Command Palette
Search for a command to run...
Tutoriel En Ligne丨traitez Une Image En 9 Secondes ! Lancement Du Cadre Efficace d'édition d'images In-Context Edit

Les méthodes d’édition d’images existantes sont principalement confrontées au problème de l’équilibre difficile entre précision et efficacité. Les méthodes de réglage fin nécessitent beaucoup de ressources informatiques et des ensembles de données de haute qualité, tandis que les techniques sans formation ont du mal à répondre à la qualité de la compréhension et de l'édition des instructions. À cet égard,Une équipe de recherche de l'Université du Zhejiang et de l'Université de Harvard a lancé In-Context Edit (ICEdit), un cadre d'édition d'images basé sur des commandes.Une modification précise de l'image peut être réalisée avec seulement quelques commandes de texte, offrant davantage de possibilités de traitement d'image et de création de contenu.
In-Context Edit aborde les limites des techniques existantes à travers trois contributions clés : un cadre d'édition contextuelle, une stratégie de réglage hybride LoRA-MoE et une méthode de mise à l'échelle du temps d'inférence de filtre précoce. Par rapport aux méthodes précédentes, il utilise seulement 1% de paramètres entraînables (200M) et 0,1% de données d'entraînement (50k), mais montre une meilleure capacité de généralisation et est capable de gérer une variété de tâches d'édition d'images. Dans le même temps, comparé à Gemini et GPT-4o,Cet outil open source est non seulement moins cher et plus rapide (il ne faut qu'environ 9 secondes pour traiter une image), mais il possède également des performances très puissantes.
à l'heure actuelle,« In-Context Edit: Command-Driven Image Generation and Editing » a été lancé dans la section « Tutoriels » du site Web officiel d'HyperAI.Cliquez sur le lien ci-dessous pour découvrir le tutoriel de déploiement en un clic ⬇️
Lien du tutoriel :https://go.hyper.ai/SHowG
