Command Palette
Search for a command to run...
Stable Virtual Camera Redéfinit La Génération De Contenu 3D Et Ouvre De Nouvelles Dimensions d'images ; BatteryLife Permet De Prédire La Durée De Vie De La Batterie Avec Plus De Précision

Dans la concurrence féroce de la création de contenu numérique, Stability AI se trouve à la croisée des chemins du destin. Cette entreprise, qui avait autrefois lancé une révolution dans la génération d'images avec Stable Diffusion, est tombée en crise en raison de problèmes de direction. Récemment, Stability AI a lancé le modèle de caméra virtuelle stable. Je me demande si un coup puissant peut sortir de l’impasse.
La caméra virtuelle stable est un modèle de diffusion multi-vues, qui combine les capacités de contrôle d'une caméra virtuelle traditionnelle avec la créativité de l'IA générative. La technologie convertit des images 2D ordinaires en vidéos 3D avec une profondeur et une perspective réalistes, sans nécessiter de reconstruction de scène complexe ou de compétences spécialisées.
Par rapport aux modèles vidéo 3D traditionnels,Le modèle ne nécessite pas un grand nombre d’images d’entrée ni d’étapes de prétraitement complexes, ce qui rend la génération de contenu 3D beaucoup plus simple et plus réalisable.Et cette technologie fonctionne bien sur le benchmark Novel View Synthesis (NVS).Les performances dépassent celles de certains modèles existants.
Actuellement, HyperAI Super Neural est en ligne « Les images stables de la caméra virtuelle se transforment en vidéos 3D en quelques secondes »Tutoriel, venez l'essayer~
Utilisation en ligne :https://go.hyper.ai/N2u9l
Du 24 au 28 mars, le site officiel hyper.ai est mis à jour :
* Ensembles de données publiques de haute qualité : 10
* Sélection de tutoriels de haute qualité : 3
* Sélection d'articles communautaires : 3 articles
* Entrées d'encyclopédie populaire : 5
* Principales conférences avec date limite en avril : 10
Visitez le site officiel :hyper.ai
Ensembles de données publiques sélectionnés
1. Ensemble de données de jeu de rôle CoSER
L'ensemble de données couvre 17 966 caractères et 29 798 dialogues réels. Il comprend non seulement des aperçus et des dialogues de personnages, mais fournit également un contenu riche tel que des résumés d'intrigue, des expériences de personnages et des arrière-plans de dialogue. De plus, le contenu du dialogue couvre trois dimensions : le langage, l’action et la pensée, ce qui rend la performance du personnage plus tridimensionnelle.
Utilisation directe :https://go.hyper.ai/1WbXV

