Command Palette
Search for a command to run...
En Simulant Une Consultation Médicale, Une Équipe De l'hôpital De Chine Occidentale De l'Université Du Sichuan a Développé Un Cadre De Dialogue multi-agents Pour Aider Au Diagnostic Des maladies.

La prévalence des maladies rares est faible et les connaissances professionnelles pertinentes sont rares. De plus, les symptômes individuels sont complexes et variables, de sorte que les erreurs de diagnostic et les retards de diagnostic sont fréquents. Ces dernières années, les grands modèles de langage (LLM) tels que GPT-4 ont obtenu de bons résultats dans la réponse aux questions médicales et le diagnostic des maladies courantes, mais sont toujours confrontés à des défis dans les tâches cliniques complexes telles que les maladies rares.Afin d’améliorer les capacités d’application pratique des LLM dans le domaine médical, certains chercheurs ont commencé à explorer l’application des systèmes multi-agents (MAS).
Un agent intelligent est un système capable de recevoir des entrées et d’effectuer des opérations spécifiques afin d’atteindre un certain objectif. Par exemple, lorsque nous communiquons avec ChatGPT au sujet de notre état de santé, nous avons en fait une conversation avec un seul agent.En revanche, le système multi-agents permet un diagnostic plus dynamique et interactif grâce au dialogue multi-agents (MAC). Ce modèle simule le mécanisme de discussion de l'équipe multidisciplinaire (MDT) dans la pratique clinique, permettant à plusieurs agents de discuter et d'analyser le même cas, et de produire les résultats du diagnostic après avoir atteint un consensus.
Récemment, des équipes de l'hôpital de Chine occidentale de l'université du Sichuan, du centre de données biomédicales de Chine occidentale, de la faculté de médecine de l'université du Zhejiang, de l'université des postes et télécommunications de Pékin, etc.Un cadre de dialogue multi-agent (MAC) a été développé sur la base de GPT-3.5 et GPT-4 respectivement.Le cadre se compose d'un agent administratif, d'un agent superviseur et de plusieurs agents médecins, qui participent conjointement à l'analyse de l'état des patients. La meilleure configuration de MAC consiste à utiliser GPT-4 comme modèle de base et à se composer de 4 agents médecins et d'un agent superviseur.
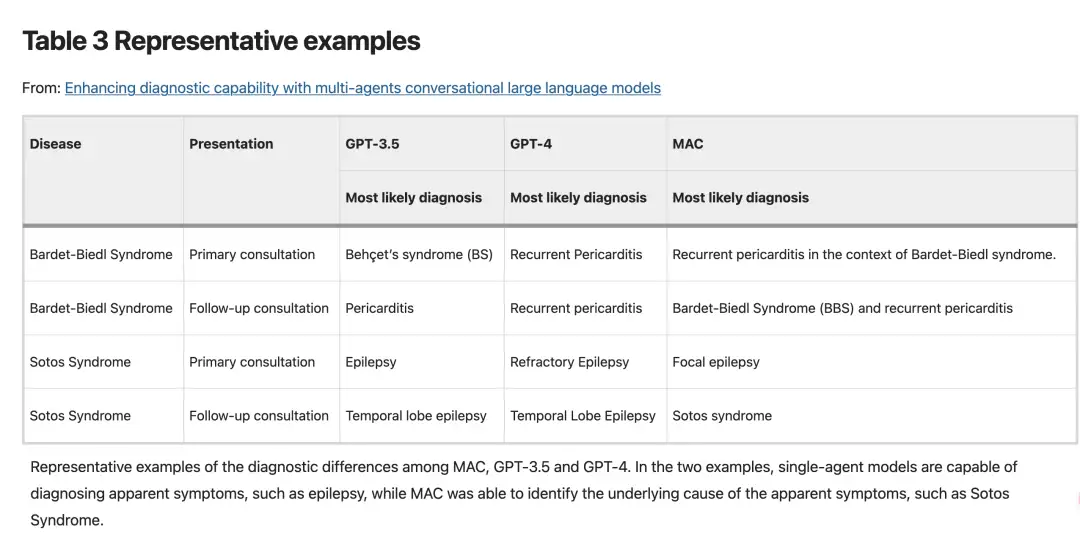
L'évaluation des performances de GPT-3.5, GPT-4 et MAC dans le raisonnement clinique et la génération de connaissances médicales pour 302 maladies rares est disponible.Le MAC a surpassé le modèle à agent unique dans les phases initiale et de suivi.De plus, les capacités de diagnostic du MAC vont au-delà des méthodes telles que les invites de la chaîne de pensée (CoT), l'auto-affinage et l'auto-cohérence.Peut produire un contenu de diagnostic plus riche.Par exemple, GPT-3.5 et GPT-4 peuvent identifier la péricardite et l’épilepsie en fonction de la présentation clinique, mais MAC, grâce à une analyse plus approfondie du dialogue conjoint, peut déterminer que la péricardite dans un cas spécifique est causée par le syndrome de Bardet-Biedl.