Essai de démonstration
1. Après avoir accédé à la page d'accueil de hyper.ai, sélectionnez la page « Tutoriel », sélectionnez « Édition contextuelle : génération et édition d'images pilotées par commandes » et cliquez sur « Exécuter ce tutoriel en ligne ».
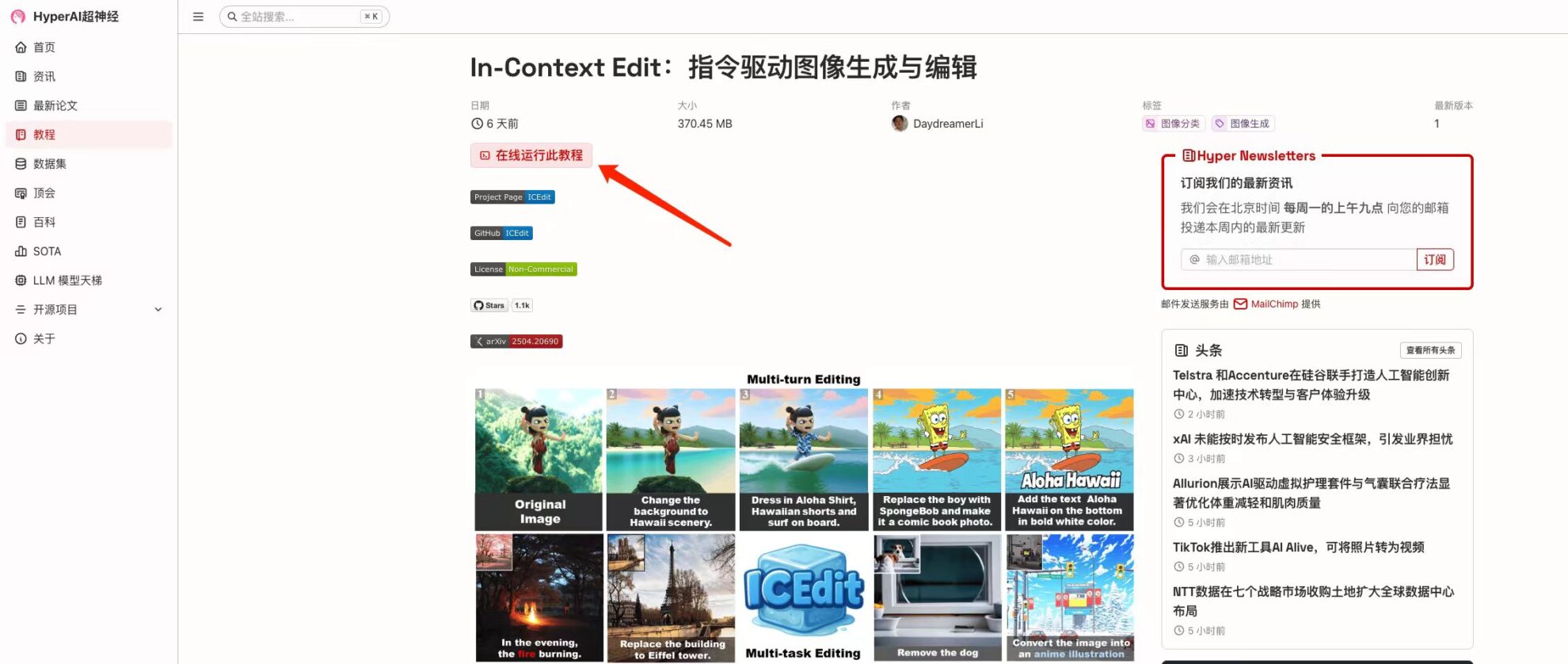
2. Une fois la page affichée, cliquez sur « Cloner » dans le coin supérieur droit pour cloner le didacticiel dans votre propre conteneur.
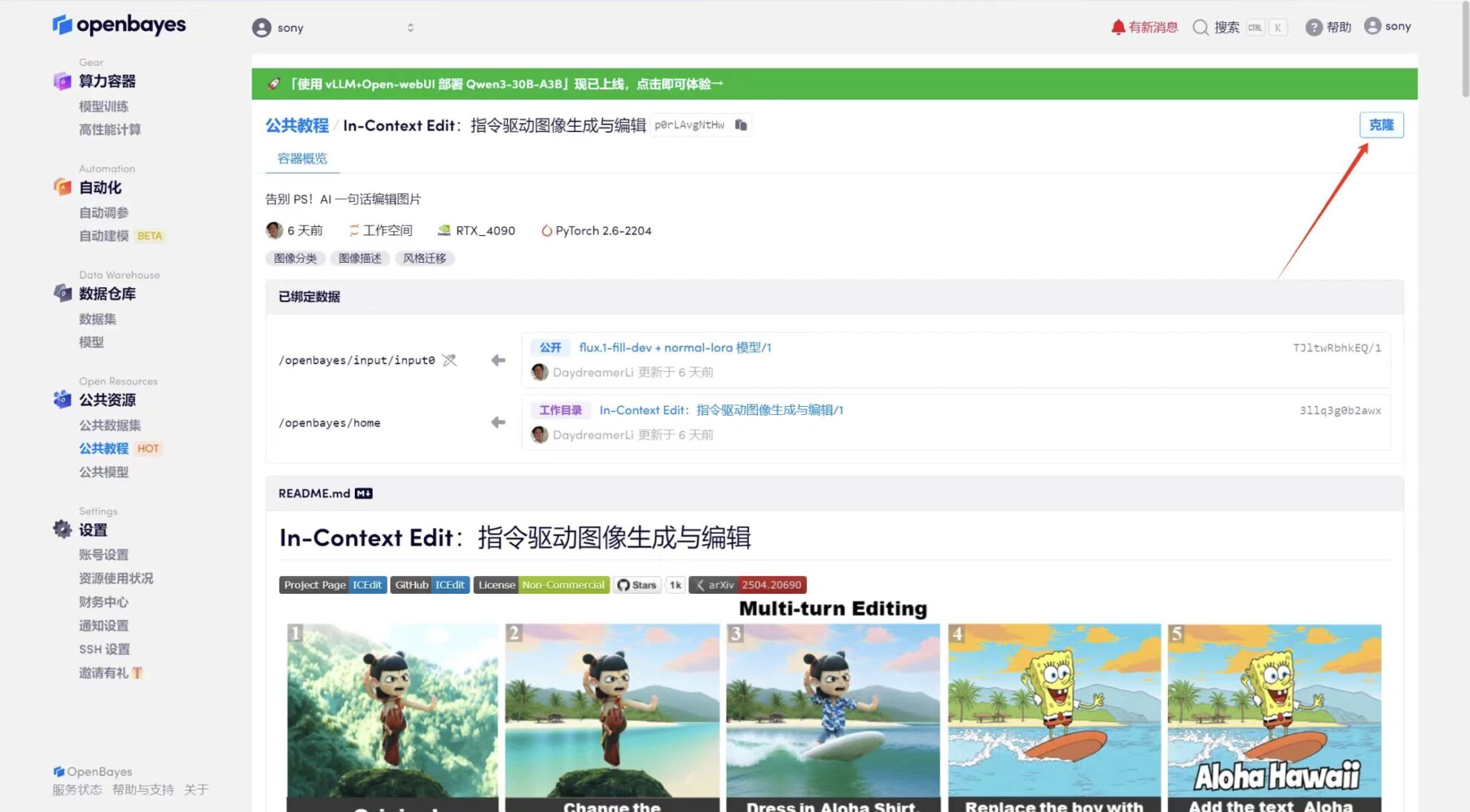
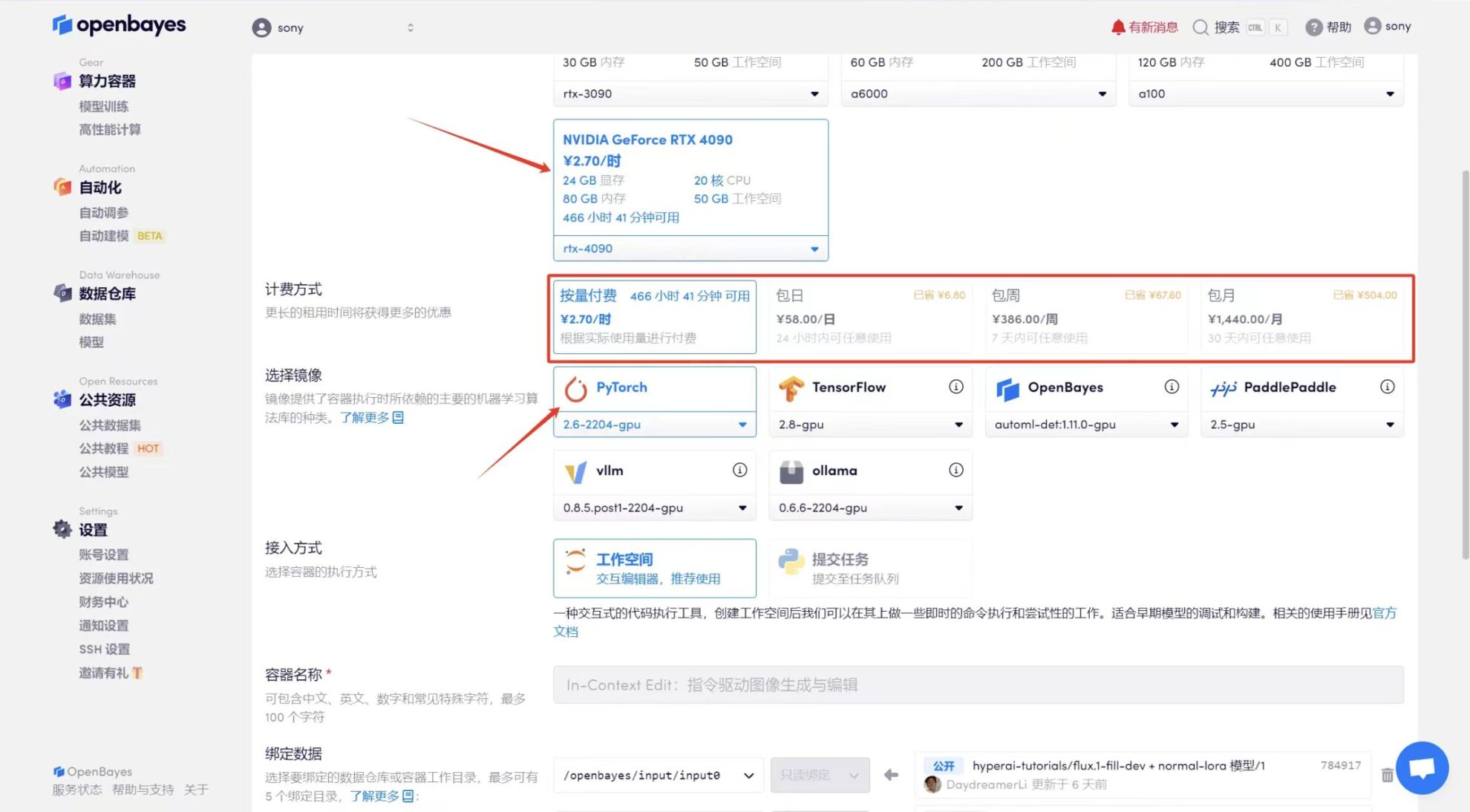
3. Sélectionnez les images « NVIDIA GeForce RTX 4090 » et « PyTorch ». La plateforme OpenBayes propose quatre méthodes de facturation. Vous pouvez choisir « Payer au fur et à mesure » ou « Quotidien/Hebdomadaire/Mensuel » selon vos besoins. Cliquez sur « Continuer ». Les nouveaux utilisateurs peuvent s'inscrire en utilisant le lien d'invitation ci-dessous pour obtenir 4 heures de RTX 4090 + 5 heures de temps CPU gratuit !