2. Ensemble de données d'annotation de raisonnement mathématique MV-MATH
L'ensemble de données MV-MATH contient 2 009 problèmes mathématiques de haute qualité, divisés en trois types : questions à choix multiples, questions à trous et questions à plusieurs étapes. L'ensemble de données contient plusieurs scènes visuelles et chaque question est équipée de 2 à 8 images. Ces images sont entrelacées avec du texte pour former des scènes multivisuelles complexes, plus proches des problèmes mathématiques du monde réel et permettant d'évaluer efficacement la capacité de raisonnement du modèle à traiter des informations multivisuelles.
Utilisation directe :https://go.hyper.ai/tRQsA
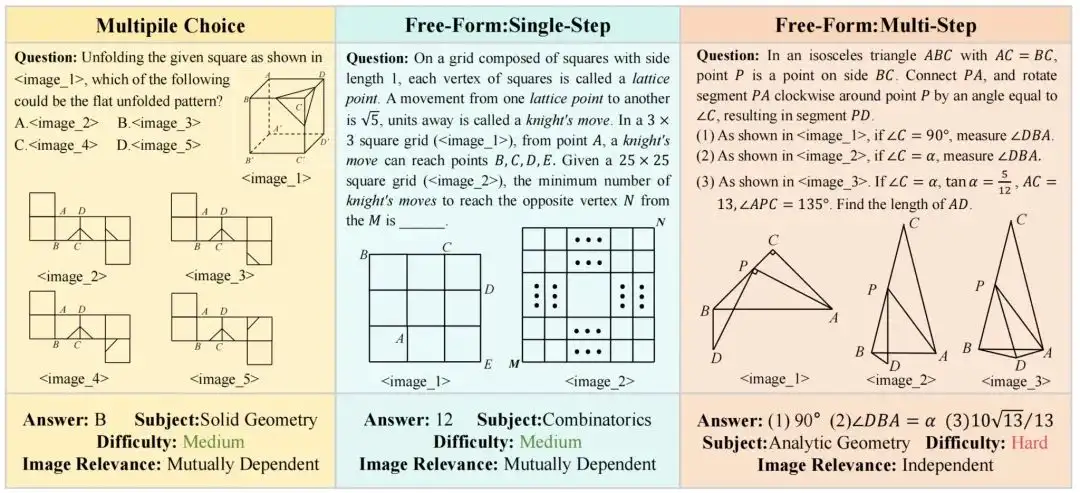
3. Ensemble de données de scène multi-vues WideRange4D
Cet ensemble de données comble le vide dans les ensembles de données de reconstruction 4D existants dans les scènes dynamiques complexes en introduisant des données de scène 4D avec une large gamme de mouvements spatiaux. Il excelle dans la richesse des scènes, la complexité des mouvements et la diversité environnementale, y compris les scènes du monde réel (telles que les rues de la ville, les routes rurales) et les scènes virtuelles, couvrant les mouvements à courte, moyenne et longue distance, ainsi que les trajectoires de mouvement complexes, tout en simulant une variété de conditions météorologiques telles que les jours ensoleillés, les jours de pluie et les tempêtes de sable.
Utilisation directe :https://go.hyper.ai/9KszI
4. Ensemble de données tactiles multimodales et multicapteurs TacQuad
TacQuad est un ensemble de données tactiles multimodales alignées et multi-capteurs collectées à partir de 4 types de capteurs tactiles visuels (GelSight Mini, DIGIT, DuraGel et Tac3D). Il fournit une solution plus complète à la faible standardisation des capteurs tactiles visuels en fournissant des données d'alignement multi-capteurs avec du texte et des images visuelles. Cela permet explicitement au modèle d'apprendre les attributs tactiles de niveau sémantique et les caractéristiques indépendantes du capteur, formant ainsi un espace de représentation multi-capteurs unifié grâce à une approche basée sur les données.
Utilisation directe :https://go.hyper.ai/uL0Zd

5. Ensemble de données vidéo sur la robotique IA physique et la conduite autonome
Cet ensemble de données est un ensemble de données d'IA physique publié par NVIDIA lors de la conférence GTC25. Il contient 15 To de données, plus de 320 000 trajectoires pour la formation des robots et jusqu'à 1 000 ressources de description de scène générale (OpenUSD), y compris la collection SimReady, couvrant différents types de routes et d'environnements géographiques, différentes infrastructures et différents environnements météorologiques.
Utilisation directe :https://go.hyper.ai/LEHa5

6. Images aériennes de paysages Ensemble de données aériennes de paysages
Skyview est un ensemble de données organisé pour la classification des paysages aériens, avec un total de 12 000 images, 15 catégories différentes, et chaque catégorie contient 800 images de haute qualité avec une résolution de 256 × 256 pixels. Cet ensemble de données fusionne des images des ensembles de données AID et NWPU-Resisc45 accessibles au public. La compilation vise à promouvoir la recherche et le développement dans le domaine de la vision par ordinateur, en particulier dans l'analyse du paysage aérien.
Utilisation directe :https://go.hyper.ai/mne9z

