Command Palette
Search for a command to run...
EasyControl, Un Outil Permettant De Générer Des Peintures De Style Ghibli, Se Lance En Un Clic ; Une Seule Image Peut Être Transformée En Modèle 3D En Quelques Secondes, TripoSG Révolutionne La Génération d'actifs 3D

Les images de style Ghibli ont récemment pris d’assaut les réseaux sociaux. Lorsque les gens ajoutent les filtres de style animation de Hayao Miyazaki aux films ou aux séries télévisées, c'est comme s'ils étaient transportés dans un monde de conte de fées plein de fantaisie. Cependant, pour de nombreux utilisateurs qui souhaitent créer eux-mêmes des images de style Ghibli, les modèles de génération existants présentent souvent des problèmes tels qu'un fonctionnement complexe, un seuil d'utilisation élevé ou des effets de génération insatisfaisants.
EasyControl réduit considérablement le seuil de création grâce à sa technologie avancée et à son interface simple et facile à utiliser.Il introduit une injection conditionnelle légère Module LoRA, paradigme de formation tenant compte de la localisation, etMécanisme d'attention causaleet Technologie de cache KV, améliorant considérablement la compatibilité des modèles, prenant en charge la fonctionnalité plug-and-play et le contrôle de style non destructif.
à l'heure actuelle,HyperIALe tutoriel « EasyControl Ghibli-style image generation Demo » a été lancé.La démonstration utilise le modèle de contrôle stylisé Img2Img pour convertir un portrait enLe style MiyazakiŒuvres d'art, venez les essayer~
Utilisation en ligne :https://go.hyper.ai/jWm9j
Du 21 au 25 avril, le site officiel de hyper.ai est mis à jour :
* Ensembles de données publiques de haute qualité : 10
* Tutoriels de haute qualité : 12
* Sélection d'articles communautaires : 4 articles
* Entrées d'encyclopédie populaire : 5
* Principales conférences avec date limite en avril : 1
Visitez le site officiel :hyper.ai
Ensembles de données publiques sélectionnés
1. Ensemble de données d'images aériennes du trafic espagnol
L'ensemble de données contient 15 070 images capturées par des véhicules aériens sans pilote (UAV) et couvre une variété de scénarios de circulation, notamment les routes régionales, les intersections urbaines, les routes rurales et différents types de ronds-points. Il y a 155 328 objets annotés dans les images, dont 137 602 sont des voitures et 17 726 sont des motos. Ces images sont Format YOLOLe stockage est pratique pour former des algorithmes de vision artificielle basés sur des réseaux neuronaux convolutifs.
Utilisation directe :https://go.hyper.ai/VJoXE

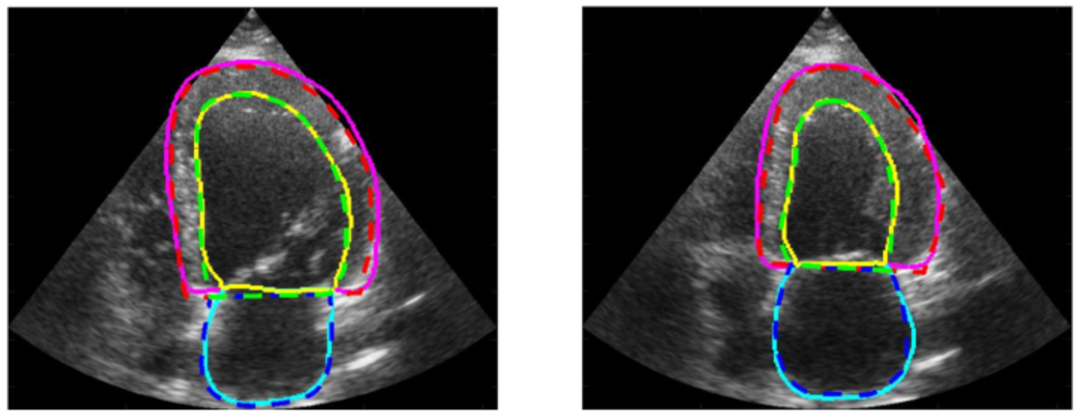
2. Ensemble de données d'images d'échographie cardiaque CAMUS
L'ensemble de données contient des séquences de vues apicales 2D à quatre et deux chambres de 500 patients, collectées au CHU de Saint-Étienne en France, et entièrement anonymisées pour garantir la confidentialité des patients et la conformité des données. Chaque image a été annotée avec précision par du personnel médical professionnel, couvrant les informations de contour de l'endocarde ventriculaire gauche, de l'épicarde ventriculaire gauche et de l'oreillette gauche. Ces annotations détaillées fournissent aux chercheurs de riches ressources de formation et de vérification.
