Command Palette
Search for a command to run...
Résumé Des Tutoriels Pratiques vLLM, De La Configuration De l'environnement Au Déploiement De Grands Modèles, Documentation Chinoise Suivant Les Mises À Jour Majeures

À mesure que le modèle de langage étendu (LLM) évolue progressivement vers l'ingénierie et le déploiement à grande échelle, son efficacité de raisonnement, son utilisation des ressources et son adaptabilité matérielle deviennent des problèmes fondamentaux affectant la mise en œuvre des applications. En 2023, une équipe de recherche de l'Université de Californie à Berkeley a ouvert le vLLM, qui a introduit le mécanisme PagedAttention pour gérer efficacement le cache KV, améliorant considérablement le débit du modèle et la vitesse de réponse, et est rapidement devenu populaire dans la communauté open source. À ce jour, vLLM a dépassé les 46 000 étoiles sur GitHub et est un projet phare dans le cadre du raisonnement sur grands modèles.
27 janvier 2025L'équipe vLLM a publié la version alpha v1,L'architecture de base a été systématiquement restructurée sur la base du travail de développement effectué au cours des deux dernières années.Le cœur de cette version mise à jour v1 est une reconstruction complète de l’architecture d’exécution.L'EngineCore isolé est introduit pour se concentrer sur la logique d'exécution du modèle, adopter une intégration approfondie