Command Palette
Search for a command to run...
Plus De 58 000 Étoiles ! RAGFlow Intègre Qwen3 Embedding Pour Traiter Facilement Des Données De Formats Complexes ; Webclick Ouvre Une Nouvelle Dimension De La Compréhension Des Pages web.
Le framework RAG (Retrieval-Augmented Generation) proposé par Meta en 2020 améliore efficacement la précision et la fiabilité des résultats LLM. La technologie a évolué, passant d'une simple récupération et génération initiale à une forme avancée intégrant des fonctionnalités d'agent telles que le raisonnement multi-tours, l'utilisation d'outils et la mémoire contextuelle. La plupart des moteurs RAG actuels sont relativement simples dans l'analyse de documents et s'appuient sur des intergiciels de récupération standard, ce qui entraîne une faible précision de récupération.
Sur cette base, InfiniFlow a publié RAGFlow en open source, un moteur RAG open source basé sur une compréhension approfondie des documents. Non seulement il résout les difficultés mentionnées ci-dessus, mais il fournit également un flux de travail RAG pré-intégré. Il suffit aux utilisateurs de suivre le processus étape par étape pour créer rapidement un système RAG.Après l'intégration avec Qwen3 Embedding, il est possible de créer une base de connaissances locale, un système intelligent de réponses aux questions et un agent en un seul endroit.
Actuellement, le site officiel d'HyperAI a lancé le tutoriel « Création d'un système RAG : pratique basée sur l'intégration Qwen3 », venez l'essayer~
Construire un système RAG : pratique basée sur l'intégration Qwen3
Utilisation en ligne :https://go.hyper.ai/FFA7f
Du 23 au 27 juin, le site officiel de hyper.ai est mis à jour :
