Command Palette
Search for a command to run...
Dites Adieu Aux Problèmes De Code ! Seed-Coder Optimise La Programmation ; Mixture-of-Thoughts Couvre Les Données multi-domaines Pour Un Raisonnement De Haute qualité.

Alors que la concurrence pour les grands modèles s'intensifie et que la tendance à la « technologie de volume et à l'échelle » se poursuit, améliorer l'utilisabilité et la performance des modèles devient un enjeu crucial. Parmi ces enjeux, la maîtrise du codage est un indicateur important pour mesurer l'utilisabilité et la performance des grands modèles. Sur cette base, l'équipe Seed de ByteDance a publié un modèle de langage open source léger mais performant : Seed-Coder-8B-Instruct.
Ce modèle est une version affinée de la série Seed-Coder, construite sur l'architecture Llama 3, avec 8,2 B paramètres et prend en charge le traitement de contexte avec une longueur maximale de 32 K jetons.Seed-Coder-8B-Instruct Avec une intervention humaine minimale, LLM peut gérer efficacement et de manière autonome les données d'entraînement du code, améliorant ainsi considérablement les capacités de codage. En générant et en analysant automatiquement des données d'entraînement de haute qualité, la capacité de génération de code du modèle peut être considérablement améliorée.
Actuellement, HyperAI Super Neural est en ligne 「vLLM+Open WebUI Déploiement Seed-Coder-8B-Instruct", venez l'essayer~
Utilisation en ligne :https://go.hyper.ai/BnO32
Rendez-vous en direct
La conférence mondiale WWDC25 d'Apple se tiendra le 10 juin à 1 h du matin, heure de Pékin. HyperAI Super Neural Video diffusera la keynote en temps réel. Pour ne rien manquer, prenez rendez-vous dès maintenant !

Du 3 au 6 juin, le site officiel hyper.ai est mis à jour :
* Ensembles de données publiques de haute qualité : 10
* Tutoriels de haute qualité : 13
* Articles recommandés cette semaine : 5
* Interprétation des articles communautaires : 4 articles
* Entrées d'encyclopédie populaire : 5
* Principales conférences avec date limite en juin : 2
Visitez le site officiel :hyper.ai
Ensembles de données publiques sélectionnés
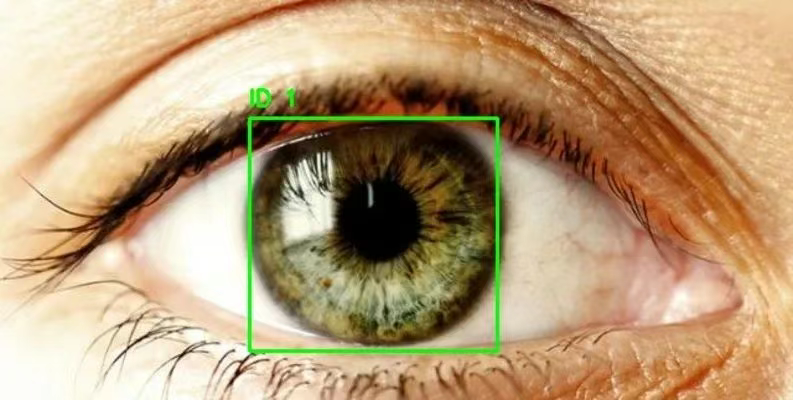
1. Ensemble de données de détection de lunettes de détection oculaire
Eye Detection est un ensemble de données de détection oculaire contenant près de 2 000 images clairement étiquetées du contour de l'œil. Ces données peuvent être utilisées pour entraîner des modèles de détection de cibles tels que RCNN et YOLO afin de suivre et de détecter les zones oculaires. Cet ensemble de données peut servir à créer des modèles de détection de la cataracte, des modèles de suivi oculaire, etc.
