Command Palette
Search for a command to run...
Sélectionnée Pour Le CVPR 2025, l'équipe De l'Institut De Technologie De Harbin a Proposé Un Cadre d'apprentissage multi-instance De Distillation Hiérarchique HDML Pour Traiter Rapidement Des Images De Pathologie En Tranches Complètes De Plusieurs gigapixels.

Les images pathologiques contiennent de riches informations phénotypiques et le diagnostic pathologique basé sur des images pathologiques est largement considéré comme la « référence absolue » pour le diagnostic du cancer. Parmi elles, l'image de diapositive entière (WSI) est une image de pathologie numérique haute résolution qui utilise la technologie de numérisation numérique de diapositives entières pour convertir des tranches de tissus pathologiques en images numériques jusqu'à 1 milliard de pixels. Il présente les caractéristiques d'une haute résolution, d'un affichage panoramique et d'un grand volume de données. Il s’agit de la méthode dominante de diagnostic médical et de recherche médicale actuelle.
L'apprentissage multi-instances (MIL) est l'une des principales méthodes d'analyse du WSI et a obtenu de bonnes performances dans des tâches telles que la détection de tumeurs, la quantification du microenvironnement tissulaire et la prédiction de la survie. Cependant, comme le WSI contient une énorme quantité d’informations, le raisonnement avec MIL est confronté au défi du coût élevé. Le premier problème est le problème du prétraitement des données. Le processus de recadrage et d’extraction de fonctionnalités WSI prend beaucoup de temps. Le deuxième problème est le problème des correctifs redondants. WSI contient généralement des correctifs redondants, qui contribuent le moins à la classification au niveau du sac. L’élimination des exemples non pertinents grâce aux scores d’attention est le moyen le plus simple de résoudre le problème ci-dessus. Cependant, l'algorithme MIL existant doit extraire les caractéristiques de tous les blocs recadrés avant de calculer les scores d'attention, ce qui crée sans aucun doute un problème de « poule et d'œuf ».
Sur la base de l'analyse ci-dessus, le professeur Jiang Junjun, le professeur associé Jiang Kui de l'Institut de technologie de Harbin en Chine et le professeur Zhang Yongbing de l'Institut de technologie de Harbin (Shenzhen) et d'autres ont démontré de manière innovante une solution qui peut réduire le temps de raisonnement. L'équipe a proposé un cadre d'apprentissage multi-instance par distillation hiérarchique (HDMIL), qui vise à identifier rapidement les correctifs non pertinents, permettant ainsi une classification rapide et précise. Selon les résultats expérimentaux, comparé aux méthodes avancées précédentes, HDMIL réduit le temps d'inférence de 28,6% sur trois ensembles de données publics.
Les résultats associés ont été publiés sous le titre « Classification rapide et précise des images pathologiques en gigapixels avec apprentissage multi-instance par distillation hiérarchique » et ont été sélectionnés pour CVPR 2025.
Points saillants de la recherche :
* La méthode proposée accélère le processus de raisonnement tout en améliorant les performances de classification, en atteignant un équilibre entre vitesse et performances que les méthodes traditionnelles ne peuvent pas atteindre, et fournit une inspiration pour les recherches futures sur la classification multi-instances.
*Cette méthode a démontré pour la première fois le classificateur de Kolmogorov-Arnold basé sur les polynômes de Tchebychev et l'a appliqué à la pathologie numérique, améliorant considérablement les performances de classification.
* La méthode proposée a été vérifiée par un grand nombre d'expériences et a obtenu des résultats de vérification fiables et efficaces sur 3 ensembles de données publics

Adresse du document :
https://arxiv.org/abs/2502.21130
Ensemble de données : Trois grands ensembles de données publiques vérifient l'efficacité
Pour garantir l’efficacité de l’expérience, les chercheurs ont évalué l’efficacité de la méthode proposée sur trois ensembles de données publics :
* L'ensemble de données Camelyon16 est utilisé pour la détection des métastases ganglionnaires du cancer du sein, où le rapport entre l'ensemble d'entraînement et l'ensemble de validation est divisé selon l'ensemble d'entraînement officiel 9:1, et l'ensemble de test officiel est utilisé pour tester tous les plis.
*L’ensemble de données TCGA-NSCLC a été utilisé pour la classification du cancer du poumon. L'ensemble de données a été divisé en un ensemble d'entraînement, un ensemble de validation et un ensemble de test dans un rapport de 8:1:1.
