Command Palette
Search for a command to run...
Précision Améliorée Par 5.2%, NVIDIA Et d'autres Ont Publié Un Modèle De Segmentation d'images Médicales Multimodales Pour Réaliser Une Segmentation Et Une Interaction Automatiques Des Images 3D
Depuis la naissance du premier scanner clinique en 1971, l’imagerie médicale a connu un bond révolutionnaire, passant des coupes bidimensionnelles à la stéréo tridimensionnelle. Le scanner spiralé moderne à 256 rangées peut collecter des données de numérisation du corps entier avec une épaisseur de couche de 0,16 mm en 0,28 seconde, et l'imagerie par résonance magnétique à champ ultra-élevé 7T peut même capturer la direction microscopique des fibres nerveuses dans l'hippocampe. Cependant, lorsque ces matrices tridimensionnelles contenant des dizaines de millions de voxels sont présentées aux médecins, la tâche de segmentation précise des organes, des lésions et des réseaux vasculaires dépend encore fortement du contour manuel couche par couche. Des études ont montré que la segmentation du foie pour un ensemble typique d’images CT abdominales prend 45 à 90 minutes, tandis que l’annotation de la planification de la radiothérapie impliquant une liaison multi-organes peut durer plus de 8 heures.Le taux d'erreur de limite causé par la fatigue visuelle des professionnels peut atteindre 12%.
Ce dilemme a donné naissance à la piste d’innovation la plus active dans le domaine de l’analyse d’images médicales. Depuis l'algorithme de croissance de région basé sur un seuil de niveaux de gris, jusqu'à la variante tridimensionnelle U-Net V-Net qui intègre l'apprentissage profond, en passant par l'architecture hybride TransUNet qui introduit le transformateur visuel, les ingénieurs algorithmiques ont constamment essayé de construire des systèmes de navigation intelligents dans le labyrinthe de pixels. Les dernières avancées de la conférence MICCAI 2024 ont montré que certains modèles ont atteint une cohérence intergroupe comparable à celle des radiologues expérimentés dans les tâches de segmentation de la prostate, mais leurs performances dans les cas rares de variations anatomiques fluctuent encore considérablement. Cela révèle une proposition philosophique technologique plus profonde : lorsque l’IA tente de comprendre le corps humain, quelle quantité de connaissances préalables est nécessaire et quelle quantité de connaissances anatomiques au-delà de la cognition humaine peut-elle générer ?
Récemment, une équipe interdisciplinaire composée de NVIDIA, de l'Université de l'Arkansas pour les sciences médicales, des National Institutes of Health et de l'Université d'Oxford a publié un résultat de recherche révolutionnaire : le modèle de segmentation d'images médicales multimodales VISTA3D.Ce modèle a été le pionnier d’une méthode d’extraction de caractéristiques de supervoxels 3D.Grâce à une architecture unifiée, il réalise l'optimisation collaborative de la segmentation automatique 3D (couvrant 127 structures anatomiques) et de la segmentation interactive. Dans un test de référence complet contenant 14 ensembles de données, il obtient la segmentation automatique et l'édition interactive 3D les plus avancées, et améliore les performances à échantillon zéro de 50%.
Les résultats de recherche pertinents sont intitulés « VISTA3D : un modèle de fondation de formation unifiée pour l'imagerie médicale 3D » et ont été publiés sous forme de pré-impression sur arXiv.

Adresse du document :
https://doi.org/10.48550/arxiv.2406.05285
Changements de paradigme et défis de la technologie d'imagerie médicale 3D
Dans la vague numérique de l'analyse d'images médicales, la technologie de segmentation automatique 3D subit un changement de paradigme du « spécialiste » au « médecin généraliste ». Les méthodes traditionnelles construisent des architectures de réseau dédiées et des stratégies de formation personnalisées pour créer des modèles experts indépendants pour chaque structure anatomique ou type de pathologie. Bien que ce modèle soit performant dans des tâches spécifiques, c’est comme demander aux radiologues de recevoir à plusieurs reprises une formation au diagnostic d’un seul organe.Lorsqu'il est confronté à un scanner corporel complet contenant 127 structures anatomiques, le système doit exécuter des dizaines de modèles en parallèle, et sa consommation de ressources informatiques et la complexité de l'intégration des résultats augmentent de manière exponentielle.
