Command Palette
Search for a command to run...
Les Meilleurs Acteurs De l'open Source Se Réunissent ! QwQ-32B Débloque Plusieurs Modes De Jeu, OpenManus Construit Des Agents IA À Faible Coût ! vLLM v1 Permet Un Raisonnement Efficace Sur Les Modèles

Au milieu de la vague de percées continues dans le domaine de l'intelligence artificielle, le dernier modèle de l'équipe Qwen, QwQ-32B, avec ses 32 milliards de paramètres, a une fois de plus rafraîchi la compréhension de l'industrie des grands modèles open source. Le modèle a démontré d'excellentes performances dans des tâches telles que la génération de code et le dialogue multi-tours, et sa capacité de raisonnement est comparable à celle de la version complète de DeepSeek-R1.
Il n'y a pas longtemps,L'architecture de base vLLM conçue spécifiquement pour accélérer le raisonnement sur les grands modèles a subi une mise à jour majeure.En optimisant les boucles d'exécution, les planificateurs unifiés et les caches de préfixes à surcharge nulle, il permet d'obtenir jusqu'à 1,7 fois plus de performances en termes de débit et de latence, permettant au QwQ-32B d'être déployé efficacement sur les cartes graphiques A6000 à double carte.
Dans le domaine des agents IA, OpenManus a pris de l'ampleur depuis son lancement. Ce projet open source, connu sous le nom d'« alternative Manus »,Non seulement il répond aux doutes extérieurs sur l'écosystème fermé grâce à la reproduction technologique, mais il fournit également aux développeurs une « clé principale » pour construire des entités intelligentes à faible coût grâce à une conception modulaire et à l'intégration de la chaîne d'outils.
Actuellement, HyperAI a lancé deux tutoriels : « Utiliser vLLM pour déployer QwQ-32B » et « OpenManus + QwQ-32B pour implémenter AI Agent ». Venez l'essayer~
Déployer QwQ-32B à l'aide de vLLM
Utilisation en ligne :https://go.hyper.ai/8nPfC
OpenManus + QwQ-32B implémente l'agent IA
Utilisation en ligne :https://go.hyper.ai/GIX1H
Du 10 au 15 mars, le site officiel de hyper.ai a été mis à jour rapidement :
* Ensembles de données publiques de haute qualité : 10
* Sélection de tutoriels de haute qualité : 4
* Sélection d'articles communautaires : 6 articles
* Entrées d'encyclopédie populaire : 5
* Principales conférences avec date limite en mars : 4
Visitez le site officiel :hyper.ai
Ensembles de données publiques sélectionnés
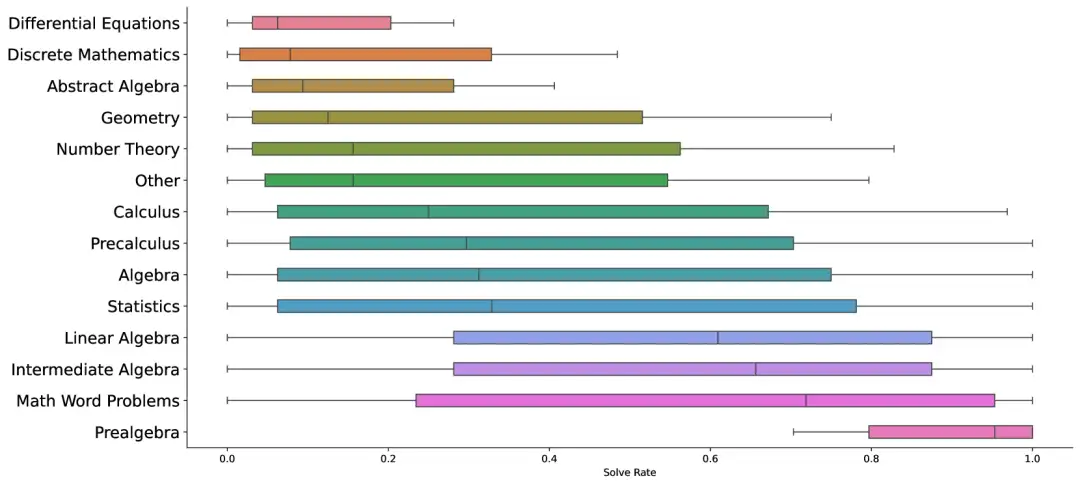
1. Ensemble de données mathématiques d'apprentissage par renforcement Big-Math
Big-Math est un ensemble de données mathématiques à grande échelle et de haute qualité conçu pour l'application de l'apprentissage par renforcement (RL) dans les modèles linguistiques. L'ensemble de données contient plus de 250 000 problèmes mathématiques de haute qualité, chacun avec une réponse vérifiable.