* Ensembles de données publiques de haute qualité : 10
* Sélection de tutoriels de haute qualité : 6
* Articles recommandés cette semaine : 5
* Interprétation d'articles communautaires : 3 articles
* Entrées d'encyclopédie populaire : 5
* Principales conférences avec date limite en juillet : 5
Visitez le site officiel :hyper.ai
Ensembles de données publiques sélectionnés
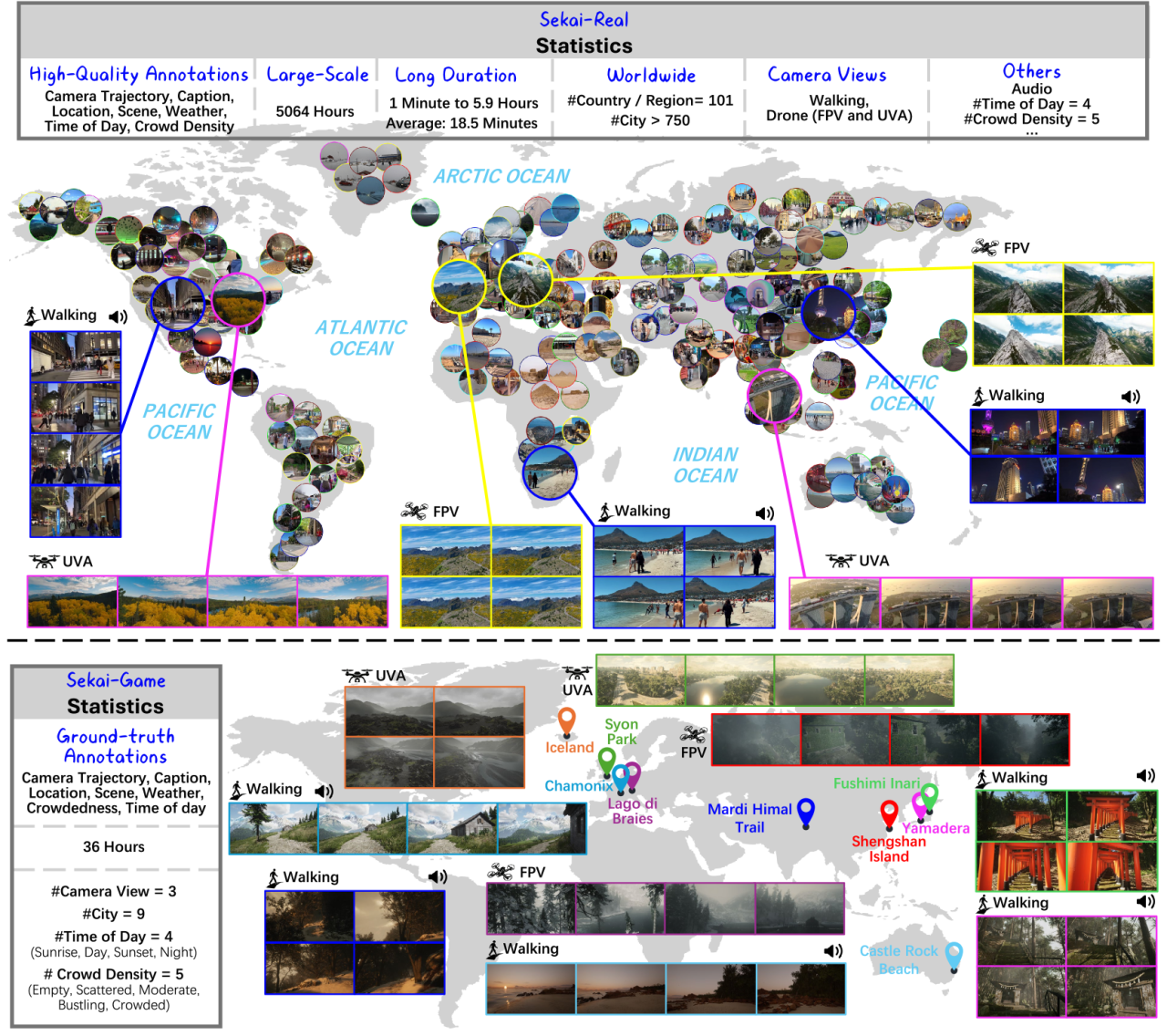
1. Ensemble de données vidéo Sekai World
Sekai est un ensemble de données vidéo mondiales de haute qualité, en perspective à la première personne, conçu pour inspirer des applications précieuses dans les domaines de la génération vidéo et de l'exploration du monde. Cet ensemble de données se concentre sur l'exploration égocentrique du monde et se compose de deux parties : Sekai-Real et Sekai-Game. Il contient plus de 5 000 heures de vidéos en perspective, prises à pied ou par drone, provenant de plus de 100 pays et régions et de 750 villes.
Utilisation directe :https://go.hyper.ai/YyBKB
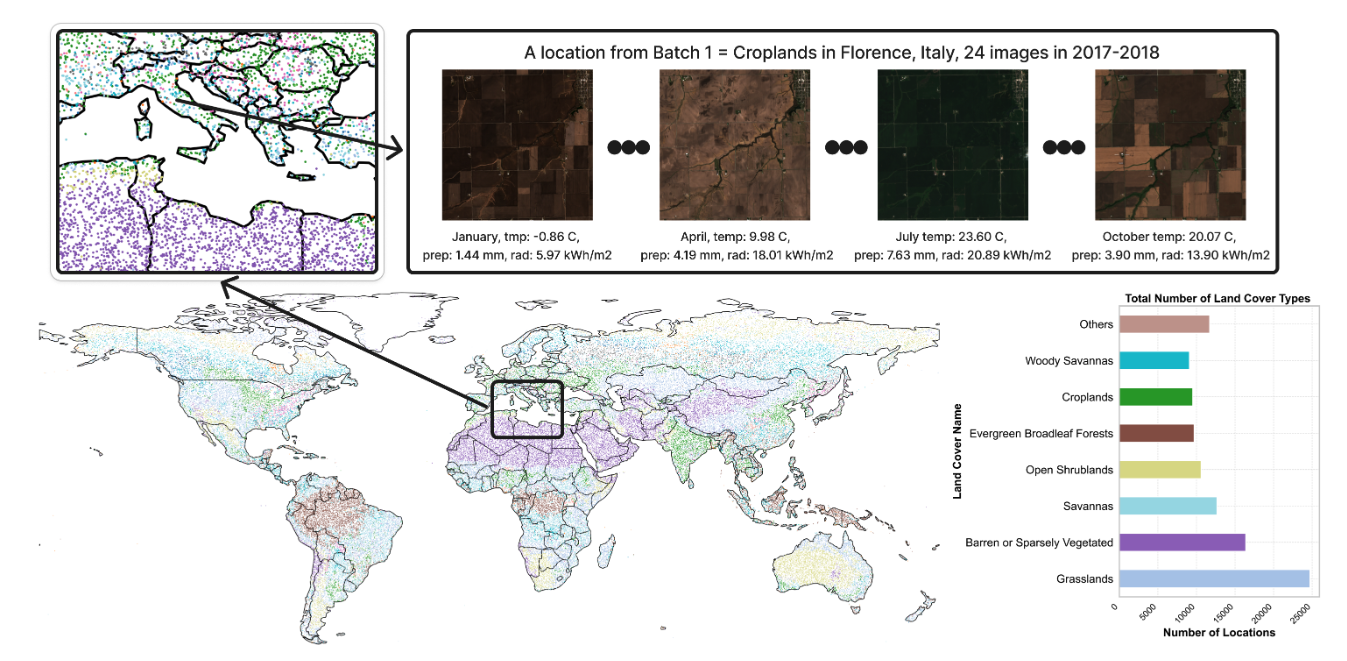
2. Ensemble de données d'imagerie satellite Ecomapper
L'ensemble de données contient plus de 2,9 millions d'images satellite, dont des images RVB et des données multispectrales spécifiques. Ces images proviennent de la mission satellite Copernicus Sentinel et couvrent divers types de couverture terrestre et de multiples points temporels. L'ensemble d'entraînement comprend 98 930 emplacements géographiques différents et l'ensemble de test 5 494 emplacements. Chaque horodatage de chaque image est accompagné de métadonnées météorologiques pertinentes, telles que la température, le rayonnement solaire et les précipitations.