Lien d'invitation exclusif HyperAI (copier et ouvrir dans le navigateur) :
https://openbayes.com/console/signup?r=Ada0322_NR0n
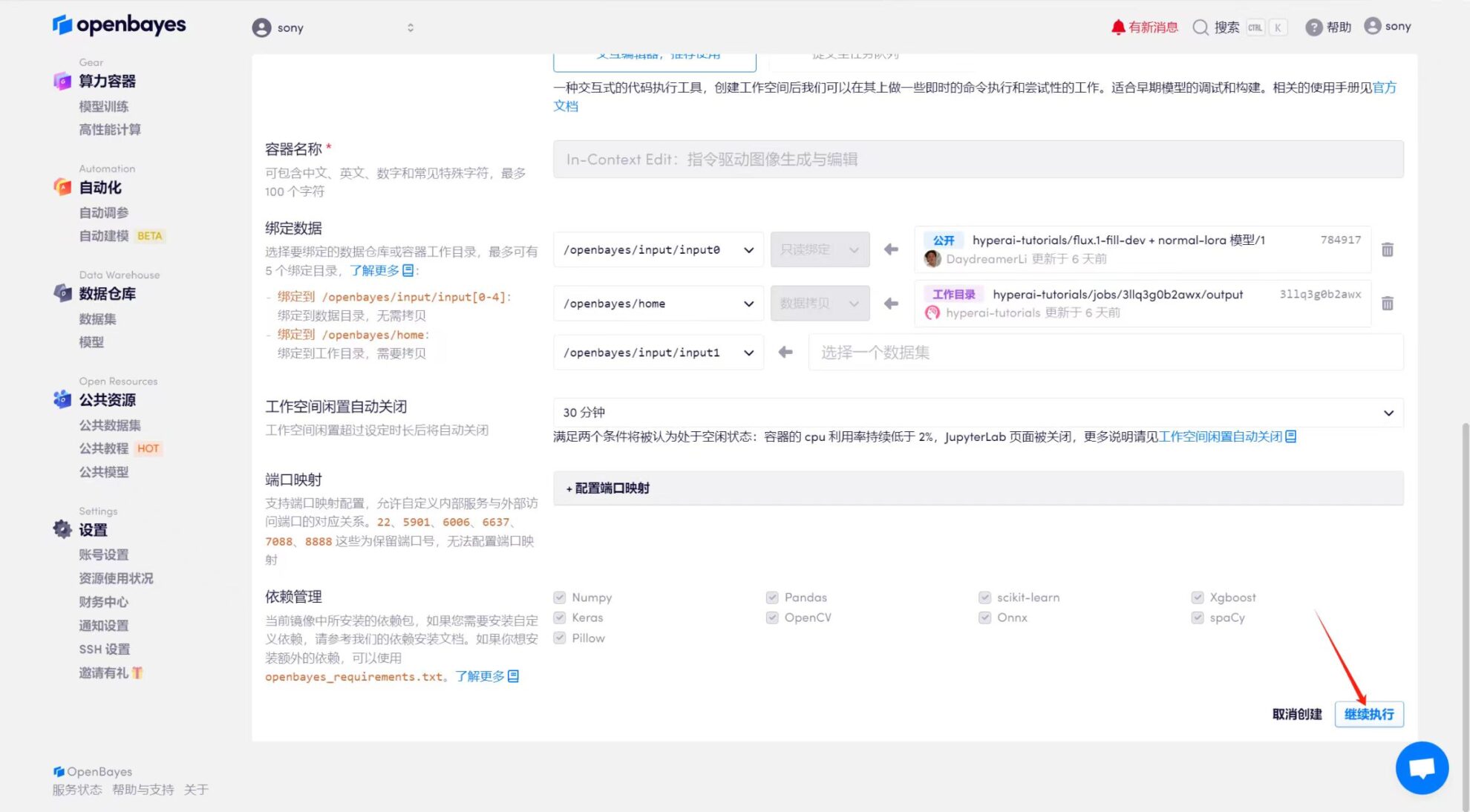
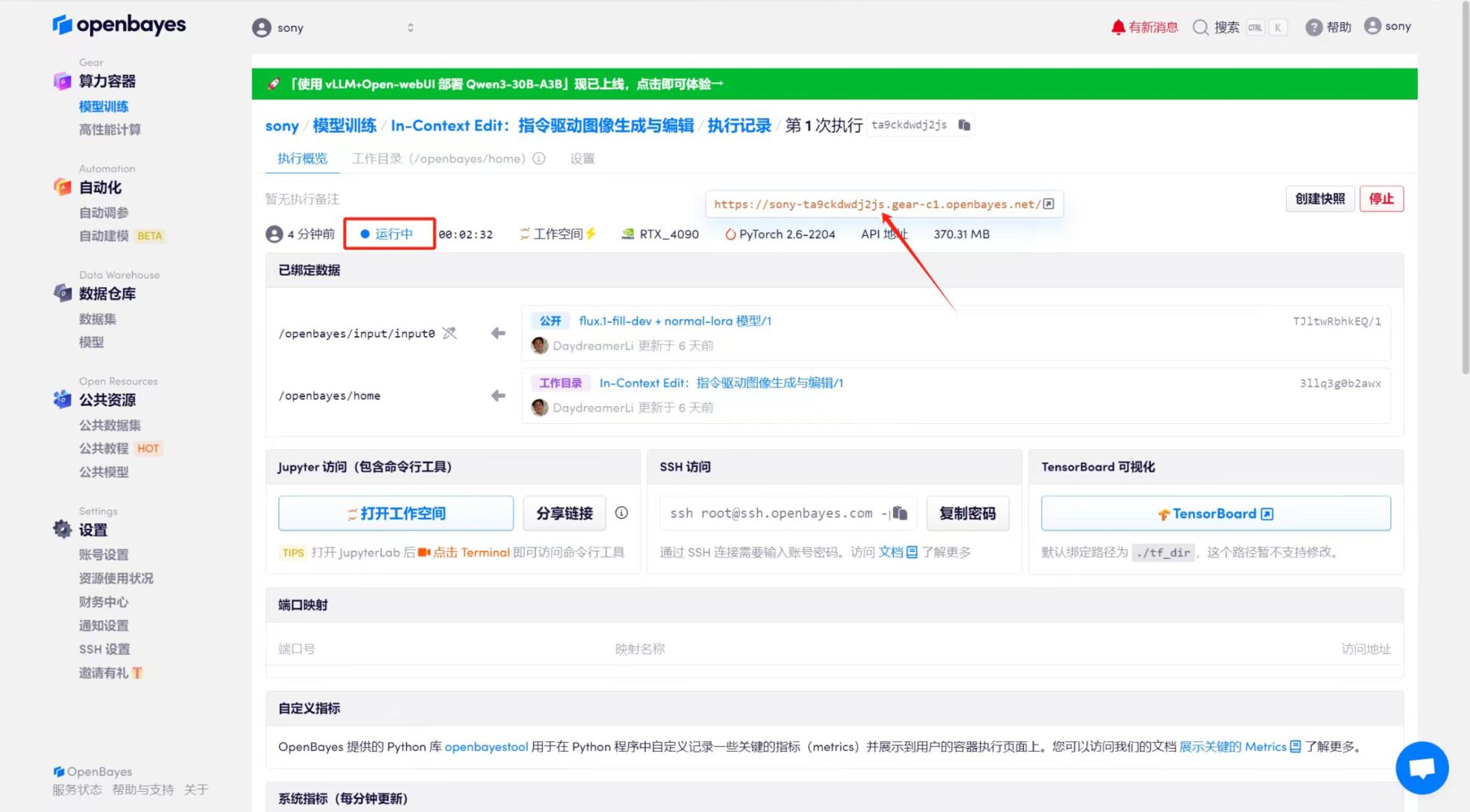
4. Attendez que les ressources soient allouées. Le premier processus de clonage prend environ 2 minutes. Lorsque le statut passe à « En cours d'exécution », cliquez sur la flèche de saut à côté de « Adresse API » pour accéder à la page de démonstration. Étant donné que le modèle est volumineux, il faut environ 3 minutes pour afficher l'interface WebUI, sinon « Bad Gateway » s'affichera. Veuillez noter que les utilisateurs doivent effectuer l'authentification par nom réel avant d'utiliser la fonction d'accès à l'adresse API.