7. Ensemble de données vidéo sur les accidents de la route EMM-AU
Cet ensemble de données est le premier ensemble de données conçu spécifiquement pour les tâches de raisonnement sur les accidents de la route, et il étend l'ensemble de données MM-AU en exploitant des techniques avancées de génération et d'amélioration vidéo. L'ensemble de données contient 2 000 vidéos détaillées de scènes d'accident nouvellement générées, qui sont générées en affinant le modèle Open-Sora 1.2 pré-entraîné, dans le but de fournir des données d'entraînement plus riches et plus diversifiées pour la compréhension et la prévention des accidents.
Utilisation directe :https://go.hyper.ai/gy0mb
8. BatteryLife Ensemble de données de prédiction de la durée de vie de la batterie
Cet ensemble de données a été créé à l’origine pour soutenir la recherche sur la prédiction de la durée de vie des batteries. Il intègre 16 ensembles de données différents et fournit plus de 90 000 échantillons provenant de 998 batteries, toutes avec des étiquettes de durée de vie. L'ensemble de données BatteryLife est 2,4 fois plus grand que la plus grande ressource précédente sur la durée de vie des batteries, BatteryML.
Utilisation directe :https://go.hyper.ai/0PzfZ
9. Petit échantillon de données sur la mutation de la protéine VenusMutHub
VenusMutHub est le premier petit ensemble de données d'échantillons de mutations protéiques pour des scénarios d'application réels. L'équipe de recherche a soigneusement compilé 905 petits échantillons de données de mutation expérimentale pour des scénarios d'application réels, couvrant 527 protéines (dont 981 protéines TP3T ont 5 à 200 mutations), couvrant une variété de données de mesure fonctionnelles telles que la stabilité, l'activité, l'affinité de liaison et la sélectivité. Toutes les données ont été obtenues à l’aide de mesures biochimiques directes plutôt que de lectures de fluorescence alternatives, garantissant ainsi l’exactitude de l’évaluation.
Utilisation directe :https://go.hyper.ai/8y20R
10. Oiseau vs Drone Ensemble de données de classification d'images d'oiseaux et de drones
Cet ensemble de données contient une collection diversifiée d'images du site Web Pexel, représentant des oiseaux et des drones en mouvement. Les images sont capturées à partir d'images vidéo, segmentées, augmentées et prétraitées pour simuler différentes conditions environnementales, améliorant ainsi le processus de formation du modèle.
Utilisation directe :https://go.hyper.ai/RdN4d
Tutoriels publics sélectionnés
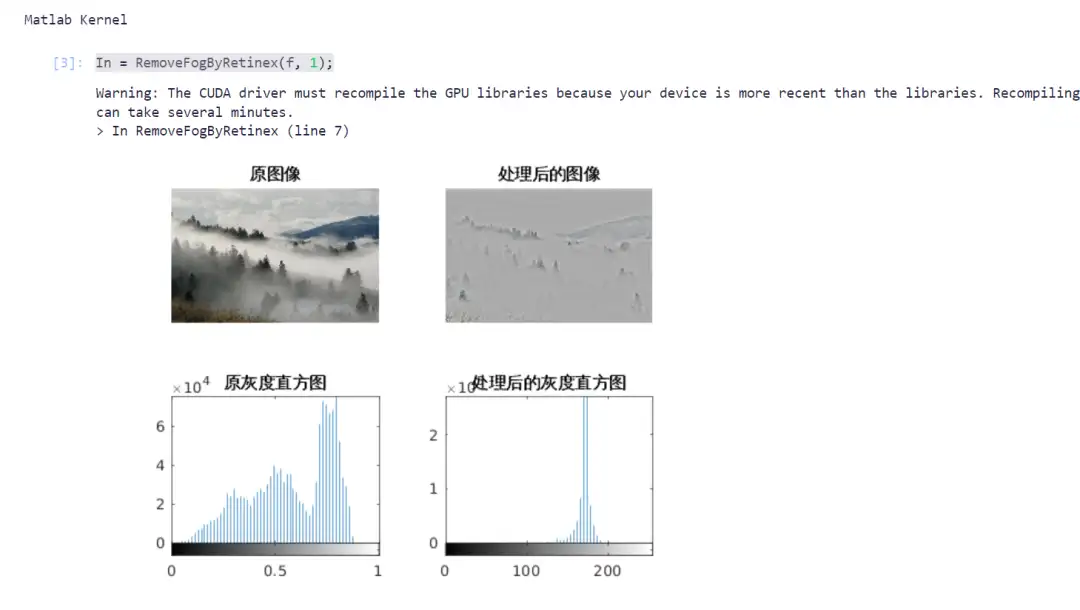
1. Dévoilage d'images avec MATLAB
Dans le domaine de la vision par ordinateur, la suppression du voile d'image est une tâche de prétraitement importante, en particulier dans la conduite autonome, l'analyse d'images de télédétection et les systèmes de surveillance. Le dévoilage peut améliorer efficacement la qualité de l’image et rendre la cible plus clairement visible.
Ce projet utilise l'algorithme Retinex pour la correction du voile d'image et le combine avec l'accélération GPU pour améliorer l'efficacité de calcul. Saisissez le code approprié selon le didacticiel pour terminer le processus de suppression du voile de l'image.
Exécutez en ligne :https://go.hyper.ai/wu1fE
2. La caméra virtuelle stable transforme les images en vidéos 3D en quelques secondes
Stable Virtual Camera (Seva en abrégé) est un modèle de diffusion général lancé par Stability AI en mars 2025. Seva est capable de générer de nouvelles vues d'une scène à partir d'un nombre quelconque de vues d'entrée et de caméras cibles. Sa conception surmonte les limites des méthodes existantes dans la génération d'échantillons avec de grandes variations de points de vue ou d'échantillons temporellement lisses, sans s'appuyer sur une configuration de tâche spécifique.
Une caractéristique notable de ce modèle est qu’il peut maintenir une génération d’échantillons très cohérente sans nécessiter d’apprentissage supplémentaire de représentation 3D, simplifiant ainsi le processus de synthèse de perspective dans les applications pratiques. De plus, Seva peut générer des vidéos de haute qualité d'une durée maximale d'une demi-minute et les faire tourner en boucle de manière transparente. Des tests de référence approfondis montrent que Seva surpasse les méthodes existantes sur différents ensembles de données et paramètres.
Les modèles et dépendances pertinents de ce projet ont été déployés. Après avoir démarré le conteneur, cliquez sur l’adresse API pour accéder à l’interface Web.
Exécutez en ligne :https://go.hyper.ai/N2u9l