Plus important encore, ce qui dérange vraiment les médecins dans la pratique clinique sont souvent ces rares cas qui brisent l’atlas anatomique standard : il peut s’agir de foyers de calcification à l’échelle nanométrique nouvellement découverts dans le foie de souris expérimentales, ou de formes de vaisseaux sanguins non conventionnelles formées en raison de variations anatomiques chez les patients transplantés. Ces scénarios révèlent des failles fondamentales dans le système existant :Une dépendance excessive aux catégories prédéfinies et à la formation fermée rend difficile pour le modèle d'apprendre des échantillons nuls et de s'adapter aux domaines ouverts.
L’aube d’une avancée décisive dans ce dilemme vient du domaine du traitement d’images naturelles. Lorsque les grands modèles de langage ont démontré des capacités de généralisation étonnantes sur plusieurs tâches, la communauté de l’imagerie médicale a commencé à explorer la création de systèmes intelligents « conversationnels ». SAM (Segment Anything Model) proposé par Meta réalise l'interaction révolutionnaire du « clic pour segmenter » dans des images bidimensionnelles, et ses performances à échantillon zéro surpassent même certains modèles professionnels. Mais lorsque l’on transpose ce paradigme dans le domaine de la médecine tridimensionnelle, la simple expansion dimensionnelle rencontre des défis fondamentaux : la complexité topologique des organes humains dans les tomographies continues est loin d’être comparable à celle d’un véhicule en mouvement dans une vidéo.
En prenant la segmentation du foie comme exemple, la bifurcation de la veine porte, l'infiltration tumorale et les artefacts métalliques des clips chirurgicaux peuvent exister simultanément entre des tranches adjacentes, ce qui nécessite que le modèle ait de véritables capacités de raisonnement spatial tridimensionnel plutôt qu'un simple suivi de séries chronologiques. Auparavant, les chercheurs ont essayé de rendre l’architecture SAM tridimensionnelle et ont formé les systèmes SAM2 et SAM3D. Bien que des progrès aient été réalisés dans des tâches telles que le suivi vasculaire,Cependant, son coefficient de Dice est toujours de 9 à 15 points de pourcentage inférieur à celui du modèle professionnel.Le taux d’erreur augmente considérablement, en particulier lorsqu’il s’agit de zones de chevauchement de plusieurs organes.
La contradiction la plus profonde réside dans la nature unique des données médicales, qui dépendent des connaissances. Lorsque la segmentation naturelle de l'image peut s'appuyer sur des caractéristiques statistiques au niveau des pixels,L’analyse d’images médicales doit intégrer les connaissances anatomiques préalables.Par exemple, la segmentation du pancréas nécessite non seulement d’identifier les caractéristiques en niveaux de gris, mais également de comprendre sa proximité anatomique avec le duodénum. Cela a donné naissance à un nouveau paradigme d’apprentissage basé sur le contexte : guider le modèle pour s’adapter à de nouvelles catégories en saisissant des exemples d’images ou de descriptions textuelles.
Cependant, les problèmes exposés par les systèmes existants lors des tests sont assez ironiques : exiger des cliniciens qu’ils fournissent des exemples d’annotations de haute qualité va à l’encontre de l’intention initiale de la segmentation automatisée ; et le biais d’alignement sémantique guidé par le texte peut conduire à une identification erronée du cholangiocarcinome hilaire comme structure vasculaire normale. Le paradoxe de cette voie technique reflète la proposition fondamentale dans le développement de l’IA médicale :Il peut être plus pratique d’établir un équilibre dynamique entre l’adaptation du domaine ouvert et la sécurité clinique que de simplement rechercher les performances de l’algorithme.