En conclusion, le MAC améliore considérablement la capacité diagnostique des LLM, comble le fossé entre les connaissances théoriques et la pratique clinique et devrait devenir un outil auxiliaire important pour les médecins.L'étude, intitulée « Améliorer la capacité de diagnostic avec des modèles de langage conversationnels multi-agents à grande échelle », a été publiée dans npj Digital Medicine, une revue Nature.

Adresse du document :
https://www.nature.com/articles/s41746-025-01550-0#Tab6
Le projet open source « awesome-ai4s » rassemble plus de 200 interprétations d'articles AI4S et fournit des ensembles de données et des outils massifs :
https://github.com/hyperai/awesome-ai4s
Ensemble de données : Dépistage de 302 maladies rares
Cette étude a examiné 302 maladies rares de la base de données Orphanet comme objets de recherche. La base de données Orphanet est une base de données complète sur les maladies rares cofinancée par la Commission européenne, couvrant plus de 7 000 maladies de 33 types.
Téléchargez l'ensemble de données de 302 cas de maladies rares :
https://go.hyper.ai/EETet
Après avoir identifié la maladie cible, l'équipe de recherche a recherché dans la base de données Medline des rapports de cas cliniques publiés après janvier 2022. En extrayant des données structurées de ces rapports de cas, nous avons recueilli des informations détaillées sur les données démographiques des patients, les manifestations cliniques, les antécédents médicaux, les résultats de l'examen physique et divers résultats d'examens auxiliaires (y compris les tests génétiques, la biopsie pathologique et les examens radiologiques), et avons enregistré les informations de diagnostic finales.
Afin d'évaluer de manière exhaustive la valeur d'application des grands modèles de langage (LLM) dans les contextes cliniques, l'équipe de recherche a conçu une expérience de simulation de consultation clinique en deux étapes, dans laquelle chaque cas a été testé dans des contextes de consultation primaire et de consultation de suivi :
* La première étape simule le scénario de consultation initiale (diagnostic initial),L’objectif principal est d’étudier les performances du LLM chez les patients qui se présentent pour la première fois et qui disposent d’informations cliniques limitées. La tâche des LLM est d’arriver à un diagnostic le plus probable, à plusieurs diagnostics possibles et à d’autres diagnostics.
* La deuxième étape simule le scénario de consultation de suivi (réexamen).Évaluer la capacité diagnostique du LLM après avoir obtenu des informations complètes sur le patient (y compris divers résultats d'examen). La tâche des LLM est d’arriver à un diagnostic le plus probable et à plusieurs diagnostics possibles.
Cette conception d'étude par phases peut non seulement tester la capacité de jugement initiale du LLM dans des conditions d'informations incomplètes, mais également évaluer systématiquement son raisonnement médical et la précision du diagnostic final après avoir pleinement maîtrisé les données cliniques, reflétant ainsi de manière exhaustive le potentiel d'application pratique du LLM dans l'aide à la décision clinique.