Utilisation directe :https://go.hyper.ai/5IUPr
2. Ensemble de données de recommandation musicale Yambda
Yambda-5B est un ensemble de données d'analyse musicale multimodale à grande échelle. Il vise à fournir des ressources d'entraînement et d'évaluation pour les grands modèles linguistiques (LLM) tels que la recommandation musicale, la recherche d'informations et le tri. Cet ensemble de données contient 4,79 milliards d'interactions (écoute, mention « j'aime » et « je n'aime plus »), couvrant 1 million d'utilisateurs et 9,39 millions de morceaux. Il s'agit actuellement de l'un des plus grands ensembles de données publiques de recommandation musicale.
Utilisation directe :https://go.hyper.ai/VSL3J
3. Ensemble de données d'imagerie satellite 4x Satellite
Cet ensemble de données est un ensemble de données d'images satellite haute résolution contenant des paires d'images satellite haute résolution (HR) et basse résolution (LR), conçues pour la tâche de super-résolution 4x.
Utilisation directe :https://go.hyper.ai/TyCeW
4. Ensemble de données de raisonnement médical MedXpertQA
L'ensemble de données contient 4 460 exemples de données, intégrant des données textuelles et visuelles, couvrant des tâches telles que la réponse aux questions médicales, le diagnostic clinique, la recommandation de plan de traitement et la compréhension des connaissances médicales de base. Il soutient la recherche et le développement de capacités complexes de prise de décision médicale et convient au réglage fin et à l'évaluation de modèles à moyenne échelle dans le domaine médical.
Utilisation directe :https://go.hyper.ai/YGW7J
5. Ensemble de données sur les sons d'animaux
L'ensemble de données contient environ 10 800 échantillons, couvrant l'audio de sept espèces, dont des oiseaux (tels que les mésanges à longue queue et les diamants mandarins), des chiens, des chauves-souris frugivores égyptiennes, des loutres géantes, des macaques et des orques. Chaque audio dure de 1 à 5 secondes, ce qui convient à la formation de modèles légers et aux expériences rapides.
Utilisation directe :https://go.hyper.ai/asUR4
6. Ensemble de données de spectrométrie de masse chimique GeMS
L'ensemble de données contient des centaines de millions de spectres de masse (dont 2 milliards dans le sous-ensemble GeMS-C1), y compris des données numériques structurées (paires de spectres de masse rapport masse/charge-intensité) et des métadonnées (sources spectrales, conditions expérimentales, etc.). Il s'agit de l'un des plus grands ensembles de données de spectrométrie de masse publics actuellement disponibles et il peut prendre en charge l'apprentissage de modèles à très grande échelle.
Utilisation directe :https://go.hyper.ai/yXI9M
7. Ensemble de données de démonstration de théorèmes DeepTheorem
DeepTheorem est un ensemble de données de raisonnement mathématique visant à améliorer les capacités de raisonnement des grands modèles de langage (LLM) grâce à des démonstrations informelles de théorèmes basées sur le langage naturel. Cet ensemble de données contient 121 000 théorèmes et démonstrations informels de niveau IMO couvrant plusieurs domaines mathématiques. Chaque paire théorème-démonstration est rigoureusement annotée.
Utilisation directe :https://go.hyper.ai/fjnad
8. Ensemble de données d'inférence SynLogic
SynLogic vise à améliorer les capacités de raisonnement logique des grands modèles de langage (LLM) grâce à l'apprentissage par renforcement avec récompenses vérifiables. L'ensemble de données contient 35 tâches de raisonnement logique variées avec vérification automatique, ce qui le rend particulièrement adapté à l'apprentissage par renforcement.
Utilisation directe :https://go.hyper.ai/iF5f2
9. Ensemble de données de raisonnement par mélange de pensées
Mixture-of-Thoughts est un ensemble de données de raisonnement multi-domaines intégrant des pistes de raisonnement de haute qualité dans trois domaines majeurs : les mathématiques, la programmation et les sciences. Il vise à entraîner de grands modèles de langage (LLM) à raisonner étape par étape. Chaque échantillon de cet ensemble de données contient un champ de messages qui stocke le processus de raisonnement sous la forme de plusieurs cycles de dialogue, permettant ainsi au modèle d'acquérir des capacités de déduction étape par étape.
