Command Palette
Search for a command to run...
ComfyUI Chroma Ouvre Une Nouvelle Dimension Des Graphiques Littéraires ; Ensemble De Données De Raisonnement Mathématique OpenMathReasoning, Le Premier Ensemble De Données De Haute Qualité Axé Sur Le Raisonnement Mathématique

Le modèle de graphe de Wensheng a fait des progrès significatifs ces dernières années, mais les modèles existants présentent encore de nombreuses limites dans les applications pratiques. La plupart des modèles ne peuvent générer qu'une seule image et ne peuvent pas effectuer de réglages précis sur l'image. Pour relever ce défi, l’équipe rock a lancé le modèle Chroma.
Chroma est un modèle de paramètres 8,9 B basé sur FLUX.1-schnell. Ce modèle permet un étalonnage des couleurs de niveau cinématographique, la synthèse d'effets spéciaux et un rendu stylisé, pour des effets visuels de niveau professionnel.Il couvre également divers genres, notamment l'animation, les animaux, les œuvres d'art et la photographie. Ce modèle est actuellement accessible via ComfyUI pour permettre aux utilisateurs de créer des contenus personnalisés..Comparé aux logiciels d'effets spéciaux traditionnels, il est plus simple et plus pratique à utiliser.
HyperAI Super Neural est désormais en ligne « Tutoriel en ligne ComfyUI Chroma Workflow »,Venez l'essayer~
Utilisation en ligne :https://go.hyper.ai/y8mdm
Du 19 au 23 mai, le site officiel de hyper.ai est mis à jour :
* Ensembles de données publiques de haute qualité : 10
* Tutoriels de haute qualité : 16
* Sélection d'articles communautaires : 6 articles
* Entrées d'encyclopédie populaire : 5
* Principales conférences avec date limite en mai : 3
Visitez le site officiel :hyper.ai
Ensembles de données publiques sélectionnés
1. Ensemble de données de référence d'évaluation multimodale M2RAG
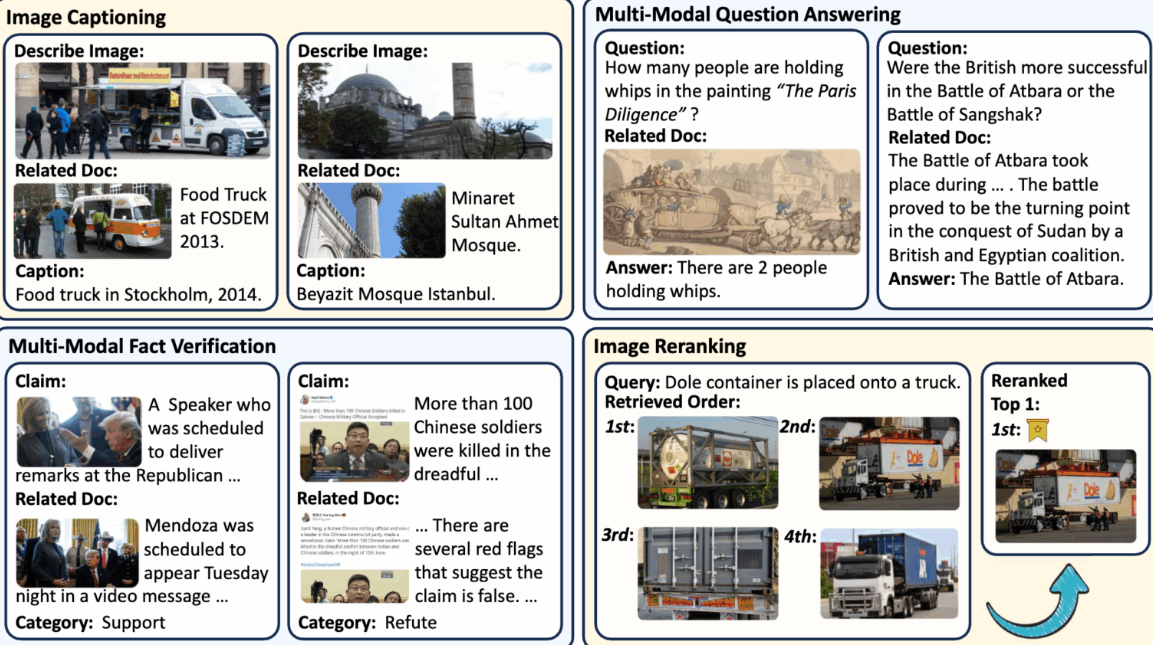
Cet ensemble de données combine des données d'image et de texte pour simuler des tâches de recherche et de génération d'informations dans des scénarios réels, tels que l'analyse d'événements d'actualité et la réponse visuelle à des questions. Il se concentre sur l'évaluation de la capacité des MLLM à utiliser les connaissances documentaires récupérées dans des contextes multimodaux, y compris la compréhension du contenu de l'image, le raisonnement par association image-texte et le jugement des faits.