Utilisation directe :https://go.hyper.ai/1u8s6
3. Ensemble de données de conduite autonome NuScenes
NuScenes est un ensemble de données publiques pour la conduite autonome qui contient environ 1,4 million d'images de caméra, 390 000 images de balayage lidar, 1,4 million d'images de balayage radar et 1,4 million de boîtes englobantes d'objets dans 40 000 images clés de Boston et de Singapour.
Utilisation directe :https://go.hyper.ai/rgw1k
4. Ensemble de données à cellule unique Tahoe-100M
Tahoe‑100M est le plus grand ensemble de données monocellulaires au monde. Il a été conçu pour fournir une base de données expérimentales réaliste et structurée aux grands modèles de langage (LLM) dotés de capacités de compréhension des interventions. Cet ensemble de données contient plus de 100 millions de cellules, couvre plus de 60 000 expériences d'intervention moléculaire et cartographie les réponses de 50 modèles de cancer à plus de 1 100 traitements médicamenteux.
Utilisation directe :https://go.hyper.ai/Hfzva
5. Ensemble de données de référence pour la compréhension des pages Web WebClick
WebClick est un ensemble de données de référence de haute qualité pour la compréhension des pages web. Il permet d'évaluer la capacité des modèles et agents multimodaux à comprendre les interfaces web, à interpréter les commandes utilisateur et à effectuer des actions précises dans les environnements numériques. Cet ensemble de données contient 1 639 captures d'écran de pages web en anglais provenant de plus de 100 sites web, accompagnées de commandes en langage naturel annotées avec précision et de cibles de clic au pixel près.
Utilisation directe :https://go.hyper.ai/ezz46
6. Banc de recherche profonde Banc de recherche profonde
DeepResearch Bench est un ensemble de données de référence pour agents de recherche approfondie qui vise à révéler la véritable répartition des besoins en recherche approfondie humaine dans différents domaines. Cet ensemble de données contient 100 tâches de recherche de niveau doctoral, chacune soigneusement élaborée par des experts de 22 domaines différents.
Utilisation directe :https://go.hyper.ai/yVHfH
7. Ensemble de données de texte d'image SA-Text
SA-Text est un jeu de données de référence à grande échelle, composé d'images de scènes de haute qualité, conçu pour les tâches de restauration d'images textuelles. Ce jeu de données contient 105 330 images de scènes haute résolution, accompagnées d'annotations textuelles au niveau des polygones, qui décrivent précisément l'emplacement et la forme du texte dans l'image, permettant ainsi au modèle de mieux comprendre l'emplacement et la structure du texte.
Utilisation directe :https://go.hyper.ai/ICYIY
8. Ensemble de données de référence pour la reconnaissance de texte OCRBench
L'ensemble de données contient 1 000 paires de questions-réponses sélectionnées et corrigées manuellement à partir de cinq tâches représentatives liées au texte : reconnaissance de texte, centre du texte de la scène, orientation du document, informations clés et expressions mathématiques manuscrites.
Utilisation directe :https://go.hyper.ai/ZcKoD
9. Ensemble de données de séquençage d'ARN unicellulaire Parse-PBMC
Parse-PBMC est un ensemble de données de séquençage d'ARN unicellulaire open source qui analyse 10 millions de cellules provenant de 1 152 échantillons dans une seule expérience et est principalement utilisé pour étudier les caractéristiques d'expression génétique des cellules mononucléaires du sang périphérique humain dans différentes conditions.