Utilisation directe :https://go.hyper.ai/iYtn2
3. Navires/navires sur les images aériennes
Cet ensemble de données contient 26,9 000 images avec uniquement la catégorie d'image « navire ». Ces images sont soigneusement annotées spécifiquement pour la détection des navires. Les annotations de la zone de délimitation sont présentées au format YOLO, ce qui permet de détecter avec précision et efficacité les navires dans les images.
Utilisation directe :https://go.hyper.ai/s03Tk

4. Ensemble de données de photographie aérienne de paysage urbain SkyCity Aerial City Landscape
Cet ensemble de données est un ensemble de données sélectionné pour la classification des paysages aériens, avec un total de 8 000 images, dont 10 catégories différentes, chaque catégorie contient 800 images de haute qualité avec une résolution de 256 × 256 pixels. Cet ensemble de données rassemble des paysages urbains issus des ensembles de données AID et NWPU-Resisc45 accessibles au public, dans le but de faciliter l'analyse du paysage urbain.
Utilisation directe :https://go.hyper.ai/eCRdN

5. 302 ensembles de données sur les cas de maladies rares
L'ensemble de données contient 302 maladies rares, avec 1 à 9 maladies rares sélectionnées aléatoirement dans chaque catégorie. Ces maladies rares ont été sélectionnées parmi plus de 7 000 maladies rares de 33 types dans la base de données Orphanet, une base de données complète sur les maladies rares cofinancée par la Commission européenne.
Utilisation directe :https://go.hyper.ai/LwqME
6. Ensemble de données de test de structure d'ARN DRfold2
Cet ensemble de données est un ensemble de données de test indépendant construit pour évaluer objectivement les performances de DRfold2 dans cette étude. Il contient 28 structures d'ARN avec une longueur de séquence inférieure à 400 nt et provient des 3 catégories suivantes : les dernières séquences cibles de RNA-Puzzles ; Séquences cibles d'ARN dans la compétition CASP15 ; et les dernières structures d'ARN publiées dans la base de données Protein Data Bank (PDB) au 1er août 2024.
Utilisation directe :https://go.hyper.ai/shkp6
7. Ensemble de données d'images médicales cardiaques HMC-QU
L'ensemble de données contient des enregistrements échocardiographiques (écho) bidimensionnels des vues apicales à quatre chambres (A4C) et apicales à deux chambres (A2C) acquises en 2018 et 2019. Les enregistrements ont été acquis par des équipements de différents fabricants (par exemple, des échographes Phillips et GE Vivid) avec une résolution temporelle de 25 images/s et des résolutions spatiales allant de 422 × 636 à 768 × 1024 pixels.
Utilisation directe :https://go.hyper.ai/gQN8a
8. Ensemble de données de raisonnement Reasoning-v1-20m
Reasoning-v1-20m contient environ 20 millions de traces de raisonnement, couvrant des problèmes complexes dans de multiples domaines tels que les mathématiques, la programmation et les sciences. Cet ensemble de données vise à aider le modèle à apprendre une logique de raisonnement complexe et à améliorer ses performances dans les tâches de raisonnement en plusieurs étapes en fournissant de riches exemples du processus de raisonnement.
Utilisation directe :https://go.hyper.ai/c2RqP
9. II-Thought-RL-v0 Ensemble de données de réponses aux questions multitâches
II-Thought-RL-v0 est un ensemble de données multitâches à grande échelle conçu pour l'apprentissage par renforcement et la résolution de problèmes. Il contient des paires questions-réponses de haute qualité qui ont été strictement filtrées en plusieurs étapes, couvrant plusieurs domaines tels que les mathématiques, la programmation et les sciences. Les paires de questions de l'ensemble de données proviennent non seulement d'ensembles de données publics, mais contiennent également des paires de questions personnalisées de haute qualité pour garantir la diversité et la praticité des données.
Utilisation directe :https://go.hyper.ai/9eSSq
L'ensemble de données contient environ 1,4 million d'entrées de données, couvrant une variété de types de questions, notamment les mathématiques, le code, les questions-réponses scientifiques et le chat général. Ces données ont été soigneusement sélectionnées, dédupliquées sémantiquement et strictement nettoyées pour garantir la haute qualité et le défi des données. Chaque entrée de l'ensemble de données contient des traces de réflexion riches, qui non seulement fournissent au modèle des exemples du processus de raisonnement, mais aident également le modèle à mieux comprendre et à générer des solutions à des tâches de raisonnement complexes.