Utilisation directe :https://go.hyper.ai/xQuV4
2. Ensemble de données de problèmes de géométrie Geometry3k
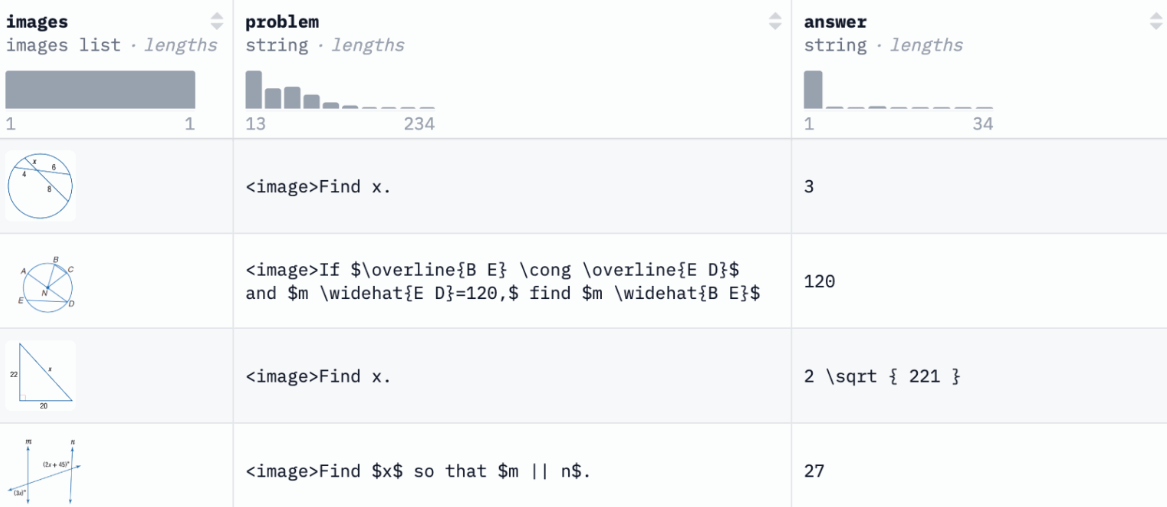
L'ensemble de données décrit une grande variété de problèmes de géométrie, tels que la résolution d'angles, de longueurs de côtés, de surfaces, de périmètres, etc., avec un total de 6 293 éléments de texte. Les diagrammes sont utilisés pour aider à présenter des informations graphiques dans les problèmes de géométrie, tels que diverses formes géométriques (triangles, cercles, quadrilatères, etc.) et leurs interrelations, avec un total de 27 213 éléments de texte.
Utilisation directe :https://go.hyper.ai/xQuV4
3. Ensemble de données de structure cristalline LLM4Mat-Bench
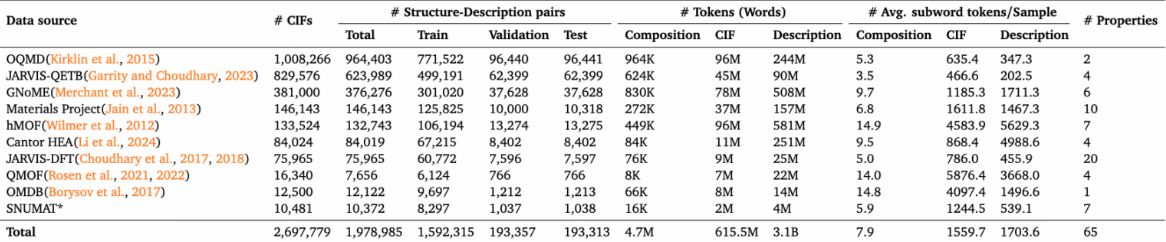
L'ensemble de données contient environ 1,97 million d'échantillons de structures cristallines provenant de 10 bases de données publiques de matériaux, couvrant 45 propriétés physiques et chimiques différentes des matériaux. Il s’agit de la plus grande référence à ce jour pour évaluer les performances des grands modèles de langage (LLM) pour la prédiction des propriétés des matériaux.
Utilisation directe :https://go.hyper.ai/cWEme
4. Ensemble de données vocales chinoises SeniorTalk pour les conversations des personnes âgées
L'ensemble de données contient des annotations détaillées multidimensionnelles, notamment des informations sur le locuteur, la transcription du contenu des conversations, des horodatages (y compris le niveau de la phrase et le niveau du mot), des étiquettes de catégorie d'accent, etc. Ces données du monde réel fourniront un soutien précieux pour des recherches approfondies sur les signaux vocaux des personnes âgées et l'optimisation des systèmes d'interaction vocale pour les personnes âgées, et favoriseront le développement d'industries connexes telles que les équipements adaptés au vieillissement, la gestion de la santé et les robots de soins assistés aux personnes âgées.
Utilisation directe :https://go.hyper.ai/MtvcV
5. Ensemble de données de raisonnement mathématique DeepMath-103K
L'ensemble de données se concentre sur les problèmes mathématiques des niveaux 5 à 9, couvrant l'algèbre, le calcul, la théorie des nombres, la géométrie, les probabilités, les mathématiques discrètes et d'autres domaines, et se concentre sur les capacités de raisonnement complexes stimulantes. L'ensemble de données effectue également un traitement de décontamination détaillé pour les repères communs via la correspondance sémantique afin de minimiser les fuites de l'ensemble de tests et de promouvoir une évaluation équitable du modèle.
Utilisation directe :https://go.hyper.ai/dquTu
6. Ensemble de données de raisonnement mathématique OpenMathReasoning
L'ensemble de données comprend des étiquettes de type de problèmes mathématiques, des étapes détaillées de résolution de problèmes, une classification du niveau de difficulté des problèmes, etc. Ces données de haute qualité, qui proviennent du domaine professionnel des mathématiques et des communautés en ligne, fournissent un support solide et puissant pour une recherche approfondie sur les processus de raisonnement mathématique et l'optimisation des modèles de résolution de problèmes mathématiques, et favorisent le développement vigoureux d'industries connexes telles que les systèmes de tutorat mathématiques intelligents, les outils auxiliaires de compétition mathématique et l'automatisation du calcul de recherche scientifique.
Utilisation directe :https://go.hyper.ai/svX2f
7. Ensemble de données image-texte multimodal VL3-Syn7M
L'ensemble de données contient des annotations fines multidimensionnelles, notamment des légendes détaillées d'images, des légendes courtes et des informations sur la source de l'image, et couvre divers types de données telles que des images de scène, des images de documents et des images de texte, fournissant un matériel riche pour que le modèle apprenne des informations multimodales.
Utilisation directe :https://go.hyper.ai/luQiA
8. Ensemble de données sur les propriétés des matériaux DFT
L'ensemble de données couvre une variété de compositions chimiques et de propriétés physiques, chaque entrée correspondant à un matériau unique. Toutes les propriétés ont été obtenues via des calculs de théorie fonctionnelle de la densité (DFT), une méthode de calcul largement utilisée dans la prédiction du comportement des matériaux. Cet ensemble de données convient à des tâches telles que la modélisation des propriétés des matériaux, la formation à l'apprentissage automatique et la découverte de matériaux, fournissant un support de données de base solide aux scientifiques et aux chercheurs en données.