Utilisation directe :https://go.hyper.ai/qtlbQ
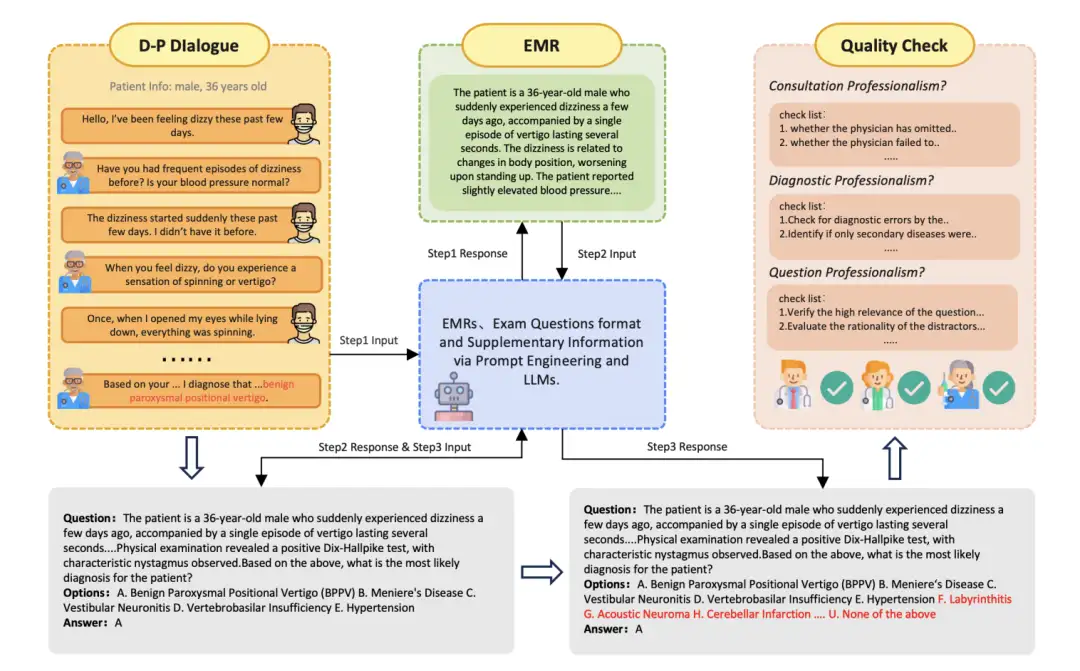
2. Ensemble de données médicales réelles chinoises JMED
L'ensemble de données JMED est un nouvel ensemble de données basé sur la distribution de données médicales du monde réel. L'ensemble de données est dérivé de conversations anonymes entre médecins et patients dans l'hôpital Internet JD Health et est filtré pour conserver les consultations qui suivent un flux de travail de diagnostic standardisé.
