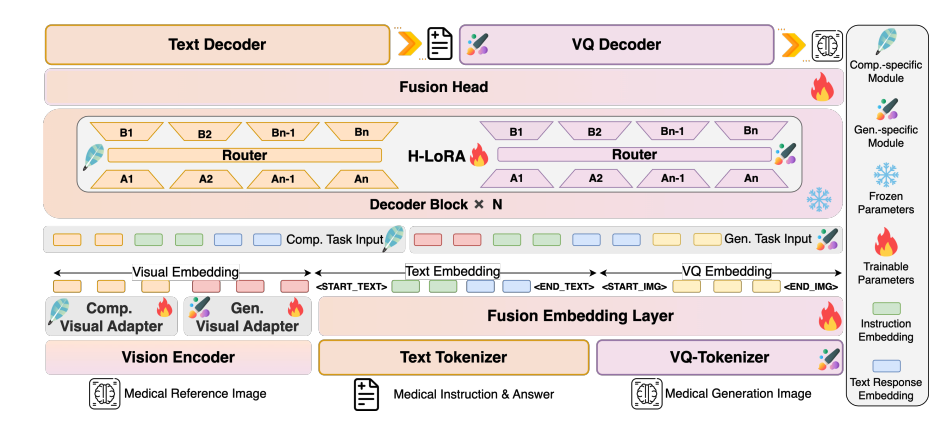
Diagramme d'architecture du modèle
Couche de codage visuel : extraction de caractéristiques hiérarchiques
CLIP-L/14 est utilisé comme encodeur visuel pour extraire des caractéristiques superficielles (2e couche) et profondes (2e à la dernière couche). Les caractéristiques superficielles sont converties en caractéristiques granulaires spécifiques via un adaptateur MLP à deux couches afin de préserver les détails de l'image ; les caractéristiques profondes sont transformées en caractéristiques granulaires abstraites par l'adaptateur afin de capturer les concepts sémantiques. Ce mécanisme d'extraction de caractéristiques à double voie fournit une représentation visuelle adaptative pour les tâches ultérieures de compréhension et de génération.
LLM Core : base de connaissances générales
Basés sur Phi-3-mini et Phi-4, deux modèles aux paramètres différents ont été construits : HealthGPT-M3 (volume des paramètres du modèle : 3,8 B) et HealthGPT-L14 (volume des paramètres du modèle : 14 B). Le cœur LLM est non seulement responsable de la compréhension et de la génération de texte, mais traite également uniformément les séquences de jetons visuels grâce à un mécanisme autorégressif : il génère des réponses textuelles pour les tâches de compréhension et des séquences d'index VQGAN pour les tâches de génération, puis reconstruit les images via le décodeur VQGAN.
Plugin H-LoRA : adaptateur spécifique à la mission
Insérez le plug-in H-LoRA dans chaque bloc Transformer de LLM, comprenant deux types de sous-modules : compréhension et génération. Chaque sous-module contient plusieurs experts LoRA, et l'activation sélective des connaissances est obtenue par routage dynamique des types de tâches et des états cachés des entrées. Le plug-in est combiné aux pondérations figées de LLM pour former un mode de raisonnement hybride « connaissances générales + expertise des tâches ».
Conclusion expérimentale : HealthGPT est significativement en avance dans les tâches de compréhension et de génération visuelles médicales
Comprendre la mission : être leader en matière de capacités professionnelles
Dans la tâche de compréhension visuelle médicale, HealthGPT surpasse largement les modèles existants. En comparant HealthGPT à d'autres modèles médicaux généraux et spécifiques (tels que Med-Flamingo, LLA-VA-Med, HuatuoGPT-Vision, BLIP-2, etc.), les résultats montrent queHealthGPT obtient de bons résultats dans les tâches de compréhension visuelle médicale, surpassant considérablement les autres modèles médicaux spécifiques et généraux.
Sur l'ensemble de données VQA-RAD, HealthGPT-L14 a atteint une précision de 77,7%, soit une amélioration de 29,1% par rapport à LLaVA-Med ; au test de référence OmniMedVQA, son score moyen était de 74,4%, et il a obtenu les meilleurs résultats dans 6 des 7 sous-tâches, dont la TDM, l'IRM et l'OCT. En particulier, sa précision dans la compréhension des modalités d'IRM complexes a atteint 99,7%, démontrant sa compréhension approfondie des images médicales très complexes.