Utilisation directe :https://go.hyper.ai/7Qo2l
10. Ensemble de données d'inférence Llama-Némotron
L'ensemble de données contient environ 22,06 millions de données mathématiques, environ 10,10 millions de données de code, le reste étant des données issues de domaines tels que les sciences et le suivi pédagogique. Les données sont générées collaborativement par plusieurs modèles tels que Llama-3.3-70B-Instruct, DeepSeek-R1 et Qwen-2.5, couvrant divers styles de raisonnement et voies de résolution de problèmes afin de répondre aux divers besoins d'apprentissage de modèles à grande échelle.
Utilisation directe :https://go.hyper.ai/4V52g
Tutoriels publics sélectionnés
Cette semaine, nous avons résumé 4 catégories de tutoriels publics de haute qualité :
*Tutoriels d'IA pour la science : 4
* Tutoriels de traitement d'images : 4
*Tutoriels de génération de code : 3
*Tutoriels d'interaction vocale : 2
Tutoriel sur l'IA pour la science
1. Démo du modèle de base atmosphérique à grande échelle d'Aurora
Aurora réduit considérablement les coûts de calcul tout en surpassant les systèmes de prévision opérationnels existants, favorisant ainsi un accès généralisé à des informations climatiques et météorologiques de haute qualité. Aurora s'est avéré environ 5 000 fois plus rapide que le système de prévision numérique le plus avancé, IFS.
Ce tutoriel utilise une carte A6000 unique comme ressource. Après avoir démarré le conteneur, cliquez sur l'adresse API pour accéder à l'interface Web.
Exécutez en ligne :https://go.hyper.ai/416Xs
2. Déploiement en un clic du modèle d'IA médicale multimodale MedGemma-4b-it
MedGemma-4b-it est un modèle d'IA médicale multimodale spécialement conçu pour le secteur médical. Il s'agit d'une version optimisée pour les instructions de la suite MedGemma. Il utilise l'encodeur d'images SigLIP, spécialement pré-entraîné, et exploite des données d'images médicales anonymisées, notamment des radiographies thoraciques, des images dermatologiques, des images ophtalmologiques et des coupes histopathologiques.
Ce tutoriel utilise une seule carte RTX 4090 comme ressource. Après avoir démarré le conteneur, cliquez sur l’adresse API pour accéder à l’interface Web.
Exécutez en ligne :https://go.hyper.ai/31RKp
3. Déploiement en un clic du modèle de raisonnement médical MedGemma-27b-text-it
Ce modèle se concentre sur le traitement des textes cliniques et est particulièrement efficace pour le triage des patients et l'aide à la prise de décision, fournissant aux médecins des informations rapides et précieuses sur l'état des patients pour faciliter la formulation de plans de traitement efficaces.
Ce tutoriel utilise les ressources A6000 double SIM. Ouvrez le lien ci-dessous pour le déployer en un clic.
Exécutez en ligne :https://go.hyper.ai/2mDmF
4. Déploiement vLLM+Open WebUI II-Medical-8B modèle de raisonnement médical
Le modèle est basé sur le modèle Qwen/Qwen3-8B et optimise les performances du modèle en utilisant SFT (réglage fin supervisé) à l'aide d'un ensemble de données d'inférence spécifique au domaine médical et en formant DAPO (une méthode d'optimisation possible) sur un ensemble de données d'inférence dure.
Les ressources informatiques utilisées dans ce tutoriel sont une seule carte RTX 4090.
Exécutez en ligne :https://go.hyper.ai/1Qvwo
Tutoriel sur le traitement d'images
1. DreamO : un framework unifié de personnalisation d'images
Basé sur l'architecture DiT (Diffusion Transformer), DreamO intègre une variété de tâches de génération d'images, prend en charge des fonctions complexes telles que le changement de costume (IP), le changement de visage (ID), le transfert de style (Style), la combinaison multi-sujets et réalise un contrôle multi-conditions via un seul modèle.
Ce tutoriel utilise des ressources pour une seule carte A6000.