VISTA3D : un modèle de base de segmentation unifié pour l'imagerie médicale 3D
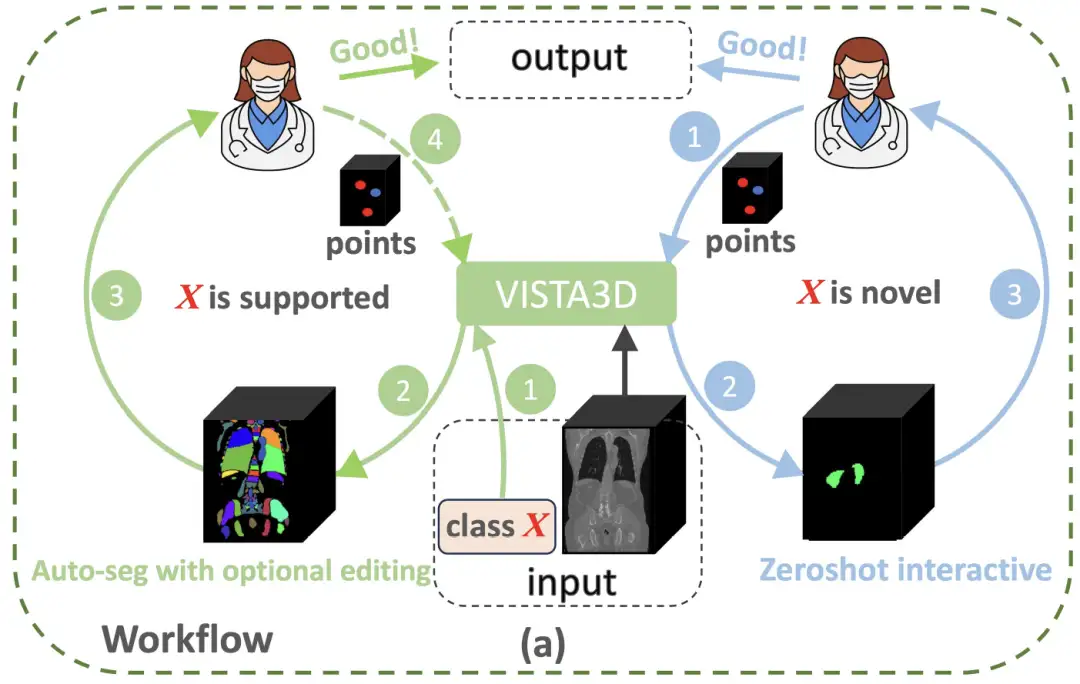
Afin de dépasser les limites paradigmatiques de l'analyse d'images médicales 3D,L'équipe de recherche de NVIDIA a construit une architecture innovante qui combine les avantages de la pré-formation bidimensionnelle avec des caractéristiques anatomiques tridimensionnelles : le modèle VISTA3D.Comme le montre la figure ci-dessous, si la tâche de segmentation X appartient aux 127 catégories prises en charge (cercles verts à gauche), VISTA3D effectuera une segmentation automatique (Auto-seg) avec une grande précision. Les médecins peuvent examiner et modifier efficacement les résultats à l’aide de VISTA3D si nécessaire. Si X est une nouvelle classe (cercle bleu à droite), VISTA3D effectuera une segmentation interactive 3D à tir nul.
Spécifiquement,L'architecture du modèle VISTA3D adopte un concept de conception modulaire et construit un noyau de segmentation 3D basé sur SegResNet, qui a été largement vérifié dans le domaine de l'imagerie médicale.Cette architecture réseau en forme de U a démontré d'excellentes performances dans les défis internationaux de segmentation faisant autorité tels que BraTS 2023. Comme le montre la figure ci-dessous, si l'utilisateur fournit une invite de classe appartenant aux 127 catégories prises en charge, la branche automatique en haut activera la fonction de division automatique prête à l'emploi. Si l'utilisateur fournit des invites de points 3D, la branche interactive en bas activera la fonction de segmentation interactive. Si les deux branches sont activées, le module de fusion basé sur un algorithme utilisera les résultats interactifs pour modifier les résultats automatiques.
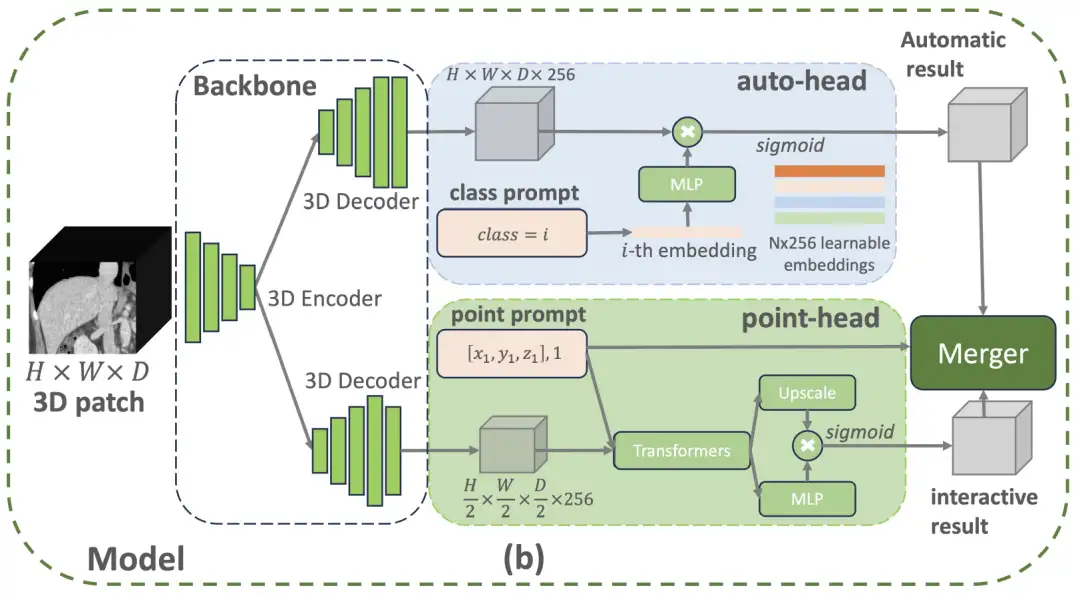
Parmi eux, la branche automatique utilise une technologie de codage intelligente pour gérer 127 structures du corps humain. Lorsqu'il est nécessaire de localiser une pièce spécifique, le système fera correspondre avec précision les informations de caractéristiques dans l'image numérisée et générera le résultat de segmentation grâce à une conversion intelligente.Cette conception permet d'économiser 60% de ressources mémoire par rapport aux méthodes traditionnelles et peut également éviter les biais d'apprentissage causés par des annotations incomplètes.Le module de correction manuelle utilise la technologie de positionnement par clic tridimensionnel : restaurez d'abord les détails de l'image, puis optimisez la vitesse de traitement. L'emplacement sur lequel le médecin a cliqué sera converti en coordonnées spatiales et associé intelligemment aux fonctionnalités de numérisation. Lorsqu'il rencontre des structures facilement déroutantes telles que le pancréas et les tumeurs, le système ajoute automatiquement des marques distinctives.