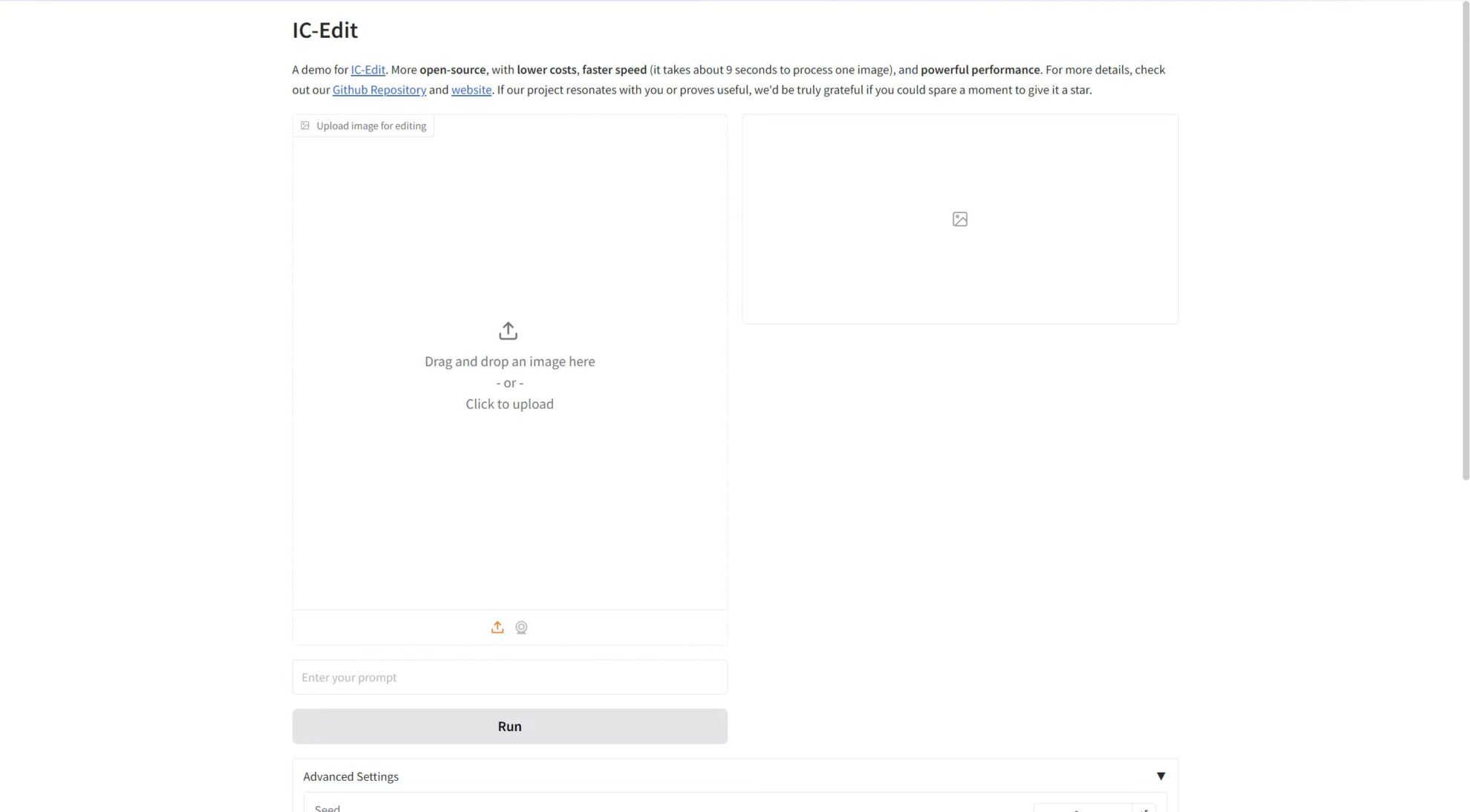
Affichage des effets
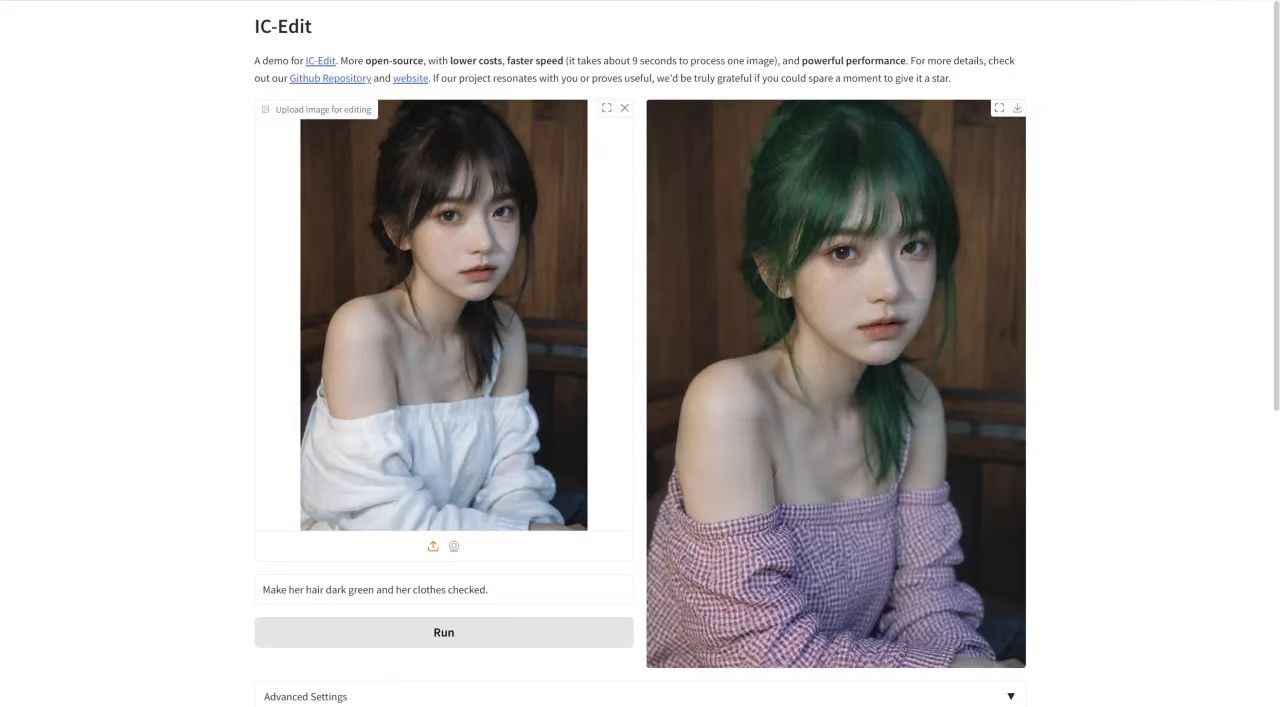
Téléchargez l'image dans « Télécharger l'image pour l'édition », puis saisissez le mot d'invite dans la zone de texte, et enfin cliquez sur « Exécuter » pour générer.
Introduction au réglage des paramètres :
* Échelle d'orientation : Utilisé pour contrôler l'influence de l'entrée conditionnelle (comme du texte ou une image) sur les résultats générés dans le modèle génératif. Des valeurs de guidage plus élevées permettront aux résultats générés de correspondre plus étroitement aux conditions d'entrée, tandis que des valeurs plus faibles conserveront plus de caractère aléatoire.
* Nombre d'étapes d'inférence : Représente le nombre d'itérations ou d'étapes du modèle dans le processus d'inférence, représentant le nombre d'étapes d'optimisation que le modèle prend pour générer le résultat. Un nombre plus élevé d’étapes produit généralement des résultats plus précis, mais peut augmenter le temps de calcul.