Exécutez en ligne :https://go.hyper.ai/zGGbh
2. BAGEL : Un modèle unifié pour la compréhension et la génération multimodales
BAGEL-7B-MoT est conçu pour gérer de manière uniforme les tâches de compréhension et de génération de données multimodales telles que le texte, les images et les vidéos. BAGEL a démontré des capacités complètes dans des tâches multimodales telles que la compréhension et la génération multimodales, le raisonnement et l'édition complexes, la modélisation du monde et la navigation. Ses principales fonctions sont la compréhension visuelle, la conversion de texte en image, l'édition d'images, etc.
Ce didacticiel utilise les ressources informatiques de la double carte A6000 et fournit la génération d'images, la génération d'images avec Think, l'édition d'images, l'édition d'images avec Think et la compréhension d'images pour les tests.
Exécutez en ligne :https://go.hyper.ai/76cEZ

3. Tutoriel en ligne sur le flux de travail ComfyUI Flex.2
Flex.2-preview peut générer des images de haute qualité à partir de descriptions textuelles saisies. Il prend en charge la saisie de texte jusqu'à 512 jetons et la compréhension de descriptions complexes pour générer le contenu image correspondant. Il prend également en charge la réparation ou le remplacement de zones spécifiques de l'image. L'utilisateur fournit l'image et le masque de réparation, et le modèle génère le nouveau contenu image dans la zone spécifiée.
Ce didacticiel utilise une seule carte RTX 4090 comme ressource et prend uniquement en charge les invites en anglais.
Exécutez en ligne :https://go.hyper.ai/MH5qY
4. Tutoriel sur le flux de travail de restauration d'images ComfyUI LanPaint
LanPaint est un outil open source de restauration locale d'images. Il utilise une méthode de raisonnement innovante pour s'adapter à divers modèles de diffusion stables (y compris les modèles personnalisés) sans formation supplémentaire, permettant ainsi une restauration d'images de haute qualité. Comparé aux méthodes traditionnelles, LanPaint offre une solution plus légère qui réduit considérablement les besoins en données d'apprentissage et en ressources de calcul.
Ce tutoriel utilise une seule carte RTX 4090. Vous pouvez cloner rapidement le modèle en cliquant sur le lien ci-dessous.
Exécutez en ligne :https://go.hyper.ai/QAuag
Tutoriel sur la génération de code
1. vLLM+Open WebUI Déploiement Seed-Coder-8B-Instruct
Seed-Coder-8B-Instruct est un modèle de langage de code open source léger mais puissant. Il s'agit d'une version optimisée de la série d'instructions Seed-Coder. Avec un minimum de ressources, LLM peut gérer efficacement et de manière autonome les données d'entraînement du code, améliorant ainsi considérablement les capacités de codage. Ce modèle repose sur l'architecture Llama 3, possède 8,2 B de paramètres et prend en charge un contexte long de 32 K jetons.
Les ressources informatiques utilisées dans ce tutoriel sont une seule carte RTX 4090.
Exécutez en ligne :https://go.hyper.ai/BnO32
2. Mellum-4b-base est un modèle conçu pour la complétion de code
Mellum-4b-base est conçu pour les tâches de compréhension, de génération et d'optimisation de code. Ce modèle démontre d'excellentes capacités tout au long du processus de développement logiciel et convient à des scénarios tels que la programmation assistée par IA, l'intégration d'IDE intelligents, le développement d'outils pédagogiques et la recherche de code.
Ce tutoriel utilise une seule carte RTX 4090 comme ressource, et le modèle est uniquement utilisé pour optimiser le code.
Exécutez en ligne :https://go.hyper.ai/2iEWz
3. Déploiement en un clic d'OpenCodeReasoning-Nemotron-32B
Ce modèle est un modèle de langage hautes performances conçu pour le raisonnement et la génération de code. Il s'agit de la version phare de la suite de modèles OpenCodeReasoning (OCR) et prend en charge une longueur de contexte de 32 000 jetons.
Les ressources informatiques utilisées dans ce tutoriel sont des cartes double A6000.