Utilisation directe :https://go.hyper.ai/2PSxR
Tutoriels publics sélectionnés
1. YOLOE : tout voir en temps réel
YOLOE est un nouveau modèle visuel en temps réel proposé par une équipe de recherche de l'Université Tsinghua en 2025, qui vise à atteindre l'objectif de « tout voir en temps réel ». Il hérite des caractéristiques en temps réel et efficaces de la série de modèles YOLO et, sur cette base, intègre en profondeur les capacités d'apprentissage zéro coup et d'invite multimodale, et peut prendre en charge la détection et la segmentation de cibles dans plusieurs scénarios tels que le texte, la vision et l'invite silencieuse.
Les modèles et dépendances pertinents de ce projet ont été déployés. Après avoir démarré le conteneur, cliquez sur l’adresse API pour accéder à l’interface Web.
Exécutez en ligne :https://go.hyper.ai/rOIS1

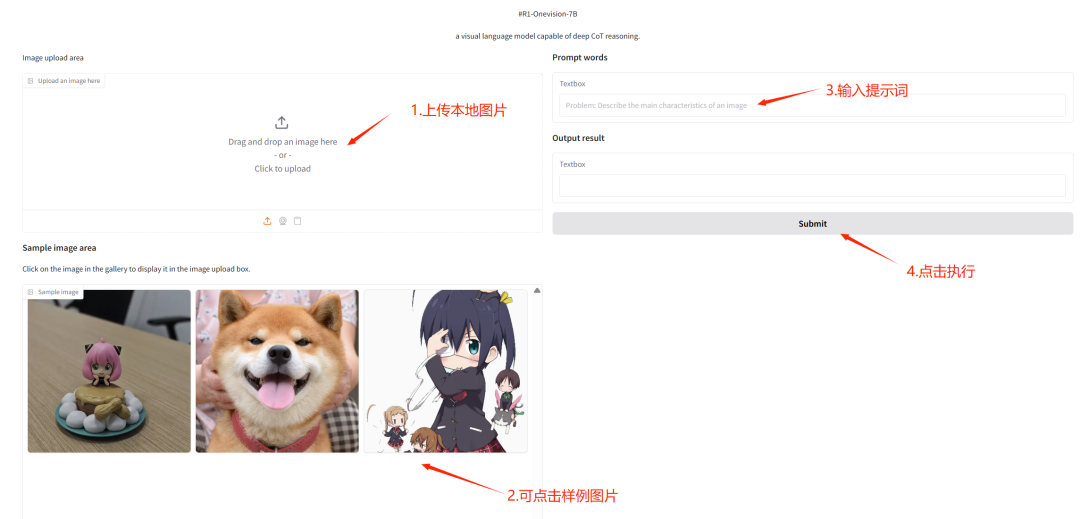
2. Déploiement en un clic de R1-OneVision
R1-OneVision est un grand modèle de raisonnement multimodal publié par une équipe de l'Université du Zhejiang. Le modèle est affiné sur la base de Qwen2.5-VL sur l'ensemble de données R1-Onevision. Il est efficace pour gérer des tâches de raisonnement visuel complexes et intégrer de manière transparente des données visuelles et textuelles. Il fonctionne bien dans des domaines tels que les mathématiques, les sciences, la compréhension approfondie des images et le raisonnement logique, et peut servir d'assistant IA puissant pour résoudre divers problèmes.
Ce tutoriel utilise R1-Onevision-7B comme démonstration et la ressource informatique utilise RTX 4090. Après avoir démarré le conteneur, cliquez sur l'adresse API pour accéder à l'interface Web.
Exécutez en ligne :https://go.hyper.ai/7I2pi
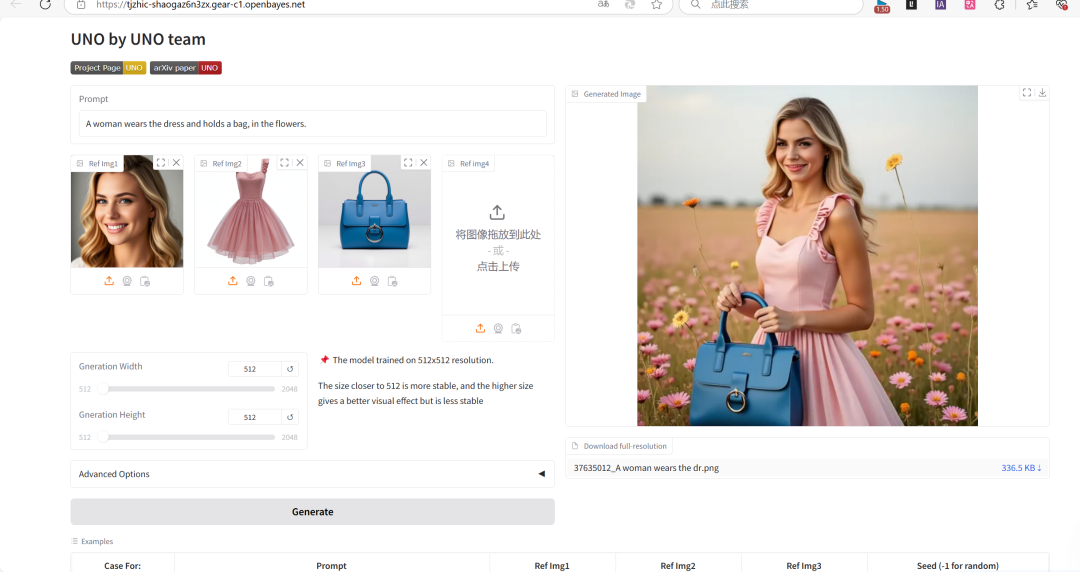
3. UNO : Génération d'images personnalisées universelles
Le projet UNO peut prendre en charge la génération d'images mono-sujets et multi-sujets, unifiant plusieurs tâches avec un seul modèle et démontrant de fortes capacités de généralisation.