Utilisation directe :https://go.hyper.ai/CwOMc
10. Ensemble de données d'édition d'instances vidéo VIRESET
VIRESET vise à fournir un support d'annotation précis pour des tâches telles que le redessin d'instances vidéo et la segmentation temporelle. L'ensemble de données contient deux contenus : l'annotation de masque améliorée SA-V et 86 000 clips vidéo.
Utilisation directe :https://go.hyper.ai/5hnGF
Tutoriels publics sélectionnés
Cette semaine, nous avons compilé 2 types de tutoriels publics de haute qualité :
*Tutoriels de déploiement de grands modèles : 3
* Tutoriels de génération de vidéos : 3
Déploiement de grands modèlesTutoriel
1. Construire un système RAG : pratique basée sur l'intégration Qwen3
RAGFlow est un moteur RAG (Retrieval Augmented Generation) open source basé sur la compréhension approfondie des documents. Intégré à LLM, il offre de véritables capacités de question-réponse, appuyées par des références fiables issues de données aux formats complexes variés.
Exécutez en ligne :https://go.hyper.ai/FFA7f
2. Déployer QwenLong-L1-32B à l'aide de vLLM+Open WebUI
QwenLong-L1-32B est le premier grand modèle de raisonnement sur texte long basé sur l'apprentissage par renforcement. Il vise à résoudre les problèmes de mémoire insuffisante et de confusion logique rencontrés par les grands modèles traditionnels lors du traitement de contextes ultra-longs (par exemple, 120 000 jetons). Il s'affranchit des limitations contextuelles des grands modèles traditionnels et offre une solution économique et performante pour les scénarios de haute précision tels que la finance et le droit.