multi-processus, réaliser la parallélisation des tâches CPU et l'intégration approfondie multi-processus via ZeroMQ, et séparer explicitement la couche API du noyau d'inférence, ce qui améliore considérablement la stabilité du système.
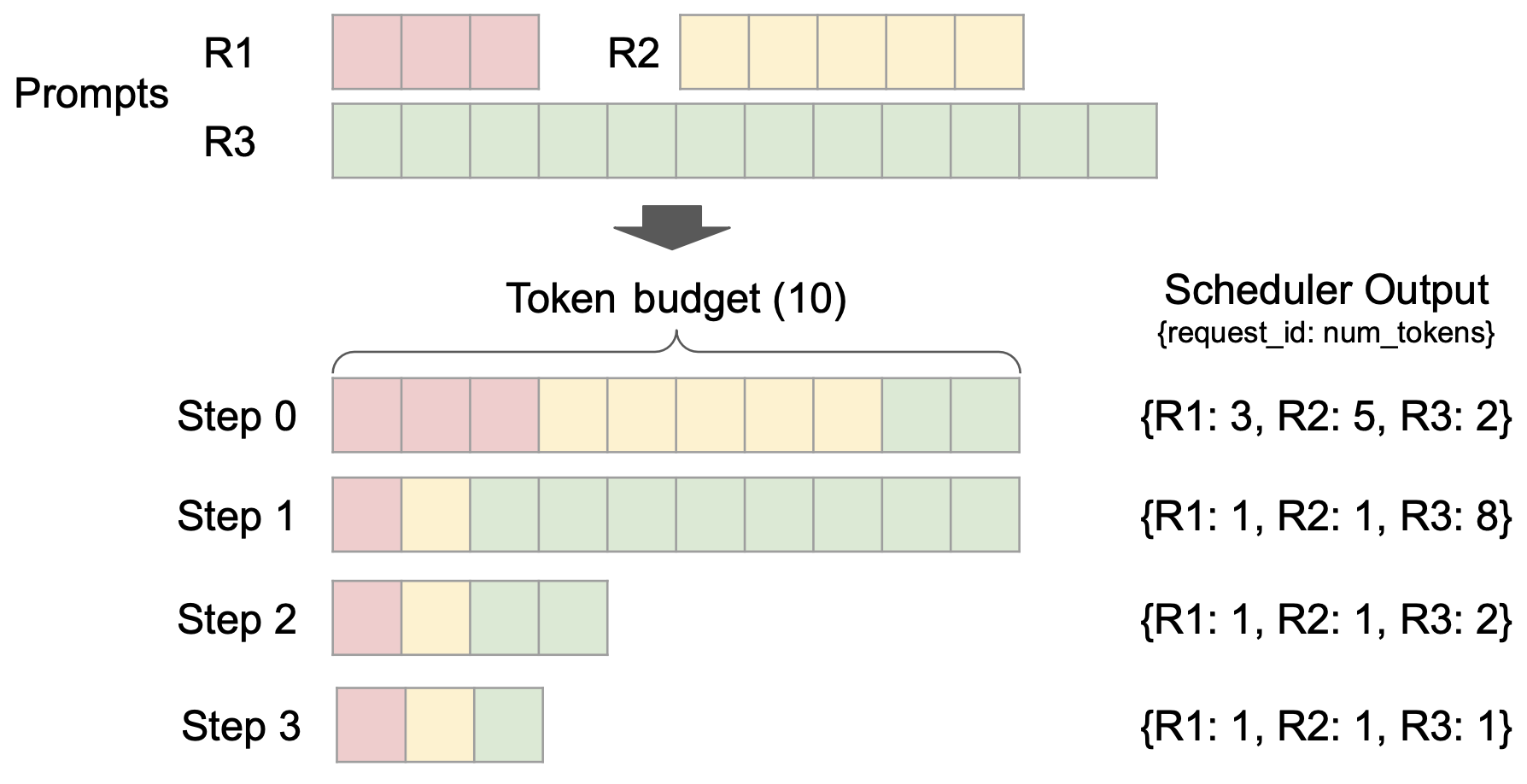
Dans le même temps, le planificateur unifié est introduit, qui présente les fonctionnalités de granularité de planification fine, de prise en charge du décodage spéculatif, de pré-remplissage en morceaux, etc.Améliorez les capacités de contrôle de la latence tout en maintenant un débit élevé.
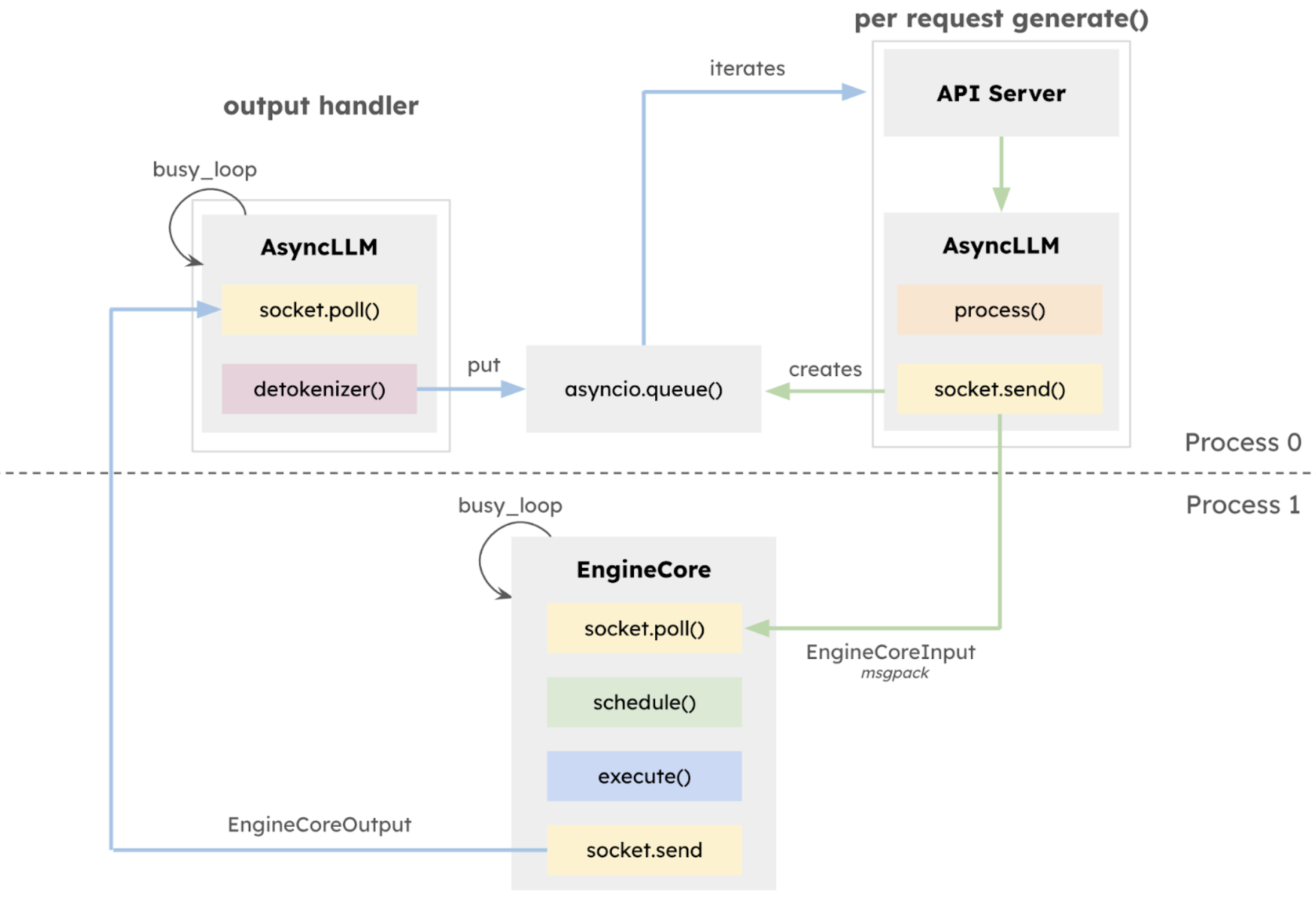
aussi,vLLM v1 adopte une conception de planification révolutionnaire sans étape.Le traitement des jetons d’entrée utilisateur et de sortie du modèle a été optimisé et la logique de planification a été simplifiée. Le planificateur prend non seulement en charge le préremplissage par blocs et la mise en cache des préfixes, mais peut également effectuer un décodage spéculatif, améliorant ainsi efficacement l'efficacité de l'inférence.
L’optimisation du mécanisme de cache est un autre point fort. vLLM v1 implémente la mise en cache des préfixes sans surcharge.Même dans les scénarios de raisonnement de texte long avec des taux de réussite de cache extrêmement faibles, il peut efficacement éviter les calculs répétés et améliorer la cohérence et l'efficacité du raisonnement.