Utilisation directe :https://go.hyper.ai/FjZsa
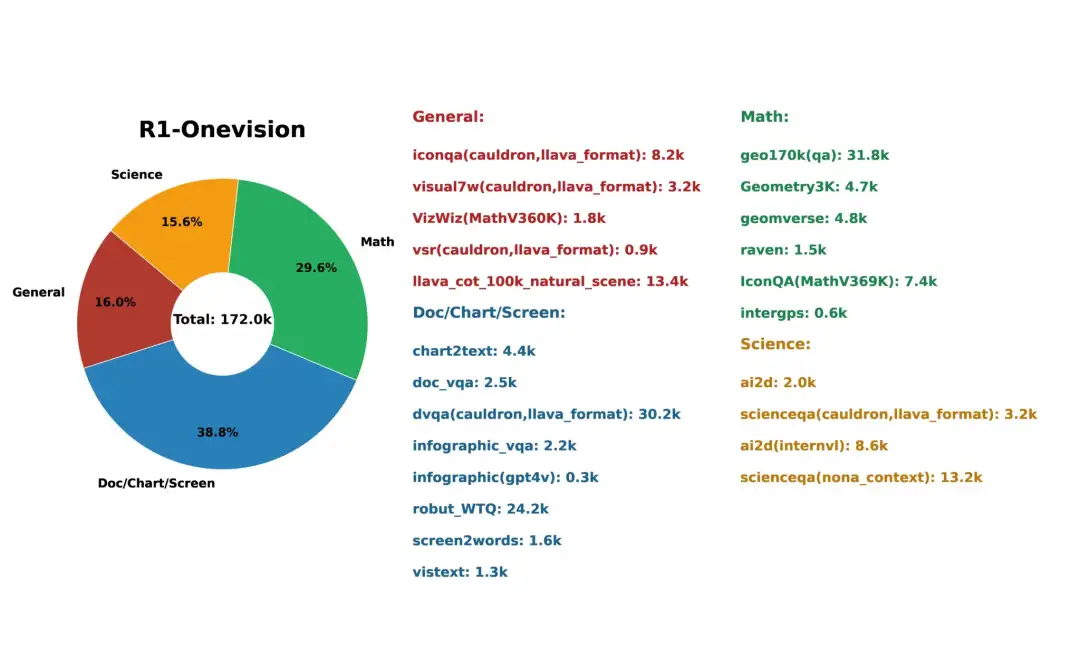
3. Ensemble de données de raisonnement multimodal R1-Onevision
L'ensemble de données R1-Onevision est conçu pour doter les modèles de capacités de raisonnement multimodal avancées. Il comble le fossé entre la compréhension visuelle et textuelle grâce à des tâches de raisonnement riches et contextuelles dans de multiples domaines tels que les scènes naturelles, les sciences, les problèmes mathématiques, le contenu basé sur l'OCR et les diagrammes complexes.
Utilisation directe :https://go.hyper.ai/jLbSI
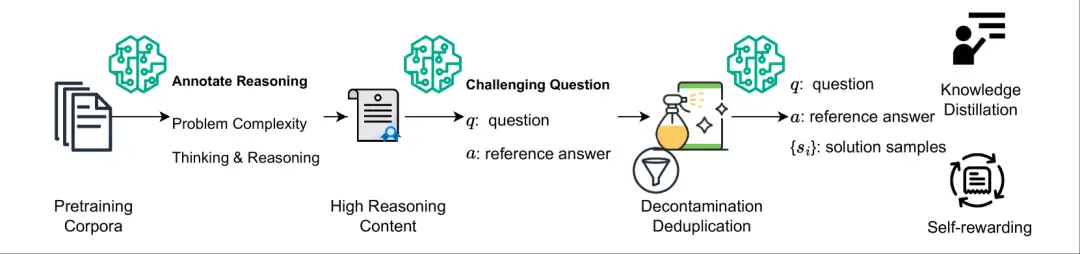
4. NaturalReasoning Ensemble de données de raisonnement naturel
L'ensemble de données NaturalReasoning est un ensemble de données de raisonnement à grande échelle et de haute qualité qui contient 2,8 millions de questions difficiles couvrant plusieurs domaines tels que les domaines STEM (par exemple, la physique, l'informatique), l'économie, les sciences sociales, etc. L'ensemble de données vise à générer des questions de raisonnement diverses et stimulantes et leurs réponses de référence en exploitant des corpus pré-entraînés et des grands modèles de langage (LLM) sans avoir besoin d'annotations humaines supplémentaires.