Ce projet est basé sur FLUX.1-dev-fp 8 et peut rapidement reconnaître du texte et générer des images basées sur des descriptions de texte.
Exécutez en ligne :https://go.hyper.ai/r8JZo
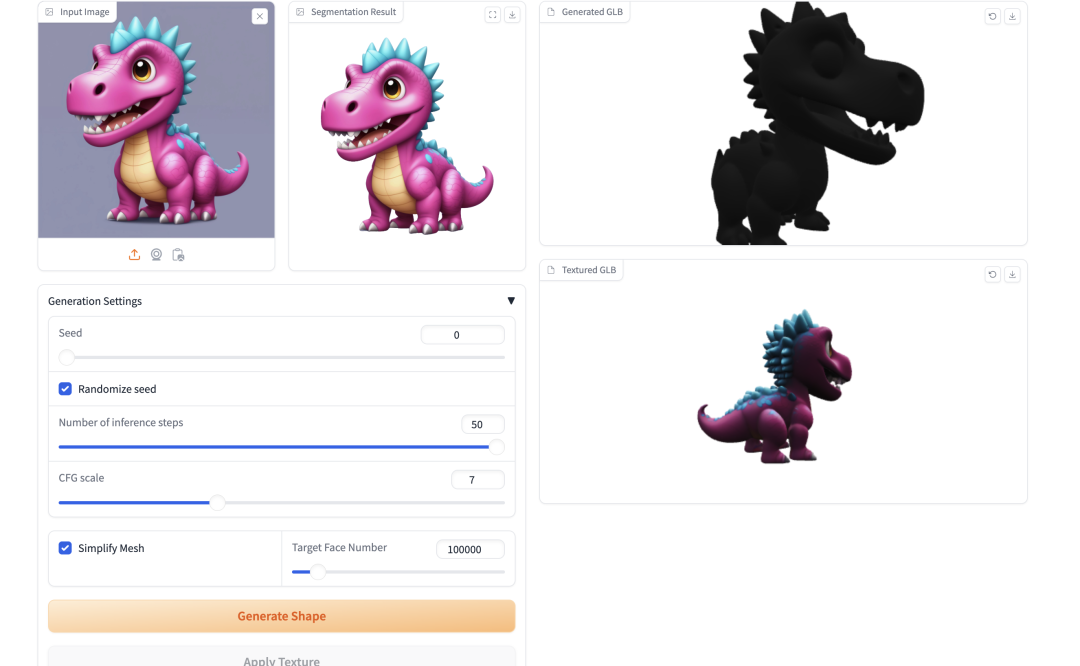
4. TripoSG : Transformez une seule image en 3D haute fidélité en quelques secondes
TripoSG est un modèle de base génératif d'image en 3D avancé avec une haute fidélité, une haute qualité et une grande généralité. Il s'appuie sur des transformateurs redressés à grande échelle, une formation supervisée hybride et des ensembles de données de haute qualité pour atteindre des performances de pointe en matière de génération de formes 3D.
Les modèles et dépendances pertinents de ce projet ont été déployés. Après avoir démarré le conteneur, cliquez sur l’adresse API pour accéder à l’interface Web.