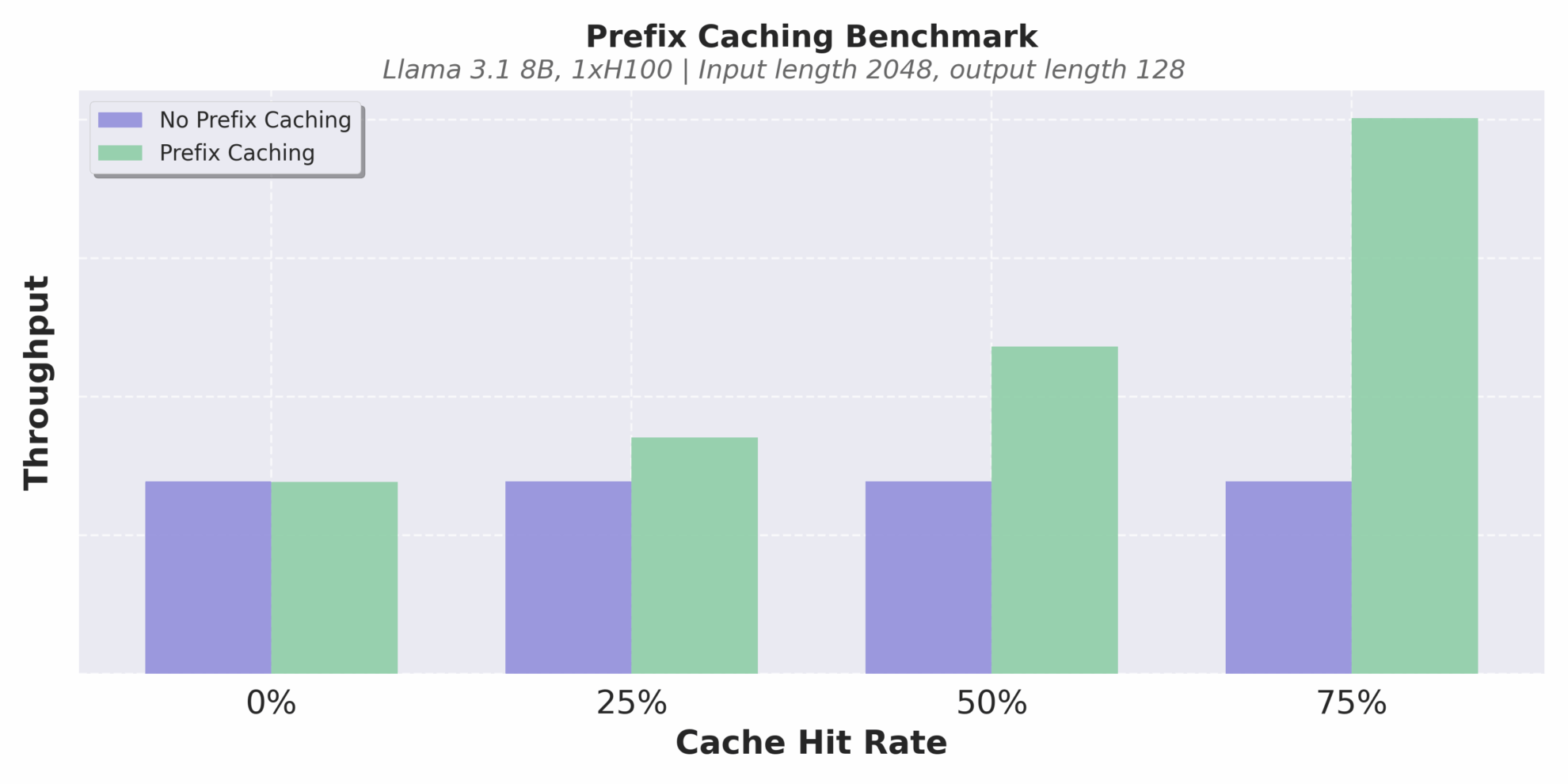
Débit à différents taux de réussite du cache
Comme le montre la figure ci-dessous, le débit de vLLM v1 est augmenté jusqu'à 1,7 fois par rapport à v0, en particulier dans le cas de QPS élevé, l'amélioration des performances est plus significative. Il convient de noter qu'en tant que version alpha, vLLM v1 est toujours en cours de développement actif et peut présenter des problèmes de stabilité et de compatibilité, mais son orientation d'évolution architecturale a clairement pointé vers des performances élevées, une maintenabilité élevée et une modularité élevée, posant ainsi une base solide pour les équipes suivantes afin de développer rapidement de nouvelles fonctionnalités.
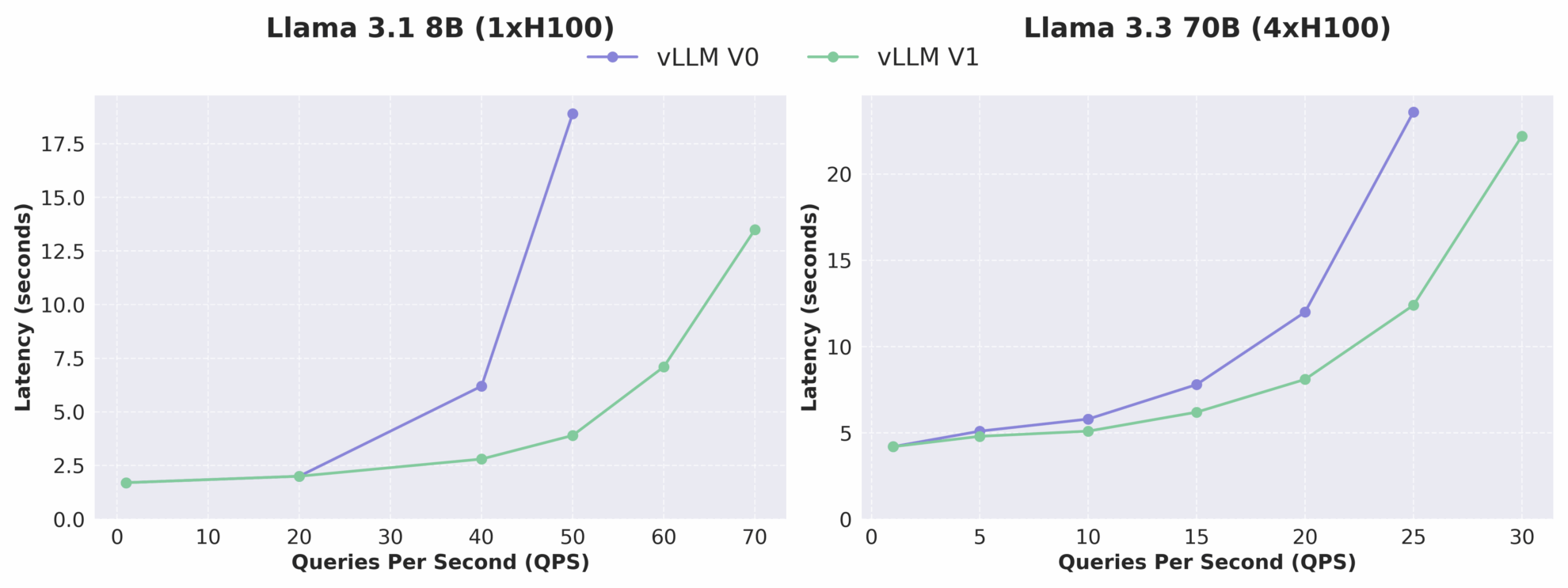
Comparaison de la relation latence-QPS entre vLLM V0 et V1
Le mois dernier, l’équipe vLLM a également effectué une mise à jour mineure de la version, axée sur l’amélioration de la compatibilité du modèle et de la stabilité du raisonnement. Cette version vLLM v0.8.5 mise à jour introduit la prise en charge dès le premier jour des modèles Qwen3 et Qwen3MoE, ajoute la configuration du noyau MoE FP8_W8A8 fusionné, corrige les bogues critiques dans les scénarios multimodaux et améliore encore la robustesse des performances dans les environnements de production.