Utilisation directe :https://go.hyper.ai/S7bEj
9. Ensemble de données sur le module de Young
Le module de Young est une quantité physique qui mesure la capacité d'un matériau à résister à la déformation. Plus sa valeur est élevée, moins le matériau risque de se déformer. Cet ensemble de données contient 393 points de données et vise à caractériser l'anisotropie du matériau en mesurant le module de Young du cristal dans différentes directions.
Utilisation directe :https://go.hyper.ai/do6zP
10. Ensemble de données de conversation chinoise pour enfants ChildMandarin
Cet ensemble de données est conçu pour remédier à la rareté des données sur la parole en mandarin pour ce groupe d'âge et vise à soutenir le développement de domaines de recherche connexes tels que la reconnaissance vocale des enfants et la vérification des locuteurs.
Utilisation directe :https://go.hyper.ai/GynAr
Tutoriels publics sélectionnés
Tutoriel de génération d'images
1. Tutoriel en ligne sur le flux de travail ComfyUI Chroma
Chroma est un modèle de figure de Vincent introduit par rock en 2025, basé sur le modèle de paramètre 8.9 B de FLUX.1-schnell. Le modèle est toujours en cours de formation et l'ensemble de données de formation a soigneusement sélectionné 5 millions de données à partir de 20 millions d'échantillons, couvrant divers types tels que les anime, les bêtes, les œuvres d'art et les photos.
Ce didacticiel utilise une seule carte RTX 4090 comme ressource et prend uniquement en charge les invites en anglais.
Exécutez en ligne :https://go.hyper.ai/irRhP
2. FractalGen : Génération d'images haute résolution pixel par pixel FractalGen est une nouvelle technologie de génération d'images basée sur des idées fractales. Il permet de générer des images haute résolution pixel par pixel grâce à des modèles génératifs fractals, améliore considérablement l'efficacité de calcul et résout le goulot d'étranglement de calcul des modèles génératifs traditionnels dans la génération d'images haute résolution.
Le projet a été déployé sous forme de notebook. Vous pouvez le cloner en un clic pour le découvrir étape par étape !
Exécutez en ligne :https://go.hyper.ai/qZN2x

3. PixelFlow : une solution de génération d'images à l'échelle des pixels
Le projet PixelFlow est une famille de modèles de génération d'images qui fonctionnent directement dans l'espace pixel brut, contrairement aux modèles d'espace latent dominants.
Les résultats qualitatifs de la conversion texte-image montrent que PixelFlow est performant en termes de qualité d'image, de qualité artistique et de contrôle sémantique.
Exécutez en ligne :https://go.hyper.ai/MbfLU
4. HiDream-I1-Démo de génération d'images complètes
Le projet HiDream-I1 est un nouveau modèle de base de génération d'images open source. HiDream-I1-Full est un modèle de génération d'images open source avec 17B paramètres. Les deux autres versions sont HiDream-I1-Dev et HiDream-I1-Fast. HiDream-I1-Full est le meilleur en termes de performances, capable de produire une qualité d'image de pointe en quelques secondes.
Les modèles et dépendances pertinents de ce projet ont été déployés. Après avoir démarré le conteneur, cliquez sur l’adresse API pour accéder à l’interface Web.
Exécutez en ligne :https://go.hyper.ai/2fSbo
5. OminiControl : Génération et contrôle d'images polyvalents
OminiControl est un framework de contrôle à usage général minimal mais puissant pour les modèles de transformateurs de diffusion tels que FLUX. Vous pouvez créer vos propres modèles OminiControl en personnalisant n'importe quelle tâche de contrôle (3D, multi-vues, guidage gestuel, etc.) à l'aide des modèles FLUX.
Ce tutoriel est basé sur le framework de contrôle universel OminiControl, et la ressource informatique utilise une seule carte A6000.
Exécutez en ligne :https://go.hyper.ai/zOAWH

Tutoriel sur l'IA pour la science
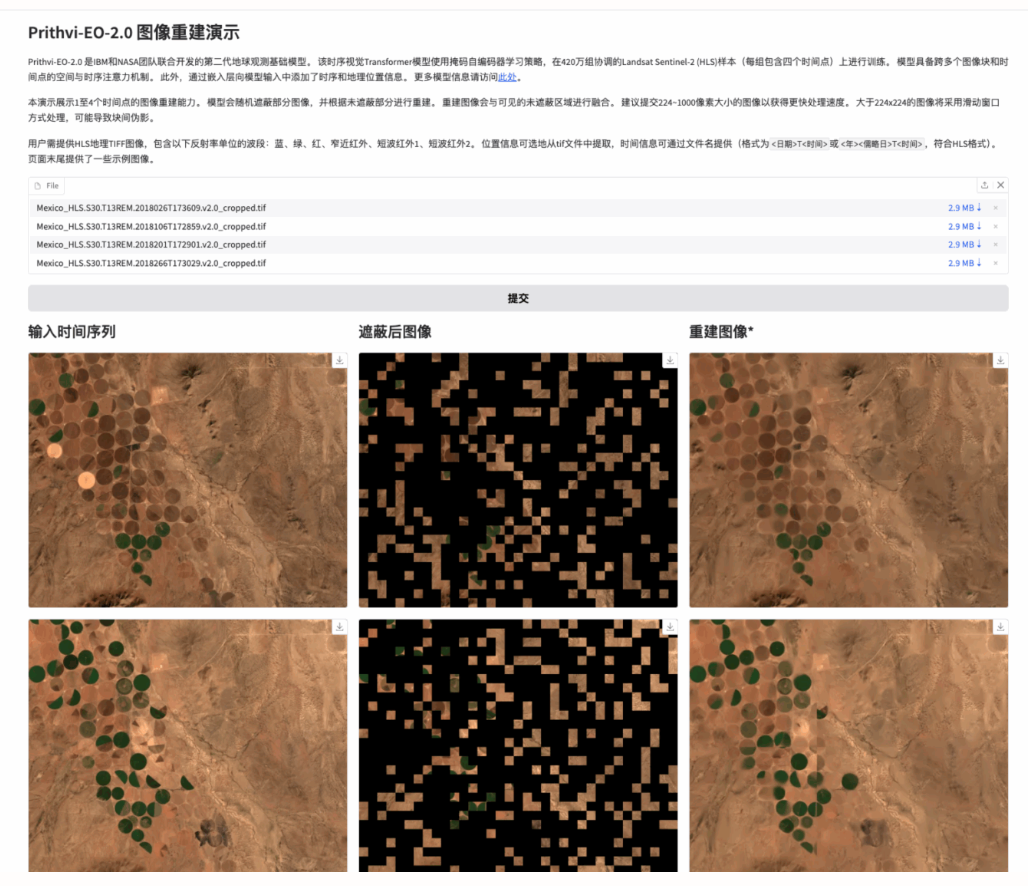
1. Démonstration du modèle de télédétection d'observation terrestre multitemporelle Prithvi-EO-2.0
Le modèle contient des mécanismes d’attention spatiale et temporelle sur plusieurs blocs et horodatages. De plus, des informations de temps et de localisation sont ajoutées à l'entrée du modèle via des intégrations.