Exécutez en ligne :https://go.hyper.ai/rcWwu
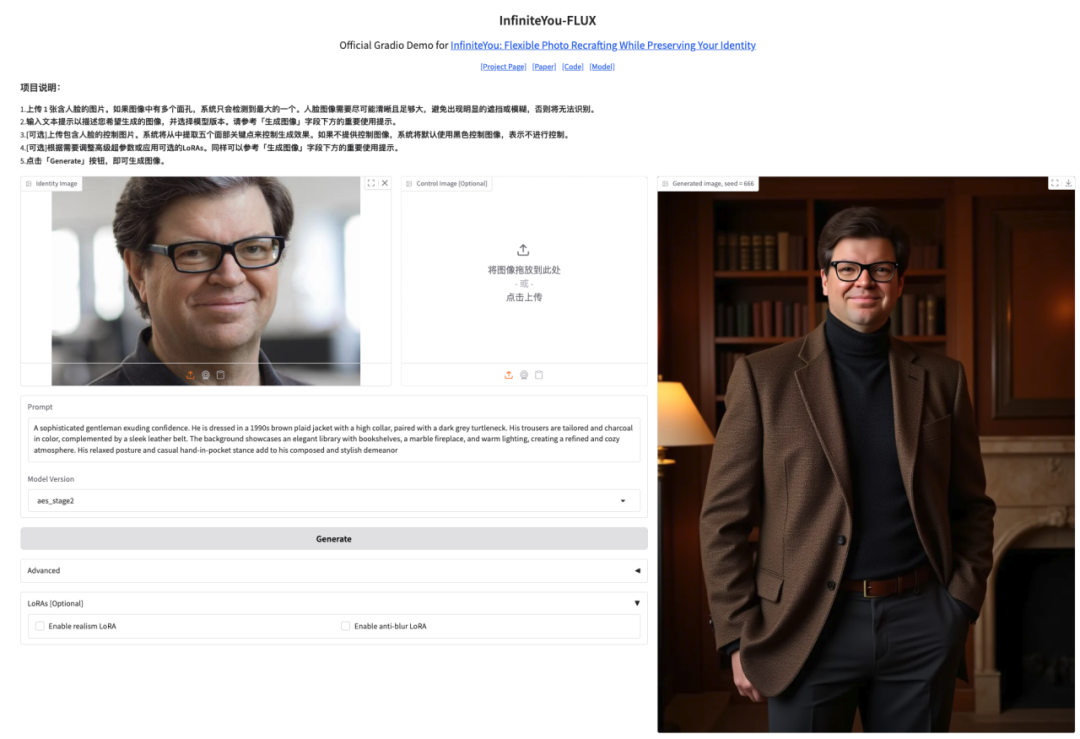
5. Démonstration de génération d'images haute fidélité InfiniteYou
InfiniteYou, abrégé en InfU, est un framework de génération d'images préservant l'identité basé sur des transformateurs de diffusion (tels que FLUX) lancé par l'équipe de création intelligente de ByteDance en 2025. Grâce à une technologie de pointe, il est capable de maintenir la cohérence de l'identité de la personne tout en générant des images, résolvant les lacunes des méthodes existantes en matière de similarité d'identité, d'alignement texte-image et de qualité de génération.
Ce tutoriel utilise InfiniteYou-FLUX v1.0 comme démonstration et la ressource de puissance de calcul est A6000. Cliquez sur le lien ci-dessous pour cloner rapidement le modèle.
Exécutez en ligne :https://go.hyper.ai/K5Yl5
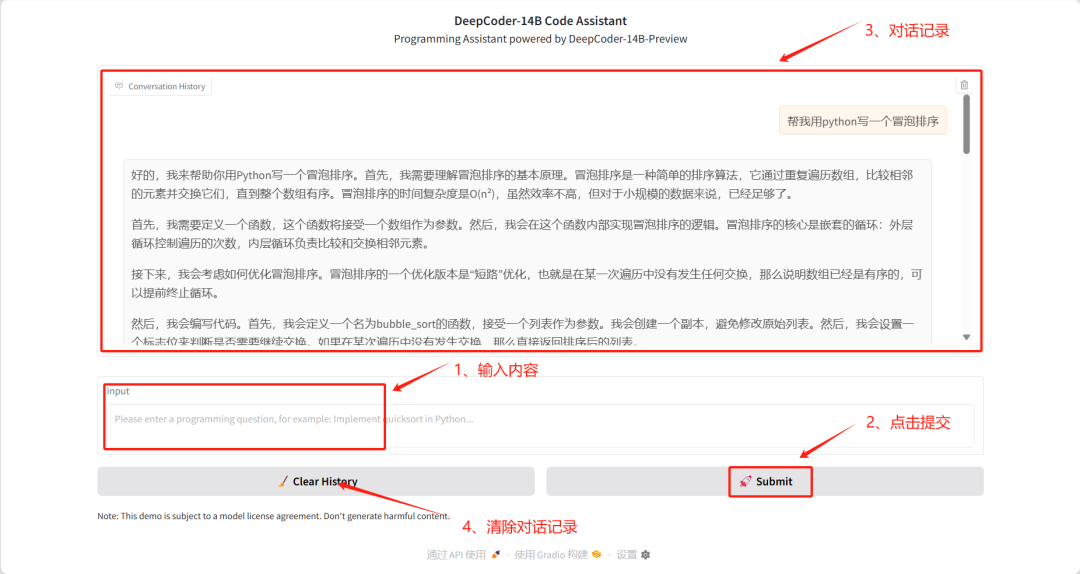
6. Déploiement en un clic de DeepCoder-14B-Preview
Le projet DeepCoder-14B-Preview est un modèle d'encodage 14B publié par AGENTICA le 8 avril 2025. Le modèle est affiné à partir de DeepSeek-R1-Distilled-Qwen-14B LLM pour le raisonnement de code et s'adapte à de longues longueurs de contexte à l'aide de l'apprentissage par renforcement distributionnel (RL). Le modèle atteint une précision Pass@1 de 60,6% sur LiveCodeBench v5 (8/1/24-2/1/25), une amélioration de 8% par rapport au modèle de base (53%), et atteint des performances similaires à celles de l'o3-mini d'OpenAI avec seulement 14B paramètres.