Le framework MAC basé sur GPT-4 et avec 4 Doctor Agents a obtenu les meilleurs résultats
En utilisant la structure fournie par Autogen, l'équipe de recherche a développé deux cadres de conversation multi-agents (MAC) basés sur GPT-3.5-turbo et GPT-4 pour simuler des consultations médicales. Comme le montre la figure ci-dessous,L'agent administratif fournit des informations au patient, l'agent superviseur initie et supervise la conversation conjointe, et les trois agents médecins discutent ensemble de l'état du patient.Le dialogue se poursuivra jusqu'à ce que les agents parviennent à un consensus ou que le nombre maximal prédéfini de tours de dialogue (fixé à 13 tours dans cette étude) soit atteint, et le résultat final du diagnostic sera émis.
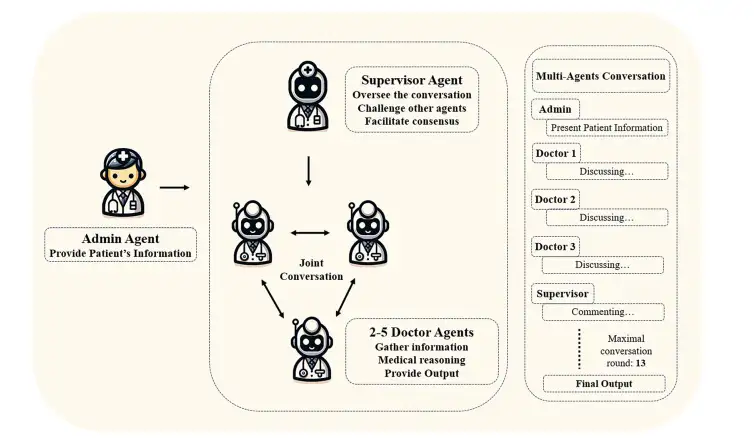
L'agent superviseur joue le rôle de contrôle qualité et d'optimisation des processus.Ses responsabilités comprennent : (1) la supervision et l’évaluation des recommandations et des décisions prises par les médecins agents ; (2) examiner les plans de diagnostic et les éléments d’examen proposés pour identifier les points clés qui pourraient être manqués ; (3) coordonner les discussions entre les médecins agents pour promouvoir l’amélioration des plans de diagnostic ; (4) encourager les médecins agents à parvenir à un consensus sur le diagnostic final et le plan d’examen ; et (5) mettre fin au processus de dialogue en temps opportun une fois le consensus atteint.
Les responsabilités des agents médicaux comprennent :(1) Fournir un raisonnement diagnostique et des conseils cliniques fondés sur des connaissances médicales professionnelles ; (2) Évaluer et commenter systématiquement les opinions des autres agents et présenter des arguments et des preuves scientifiques et raisonnables ; (3) Intégrer et optimiser les retours d’expérience des autres agents pour améliorer en permanence les résultats du diagnostic.
À l’aide de rapports de cas cliniques réels provenant de la base de données Medline, les chercheurs ont évalué les connaissances et les capacités diagnostiques de GPT-3.5, GPT-4 et MAC pour 302 maladies rares. De plus, l’impact de différents paramètres sur les performances MAC est étudié.