Ce didacticiel utilise le modèle Prithvi-EO-2.0-300M comme démonstration et la ressource informatique utilise RTX 4090.
Exécutez en ligne :https://go.hyper.ai/DvqV1
2. Démonstration du modèle de régression intelligente spatio-temporelle (STIR) de Gnnwr
GNNWR est un modèle de régression intelligent spatio-temporel basé sur PyTorch spécialement conçu pour gérer les problèmes de non-stationnarité spatiale et temporelle. Le modèle permet une modélisation de haute précision de processus géographiques complexes en convertissant l'ajustement non linéaire de la proximité géographique et des poids non stationnaires en représentation et construction d'un réseau neuronal.
Les modèles et dépendances pertinents de ce projet ont été déployés. Après avoir démarré le conteneur, cliquez sur l’adresse API pour accéder à l’interface Web.
Exécutez en ligne :https://go.hyper.ai/Y1Cq0
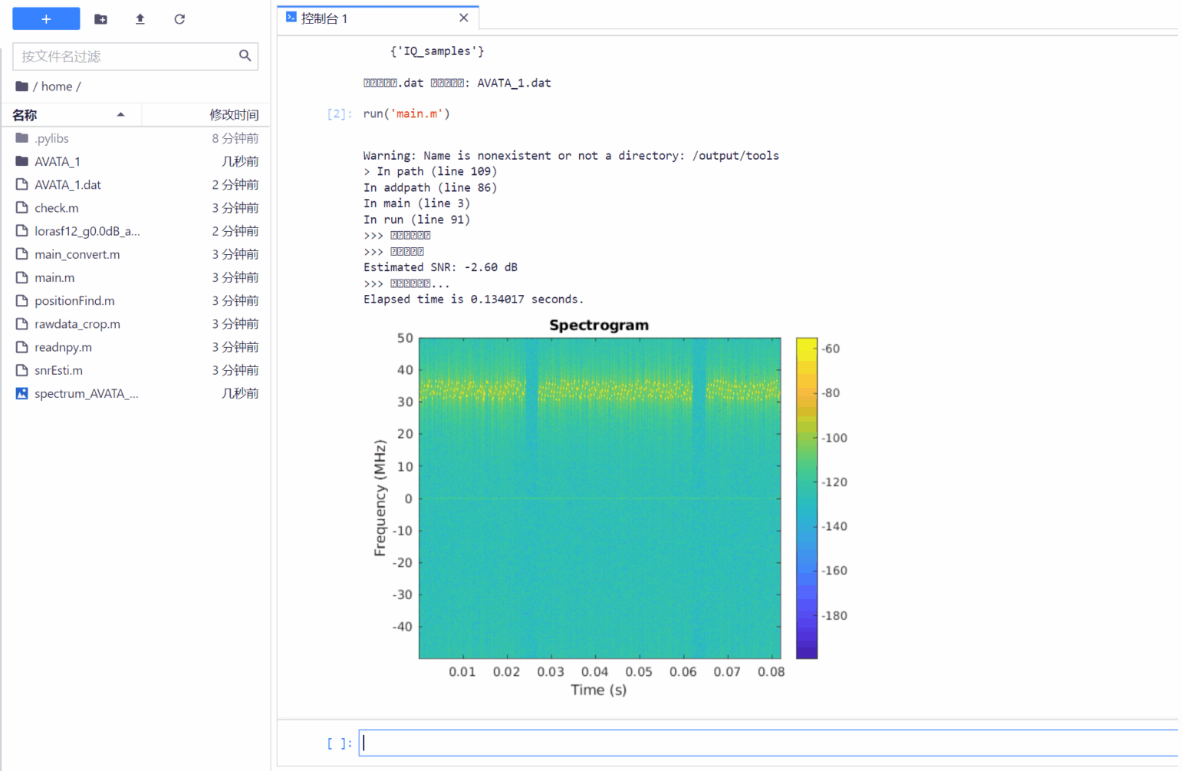
3. Traitement des signaux UAV à l'aide de Matlab basé sur le système RFUAV
Dans le domaine de la sécurité des communications et de la surveillance du spectre, les systèmes d’identification de drones basés sur des données de radiofréquence (RF) ont été largement étudiés. Le projet RFUAV analyse et traite les signaux IQ des drones grâce à l'analyse du spectre et à l'estimation du rapport signal sur bruit.
Étant donné que les données originales ne sont pas encore disponibles, l'ensemble de données ici utilise les données de la plateforme IDLab comme démonstration de traitement des données. Étant donné que l’ensemble de données complet est trop volumineux, ce didacticiel n’analyse qu’une partie des données. Cliquez sur le lien ci-dessous pour déployer en un clic.