Ce tutoriel utilise le modèle DeepCoder-14B-Preview comme cas de démonstration et adopte la méthode de quantification 8 bits fournie par bitsandbytes pour optimiser l'utilisation de la mémoire vidéo.
Exécutez en ligne :https://go.hyper.ai/17aD2
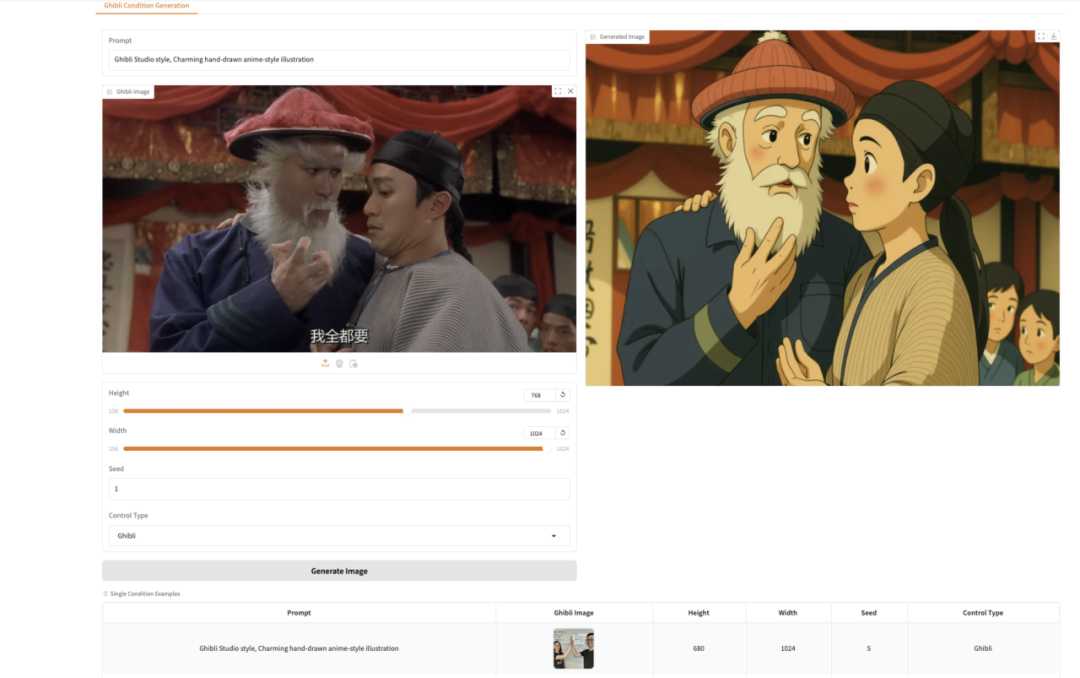
7. Démonstration de génération d'images de style Ghibli avec EasyControl
EasyControl est un projet qui vise à ajouter un contrôle efficace et flexible au transformateur de diffusion. Le projet améliore considérablement la compatibilité des modèles en introduisant des modules LoRA d'injection conditionnelle légers, des paradigmes de formation sensibles à la localisation et en combinant des mécanismes d'attention causale et la technologie de cache KV, prenant en charge la fonctionnalité plug-and-play et le contrôle de style sans perte.