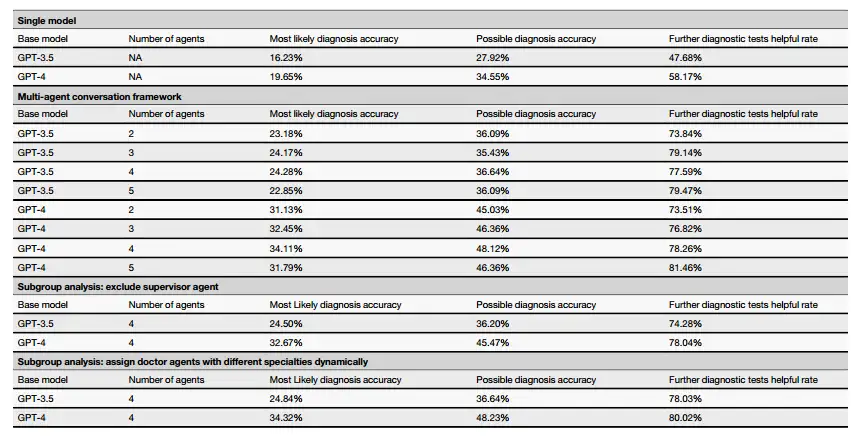
Par exemple, l’équipe de recherche a comparé les différences de performances lorsque le cadre MAC utilisait GPT-4 et GPT-3.5 comme modèle de base.Les résultats montrent que MAC utilisant GPT-3.5 ou GPT-4 comme modèle de base fonctionne nettement mieux que leurs versions indépendantes respectives. En d’autres termes, la capacité de diagnostic du MAC est grandement améliorée par rapport au modèle à agent unique.De plus, lorsqu'il est utilisé comme modèle de base pour MAC, il est démontré que GPT-4 surpasse GPT-3.5, ce qui implique qu'un modèle de base plus puissant peut conduire à de meilleures performances globales.
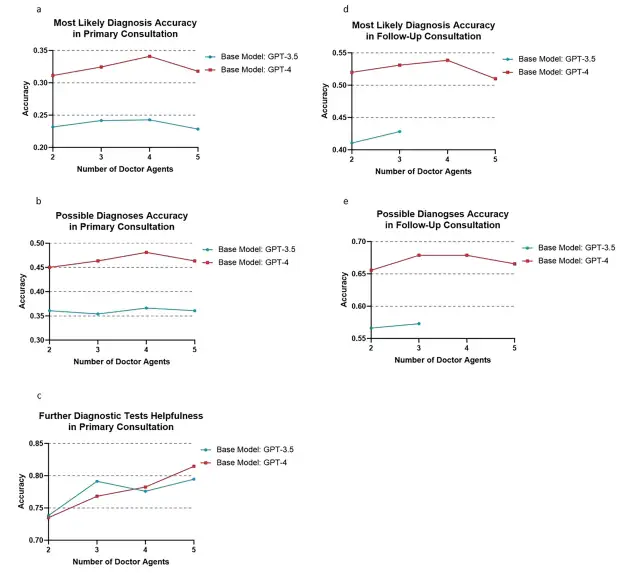
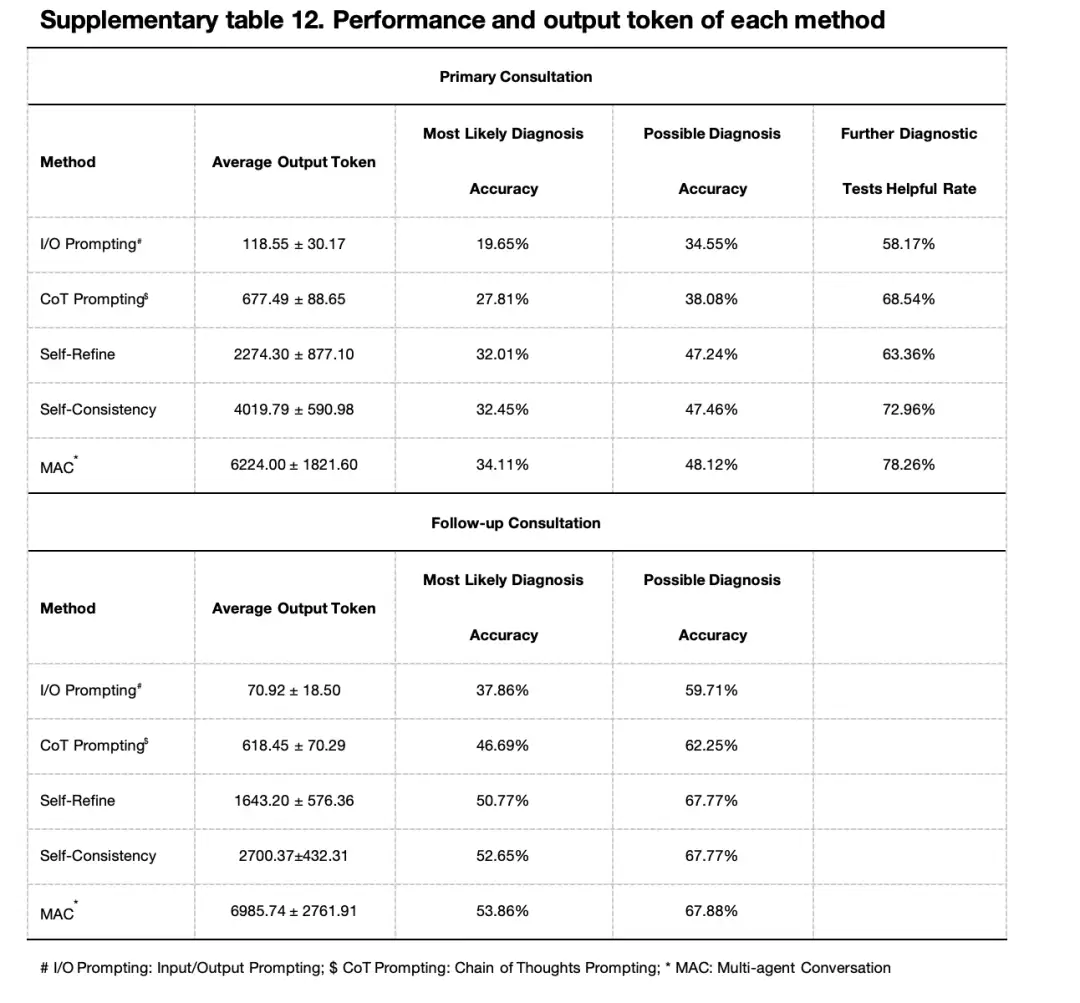
aussi,Les chercheurs ont également étudié l’impact du nombre d’agents docteurs sur les performances du cadre multi-agents.Les résultats expérimentaux basés sur le modèle GPT-4 ont montré qu'en termes de précision diagnostique la plus probable, il atteignait un pic de 34,11% avec 4 agents, tandis qu'il chutait légèrement à 31,79% avec 5 agents. Un modèle similaire a été observé dans la précision du diagnostic possible, la précision des agents 2, 3, 4 et 5 étant respectivement de 51,99%, 53,31%, 53,86% et 50,99%. Dans l’expérience basée sur le modèle GPT-3.5, les quatre agents médecins ont également montré les meilleures performances. Cependant, dans l’ensemble, les performances de 3 agents ne sont pas très différentes de celles de 4 agents.
De plus, dans un scénario de consultation initiale simulée impliquant quatre agents médecins,Le cadre MAC basé sur GPT-4 a obtenu de meilleures performances dans de nombreux indicateurs clés : la précision du diagnostic le plus probable a atteint 34,11% (GPT-3,5 est de 24,28%), la précision du diagnostic possible a atteint 48,12% (GPT-3,5 est de 36,64%) et l'utilité des tests de diagnostic supplémentaires a atteint 78,26% (GPT-3,5 est de 77,37%). En termes de performance diagnostique lors des consultations de suivi, le cadre MAC basé sur GPT-4 avec la participation de 4 médecins agents a également obtenu les meilleurs résultats.