Exécutez en ligne :https://go.hyper.ai/f73C2
3. Déploiement vLLM+Open WebUI Magistral-Small-2506
Magistral-Small-2506 est basé sur Mistral Small 3.1 (2503) et offre des capacités de raisonnement améliorées, le suivi SFT via Magistral Medium et l'apprentissage par renforcement. Ce modèle de raisonnement compact et efficace, doté de 24 B paramètres, est capable de suivre de longues chaînes de raisonnement avant de fournir des réponses, afin de mieux comprendre et traiter des problèmes complexes, améliorant ainsi la précision et la rationalité des réponses.
Exécutez en ligne :https://go.hyper.ai/yLeoh
Tutoriel de génération de vidéos
1. MAGI-1 : le premier modèle de génération vidéo autorégressif à grande échelle au monde
Magi-1 est le premier modèle de génération vidéo autorégressif à grande échelle au monde. Il génère des vidéos par prédiction autorégressive d'une série de blocs vidéo, définis comme des segments de longueur fixe d'images consécutives. Il atteint d'excellentes performances sur les tâches de conversion d'images en vidéos conditionnées par des instructions textuelles, offrant une cohérence temporelle et une évolutivité élevées.
Exécutez en ligne :https://go.hyper.ai/NZ6cc
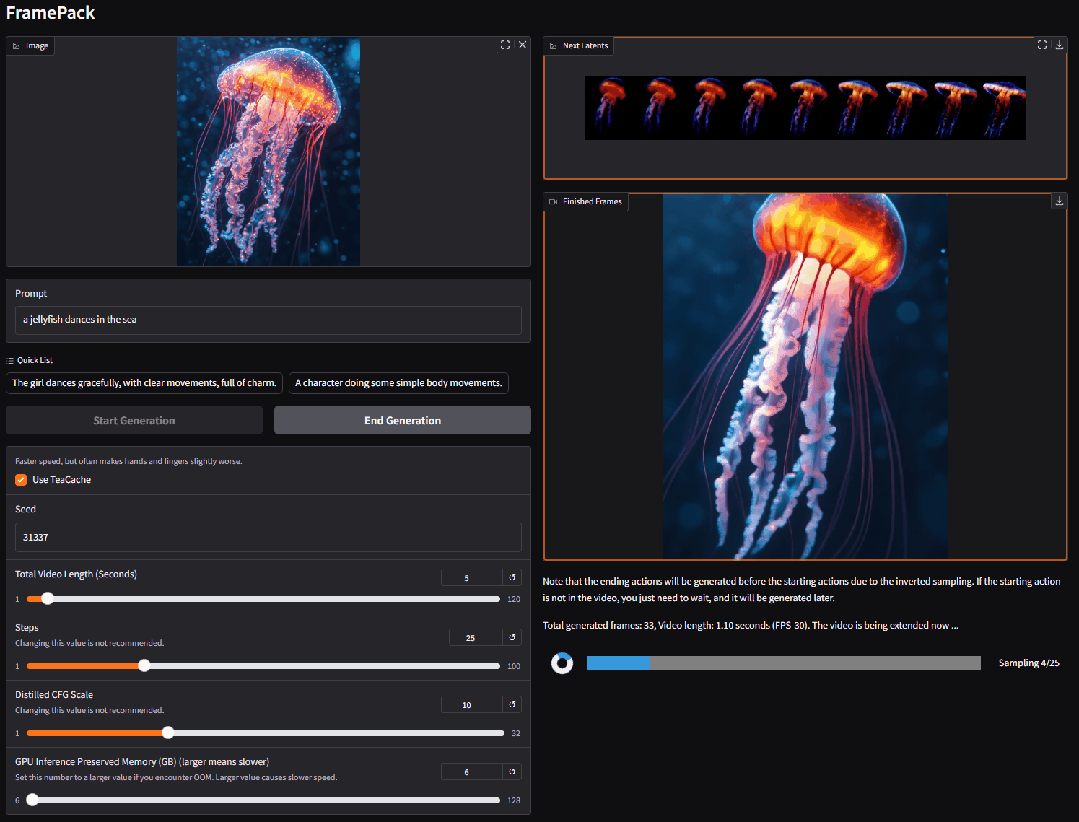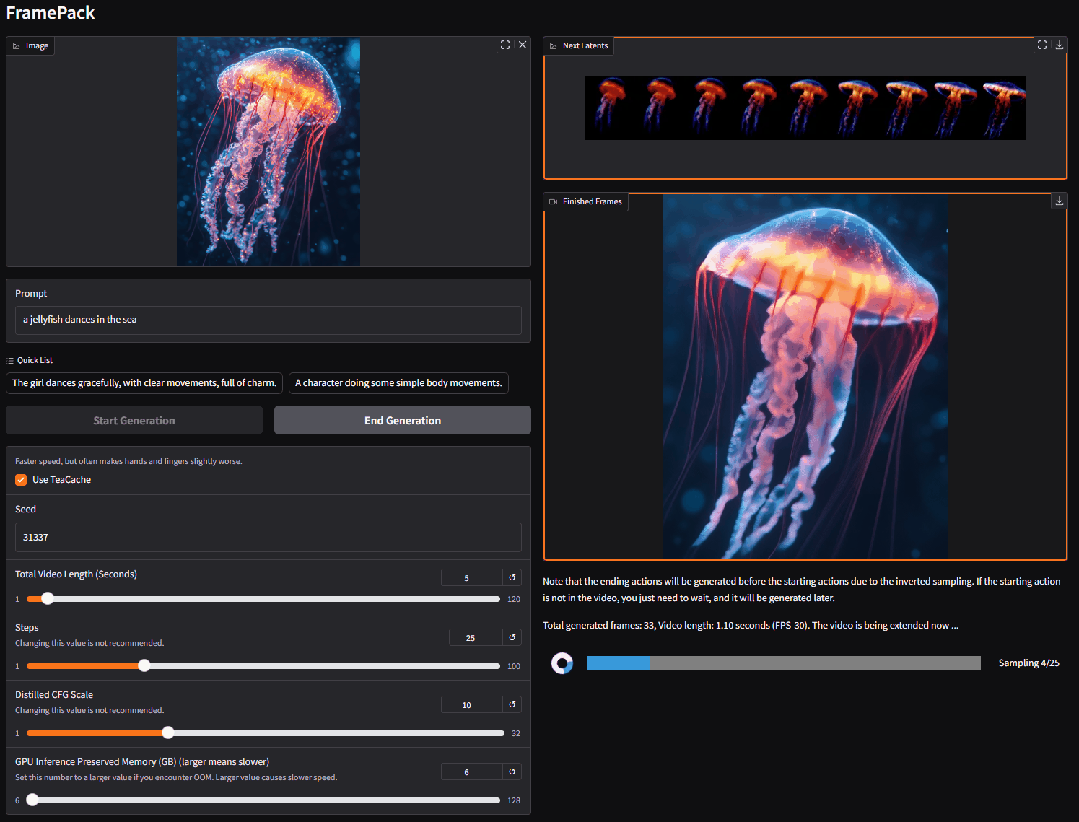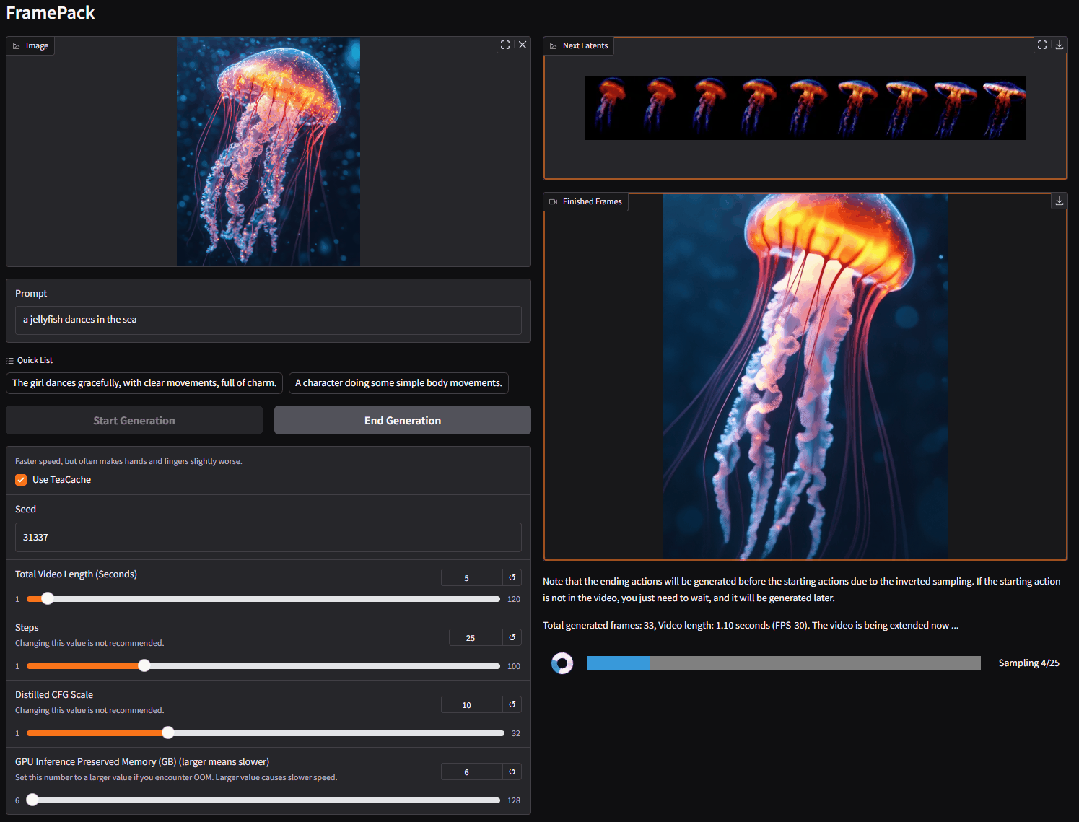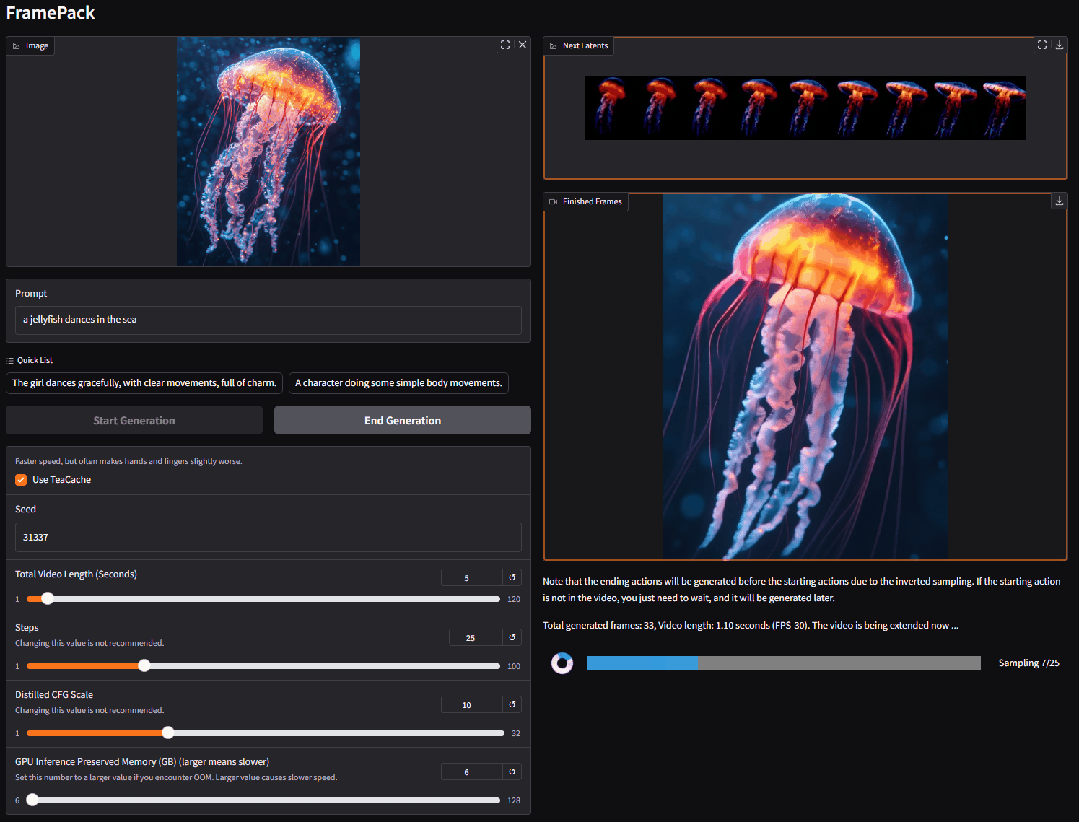
2. FramePackLoop : outil open source de génération de vidéos en boucle transparente