Afin de vous aider à démarrer plus efficacement avec vLLM, l'éditeur a compilé une série de tutoriels pratiques et de cas modèles, couvrant le processus complet, de l'installation de base au déploiement de l'inférence.Aidez tout le monde à démarrer rapidement et à acquérir une compréhension approfondie. Amis intéressés, venez vivre l'expérience !
Vous trouverez plus de documents et de tutoriels vLLM chinois à l'adresse suivante :
Tutoriel de base
1 . Tutoriel de démarrage vLLM : un guide étape par étape pour les débutants
* Fonctionnement en ligne :https://go.hyper.ai/Jy22B
Ce didacticiel montre étape par étape comment configurer et exécuter vLLM, en fournissant un guide de démarrage complet pour l'installation de vLLM, l'inférence du modèle, le démarrage du serveur vLLM et comment effectuer des requêtes.
2 . Utiliser vLLM pour raisonner sur Qwen2.5
* Fonctionnement en ligne :https://go.hyper.ai/SwVEa
Ce didacticiel montre en détail comment effectuer des tâches de raisonnement sur un grand modèle de langage avec 3B paramètres, y compris le chargement du modèle, la préparation des données, l'optimisation du processus de raisonnement et l'extraction et l'évaluation des résultats.
3 . Chargement de grands modèles à l'aide de vLLM , Effectuer un apprentissage en quelques coups
* Fonctionnement en ligne :https://go.hyper.ai/OmVjM