Le modèle de génération de parole CSM (Conversational Speech Model) lancé par l'équipe Sesame peut produire une parole fluide, naturelle et émotionnelle basée sur du texte et une entrée audio. Comparé aux modèles traditionnels de génération de parole par IA, le CSM possède des capacités de compréhension émotionnelle plus fortes, un rythme de conversation plus naturel, une interaction en temps réel avec un délai quasi nul et aucun sens de drone.
Exécutez en ligne :https://go.hyper.ai/bxOoN
Articles de la communauté
L'algorithme d'apprentissage profond AcneDGNet développé par l'équipe de l'hôpital international de l'université de Pékin peut identifier avec précision les lésions d'acné et déterminer automatiquement leur gravité, avec une précision diagnostique comparable à celle des dermatologues seniors. Il offre un support solide pour les consultations en ligne et les traitements médicaux hors ligne, aidant à gérer l'acné plus efficacement. Cet article est une interprétation détaillée et un partage de la recherche.
Voir le rapport complet :https://go.hyper.ai/qAjYK
Une équipe de recherche de l’Université de Cambridge a proposé une méthode appelée AlphaFold-Metainference. Cette méthode utilise la corrélation entre la carte d'erreur d'alignement prédite par AlphaFold et la matrice de changement de distance dans la simulation de dynamique moléculaire pour construire une collection structurelle de protéines désordonnées et de protéines contenant des régions désordonnées, fournissant de nouvelles idées pour la prédiction de structures protéiques désordonnées basées sur des méthodes d'apprentissage en profondeur, et élargissant encore le champ d'application d'AlphaFold. Cet article est une interprétation détaillée et un partage de la recherche.
Voir le rapport complet :https://go.hyper.ai/6Bbhc
Des études ont montré que lorsque les professionnels travaillent avec des images médicales pendant une longue période, le taux d’erreur de limite causé par la fatigue visuelle peut atteindre 12%. Pour résoudre ce problème, NVIDIA s’est récemment associé à d’autres équipes de recherche pour proposer un modèle de segmentation d’images médicales multimodales VISTA3D. Ce modèle a été le pionnier d'une méthode d'extraction de caractéristiques de super-voxels tridimensionnels et a permis une optimisation collaborative de la segmentation automatique tridimensionnelle et de la segmentation interactive grâce à une architecture unifiée. Dans un test de référence complet impliquant 23 ensembles de données, sa précision de segmentation a été améliorée de 5,2% par rapport au modèle expert optimal existant. Les résultats pertinents ont été publiés sous forme de pré-impression sur arXiv. Cet article est une interprétation détaillée et un partage de la recherche.
Voir le rapport complet :https://go.hyper.ai/D19LU
Articles populaires de l'encyclopédie
1. DALL-E
2. Fusion de tri réciproque RRF
3. Front de Pareto
4. Compréhension linguistique multitâche à grande échelle (MMLU)
5. Apprentissage contrastif
Voici des centaines de termes liés à l'IA compilés pour vous aider à comprendre « l'intelligence artificielle » ici :

Suivi unique des principales conférences universitaires sur l'IA :https://go.hyper.ai/event
Voici tout le contenu de la sélection de l’éditeur de cette semaine. Si vous avez des ressources que vous souhaitez inclure sur le site officiel hyper.ai, vous êtes également invités à laisser un message ou à soumettre un article pour nous le dire !
À la semaine prochaine !