*En utilisant l'ensemble de données TCGA-BRCA pour la classification des sous-types de cancer du sein, le rapport entre l'ensemble d'entraînement, l'ensemble de validation et l'ensemble de test est également de 8:1:1
Il convient de noter que tous les WSI ont été prétraités à l'aide des outils développés par CLAM et que les expériences ont suivi une validation croisée Monte Carlo 10 fois supérieure.
Architecture du modèle : L'architecture en deux étapes implique la formation et le raisonnement, et introduit de manière innovante le classificateur Kolmogorov-Arnold
Le cadre HDMIL proposé par l’institut comporte deux parties : la formation et le raisonnement. Dans ce cadre, il existe deux composants clés : l’un est le réseau multi-instance dynamique (DMIN), qui est conçu pour classer les WSI haute résolution et identifier les instances qui ne sont pas liées à la classification au niveau du sac ; l'autre est le réseau de présélection d'instances légères (LIPN), un réseau spécialement conçu pour le WSI basse résolution.
Avant la formation, les chercheurs ont d’abord prétraité les données d’entrée en suivant la procédure standard pour l’WSI pathologique. L'ensemble de données se compose de pyramides WSI S avec des étiquettes de diapositives, chaque Xᵢ contenant une paire de WSI haute résolution (20x) et basse résolution (1,25x), désignées respectivement par Xᵢ,ₕᵣ et Xᵢ,ₗᵣ.
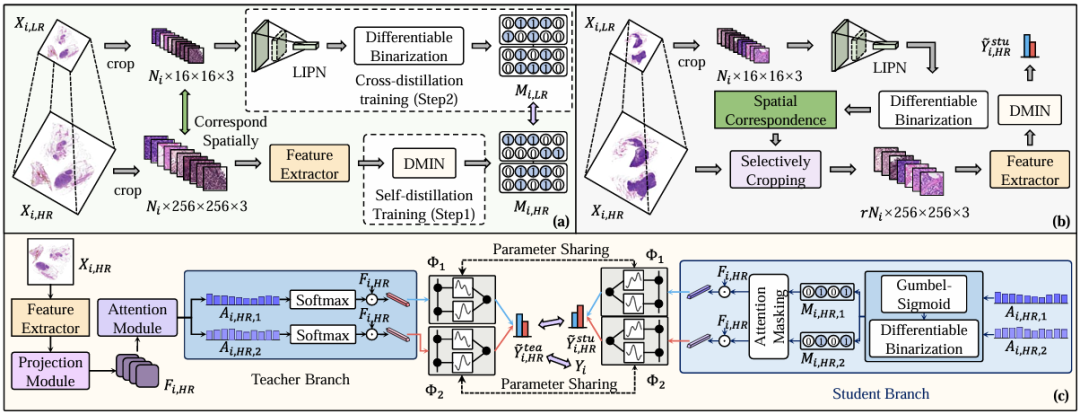
Plus précisément, la figure a montre la phase de formation, comme illustré dans la figure suivante. Les chercheurs ont d’abord adopté une stratégie d’entraînement par auto-distillation pour entraîner DMIN avec WSI haute résolution (Xᵢ,ₕᵣ), lui permettant d’effectuer une classification au niveau du sac et d’indiquer les régions non pertinentes. Bien que DMIN ait identifié avec succès les régions non pertinentes dans WSI, il n’a pas amélioré la vitesse d’inférence. Parce que DIMN doit utiliser les fonctionnalités de tous les correctifs générés par l'extracteur de fonctionnalités pour déterminer quelles instances doivent être éliminées, et l'extraction de fonctionnalités par correctif est en fait la clé pour briser le goulot d'étranglement de la vitesse d'inférence WSI.
Les chercheurs ont donc gelé le DMIN et utilisé le masque résultant pour extraire le LIPN. Comme mentionné ci-dessus, LIPN est un réseau de présélection d'instances léger adapté au WSI basse résolution. Il est formé par distillation croisée à l'aide d'un WSI basse résolution (Xᵢ,ₗᵣ) et peut rapidement identifier les régions non pertinentes dans un WSI basse résolution, indiquant ainsi indirectement les correctifs non pertinents dans un WSI haute résolution.
En termes de mise en œuvre spécifique, les chercheurs ont adopté le ResNet-50 largement utilisé comme extracteur de fonctionnalités, qui est un modèle pré-entraîné sur ImageNet, et ont utilisé une variante légère de MobileNetV4 pour le réseau de présélection LIPN. Grâce aux étapes ci-dessus, les chercheurs ont obtenu un jugement d’importance binaire (importante ou non) de chaque région à un coût de calcul très faible.