Exécutez en ligne :https://go.hyper.ai/rowsq
4. Analyse de la réponse dynamique non linéaire du séisme de Koyna en tenant compte de la pression hydrodynamique
Abaqus est un puissant logiciel d'analyse par éléments finis (FEA) largement utilisé dans le domaine de la simulation d'ingénierie. Il simule et analyse divers problèmes d'ingénierie grâce à la méthode des éléments finis et peut gérer des problèmes allant des problèmes linéaires simples aux problèmes non linéaires complexes.
Ce tutoriel est le tutoriel officiel d'Abaqus : Analyse sismique des barrages-poids en béton. Cet exemple illustre une application typique du modèle de matériau de plasticité endommagé pour le béton afin d'évaluer la stabilité et les dommages des structures en béton soumises à des charges arbitraires.
Exécutez en ligne :https://go.hyper.ai/cXdKk
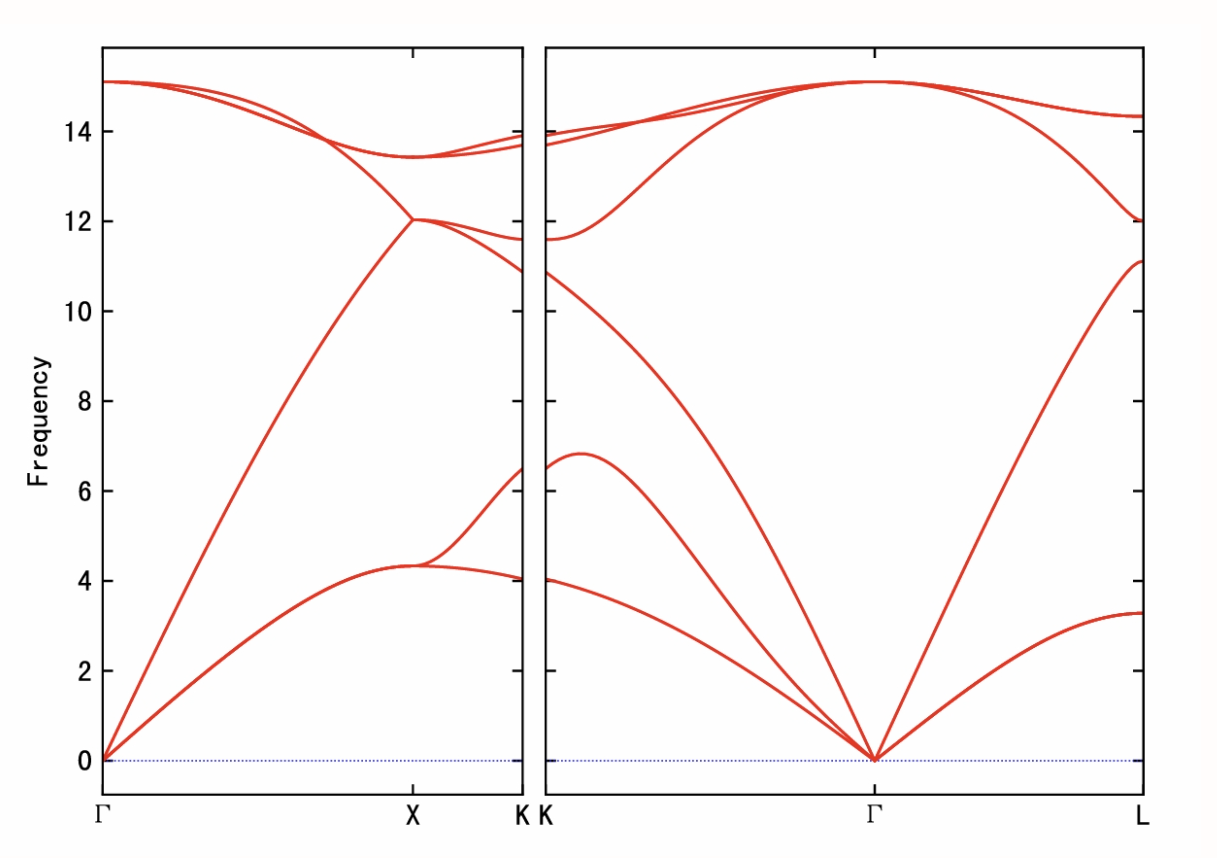
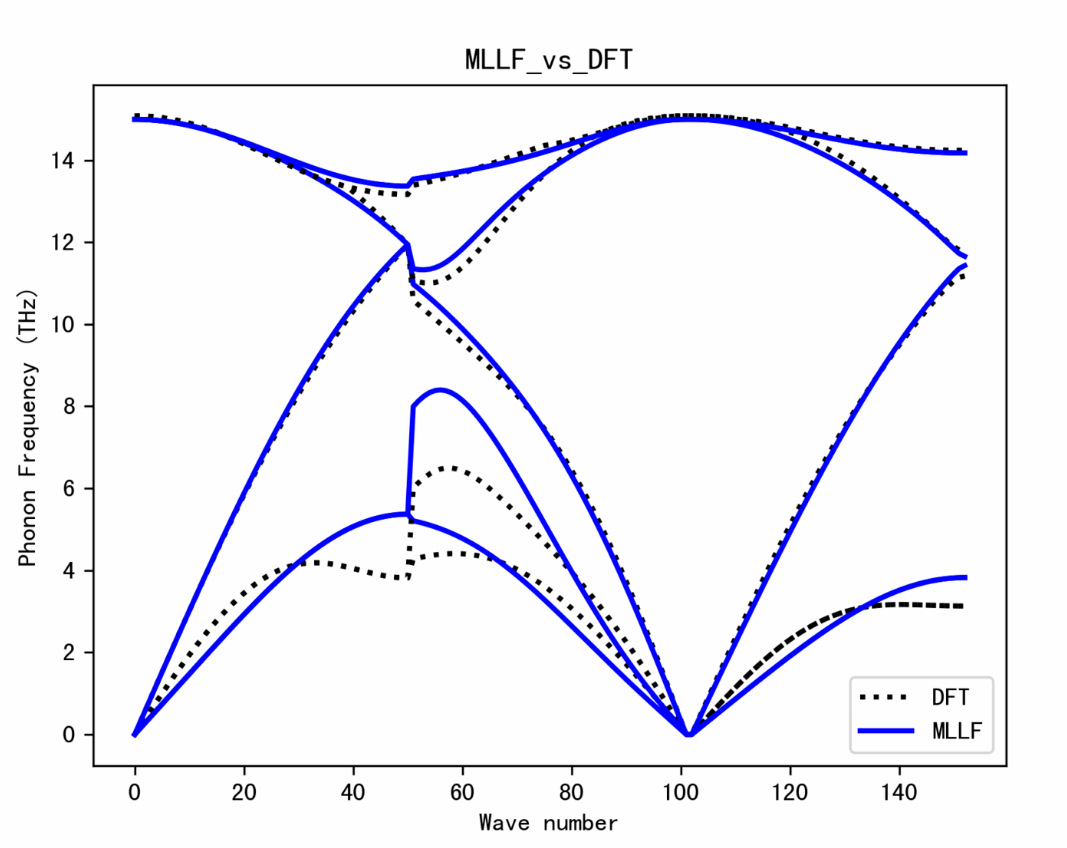
5. VASP combiné à Phonopy pour calculer le spectre de phonons du silicium
Phonopy est un package Python permettant de calculer les structures de bandes de phonons, les propriétés thermiques, les vitesses de groupe et d'autres quantités liées aux phonons aux niveaux harmonique et quasi-harmonique.