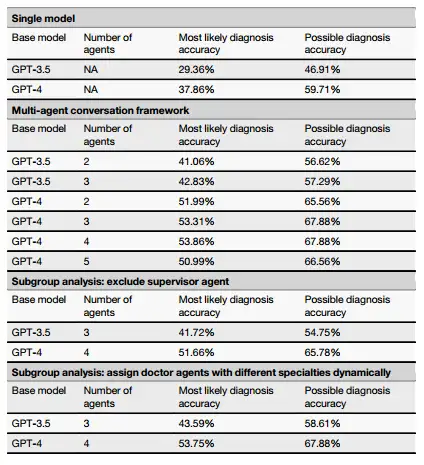
Les chercheurs ont également évalué l’impact potentiel de la suppression de l’agent superviseur sur les performances globales du MAC. Les résultats montrent que lorsque l'agent superviseur est supprimé, dans le scénario de consultation initiale simulé avec 4 agents médecins,Les données du cadre MAC basé sur GPT-4 en termes de précision diagnostique la plus probable, de précision diagnostique possible et d'utilité de tests diagnostiques supplémentaires étaient respectivement de 32,67%, 45,47% et 78,04%, qui sont toutes inférieures à celles lorsqu'elles n'étaient pas supprimées.Dans le scénario de consultation de suivi, le cadre MAC avec l'agent superviseur supprimé avait une précision de diagnostic probable et une précision de diagnostic possible inférieures à celles lorsqu'il n'était pas supprimé.Cela montre que Supervisor Agent améliore l’efficacité du cadre.
Conclusion expérimentale : le MAC peut identifier directement la cause profonde de la maladie et dispose de capacités de diagnostic plus solides
L'équipe de recherche a évalué la performance des cadres GPT-3.5, GPT-4 et MAC dans la génération de connaissances sur les maladies rares, y compris la définition de la maladie, l'épidémiologie, les caractéristiques cliniques, l'étiologie, les méthodes de diagnostic, le diagnostic différentiel, le diagnostic prénatal, le conseil génétique, la gestion du traitement et le pronostic. Les résultats montrent que ces modèles fonctionnent bien dans toutes les dimensions d’évaluation, avec des scores dépassant 4 points pour chaque indicateur, comme le montre la figure ci-dessous. aussi,Ils ont démontré des niveaux élevés d’exactitude du contenu (contenu inapproprié/incorrect), d’exhaustivité des informations (omissions), de sécurité (probabilité et ampleur du préjudice possible) et d’objectivité (biais).
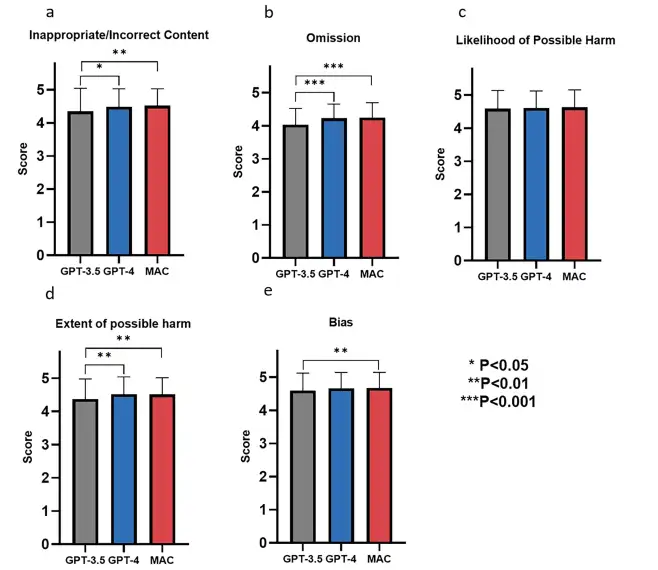
Dans le diagnostic de cas spécifiques de maladies, comme le montre la figure ci-dessous, les chercheurs ont constaté que GPT-3.5 et GPT-4 étaient capables de diagnostiquer des maladies sur la base de symptômes évidents, tels que l'identification de la péricardite et de l'épilepsie à travers des manifestations cliniques, mais ils étaient insuffisants pour explorer les causes profondes de la maladie.En revanche, le cadre MAC fournit une analyse plus approfondie grâce à un dialogue conjoint, qui peut déterminer que la péricardite dans un cas particulier est causée par le syndrome de Bardet-Biedl.