FramePackLoop est un outil automatisé de traitement de séquences d'images et de génération de boucles conçu pour simplifier les workflows de production vidéo. L'outil utilise une architecture modulaire pour réaliser le compactage des séquences d'images, l'alignement temporel et la synthèse de boucles transparentes. Plus précisément, il combine l'estimation du flux optique avec la modélisation temporelle basée sur l'attention pour maintenir la cohérence du mouvement inter-images.
Exécutez en ligne :https://go.hyper.ai/WIRoM
3. VIRES : Redessin vidéo à double guidage esquisse-texte
VIRES est une méthode de redessin d'instances vidéo combinant croquis et guidage textuel, prenant en charge de multiples opérations d'édition telles que le redessin, le remplacement, la génération et la suppression de sujets vidéo. Cette méthode utilise les connaissances préalables des modèles vidéo générés par le texte pour garantir la cohérence temporelle. Les résultats expérimentaux montrent que VIRES est performant sur de nombreux aspects, notamment la qualité vidéo, la cohérence temporelle, l'alignement conditionnel et les évaluations des utilisateurs.
Exécutez en ligne :https://go.hyper.ai/GeZxZ

💡Nous avons également créé un groupe d'échange de tutoriels Stable Diffusion. Bienvenue aux amis pour scanner le code QR et commenter [tutoriel SD] pour rejoindre le groupe pour discuter de divers problèmes techniques et partager les résultats de l'application ~

Recommandation de papier de cette semaine
1. LLM par glisser-déposer : invites à pondération zéro-shot