Ce tutoriel utilisera un script automatisé pour effectuer une phonographie afin de démontrer le processus de calcul. Grâce à ce tutoriel, vous apprendrez le processus de base du calcul du spectre des phonons. Après avoir démarré le conteneur, cliquez sur l’adresse API pour accéder à l’interface Web.
Exécutez en ligne :https://go.hyper.ai/Lb00V
6. Utilisation de VASP pour l'entraînement des champs de force par apprentissage automatique
Ce tutoriel prendra le cristal de silicium comme exemple et montrera comment entraîner le champ de force d'apprentissage automatique vasp via la dynamique moléculaire d'ensemble NpT. Grâce à ce tutoriel, vous apprendrez le processus de base de la formation du champ de force de l'apprentissage automatique. Après avoir démarré le conteneur, cliquez sur l’adresse API pour accéder à l’interface Web.
Exécutez en ligne :https://go.hyper.ai/JssLr
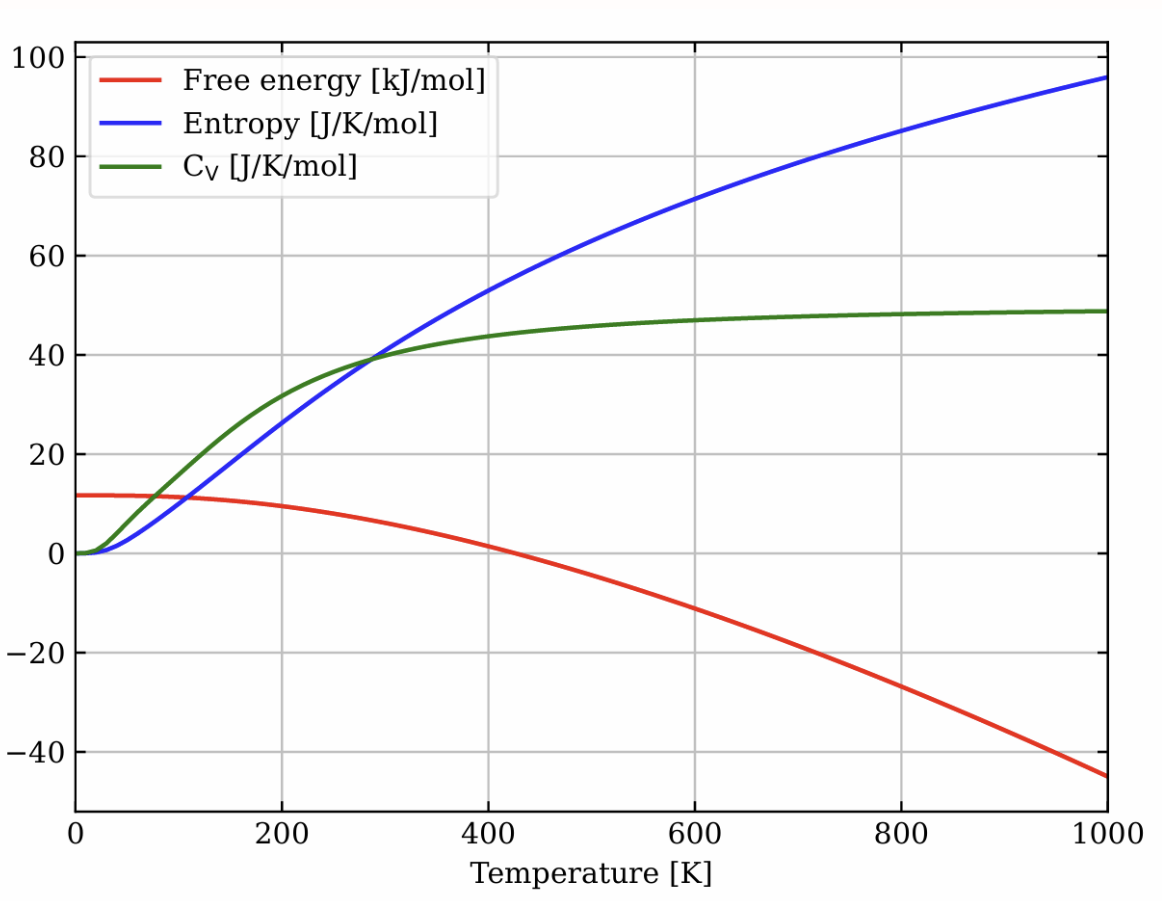
7. VASP combiné à Phonopy pour calculer la capacité thermique spécifique du silicium
VASP est un programme informatique pour la modélisation de matériaux à l'échelle atomique à partir de principes de base, tels que les calculs de structure électronique et la dynamique moléculaire mécanique quantique. Phonopy est un package Python permettant de calculer les structures de bandes de phonons, les propriétés thermiques, les vitesses de groupe et d'autres quantités liées aux phonons aux niveaux harmonique et quasi-harmonique.