Utilisation directe :https://go.hyper.ai/Mb6Cd
5. Ensemble de données de collection de noyaux d'archives AI-CUDA-Engineer
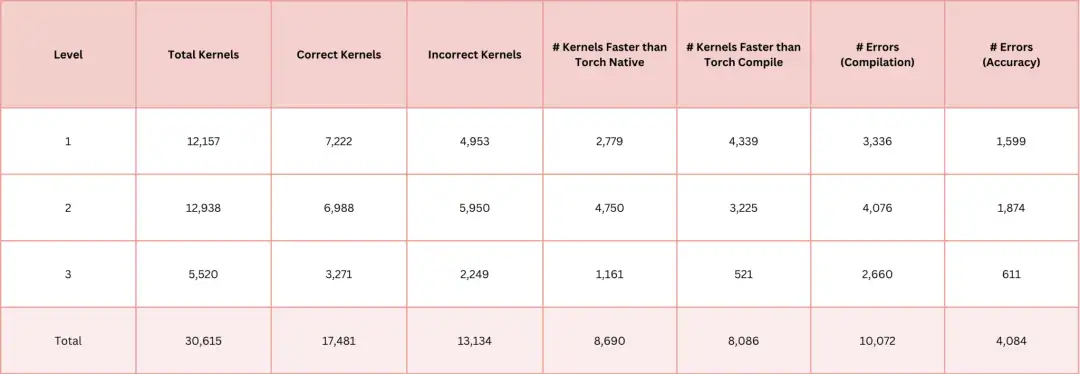
L'ensemble de données AI-CUDA-Engineer-Archive est une collection de noyaux CUDA générés par l'IA, qui vise à faciliter la formation ultérieure de modèles open source et le développement de meilleurs modules de fonctions CUDA. L'ensemble de données contient plus de 30 000 noyaux CUDA, tous générés par des ingénieurs CUDA pilotés par l'IA, dont plus de 17 000 noyaux ont été vérifiés comme étant corrects, et environ 50% de noyaux surpassent l'environnement d'exécution natif de PyTorch.
Utilisation directe :https://go.hyper.ai/3lPrI
6. Ensemble de données de chimie quantique QM9
L'ensemble de données QM9 est un ensemble de données de chimie quantique largement utilisé, contenant les résultats de calcul de chimie quantique d'environ 134 000 petites molécules organiques. Ces molécules sont composées des éléments carbone, hydrogène, azote, oxygène et fluor et ont un poids moléculaire ne dépassant pas 900 Daltons.
Utilisation directe :https://go.hyper.ai/PZdz7
7. Ensemble de données de conformation moléculaire 3D GEOM-Drugs
L'ensemble de données GEOM-Drugs est un grand ensemble de données de conformation moléculaire 3D contenant 430 000 molécules, chacune ayant en moyenne 44 atomes. Après traitement des données, chaque molécule peut contenir jusqu'à 181 atomes. Dans l’expérience, les chercheurs ont collecté les 30 conformations de plus faible énergie de chaque molécule et ont demandé à chaque méthode de base de générer les positions 3D et les types d’atomes constitutifs de ces molécules.
Utilisation directe :https://go.hyper.ai/5B3U8
8. Ensemble de données de divination chinoise Feng Shui sur la voyance
L'ensemble de données contient 207 questions sur le Feng Shui, le Bazi, etc., et chaque question a une réponse correspondante unique.