Ce tutoriel utilise le modèle Stylized Img2Img Controls, capable de transformer un portrait en une œuvre d'art de style Hayao Miyazaki, tout en préservant les traits du visage et en appliquant l'esthétique emblématique de l'anime.
Exécutez en ligne :https://go.hyper.ai/jWm9j
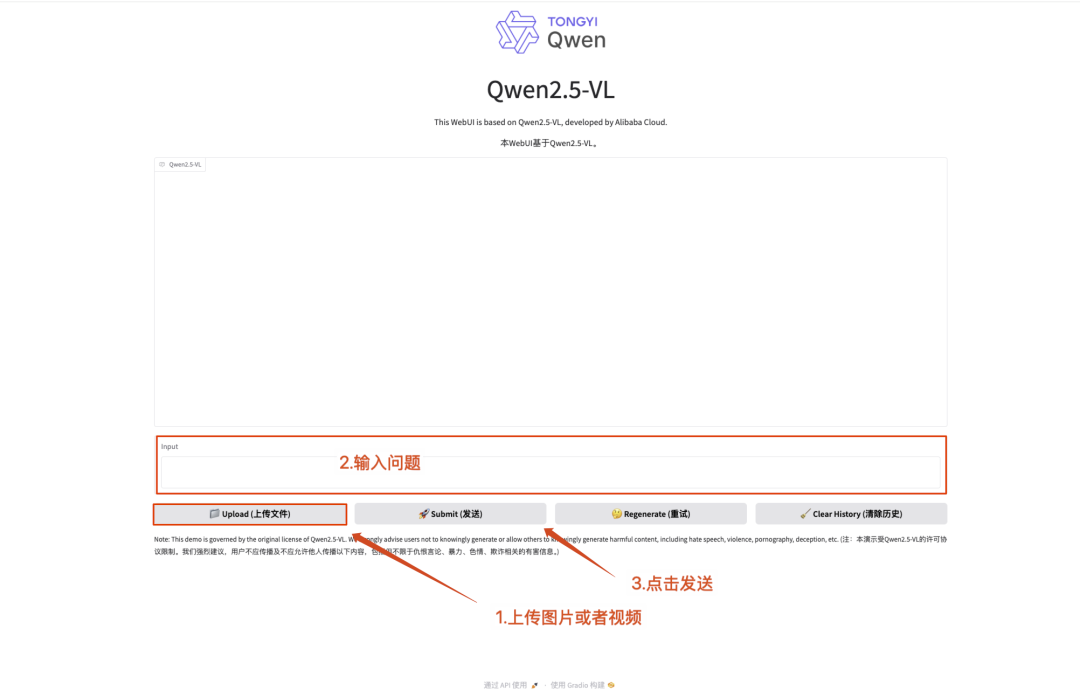
8. Qwen2.5-0mni : Prise en charge complète de la lecture, de l'écoute et de l'écriture
Qwen2.5-Omni est le dernier modèle phare multimodal de bout en bout lancé par l'équipe Tongyi Qianwen d'Alibaba. Il est conçu pour une perception multimodale complète et traite de manière transparente diverses entrées, notamment du texte, des images, de l'audio et de la vidéo, tout en prenant en charge la génération de texte en streaming et la sortie de synthèse vocale naturelle.
Ce tutoriel utilise Qwen2.5-Omni comme démonstration et les ressources de calcul sont A6000.
Exécutez en ligne :https://go.hyper.ai/eghWg
9. Déploiement en un clic de Qwen2.5-VL-32B-Instruct
Qwen2.5-VL-32B-Instruct est un grand modèle multimodal open source développé par l'équipe Alibaba Tongyi Qianwen. Basé sur la série Qwen2.5-VL, ce modèle est optimisé grâce à la technologie d'apprentissage par renforcement et réalise une percée dans les capacités multimodales avec une échelle de paramètres de 32B.
Ce tutoriel utilise Qwen2.5-VL-32B comme démonstration et les ressources de calcul sont A6000*2. Les fonctions incluent la compréhension de texte, la compréhension d'images et la compréhension de vidéos.
Exécutez en ligne :https://go.hyper.ai/Dp2Pd
10. Déploiement en un clic Qwen2.5-VL-32B-Instruct-AWQ
Qwen2.5-VL-32B-Instruct-AWQ est une version quantifiée de Qwen2.5-VL-32B-Instruct, qui améliore considérablement les capacités de programmation et de calcul mathématique. Le modèle prend en charge les interactions dans 29 langues, peut traiter de longs textes de 128 000 jetons et dispose de fonctions de base telles que la compréhension de données structurées et la génération JSON. Développé sur la base de l'architecture des transformateurs, il permet un déploiement efficace grâce à la technologie de quantification et convient aux scénarios d'application d'IA à grande échelle.