Ce tutoriel utilisera un script automatisé pour démontrer le processus de calcul à l'aide de Phonopy. Grâce à ce tutoriel, vous apprendrez le processus de base du calcul de la capacité thermique spécifique. Après avoir démarré le conteneur, cliquez sur l’adresse API pour accéder à l’interface Web.
Exécutez en ligne :https://go.hyper.ai/MWlU1
Tutoriel vLLM
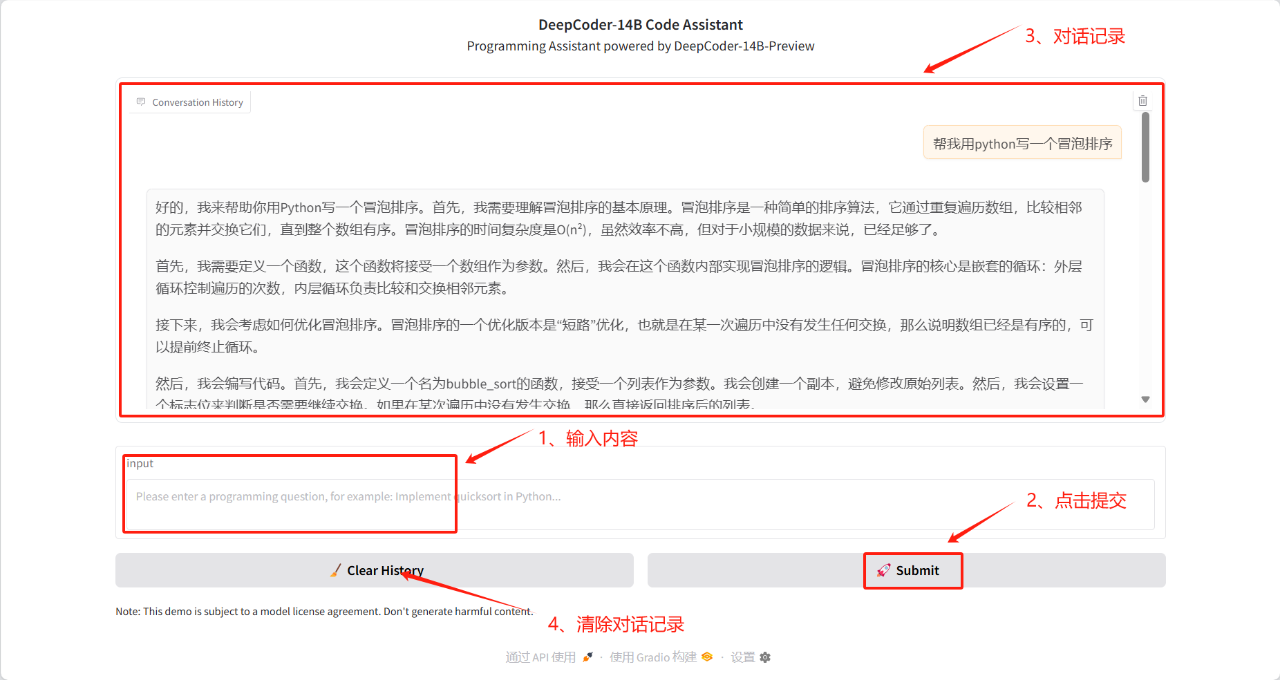
1. Déploiement en un clic de DeepCoder-14B-Preview DeepCoder-14B-Preview a atteint une précision Pass@1 de 60,6% sur LiveCodeBench v5 (8/1/24-2/1/25), une amélioration de 8% par rapport au modèle de base (53%), et a obtenu des performances similaires à celles de l'o3-mini d'OpenAI avec seulement 14B paramètres. DeepCoder-14B-Preview utilise la méthode de quantification 8 bits fournie par bitsandbytes pour optimiser l'utilisation de la mémoire vidéo. La ressource de puissance de calcul utilisée est RTX4090. Après avoir démarré le conteneur, cliquez sur l’adresse API pour accéder à l’interface Web.
Exécutez en ligne :https://go.hyper.ai/6U1k1
2. Déployer GLM-4-32B à l'aide de vLLM et d'Open-WebUI
GLM-4-32B-0414 a obtenu de bons résultats en ingénierie de code, génération d'artefacts, appel de fonctions, réponse aux questions basées sur la recherche et génération de rapports. En particulier, sur plusieurs benchmarks tels que la génération de code ou des tâches de réponse à des questions spécifiques, GLM-4-32B-Base-0414 atteint des performances comparables à des modèles plus grands tels que GPT-4o et DeepSeek-V3-0324(671B).
Ce tutoriel utilise GLM-4-32B comme démonstration et les ressources informatiques utilisent une double carte A6000.
Exécutez en ligne :https://go.hyper.ai/j13EA
3. Déployer les modèles de la série Qwen3 à l'aide de vLLM+Open-webUI
Qwen3 est la dernière génération de grands modèles de langage de la série Qwen, fournissant des modèles denses complets et des modèles de mélange d'experts (MoE). S'appuyant sur une riche expérience de formation, Qwen3 a réalisé des progrès révolutionnaires en matière de raisonnement, de suivi des instructions, de capacités d'agent et de support multilingue. Les scénarios d’application de Qwen3 sont très larges. Il prend en charge le traitement de texte, d'image, d'audio et de vidéo et peut répondre aux besoins de création de contenu multimodal et de tâches intermodales.