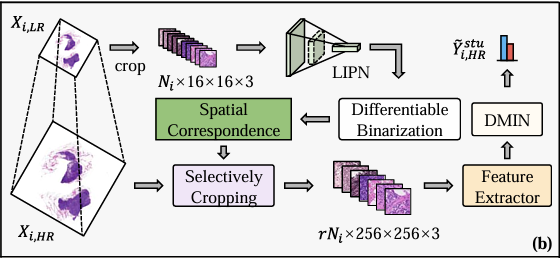
La figure c montre l'entraînement par autodistillation de DMIN sur WSI haute résolution (Xᵢ,ₕᵣ), comme indiqué ci-dessous. On peut voir que DMIN se compose de cinq modules, dont le module de projection, le module d'attention, la branche enseignant, la branche étudiant et les classificateurs CKA.

Plus précisément, tous les patchs extraits du WSI haute résolution (Xᵢ,ₕᵣ) sont d'abord entrés dans l'extracteur de fonctionnalités pré-entraîné pour générer un ensemble de fonctionnalités de niveau exemple Iᵢ,ₕᵣ, qui sont ensuite entrées dans le module de projection pour la réduction de la dimensionnalité afin d'obtenir un nouvel ensemble de fonctionnalités Fᵢ,ₕᵣ, qui sont ensuite entrées dans le module d'attention pour calculer le score d'attention non normalisé.
Dans la branche enseignant, le Fᵢ,ₕᵣ réduit est pondéré linéairement à l'aide de la matrice d'attention de chaque classe pour produire une représentation au niveau du sac pour la classification finale. Seul un sous-ensemble d'exemples avec des scores d'attention élevés est utilisé dans la branche étudiante pour calculer la représentation au niveau du sac, et les chercheurs imposent également des contraintes pour garantir que sa représentation au niveau du sac est aussi cohérente que possible avec la représentation obtenue dans la branche enseignant en utilisant toutes les instances. Grâce à cette méthode, le module d'attention est mis en œuvre pour accorder plus d'attention aux instances les plus importantes pour la classification au niveau du sac et filtrer les instances non pertinentes. Dans le même temps, le processus d’optimisation adopte également l’astuce Gumbel pour utiliser de manière sélective des instances avec des scores d’attention plus élevés pour la formation de bout en bout afin d’éviter l’apparition de problèmes non différenciables.
Enfin, pour améliorer les capacités du classificateur MIL, les chercheurs ont proposé d’utiliser un réseau de Kolmogorov-Arnold pour apprendre des fonctions d’activation non linéaires au lieu d’utiliser des fonctions d’activation fixes dans le classificateur. Et en concevant une fonction de perte hybride, les chercheurs ont atteint trois objectifs de formation pour DMIN. La première est que la branche enseignante peut classer correctement Xᵢ,ₕᵣ ; la deuxième est que les résultats de classification de l’utilisation de certaines instances dans la branche étudiante peuvent être cohérents avec les résultats de classification de l’utilisation de toutes les instances dans la branche enseignant ; et la troisième est que la proportion d’instances sélectionnées doit être contrôlable.
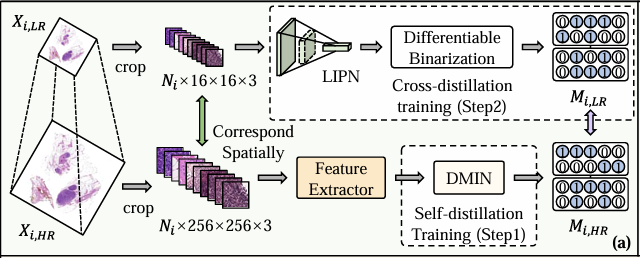
La figure b montre l’étape de raisonnement, comme indiqué ci-dessous. Le processus spécifique peut être divisé en trois étapes : la première étape consiste à recadrer tous les patchs dans le WSI basse résolution (Xᵢ,ₗᵣ), avec un total de Nᵢ ; la deuxième étape consiste à saisir ces patchs dans LIPN pour identifier les zones liées à la classification et générer Mᵢ,ₗᵣ ; la troisième étape consiste à recadrer sélectivement les patchs correspondants dans Xᵢ,ₕᵣ en fonction de Mᵢ,ₗᵣ, puis à saisir les patchs restants dans l'extracteur de fonctionnalités et DMIN, et enfin à les calculer séparément via les branches étudiantes inter-catégories pour générer les résultats de classification finaux.