Les modèles et dépendances pertinents de ce projet ont été déployés. Après avoir démarré le conteneur, cliquez sur l’adresse API pour accéder à l’interface Web.
Exécutez en ligne :https://go.hyper.ai/fAYEK
Depuis sa sortie, DeepCoder-14B-Preview a gagné plus de 3 000 étoiles sur GitHub pour ses performances exceptionnelles dans les tâches de compréhension et de raisonnement du code. Le modèle a démontré des capacités comparables à celles de l'o3-mini dans plusieurs évaluations, et présente des performances de raisonnement efficaces et une bonne évolutivité.
Pour aider les développeurs à expérimenter et à déployer rapidement le modèle, la section didacticiel du site Web officiel d'HyperAl a lancé le didacticiel « Déploiement en un clic de DeepCoder-14B-Preview ». Cliquez sur le lien ci-dessous pour démarrer rapidement.
Exécutez en ligne :https://go.hyper.ai/V42RT
Afin de promouvoir l'application et le développement de l'ingénierie des protéines de l'IA, le groupe de recherche du professeur Hong Liang de l'Université Jiao Tong de Shanghai a développé une plate-forme ouverte unique, VenusFactory, conçue pour l'ingénierie des protéines. Les chercheurs peuvent facilement appeler plus de 40 modèles d’apprentissage profond de protéines de pointe sans écrire de codes complexes.
Actuellement, le site Web officiel d'HyperAI a lancé un didacticiel de déploiement en un clic pour la « VenusFactory Protein Engineering Design Platform ». Cliquez sur cloner pour le démarrer en un clic.
Exécutez en ligne :https://go.hyper.ai/TnskV
Articles de la communauté
Le laboratoire d'intelligence artificielle de Shanghai et plusieurs universités ont proposé Modèle MaMI, a introduit de manière innovante un adaptateur de paramètres modaux continus, brisant les limites de la modalité unique traditionnelle et permettant au modèle unifié de s'adapter à plusieurs modalités d'entrée telles que les rayons X et la tomodensitométrie en temps réel. Évalué sur 11 ensembles de données d'imagerie médicale publics, MaMI a démontré des performances de réidentification de pointe, offrant un support solide pour une récupération d'images historiques précise et dynamique en médecine personnalisée. Cet article est une interprétation détaillée et un partage de la recherche.
Voir le rapport complet :https://go.hyper.ai/e8Eat
Phaseshift Technologies, une entreprise canadienne de matériaux avancés, s'engage à utiliser la technologie de l'IA et la simulation multi-échelle pour développer des alliages et des composites de nouvelle génération. Sa plateforme Rapid Alloy Design (RAD™) permet de développer des alliages personnalisés pour des besoins et des scénarios spécifiques dans diverses industries, augmentant la vitesse de développement des matériaux jusqu'à 100 fois celle des méthodes traditionnelles tout en réduisant les coûts de 90%. Cet article est un rapport détaillé sur l'entreprise.
Voir le rapport complet :https://go.hyper.ai/da4VH
Le professeur Luo Xiaozhou de l'Institut de technologie avancée de Shenzhen de l'Académie chinoise des sciences a donné une présentation approfondie sur le thème de « l'ingénierie enzymatique basée sur l'intelligence artificielle » lors du sommet sur la conception de protéines IA « Future Has Come » organisé par l'Université Jiao Tong de Shanghai. À partir de perspectives multiples telles que le cadre UniKP et la machine ProEnsemble, les applications innovantes de l'IA dans l'ingénierie enzymatique et ses pratiques de biofabrication sont expliquées. Cet article est une transcription du partage du professeur Luo Xiaozhou.
Voir le rapport complet :https://go.hyper.ai/de1KW
Des équipes d’universités de premier plan telles que le MIT/UC Berkeley/Harvard/Stanford ont proposé conjointement l’algorithme innovant DRAKES. En introduisant un cadre d'apprentissage par renforcement, ils ont réalisé pour la première fois la rétropropagation de récompense différentiable de la trajectoire complète générée dans un modèle de diffusion discrète, améliorant considérablement les performances des tâches en aval tout en maintenant le caractère naturel de la séquence. Cet article est une interprétation détaillée et un partage du document de recherche.
Voir le rapport complet :https://go.hyper.ai/YyEof
Articles populaires de l'encyclopédie
1. DALL-E
2. Fusion de tri réciproque RRF
3. Front de Pareto
4. Compréhension linguistique multitâche à grande échelle (MMLU)
5. Apprentissage contrastif
Voici des centaines de termes liés à l'IA compilés pour vous aider à comprendre « l'intelligence artificielle » ici :