Exécutez en ligne :https://go.hyper.ai/jhwYd
Tutoriel sur l'interaction vocale
1. VITA-1.5 : Démonstration du modèle d'interaction multimodale
ITA-1.5 est un modèle linguistique multimodal à grande échelle qui intègre la vision, le langage et la parole. Il est conçu pour permettre une interaction visuelle et vocale en temps réel, comparable à celle de GPT-4o. VITA-1.5 réduit considérablement la latence d'interaction, de 4 secondes à 1,5 seconde, améliorant ainsi considérablement l'expérience utilisateur.
Ce tutoriel utilise une carte unique A6000 comme ressource. Actuellement, l’interaction de l’IA ne prend en charge que le chinois et l’anglais.
Exécutez en ligne :https://go.hyper.ai/WTcdM
2. Kimi-Audio : Laissez l'IA comprendre les humains
Kimi-Audio-7B-Instruct est un modèle d'infrastructure audio open source capable de gérer diverses tâches de traitement audio au sein d'une infrastructure unifiée. Il prend en charge diverses tâches telles que la reconnaissance vocale automatique (RAP), les questions-réponses audio (QRA), le sous-titrage audio automatique (CAA), la reconnaissance vocale des émotions (RSE), la classification des événements/scènes sonores (SEC/ASC) et le dialogue vocal de bout en bout.
Ce tutoriel utilise des ressources pour une seule carte A6000.
Exécutez en ligne :https://go.hyper.ai/UBRBP
Recommandation de papier de cette semaine
1. Un modèle fondateur du système terrestre
Cet article propose le modèle Aurora, un modèle de base à grande échelle formé sur plus d'un million d'heures de données géophysiques diverses, qui surpasse les systèmes de prévision opérationnelle existants en matière de qualité de l'air, de vagues océaniques, de trajectoires de cyclones tropicaux et de prévisions météorologiques à haute résolution.
Lien vers l'article :https://go.hyper.ai/ibyij
2. Paper2Poster : Vers l'automatisation des posters multimodaux à partir d'articles scientifiques
La création d'affiches pour articles universitaires est une tâche essentielle et complexe en communication scientifique, qui nécessite de compresser de longs documents intercalés en une seule page au contenu visuellement cohérent. Pour relever ce défi, cet article présente la première suite de tests et de mesures pour la création d'affiches pour articles universitaires, capable de transformer un article de 22 pages en une affiche PowerPoint finale modifiable.
Lien vers l'article :https://go.hyper.ai/Q4cQG
3. ProRL : l'apprentissage par renforcement prolongé élargit les limites du raisonnement dans les grands modèles linguistiques
La question de savoir si l'apprentissage par renforcement élargit réellement les capacités de raisonnement du modèle reste controversée. Cet article propose une nouvelle méthode d'apprentissage, ProRL, qui combine le contrôle de la divergence KL, la réinitialisation de la politique de référence et une suite de tâches diversifiée. Cette approche apporte de nouvelles perspectives pour une meilleure compréhension des conditions dans lesquelles l'apprentissage par renforcement élargit significativement les limites du raisonnement des modèles de langage.
Lien vers l'article :https://go.hyper.ai/62DUb
4. Post-formation non supervisée pour le raisonnement LLM multimodal via GRPO
Cette étude utilise GRPO, un algorithme d'apprentissage par renforcement en ligne stable et évolutif, pour parvenir à une auto-amélioration continue sans supervision externe, et propose MM-UPT, un cadre de post-formation non supervisé simple et efficace pour les grands modèles linguistiques multimodaux. Les résultats expérimentaux montrent que MM-UPT améliore significativement la capacité de raisonnement de Qwen2.5-VL-7B.