Cet article présente les modèles de langage volumineux par glisser-déposer (DnD), un générateur de paramètres basé sur des invites qui élimine le besoin d'apprentissage par tâche en mappant directement un petit nombre d'invites de tâches non étiquetées aux mises à jour de pondération LoRA. Un encodeur de texte léger affine chaque lot d'invites en intégrations conditionnelles, qui sont ensuite converties en un ensemble complet de matrices LoRA par un décodeur hyperconvolutionnel en cascade.
Lien vers l'article :https://go.hyper.ai/hAO8y
2. Lumière des normales : représentation unifiée des caractéristiques pour la stéréophotométrie universelle
Dans cet article, nous proposons une nouvelle méthode de stéréophotométrie universelle (UniPS) pour résoudre le problème de la récupération de normales de surface de haute précision dans des conditions d'éclairage arbitraires. Les résultats expérimentaux montrent que LINO-UniPS surpasse les méthodes de stéréophotométrie universelle de pointe existantes sur des benchmarks publics et présente de fortes capacités de généralisation pour s'adapter à différentes propriétés de matériaux et scénarios d'éclairage.
Lien vers l'article :https://go.hyper.ai/oTFMo
3. Le découpage guidé par la vision est tout ce dont vous avez besoin : améliorer le RAG grâce à la compréhension multimodale des documents
Cet article propose une nouvelle méthode de fragmentation de documents multimodaux qui exploite les grands modèles multimodaux (LMM) pour traiter les documents PDF par lots tout en préservant la cohérence sémantique et l'intégrité structurelle. Cette méthode traite les documents par lots de pages configurables et préserve les informations contextuelles d'un lot à l'autre, permettant ainsi un traitement précis des tableaux, des éléments visuels intégrés et du contenu procédural sur plusieurs pages.