Tâches de génération : avancées dans la conversion de modalité et la super-résolution
L'expérience de la tâche générative montre que HealthGPT est performant dans la conversion et l'amélioration des images médicales. Dans la tâche de conversion CT-IRM, l'indice SSIM de HealthGPT-M3 a atteint 79,38 (Brain CT2MRI), soit 11,6% de plus que la méthode traditionnelle Pix2Pix. La précision de conversion dans des zones complexes comme le bassin est également excellente ; dans la tâche de super-résolution, son SSIM a atteint 78,19 et son PSNR 32,76, surpassant SRGAN, DASR et d'autres modèles dédiés en termes de restitution des détails, notamment pour la reconstruction fine des structures cérébrales.
Il convient de noter queHealthGPT peut gérer plusieurs tâches de génération dans un seul modèle.Les méthodes traditionnelles nécessitent la formation de modèles indépendants pour chaque sous-tâche, ce qui met en évidence l’avantage d’efficacité d’un cadre unifié.
Validation de la méthode : la valeur du H-LoRA et la stratégie en trois phases
Les expériences d'ablation ont confirmé la nécessité de la technologie de base : après avoir supprimé H-LoRA, les performances moyennes des tâches de compréhension et de génération ont diminué de 18,7% ; lorsque l'entraînement hybride a été adopté au lieu de la stratégie en trois étapes, le conflit de tâches a provoqué une dégradation des performances de 23,4%.
La comparaison entre H-LoRA et MoELoRA montre qu'avec 4 experts, le temps d'apprentissage H-LoRA n'est que de 671 TP3T par rapport à MoELoRA, mais les performances sont améliorées de 5,21 TP3T, démontrant ainsi son double avantage en termes d'efficacité de calcul et de performance des tâches. Le rôle de la perception visuelle multicouche a également été vérifié.La vitesse de convergence est améliorée de 40% lorsque des fonctionnalités abstraites sont utilisées dans la tâche de compréhension, et la fidélité de l'image est améliorée de 25% lorsque des fonctionnalités spécifiques sont utilisées dans la tâche de génération.
Potentiel d'application clinique : un pont entre la recherche et la pratique
Dans l’expérience d’évaluation humaine, cinq cliniciens ont évalué à l’aveugle les réponses à 1 000 questions ouvertes.La proportion de réponses HealthGPT-L14 sélectionnées comme « meilleures réponses » a atteint 65,7%,Dépassant de loin LLaVA-Med (34.08%) et HuatuoGPT-Vision (21.94%).
à l'heure actuelle,HyperAI Hyper.aiLe tutoriel « HealthGPT : AI Medical Assistant » est désormais disponible dans la section tutoriel.Téléchargez simplement des images médicales pour démarrer une consultation comparable à celle d'un médecin. Venez vivre cette expérience !
Lien du tutoriel :
Essai de démonstration
1. Après avoir accédé à la page d'accueil de hyper.ai, sélectionnez la page « Tutoriels », sélectionnez « HealthGPT : AI Medical Assistant » et cliquez sur « Exécuter ce tutoriel en ligne ».

2. Une fois la page affichée, cliquez sur « Cloner » dans le coin supérieur droit pour cloner le didacticiel dans votre propre conteneur.
3. Sélectionnez les images « NVIDIA RTX A6000 » et « PyTorch ». La plateforme OpenBayes propose quatre modes de facturation : « à l'utilisation » ou « quotidien/hebdomadaire/mensuel » selon vos besoins. Cliquez sur « Continuer ». Les nouveaux utilisateurs peuvent s'inscrire via le lien d'invitation ci-dessous pour obtenir 4 heures de RTX 4090 et 5 heures de temps processeur gratuit !
Lien d'invitation exclusif HyperAI (copier et ouvrir dans le navigateur) :
https://openbayes.com/console/signup?r=Ada0322_NR0n
4. Attendez que les ressources soient allouées. Le premier processus de clonage prend environ 2 minutes. Lorsque le statut passe à « En cours d'exécution », cliquez sur la flèche de saut à côté de « Adresse API » pour accéder à la page de démonstration. Étant donné que le modèle est volumineux, il faut environ 3 minutes pour afficher l'interface WebUI, sinon « Bad Gateway » s'affichera. Veuillez noter que les utilisateurs doivent effectuer l'authentification par nom réel avant d'utiliser la fonction d'accès à l'adresse API.