* Graine: Graine de nombre aléatoire, utilisée pour contrôler le caractère aléatoire du processus de génération. La même valeur Seed peut produire les mêmes résultats (à condition que les autres paramètres soient les mêmes), ce qui est très important pour reproduire les résultats.
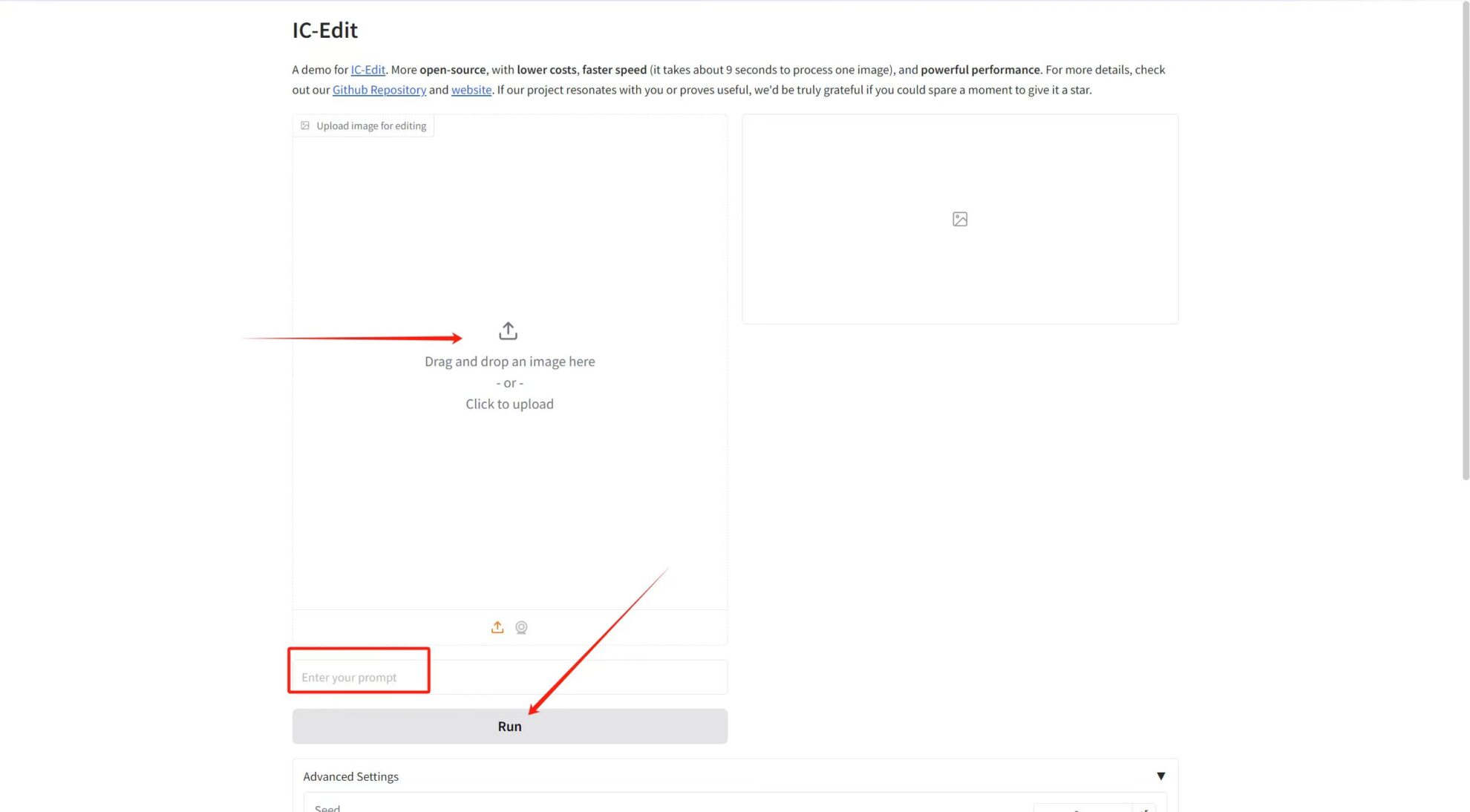
J'ai téléchargé une photo portrait avec l'invite : Rendez ses cheveux vert foncé et ses vêtements à carreaux. L'effet est comme indiqué ci-dessous~