Les chercheurs ont comparé le MAC avec les indices d’entrée/sortie (E/S), les indices de chaîne de pensée (CoT), l’auto-optimisation et les méthodes d’auto-cohérence. Comme le montre la figure ci-dessous,Lors des consultations initiales et de suivi, le MAC a obtenu les meilleurs résultats en termes de diagnostic le plus probable, de diagnostic possible et d'efficacité des tests diagnostiques supplémentaires.
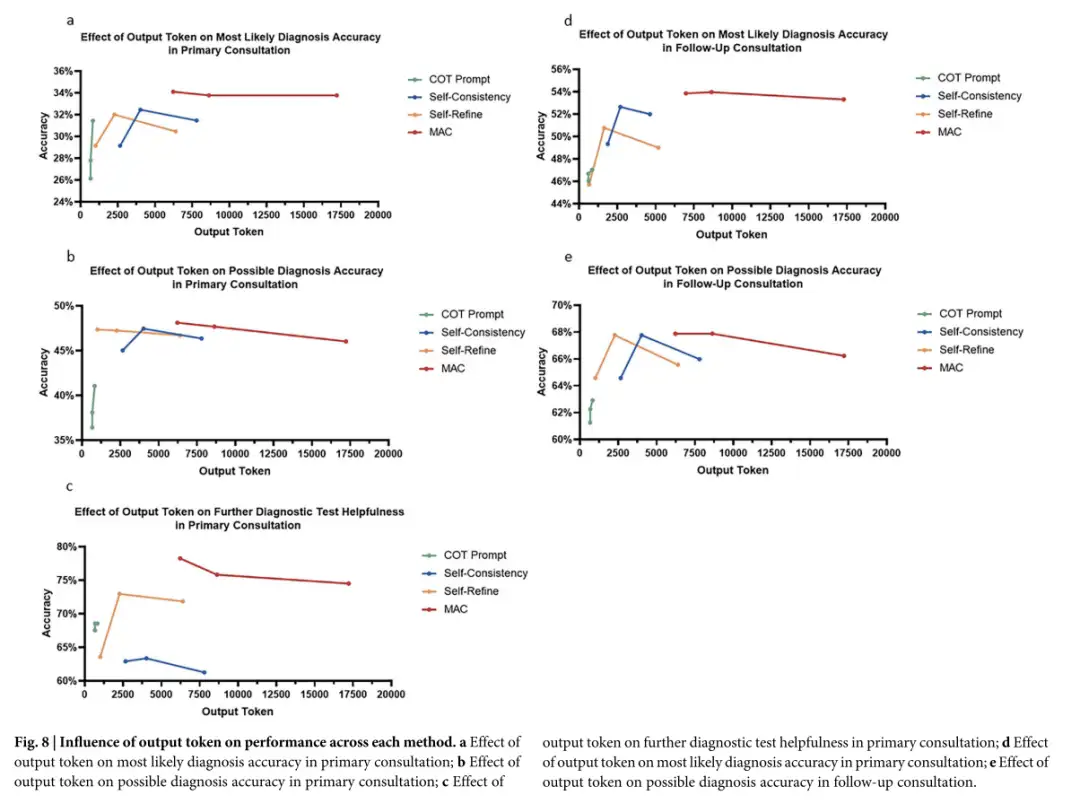
De plus, MAC génère davantage de jetons. L’augmentation de la production permet non seulement d’explorer différentes voies de raisonnement, mais permet également de réfléchir et de corriger les résultats précédents, ce qui peut augmenter la profondeur de l’analyse et améliorer la capacité à identifier les causes profondes des maladies négligées. Cependant, les recherches montrent également queBien que l’augmentation du nombre d’appels LLM et donc la génération de plus de jetons puissent améliorer les performances MAC, l’ampleur de cette amélioration est limitée par le type de tâche et la méthode de raffinement utilisée.