Ce tutoriel utilise vLLM+Open-webUI comme démonstration, et la ressource utilisée est une seule carte RTX 4090.
Exécutez en ligne :https://go.hyper.ai/IiHHC
4. Utilisez vLLM pour charger de grands modèles pour un apprentissage en quelques étapes
Ce tutoriel est Qwen2.5-3B-Instruct pour le chargement de la quantification AWQ sur RTX 4090 à l'aide de vLLM. Pour chaque problème de test, nous récupérons un ensemble de questions similaires qui le « soutiennent » à l’aide des données de formation. En utilisant un ensemble de questions similaires, nous avons créé une conversation que nous pourrions alimenter dans notre modèle, en considérant des éléments tels que « construction » et « sujet ».
Actuellement, le site Web officiel d'HyperAI a lancé un didacticiel de déploiement en un clic pour « Utiliser vLLM pour charger de grands modèles pour un apprentissage en quelques coups ». Cliquez sur cloner pour le démarrer en un clic.
Exécutez en ligne :https://go.hyper.ai/YhwvL
Articles de la communauté
1. En combinant le modèle de langage protéique et le modèle d'inpainting d'image, le MIT et Harvard ont proposé conjointement PUPS pour réaliser la localisation des protéines dans une cellule unique.
Une équipe du MIT et de l'Université Harvard a proposé un cadre de prédiction PUPS qui combine des séquences de protéines et des images cellulaires pour prédire la localisation subcellulaire de protéines inconnues. Le cadre combine de manière innovante un modèle de langage protéique et un modèle d'inpainting d'image pour prédire la localisation des protéines, lui permettant de fusionner les capacités de généralisation des prédictions de protéines inconnues avec des prédictions spécifiques au type de cellule qui capturent la variabilité cellulaire.
Voir le rapport complet :https://go.hyper.ai/TIgUm
2. L'équipe de l'Université du Zhejiang a développé le système Earth Explorer pour explorer l'évolution du temps profond/les profils géologiques/les scénarios de recherche scientifique et permettre la recherche en sciences de la Terre dans le temps profond
Qi Jin, chercheur à temps plein à l'École des sciences de la Terre de l'Université du Zhejiang, a fait une présentation spéciale sur la « Plateforme d'innovation collaborative Deep Time Earth Crowd Intelligence » lors de la réunion annuelle académique 2025 du Comité professionnel des modèles géographiques et de l'analyse de l'information géographique de la Société géographique chinoise. Les réalisations de l'équipe ont été présentées sous trois aspects : la vue d'ensemble du système d'analyse de visualisation temporelle profonde (Earth Explorer), les progrès de la recherche et du développement et les résultats de l'application. Cet article est une transcription des points saillants du partage du professeur Qi Jin.
Voir le rapport complet :https://go.hyper.ai/6wNdI
3. Sur la base de 8 millions de données réelles, l'équipe de l'Université Cornell a utilisé des réseaux neuronaux graphiques pour prédire avec précision la survie des patients atteints de cancer du poumon et a découvert 3 sous-types mortels.
L'Université Cornell et Regeneron Pharmaceuticals aux États-Unis ont proposé le modèle de survie mixte codé par graphes (GEMS), qui utilise des réseaux neuronaux graphiques pour coder les relations complexes dans les dossiers médicaux électroniques des patients et les combine avec des modèles d'analyse de survie pour identifier les sous-phénotypes avec des caractéristiques et des résultats de survie cohérents.
Voir le rapport complet :https://go.hyper.ai/dXSH5
4. Pour la première fois, l'équipe de Columbia a proposé PXRDnet pour réaliser une analyse de bout en bout des nanocristaux et a analysé avec succès 200 nanocristaux simulés complexes.
Des chercheurs de l'Université de Columbia et de l'Université de Stanford ont proposé une méthode d'analyse de structure d'intelligence artificielle générative PXRDnet basée sur un modèle de diffusion. Même en se basant uniquement sur la formule chimique et sur des schémas de diffraction de poudre élargis et limités en taille et en informations rares, le modèle a pu résoudre avec succès 200 nanocristaux simulés de symétrie et de complexité variables, couvrant des structures des sept systèmes cristallins jusqu'à une taille de 10 Å.
Voir le rapport complet :https://go.hyper.ai/6JqUm
5. Mise à jour complète du système Gemini 2.5, Deep Think soutient et écrase OpenAI
Lors du discours d'ouverture de Google I/O 2025 qui vient de s'achever, Google a publié plusieurs mises à jour importantes, démontrant une fois de plus sa force dans la course à l'IA.
Voir le rapport complet :https://go.hyper.ai/Ct6DM
6. Le dernier discours de Jen-Hsun Huang ! NVLink Fusion, un écosystème ouvert, prend en charge l'infrastructure d'IA semi-personnalisée ; modèle de base de robot humanoïde open source
Huang Renxun a partagé plusieurs mises à jour sur Nvidia dans les domaines du centre de données, de l'IA d'entreprise et de la robotique au Computex 2025.
Voir le rapport complet :https://go.hyper.ai/VRCgw
Articles populaires de l'encyclopédie
1. DALL-E
2. Boucle homme-machine
3. Fusion de tri inverse
4. Mémoire à long terme bidirectionnelle
5. Compréhension linguistique multitâche à grande échelle
Voici des centaines de termes liés à l'IA compilés pour vous aider à comprendre « l'intelligence artificielle » ici :
Date limite de mai pour la conférence de haut niveau
RTSS 2025 :23 mai 19:59:59
SIGGRAPH 2025 : 23 mars 19:59:59
ASE 2025 :31 mai 19:59:59
Suivi unique des principales conférences universitaires sur l'IA :https://go.hyper.ai/event
Voici tout le contenu de la sélection de l'éditeur de cette semaine. Si vous souhaitez inclure hyper.ai Pour les ressources sur le site officiel, vous êtes également invités à laisser un message ou à contribuer pour nous le dire !
À la semaine prochaine !








