Command Palette
Search for a command to run...
Le Cours De L’action N’a Pas Réussi À Arrêter Sa chute. Huang Renxun a Révélé l'heure De Lancement De Blackwell Ultra Et Vera Rubin, Et La Capacité De Raisonnement Est Devenue Le Centre d'intérêt

Ces dernières années, NVIDIA a été présente dans presque toutes les grandes tendances du domaine technologique mondial, du cloud computing à la cryptomonnaie, du métaverse à l'intelligence artificielle. Surtout dans la nouvelle vague d'intelligence artificielle, NVIDIA, avec sa profonde accumulation technologique, contrôle fermement la part de marché des GPU des centres de données d'environ 95%, devenant ainsi le leader absolu dans le domaine des puces d'IA.
Cependant, plus tôt cette année,DeepSeek L’émergence des modèles d’inférence a envoyé un signal clair au public : le modèle du « grand effort pour réaliser des miracles » qui reposait autrefois sur l’accumulation de données et de puissance de calcul est progressivement devenu inefficace. Cela a ébranlé les attentes du marché quant aux perspectives de puissance de calcul de l'IA, et les cours des actions de nombreux géants de la technologie, dont Nvidia, ont fortement chuté. Bien que le cours de l'action Nvidia se soit depuis redressé, sa domination dans le secteur n'est plus aussi inébranlable qu'elle l'était autrefois. Afin de prouver la force de l'entreprise, Nvidia devra mettre à niveau et mettre à jour de manière exhaustive son GPU.
Lors de la conférence GTC 2025 qui s'est tenue à 1 heure du matin, heure de Pékin, le 19 mars, Huang Renxun a apporté les dernières nouvelles concernant les puces Nvidia :La version améliorée de l'architecture de puce IA Blackwell, Blackwell Ultra, sera lancée au second semestre de cette année. NVIDIA GB300 NVL72 et NVIDIA HGX™ B300 NVL16 amélioreront considérablement les capacités de raisonnement des modèles. L'architecture GPU de nouvelle génération de NVIDIA, Vera Rubin, sera disponible l'année prochaine.
NVIDIA Blackwell Ultra accélère l'inférence de l'IA
Lors de la conférence GTC de l'année dernière, Huang Renxun a annoncé l'architecture de puce IA de nouvelle génération Blackwell. Trémie Successeur du GPU NVIDIA GeForce, l'architecture Blackwell compte 208 milliards de transistors et se concentre sur l'accélération des tâches d'IA générative, de la formation à grande échelle et des charges de travail d'inférence. Huang Renxun a fièrement déclaré dans son discours qu'il s'agissait de la série de puces IA la plus puissante à ce jour.

Dans l'émission en direct d'aujourd'hui, Huang Renxun a de nouveau mentionné Blackwell.Il a déclaré : « Les avantages de Blackwell sont qu'il est plus rapide, plus grand, qu'il possède plus de transistors et une puissance de calcul plus élevée. » De plus, l'architecture NVL 72 + le modèle de précision de calcul FP4 qu'il adopte améliorent également les performances de Blackwell, ce qui signifie que nous pouvons effectuer les mêmes tâches de calcul avec une consommation d'énergie moindre.
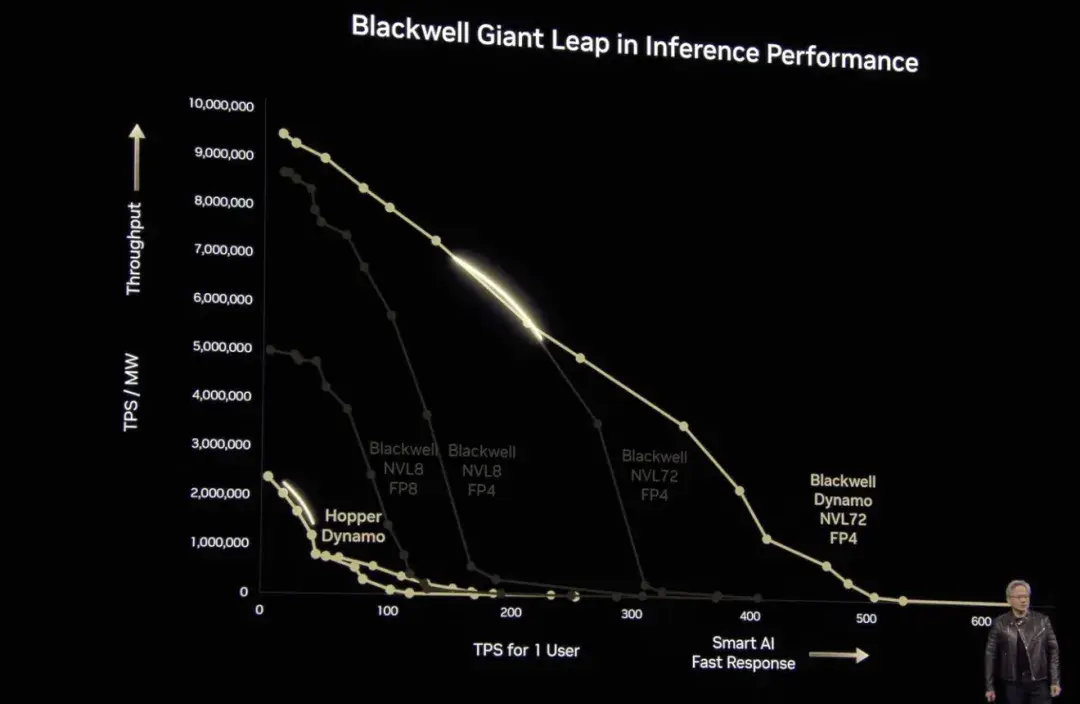
Il convient de mentionner qu’après l’émergence de DeepSeek, l’accent du marché de l’intelligence artificielle s’est progressivement déplacé de la « formation » vers « l’inférence ». Lors de cette conférence, Huang Renxun a spécifiquement cité un cas de modèle d'inférence pour prouver la supériorité des performances informatiques de Blackwell - 40 fois supérieures à celles de Hopper. « Je l'ai déjà dit : si Blackwell commence à les expédier en volume, vous ne pourrez même pas faire venir Hopper. » Bien entendu, Huang Renxun a également mentionné que Blackwell est pleinement investi dans la production et que l'usine d'IA NVIDIA Blackwell sera à nouveau modernisée au cours du second semestre de cette année.Et passez en toute transparence à Blackwell Ultra.