Les deux modules réalisent un réglage précis grâce à une collaboration intelligente. L'opération de correction n'affectera que la zone locale connectée à la position du clic, tout comme l'utilisation d'un scalpel de précision pour modifier une partie spécifique sans détruire le résultat global de la segmentation.Cette solution d'optimisation tridimensionnelle améliore l'efficacité de correction des médecins par 40%.Au cours de la phase de formation du modèle, l'équipe de recherche a également intégré 11 454 ensembles de données de tomodensitométrie, adopté un mécanisme de génération de pseudo-étiquettes dans un cadre d'apprentissage semi-supervisé et l'a combiné avec une stratégie de formation progressive en quatre étapes. Ils ont d'abord effectué une pré-formation sur un ensemble de données mixtes (comprenant des pseudo-étiquettes et des annotations de super-voxels), puis ont affiné respectivement les tâches de segmentation automatique et de correction interactive, et ont finalement réalisé une intégration fonctionnelle grâce à une formation conjointe. En fin de compte, le modèle VISTA3D réalise de multiples avancées technologiques grâce à des innovations fondamentales.
Dans un premier temps, le modèle a été validé systématiquement sur 14 ensembles de données publiques internationales, couvrant 127 types de structures anatomiques et de caractéristiques pathologiques.Sa précision de segmentation automatique 3D (coefficient de Dice 0,91±0,05) est 8,3% supérieure à celle du modèle de base traditionnel.Il prend également en charge la correction interactive par clic, réduisant le temps nécessaire à la correction manuelle à 1/3 de la méthode traditionnelle. Deuxièmement, la première technologie de transfert de caractéristiques supervoxel 3D, en découplant les caractéristiques spatiales du réseau dorsal pré-entraîné 2D, a permis d'obtenir une amélioration de 50% mIoU dans les tâches à tir nul telles que la segmentation du pancréas.L’efficacité de l’étiquetage est 2,7 fois supérieure à celle de l’apprentissage supervisé.En outre, l’équipe de recherche a également construit un ensemble de données multimodales interinstitutionnelles.Tout en maintenant la précision d'annotation de 97,2%, le coût d'annotation des données est compressé à 15% d'annotation manuelle complète.
Progrès de la recherche sur l'intégration de l'imagerie médicale 3D et de l'IA en Chine
Ces dernières années, avec l'application généralisée de la technologie de l'IA dans le domaine médical, la combinaison de la technologie d'imagerie médicale tridimensionnelle et de l'intelligence artificielle est progressivement devenue un point chaud de la recherche et a fait des progrès significatifs en Chine, apportant de nouvelles opportunités pour le diagnostic et le traitement médicaux.