En résumé, cette étude a développé avec succès un cadre de dialogue multi-agents (MAC) pour le diagnostic des maladies, qui peut fournir des suggestions diagnostiques précieuses et recommander un diagnostic plus approfondi à différentes étapes de la consultation clinique, et est applicable à tous les types de maladies rares. De plus, par rapport aux méthodes existantes telles que la chaîne de pensée (CoT), l’auto-optimisation et l’auto-cohérence,MAC offre non seulement une précision de diagnostic plus élevée, mais génère également un contenu de diagnostic plus riche et plus complet.Ce cadre améliore considérablement les capacités de diagnostic clinique des grands modèles linguistiques.
Les systèmes multi-agents présentent un grand potentiel d’application dans le domaine médical
Ces dernières années, les systèmes multi-agents ont montré des progrès prometteurs dans le domaine de la prise de décision et du diagnostic médical. Plusieurs cadres importants ont émergé et adopté différentes stratégies pour utiliser de grands modèles linguistiques afin d’effectuer des tâches cliniques. Par exemple, l’Université Jiao Tong de Shanghai a proposé MedAgents, un cadre de collaboration multidisciplinaire pour le domaine médical. Ce cadre permet aux agents basés sur LLM de mener plusieurs séries de discussions collaboratives dans un environnement de jeu de rôle, améliorant considérablement les performances de LLM dans la réponse aux questions médicales à échantillon zéro. La recherche a été publiée sur arXiv sous le titre « MedAgents : Large Language Models as Collaborators for Zero-shot Medical Reasoning ».
Adresse du document :
https://arxiv.org/abs/2311.10537
Différent de MedAgents et d'autres plateformes qui se concentrent sur les questions et réponses médicales,Le cadre MAC se concentre sur les tâches de diagnostic, incitant plusieurs agents à analyser, à discuter de manière interactive et à fournir des suggestions de diagnostic ouvertes dans le même contexte clinique.En termes de conception architecturale de l'agent intelligent, MAC contient plusieurs agents docteurs et un agent superviseur, tandis que d'autres frameworks adoptent des paramètres différents, tels que la création d'agents distincts pour les questions et les réponses. Les cadres diffèrent également dans la manière dont ils parviennent à un consensus. Par exemple, les MedAgents affinent continuellement leurs réponses par des révisions itératives jusqu'à ce que tous les experts parviennent à un consensus, tandis que le MAC est déterminé par l'agent superviseur lorsque les agents médecins ont atteint un consensus suffisant.
Bien que ces systèmes multi-agents aient leurs propres caractéristiques de configuration et d'objectifs, ils ont un grand potentiel d'application dans le domaine médical, et des recherches supplémentaires sont encore nécessaires à l'avenir pour explorer et optimiser pleinement leur rôle réel dans les environnements cliniques.
L’équipe de recherche du cadre de dialogue multi-agents mentionné ci-dessus se concentre sur l’exploration de pointe à l’intersection de l’intelligence artificielle générative et de la médecine clinique.Il dispose de riches ressources de données cliniques et d’installations informatiques avancées, et ses résultats de recherche ont été publiés dans des revues universitaires internationales de haut niveau.
L’équipe s’engage à appliquer concrètement la technologie de l’intelligence artificielle et à transformer véritablement le modèle et l’écosystème du diagnostic et du traitement médicaux cliniques. Nous invitons sincèrement les institutions académiques et les entreprises à mener des projets de coopération. Nous invitons les étudiants diplômés exceptionnels qui sont intéressés par ce domaine à postuler. Parallèlement, nous recrutons des assistants de recherche scientifique passionnés pour rejoindre l’équipe. Les parties intéressées peuvent contacter [email protected].