Ce tutoriel utilise vLLM pour charger le modèle Qwen2.5-3B-Instruct-AWQ pour un apprentissage en quelques coups. Il explique en détail comment récupérer des données de formation pour obtenir des questions similaires afin de créer des dialogues, utiliser le modèle pour générer des sorties différentes, déduire des malentendus et combiner des méthodes connexes pour un classement intégré, etc., pour réaliser un processus complet depuis la préparation des données jusqu'à la soumission des résultats.
4 . Combinaison de LangChain avec vLLM , Tutoriel
* Fonctionnement en ligne :https://go.hyper.ai/Y1EbK
Ce tutoriel se concentre sur l'utilisation de LangChain avec vLLM, visant à simplifier et à accélérer le développement d'applications LLM intelligentes, couvrant une large gamme de contenu allant des paramètres de base aux applications fonctionnelles avancées.
Déploiement de grands modèles
1 . Déployer Qwen3-30B-A3B à l'aide de vLLM
* Agence émettrice :Équipe Alibaba Qwen
* Fonctionnement en ligne :https://go.hyper.ai/6Ttdh
Qwen3-235B-A22B a montré des capacités comparables à DeepSeek-R1, o1, o3-mini, Grok-3 et Gemini-2.5-Pro dans des tests de référence tels que le code, les mathématiques et les capacités générales. Il convient de mentionner que le nombre de paramètres activés du Qwen3-30B-A3B n'est que de 10% de QwQ-32B, mais ses performances sont meilleures. Même un petit modèle comme le Qwen3-4B peut égaler les performances du Qwen2.5-72B-Instruct.