Lien vers l'article :https://go.hyper.ai/W5nO5
5. Le mécanisme d'entropie de l'apprentissage par renforcement pour les modèles de langage raisonné
Cet article vise à surmonter un obstacle majeur à l'utilisation de grands modèles de langage (LLM) pour le raisonnement en apprentissage par renforcement à grande échelle (RL), à savoir l'effondrement de l'entropie des politiques. À cette fin, les chercheurs ont proposé deux méthodes simples et efficaces : Clip-Cov et KL-Cov. La première écrête les jetons à forte covariance, tandis que la seconde leur impose une pénalité KL. Les résultats expérimentaux montrent que ces méthodes peuvent favoriser le comportement d'exploration, aidant ainsi la politique à échapper à l'effondrement de l'entropie et à obtenir de meilleures performances en aval.
Lien vers l'article :https://go.hyper.ai/rFSoq
Autres articles sur les frontières de l'IA :https://go.hyper.ai/UuE1o
Interprétation des articles communautaires
S'appuyant sur les avancées réalisées par la série GPT dans le domaine du langage, une équipe de recherche de l'Institut de chimie organique et de biochimie de l'Académie tchèque des sciences a extrait 700 millions de spectres MS/MS du Global Natural Products Social Molecular Network (GNPS), a construit avec succès le plus grand ensemble de données de spectrométrie de masse de l'histoire, GeMS, et a formé un modèle Transformer DreaMS avec 116 millions de paramètres.
Voir le rapport complet :https://go.hyper.ai/P9qvl
Afin de mieux connecter la recherche de pointe aux scénarios d'application, HyperAI organisera le 7e salon Meet AI Compiler Technology à Pékin le 5 juillet. Nous avons la chance d'avoir invité de nombreux experts seniors d'AMD, de l'Université de Pékin, de Muxi Integrated Circuit, etc. pour partager leurs meilleures pratiques et leurs analyses de tendances pour les compilateurs d'IA.
Voir le rapport complet :https://go.hyper.ai/FPxw2
Le Dr Liang Haojian, de l'Institut d'innovation en information spatiale de l'Académie chinoise des sciences, a prononcé une conférence intitulée « Recherche sur les méthodes d'optimisation de la configuration des installations de lutte contre les incendies en milieu urbain basées sur l'apprentissage par renforcement profond hiérarchique » lors de la réunion académique annuelle 2025 du Comité professionnel d'analyse des modèles géographiques et de l'information géographique de la Société chinoise de géographie. Prenant comme point de départ l'optimisation de la configuration des installations de lutte contre les incendies en milieu urbain, les méthodes d'optimisation classiques dans le domaine de l'optimisation géospatiale ont été systématiquement passées en revue, et les avantages et le potentiel des méthodes d'optimisation basées sur l'apprentissage par renforcement profond (DRL) ont été présentés en détail. Cet article est une transcription des points saillants de la présentation du Dr Liang Haojian.
Voir le rapport complet :https://go.hyper.ai/xvnAI
Le Show Lab de l'Université nationale de Singapour a publié le 28 mai 2025 un plug-in de cohérence universel, OmniConsistency, qui utilise un transformateur de diffusion à grande échelle (DiT). Il s'agit d'une conception entièrement plug-and-play, compatible avec LoRA de tout style sous le framework Flux, et basée sur un mécanisme d'apprentissage de cohérence pour les paires d'images stylisées afin d'obtenir une généralisation robuste.
Voir le rapport complet :https://go.hyper.ai/etmWQ
Articles populaires de l'encyclopédie
1. DALL-E
2. Boucle homme-machine
3. Fusion de tri inverse
4. Mémoire à long terme bidirectionnelle
5. Compréhension linguistique multitâche à grande échelle
Voici des centaines de termes liés à l'IA compilés pour vous aider à comprendre « l'intelligence artificielle » ici :
Date limite de juin pour le sommet
S&P 2026 6 juin 7:59:59
ICDE 2026 19 juin 7:59:59
Suivi unique des principales conférences universitaires sur l'IA :https://go.hyper.ai/event
Voici tout le contenu de la sélection de l'éditeur de cette semaine. Si vous souhaitez inclure hyper.ai Pour les ressources sur le site officiel, vous êtes également invités à laisser un message ou à contribuer pour nous le dire !
À la semaine prochaine !