En 2023, l’application de l’IA en imagerie médicale se concentrera principalement sur le diagnostic auxiliaire. L’IA peut rapidement passer au crible d’énormes ensembles de données d’images et d’informations sur les patients pour améliorer l’efficacité du diagnostic. Par exemple, certains systèmes d’imagerie intégrés à l’IA peuvent détecter de minuscules anomalies difficiles à identifier à l’œil nu, améliorant ainsi la précision du diagnostic. De plus, l’IA peut récupérer les images précédentes du dossier médical électronique d’un patient et les comparer avec l’image la plus récente, fournissant ainsi aux médecins des informations diagnostiques plus complètes. Par exemple,L'Université Jiao Tong de Shanghai a proposé un nouveau modèle de travail PnPNet pour la segmentation d'images médicales 3D.Le problème de la confusion des limites inter-classes est résolu en modélisant la dynamique d'interaction entre les régions limites qui se croisent et leurs régions adjacentes. Les performances sont SOTA, surpassant celles de réseaux tels que MedNeXt, Swin UNETR et nnUNet.
* Adresse du papier :
https://arxiv.org/abs/2312.08323
En 2024, l’intégration de la technologie d’imagerie médicale 3D et de l’IA se rapprochera et les orientations de recherche se diversifieront. D'une part, l'application de la technologie de l'IA dans la reconstruction tridimensionnelle d'images médicales a progressivement mûri et peut effectuer automatiquement la segmentation et la reconstruction d'images tridimensionnelles, améliorant ainsi la précision et l'efficacité de la reconstruction d'images. D’autre part, les capacités de l’IA en matière d’analyse d’images ont également été améliorées, ce qui peut aider les médecins à diagnostiquer les maladies et à formuler des plans de traitement. En outre, la technologie de l’IA est également appliquée au post-traitement des images, comme la réduction du bruit, l’amélioration et le rendu, pour améliorer la lisibilité et l’esthétique des images. Par exemple,L'hôpital de Chine occidentale de l'université du Sichuan a développé de manière innovante le système chinois de rapport et de données sur les nodules pulmonaires (C-Lung-RADS) basé sur les données de la cohorte de dépistage du cancer du poumon de la population chinoise et de la cohorte clinique des nodules pulmonaires.Une évaluation précise et une gestion personnalisée du risque de malignité des nodules pulmonaires ont été obtenues.
* Adresse du papier :
https://www.nature.com/articles/s41591-024-03211-3
D’ici 2025, l’application de la technologie de l’IA à l’imagerie médicale tridimensionnelle sera plus étendue et plus approfondie. Par exemple,Une équipe de recherche de l'Université de Pékin a récemment lancé un « Projet de groupe d'imagerie rénale » à l'échelle internationale.Il est prévu de prendre l’initiative de construire une carte numérique de l’ensemble du rein grâce à la technologie d’imagerie multimodale et aux algorithmes d’intelligence artificielle. Ce « rein numérique » peut rendre le mécanisme de la maladie rénale plus clairement visible et fournir une nouvelle direction pour le diagnostic précis, le développement de nouveaux médicaments et le traitement précis de la maladie rénale.
en même temps,Une équipe de l'Université chinoise des géosciences et de Baidu a proposé conjointement un cadre général appelé ConDSeg pour la segmentation d'images médicales basée sur le contraste.Ce cadre introduit de manière innovante une stratégie de formation au renforcement de la cohérence, un module de découplage des informations sémantiques, un module d'agrégation de fonctionnalités basé sur le contraste et un décodeur sensible à la taille, améliorant ainsi encore la précision du modèle de segmentation d'images médicales.
* Adresse du papier :
https://arxiv.org/abs/2412.08345
De plus, l'Université des sciences et technologies de Kunming et l'Université océanique de Chine ont proposé une méthode de fusion d'images médicales non alignées par alignement bidirectionnel des caractéristiques par étapes (BSFA). Par rapport aux méthodes traditionnelles, cette étude aligne et fusionne simultanément des images médicales multimodales non alignées grâce à une approche en une seule étape dans un cadre de traitement unifié, ce qui permet non seulement de coordonner les tâches doubles, mais réduit également efficacement le problème de complexité du modèle causé par l'introduction de plusieurs encodeurs de fonctionnalités indépendants.
* Adresse papier:
https://doi.org/10.48550/arXiv.2412.08050
Cependant, la recherche sur la combinaison de la technologie d’imagerie médicale 3D avec l’IA est également confrontée à certains défis. Des questions telles que la confidentialité des données, la transparence des algorithmes, la capacité de généralisation des modèles et la supervision réglementaire restent des questions clés qui doivent être traitées. À l’avenir, avec les progrès continus de la technologie et l’amélioration des réglementations, ces problèmes pourront être progressivement résolus, favorisant ainsi une application plus large de la technologie de l’IA dans le domaine de l’imagerie médicale.