2 . Déployer GLM-4-32B à l'aide de vLLM
* Agence émettrice :Zhipu AI, Université Tsinghua
* Fonctionnement en ligne :https://go.hyper.ai/HJqqO
GLM-4-32B-0414 a obtenu de bons résultats en ingénierie de code, génération d'artefacts, appel de fonctions, réponse aux questions basées sur la recherche et génération de rapports. En particulier, sur plusieurs benchmarks tels que la génération de code ou des tâches de réponse à des questions spécifiques, GLM-4-32B-Base-0414 atteint des performances comparables à des modèles plus grands tels que GPT-4o et DeepSeek-V3-0324 (671B).
3 . Déploiement à l'aide de vLLM , Aperçu de DeepCoder-14B
* Agence émettrice :Équipe Agentica, Together AI
* Fonctionnement en ligne :https://go.hyper.ai/sYwfO
Le modèle est basé sur DeepSeek-R1-Distilled-Qwen-14B et affiné via l'apprentissage par renforcement distributionnel (RL). Il dispose de 14 milliards de paramètres et a atteint une précision Pass@1 de 60,6% dans le test LiveCodeBench v5, ce qui est comparable à l'o3-mini d'OpenAI.
4 . Déploiement à l'aide de vLLM , Gemma-3-27B-IT
* Agence émettrice :Équipe MetaGPT
* Fonctionnement en ligne :https://go.hyper.ai/0rZ7j
Gemma 3 est un grand modèle multimodal capable de traiter des entrées de texte et d'image et de générer des sorties de texte. Ses variantes pré-entraînées et adaptées aux instructions fournissent des poids ouverts pour une variété de tâches de génération de texte et de compréhension d'images, notamment la réponse aux questions, le résumé et le raisonnement. Leur taille relativement petite permet leur déploiement dans des environnements aux ressources limitées. Ce tutoriel utilise gemma-3-27b-it comme démonstration pour l'inférence de modèle.
Plus d'applications
1 .OpenManus + QwQ-32B , Mise en œuvre de l'agent IA
* Agence émettrice :Équipe MetaGPT
* Fonctionnement en ligne :https://go.hyper.ai/RqNME
OpenManus est un projet open source lancé par l'équipe MetaGPT en mars 2025. Il vise à reproduire les fonctions principales de Manus et à fournir aux utilisateurs une solution d'agent intelligent qui peut être déployée localement sans code d'invitation. QwQ est le modèle de raisonnement de la série Qwen. Comparé aux modèles de réglage d'instructions traditionnels, QwQ possède des capacités de réflexion et de raisonnement et peut réaliser des améliorations significatives des performances dans les tâches en aval, en particulier les problèmes difficiles. Ce tutoriel fournit des services d'inférence pour OpenManus basés sur le modèle QwQ-32B et gpt-4o.
2 .RolmOCR OCR ultra-rapide multi-scénarios , Nouveau benchmark d'identification open source
* Agence émettrice :Reducto AI
* Fonctionnement en ligne :https://go.hyper.ai/U3HRH
RolmOCR est un outil OCR open source développé sur la base du modèle de langage visuel Qwen2.5-VL-7B. Il peut extraire du texte à partir d'images et de PDF rapidement et avec une faible utilisation de la mémoire, surpassant des outils similaires tels que olmOCR. RolmOCR ne s'appuie pas sur les métadonnées PDF, ce qui simplifie le processus et prend en charge une large gamme de types de documents, tels que les notes manuscrites et les documents universitaires.
Ce qui précède est le tutoriel lié à vLLM préparé par l'éditeur. Si vous êtes intéressé, venez le découvrir par vous-même !
Afin d'aider les utilisateurs nationaux à mieux comprendre et appliquer le vLLM,Les bénévoles de la communauté HyperAI ont collaboré pour compléter le premier document chinois vLLM, qui est désormais entièrement disponible sur hyper.ai.Le contenu couvre les principes du modèle, les didacticiels de déploiement et les interprétations de version, offrant aux développeurs chinois un parcours d'apprentissage systématique et des ressources pratiques.
Vous trouverez plus de documents et de tutoriels vLLM chinois à l'adresse suivante :https://vllm.hyper.ai