Lien vers l'article :https://go.hyper.ai/IZA15
4. OmniGen2 : de l'exploration à la génération multimodale avancée
Cet article présente OmniGen2, un modèle génératif polyvalent et open source qui vise à fournir une solution unifiée pour de multiples tâches génératives, notamment la génération de texte en image, l'édition d'images et la génération de contexte. Contrairement à OmniGen v1, OmniGen2 conçoit deux chemins de décodage indépendants pour les modalités texte et image, utilisant des paramètres non partagés et des tokenizers d'images distincts. Cette conception permet à OmniGen2 de s'appuyer sur des modèles de compréhension multimodale existants sans réadapter les entrées VAE, préservant ainsi les capacités de génération de texte d'origine.
Lien vers l'article :https://go.hyper.ai/iCFzp
5. PAROAttention : réorganisation tenant compte des modèles pour une attention quantifiée et éparse efficace dans les modèles de génération visuelle
Cet article propose une nouvelle technique de réorganisation des balises sensible aux motifs (PARO) qui unifie divers motifs d'attention en blocs adaptés au matériel. Cette unification simplifie et améliore considérablement les effets de la parcimonie et de la quantification. Grâce à cette méthode, PARO Attention permet de générer des vidéos et des images avec une perte de métriques quasi nulle et d'obtenir des résultats quasiment identiques à ceux de la ligne de base de précision maximale, avec une densité et une largeur de bits considérablement réduites, permettant une accélération de la latence de bout en bout de 1,9 à 2,7 fois supérieure.
Lien vers le document:https://go.hyper.ai/sScNH
Autres articles sur les frontières de l'IA :https://go.hyper.ai/iSYSZ
Interprétation des articles communautaires
Google DeepMind a lancé le modèle AlphaGenome, capable de prédire des milliers de propriétés moléculaires liées à leur activité régulatrice, et d'évaluer l'impact des variations ou mutations génétiques en comparant les résultats de prédiction des séquences variantes et non variantes. L'une des avancées majeures d'AlphaGenome est la capacité à prédire les jonctions d'épissage directement à partir des séquences et à les utiliser pour prédire l'effet des variants.
Voir le rapport complet :https://go.hyper.ai/o8E1F
Le professeur Li Dong, directeur du Centre des sciences des données médicales de l'hôpital Tsinghua Chang Gung, a donné une présentation spéciale sur « Comment utiliser les données médicales pour mener des recherches innovantes à l'ère des soins de santé intelligents » lors de la conférence Zhiyuan de Pékin 2025, présentant les innovations apportées par les grands modèles à l'ère des soins de santé intelligents.
Voir le rapport complet :https://go.hyper.ai/rAabv
L'organisme de recherche à but non lucratif Arc Institute, en collaboration avec des équipes de recherche de l'UC Berkeley, de Stanford et d'autres universités, a lancé le modèle cellulaire virtuel STATE, capable de prédire la réponse des cellules souches, des cellules cancéreuses et des cellules immunitaires aux médicaments, aux cytokines ou aux interventions génétiques. Les résultats expérimentaux montrent que State surpasse largement les méthodes classiques actuelles pour prédire les modifications du transcriptome après intervention.
Voir le rapport complet :https://go.hyper.ai/B3Rc6
Articles populaires de l'encyclopédie
1. DALL-E
2. Fusion de tri réciproque RRF
3. Front de Pareto
4. Compréhension linguistique multitâche à grande échelle (MMLU)
5. Apprentissage contrastif
Voici des centaines de termes liés à l'IA compilés pour vous aider à comprendre « l'intelligence artificielle » ici :
Date limite de juillet pour le sommet
2 juillet 7:59:59 VLDB 2026
11 juillet 7:59:59 POPL 2026
15 juillet 7:59:59 SODA 2026
18 juillet 7:59:59 SIGMOD 2026
19 juillet 7:59:59 ICSE 2026
Suivi unique des principales conférences universitaires sur l'IA :https://go.hyper.ai/event
Voici tout le contenu de la sélection de l’éditeur de cette semaine. Si vous avez des ressources que vous souhaitez inclure sur le site officiel hyper.ai, vous êtes également invités à laisser un message ou à soumettre un article pour nous le dire !
À la semaine prochaine !