Blackwell Ultra inclura la solution rackable NVIDIA GB300 NVL72, et NVIDIA HGX B300 NVL16 système.
Tout d'abord, le NVIDIA GB300 NVL72 utilise une conception montée en rack entièrement refroidie par liquide qui contient 72 GPU NVIDIA Blackwell Ultra et 36 NVIDIA basés sur Arm Processeur Grace™ Intégrez-vous dans une plate-forme unique optimisée pour l'inférence évolutive au moment des tests. Par rapport à la génération précédente NVIDIA GB200 NVL72, le GB300 NVL72 a des performances d'IA 1,5 fois supérieures, peut explorer plusieurs solutions et décomposer des tâches complexes en plusieurs étapes pour générer des réponses de meilleure qualité.
Deuxièmement, NVIDIA HGX B300 NVL16 constitue une avancée majeure pour le traitement efficace de tâches complexes telles que le raisonnement IA. Comparé à Hopper, il augmente la vitesse de raisonnement des grands modèles de langage de 11 fois, augmente la puissance de calcul de 7 fois et augmente la capacité de mémoire de 4 fois.
En résumé, Blackwell Ultra améliore l’inférence étendue au moment de la formation et des tests, offrant un support solide pour des applications telles que le raisonnement IA accéléré, l’agent IA et l’IA physique.
À cet égard, Huang Renxun a déclaré : « La technologie de l'IA a fait un bond en avant considérable, et la demande de performances de calcul pour le raisonnement et les agents d'IA a considérablement augmenté. À cette fin, nous avons conçu Blackwell Ultra, une plateforme multifonctionnelle capable d'effectuer efficacement des tâches de pré-entraînement, de post-entraînement et de raisonnement. »
L'architecture GPU de nouvelle génération de Nvidia Vera Rubin
Nvidia donne à ses architectures le nom de scientifiques depuis 1998, et cette fois-ci ne fait pas exception.La prochaine architecture GPU de nouvelle génération de Nvidia, Vera Rubin, porte le nom de Vera Rubin, l'astronome américaine qui a découvert la matière noire.

Vera Rubin a intégré pour la première fois en profondeur l'architecture CPU et GPU développée par ses soins.Cela marque une nouvelle avancée pour NVIDIA dans l’architecture informatique de l’IA, repoussant encore les limites des performances de calcul de l’IA.
« En gros, tout est nouveau, sauf le châssis », a déclaré Huang Renxun. En tant que première architecture CPU entièrement conçue de manière indépendante par NVIDIA, Vera est construite sur un cœur Arm personnalisé. Il s'agit d'un petit processeur de seulement 50 watts, mais avec une mémoire plus grande et une bande passante plus élevée. Selon les données officielles de NVIDIA, les performances de calcul de Vera sont directement augmentées de 2 fois par rapport à Grace Blackwell. De plus, il est également profondément optimisé pour les charges d'IA. En optimisant l'ensemble d'instructions, la latence de communication est considérablement réduite, ce qui rend le traitement des données plus efficace et plus fluide, offrant un support solide pour la formation et le raisonnement de l'IA.
Dans le même temps, le nouveau GPU Rubin représente également un nouveau bond en avant dans le domaine de l’informatique de l’IA. Lorsqu'il est exécuté avec Vera, le calcul d'inférence Rubin peut atteindre 50 pétaflops, soit plus de 2 fois les performances des GPU Blackwell existants. De plus, Rubin prend également en charge jusqu'à 288 Go de mémoire haute vitesse, garantissant que la formation et le raisonnement de l'IA peuvent traiter efficacement d'énormes quantités de données.
Huang Renxun a également révélé que Vera Rubin NVL144 sera disponible au second semestre de l'année prochaine.Au cours du second semestre 2027, NVIDIA prévoit de lancer Vera Rubin Ultra, qui utilise la technologie NVL576 et se compose de 2,5 millions de composants. Chaque rack a une puissance allant jusqu'à 600 kilowatts. Le nombre d’opérations en virgule flottante augmentera de 14 fois pour atteindre 15 exaflops, permettant ainsi une évolutivité extrême.