Résultats de recherche : le HDMIL « simplifié » surpasse toujours les méthodes avancées existantes
Sur la base des trois ensembles de données de Camelyon16, TCGA-NSCLC et TCGA-BRCA, les chercheurs ont comparé les performances de classification de HDMIL avec 11 méthodes MIL, notamment Max-pooling, Mean-Pooling, ABMIL, CLAMSB, CLAMMB, DSMIL, TransMIL, DTFDAFS, DTFDMAS, S4MIL et MambaMIL.
Il convient de mentionner que les chercheurs ont testé différentes configurations de HDMIL, à savoir HDMIL† et HDMIL. Le premier signifie que seul DMIN est utilisé pour le raisonnement sans instance de présélection via LIPN. Les résultats spécifiques sont présentés dans la figure ci-dessous :
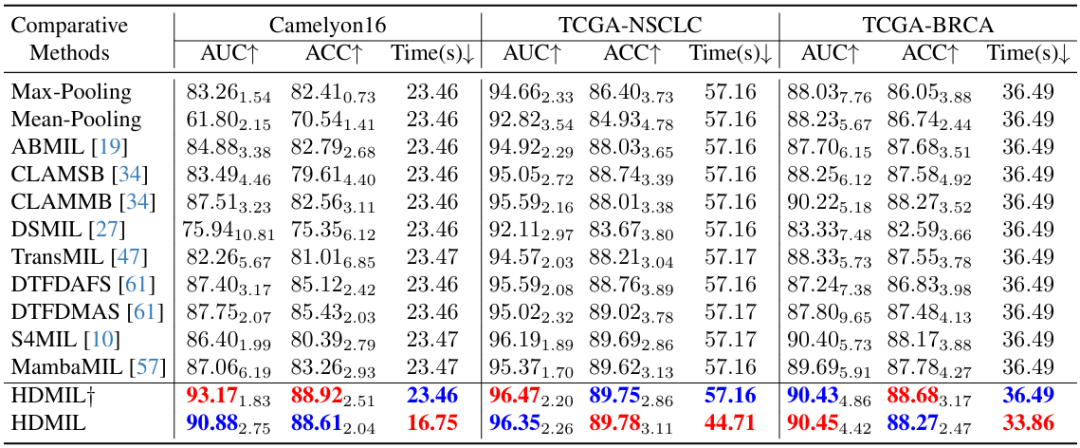
On peut constater que HDMIL† et HDMIL ont tous deux des résultats de test systématiquement meilleurs sur les trois ensembles de données que les méthodes existantes. Par exemple, sur l'ensemble de données Camelyon16, HDMIL a atteint une AUC de 90,88% et une précision de 88,61%, soit respectivement 3,13% et 3,18% de plus que la meilleure méthode précédente.
Dans le même temps, lorsque l’ensemble de données est suffisamment volumineux, HDML améliore la vitesse sans affecter les performances de classification. Par exemple, sur TCGA-NSCLC et TCGA-BRCA, les deux contiennent environ 1 000 WSI, mais l'écart de performance de test entre HDML† et HDML n'est pas important, ce qui prouve que HDML a atteint un excellent équilibre entre la vitesse d'inférence et les performances de classification.
De plus, HDMIL† est comparable aux autres méthodes existantes en termes de temps de traitement, tandis que HDMIL surpasse considérablement toutes les méthodes car HDMIL† doit traiter le même nombre de patchs haute résolution que les autres méthodes. HDMIL réduit le temps consacré au traitement des données via LIPN, réduisant ainsi considérablement le temps consacré à l'inférence par rapport aux autres méthodes sur les trois ensembles de données, obtenant des augmentations de vitesse de 28,6%, 21,8% et 7,2% respectivement.
Afin d’analyser l’impact de chaque composant, les chercheurs ont mené une expérience d’ablation pour illustrer davantage l’impact de chaque module en HDML sur les résultats de classification, comme le montre la figure ci-dessous. Les résultats de la recherche montrent que le remplacement du classificateur traditionnel basé sur des couches linéaires par le classificateur CKA proposé et l'intégration de l'autodistillation dans la formation DMIN améliorent considérablement les performances de classification.

En général, la proposition HDMIL est sans aucun doute une idée et une tentative nouvelle. La faisabilité de son idée a été prouvée par un grand nombre d’expériences. Il fournit une nouvelle méthode d'analyse d'images pathologiques, notamment WSI, en utilisant la méthode MIL, et accélère le développement vigoureux de la pathologie numérique.