Démonstration d'effet
Téléchargez une image, saisissez la question dans le champ « Question », sélectionnez le modèle dans le champ « Choisir le modèle » et cliquez sur « Traiter » pour y répondre en temps réel. Ce projet propose deux modèles :
* HealthGPT-M3 : une version plus petite optimisée pour la vitesse et une utilisation réduite de la mémoire.
* HealthGPT-L14 : une version plus grande conçue pour des performances supérieures et des tâches plus complexes.
L'exemple de réponse est présenté ci-dessous :
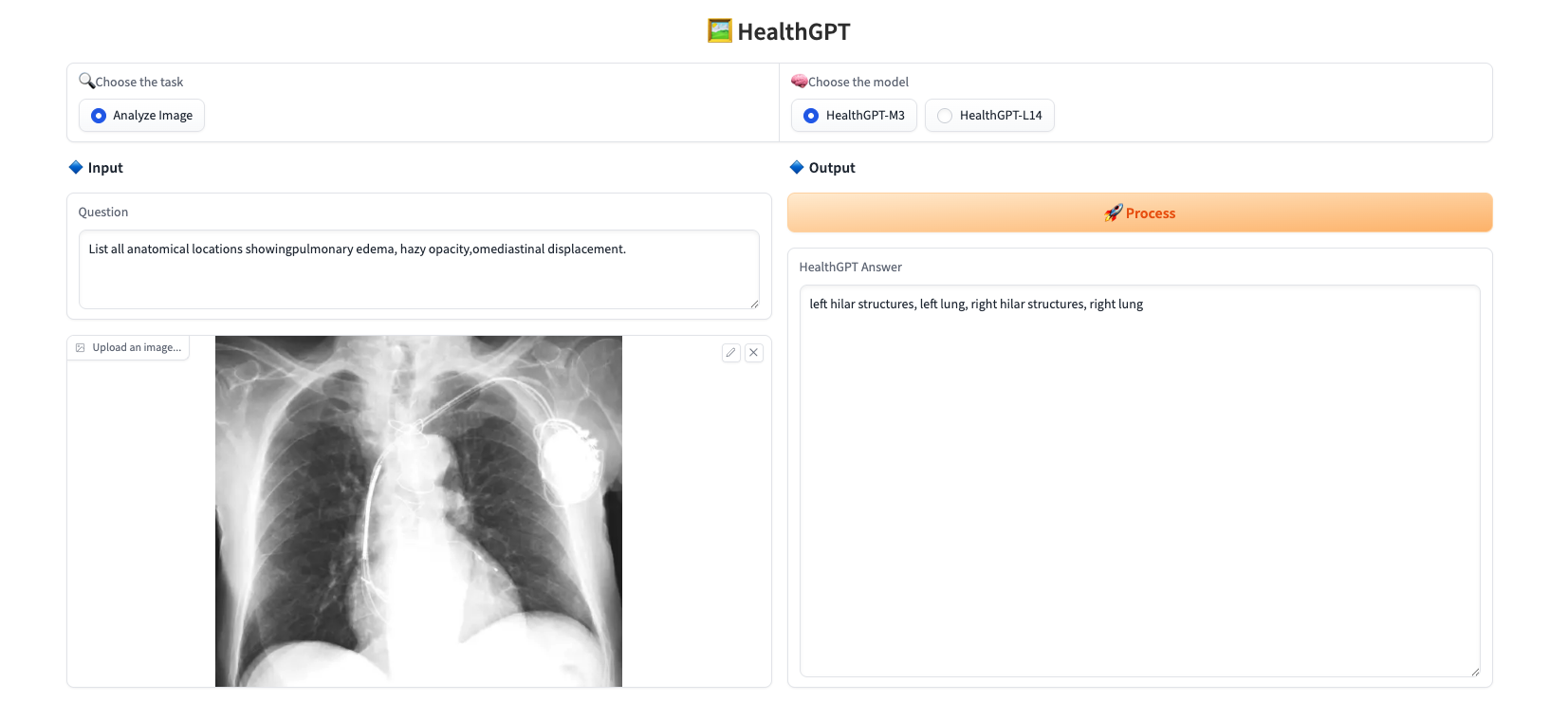
Le tutoriel ci-dessus est recommandé par HyperAI. Les lecteurs intéressés sont invités à le découvrir ⬇️
Lien du tutoriel :