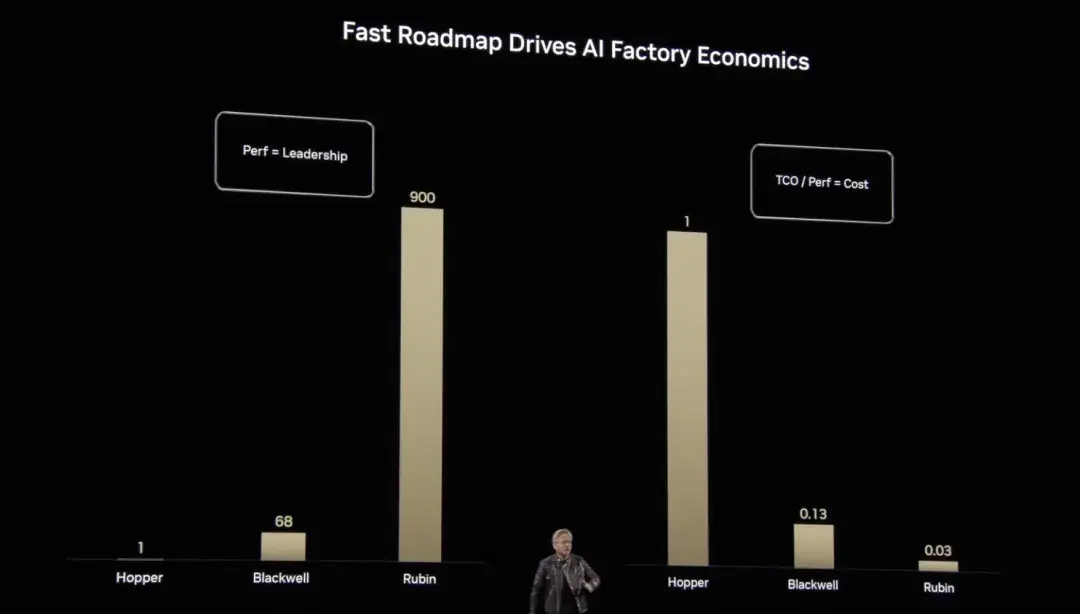
De Grace Hopper à Blackwell et maintenant à Rubin, Huang Renxun nous a montré les progrès de NVIDIA en matière de performances de calcul et d'optimisation des coûts.Par rapport à la puissance de calcul de référence, les opérations à virgule flottante étendues verticalement de Hopper sont 1 fois supérieures à la référence, Blackwell l'augmente à 68 fois et Rubin passe à 900 fois, réalisant une croissance exponentielle. Cette avancée non seulement réduit considérablement le coût unitaire du calcul de l’IA, mais rend également la formation et le raisonnement de modèles d’IA plus complexes et à grande échelle efficaces et réalisables.
Nvidia fournira des services complets pour la construction d'usines d'IA
Ces dernières années, l’accent du domaine de l’IA s’est progressivement déplacé de la formation de grands modèles vers l’application généralisée de modèles d’inférence. L’inférence est devenue le principal moteur de la croissance rapide de l’économie de l’IA. Ce changement modifie non seulement le paysage technologique, mais impose également de nouvelles exigences en matière d’infrastructure informatique. Les centres de données traditionnels ne sont pas conçus pour la nouvelle ère de l’IA. Afin de promouvoir efficacement le raisonnement et le déploiement de l'IA, les usines d'IA (Usines d'IA) a vu le jour.
Les usines d'IA non seulement stockent et traitent les données, mais « produisent également de l'intelligence » à grande échelle, transformant les données brutes en informations en temps réel. NVIDIA a déclaré : « Investir dans des entreprises spécialisées dans la construction d'usines d'IA permettra de prendre la tête du marché futur. »
Pour soutenir cette transformation, NVIDIA a créé les éléments de base des usines d'IA full-stack et fournit à ses partenaires les composants clés suivants : puces de calcul hautes performances, technologies réseau avancées, gestion de l'infrastructure et orchestration de la charge de travail, le plus grand écosystème d'inférence d'IA, plates-formes de stockage et de données, plans de conception et d'optimisation, architectures de référence et méthodes de déploiement flexibles.

Il ne fait aucun doute que la puissance de calcul est le pilier central des usines d’IA. Des architectures Hopper à Blackwell, NVIDIA offre le calcul accéléré le plus puissant au monde. Grâce à la solution au niveau du rack GB300 NVL72 basée sur Blackwell Ultra, les usines d'IA peuvent atteindre jusqu'à 50 fois la sortie d'inférence d'IA et fournir un support de performances sans précédent pour le traitement de tâches complexes.