La pathologie numérique prospère grâce à l'IA
Ces dernières années, le développement vigoureux de la pathologie numérique a conduit à une nouvelle série d’avancées en médecine et en biologie, jouant notamment un rôle important dans la lutte contre le cancer, l’un des plus grands ennemis de l’humanité. Il convient de mentionner que la proposition HDMIL n’est pas la première tentative de l’équipe de l’Institut de technologie de Harbin dans ce domaine.
L'année dernière, le CVPR 2024 comprenait une étude intitulée « Coloration immunohistochimique virtuelle pour les images histologiques assistées par un apprentissage faiblement supervisé ». L'article mentionne une méthode d'apprentissage faiblement supervisée appelée confusion-GAN pour la coloration par immunohistochimie virtuelle (IHC), qui peut convertir les images H&E en images IHC, résolvant ainsi le coût fastidieux et coûteux des méthodes traditionnelles de coloration IHC.

Adresse de l'article : https://openaccess.thecvf.com/content/CVPR2024/papers/Li_Virtual_Immunohistochemistry_Staining_for_Histological_Images_Assisted_by_Weakly-supervised_Learning_CVPR_2024_paper.pdf
En plus des mêmes auteurs que la recherche mentionnée ci-dessus, cet article a également été co-écrit par le professeur Jiang Junjun et le professeur Zhang Yongbing, ce qui confirme davantage la profonde culture et l'accumulation de l'Institut de technologie de Harbin dans ce domaine.
Bien entendu, en tant que deux auteurs correspondants de l’article, le professeur Jiang Junjun et le professeur Zhang Yongbing méritent également une mention spéciale. Le professeur Jiang Junjun est actuellement professeur titulaire et directeur de doctorat à l'École d'informatique de l'Institut de technologie de Harbin, vice-doyen de l'École d'intelligence artificielle et directeur adjoint du Centre de recherche sur l'interface intelligente et l'interaction homme-machine. Il a été sélectionné pour le programme national des jeunes talents et est également le responsable académique du « Young Scientist Studio » de l'Institut de technologie de Harbin. Ses axes de recherche portent sur le traitement d'images, la vision par ordinateur, l'apprentissage profond (la recherche porte sur les grands modèles et le traitement d'images, les systèmes autonomes multimodaux sans pilote, l'intelligence artificielle générative, etc.) et d'autres domaines.
Le professeur Zhang Yongbing est actuellement professeur et directeur de doctorat à l'École d'informatique de l'Institut de technologie de Harbin. Ses principaux domaines de recherche comprennent la vision par ordinateur, le traitement d’images biomédicales et l’imagerie par ordinateur. En outre, le professeur Zhang Yongbing occupe également plusieurs postes. Il est membre de nombreuses associations nationales et étrangères renommées, notamment la China Computer Society, la China Artificial Intelligence Society, l'IEEE, la SPIE, l'OSA, etc. Il a publié plus de 100 articles lors de conférences internationales de premier plan sur l'intelligence artificielle et a obtenu plus de 50 brevets d'invention. Actuellement, les principales recherches du professeur Zhang Yongbing portent sur l’exploration de l’application de l’intelligence artificielle et de la vision par ordinateur dans les domaines de la médecine de la vie et de la santé médicale.
Outre l'Institut de technologie de Harbin, de plus en plus d'universités et de laboratoires s'intéressent également au domaine de la pathologie numérique et y contribuent par leurs propres efforts. Par exemple, une équipe de l'Université de technologie d'Eindhoven aux Pays-Bas a publié une étude intitulée « A Spatially-Aware Multiple Instance Learning Framework for Digital Pathology », qui proposait un modèle appelé Global ABMIL (GABMIL). Ce modèle est une version améliorée du modèle traditionnel ABMIL. Il peut intégrer des informations spatiales dans le vecteur d'intégration via le module de mélange d'informations spatiales, puis utiliser le réseau ABMIL pour prédire l'étiquette de la tranche, évitant ainsi la méthode MIL traditionnelle qui ignore souvent un facteur clé dans le diagnostic pathologique : les informations d'interaction spatiale entre les blocs d'images.
Adresse de l'article : https://arxiv.org/abs/2504.17379
En bref, l’intégration de l’intelligence artificielle et de la médecine traditionnelle est irréversible et tout le monde peut en bénéficier. Il est indéniable que ce sont ces « explorateurs » engagés à l’avant-garde de la science qui nous donnent l’opportunité de profiter des applications de l’intégration croisée de l’intelligence artificielle et de la médecine. Bien sûr, avec une culture approfondie à long terme, il y a des raisons de croire que l'équipe de l'Institut de technologie de Harbin continuera à s'enraciner ici, accélérant ainsi le développement de l'ensemble du domaine.