Utilisation directe :https://go.hyper.ai/31k1P
9. Ensemble de données de référence pour l'évaluation des domaines d'études SuperGPQA
SuperGPQA est un ensemble de données de référence permettant d'évaluer les performances des systèmes avancés de réponses aux questions. Il se concentre sur les domaines du traitement du langage naturel et de l'évaluation de l'apprentissage automatique, et vise à tester la capacité de raisonnement et le niveau de connaissance du modèle à travers des questions interdisciplinaires complexes. L'ensemble de données couvre 285 domaines d'études de niveau universitaire avec divers types de questions, notamment la biologie, la physique, la chimie et d'autres domaines scientifiques.
Utilisation directe :https://go.hyper.ai/oP1pb
10. olmOCR-mix-0225 Ensemble de données de documents PDF à grande échelle
olmOCR-mix-0225 est un ensemble de données de documents PDF à grande échelle et de haute qualité conçu pour la formation et l'optimisation des modèles de reconnaissance optique de caractères (OCR). L'ensemble de données contient environ 250 000 pages de contenu PDF, couvrant divers types tels que des articles universitaires, des documents juridiques et des manuels. L'ensemble de données contient non seulement du contenu textuel, mais extrait également les informations de coordonnées des éléments saillants (tels que les blocs de texte et les images) de chaque page. Ces informations sont injectées dynamiquement dans l’invite du modèle, réduisant considérablement les hallucinations du modèle.
Utilisation directe :https://go.hyper.ai/dXNkk
Tutoriels publics sélectionnés
1. Déploiement en un clic du QwQ-32B-AWQ
QwQ-32B est le modèle d'inférence de la série Qwen. Comparé aux modèles de réglage d'instructions traditionnels, QwQ possède des capacités de réflexion et de raisonnement et peut réaliser des améliorations significatives des performances dans les tâches en aval, en particulier les problèmes difficiles. Il est comparable aux modèles d’inférence avancés tels que DeepSeek-R1 et o1-mini.
Les modèles et dépendances pertinents de ce projet ont été déployés. Après avoir démarré le conteneur, cliquez sur l’adresse API pour accéder à l’interface Web.
Exécutez en ligne :https://go.hyper.ai/Q8HmJ

2. Déployer QwQ-32B à l'aide de vLLM
vLLM est un framework de raisonnement open source conçu pour un déploiement efficace de grands modèles de langage. Sa technologie de base réduit considérablement le seuil matériel pour le raisonnement du modèle en optimisant la gestion de la mémoire et l'efficacité du calcul. Ce didacticiel utilise vLLM pour déployer le modèle QwQ-32B afin de réduire davantage les coûts de déploiement et de répondre aux besoins de scénarios plus interactifs.
Les modèles et dépendances pertinents de ce projet ont été déployés. Après avoir démarré le conteneur, cliquez sur l’adresse API pour accéder à l’interface Web.
Exécutez en ligne :https://go.hyper.ai/8nPfC
3.OpenManus + QwQ-32B implémente l'agent IA
OpenManus est un projet open source lancé par l'équipe MetaGPT. Son objectif est de reproduire les fonctions principales de Manus et de fournir aux utilisateurs une solution d'agent intelligent qui peut être déployée localement sans code d'invitation.
Accédez au site Web officiel pour cloner et démarrer le conteneur, entrez dans l'espace de travail et entrez les commandes correspondantes pour découvrir le modèle.
Exécutez en ligne :https://go.hyper.ai/GIX1H
4. Step-Audio-TTS-3B Modèle de génération de parole dialectale au niveau de la production
Step-Audio est le premier système de dialogue vocal en temps réel open source de niveau produit du secteur qui intègre la compréhension de la parole et le contrôle de la génération. Il a été open source par l'équipe Stepfun-AI en 2025. Il prend en charge la génération multilingue (comme le chinois, l'anglais et le japonais), les émotions vocales (comme le bonheur et la tristesse) et les dialectes (comme le cantonais et le dialecte du Sichuan). Il peut contrôler la vitesse de la parole et le style rythmique, et prend en charge le RAP et le fredonnement, etc.
Accédez au site Web officiel pour cloner et démarrer le conteneur, copiez directement l'adresse API et vous pourrez effectuer une synthèse vocale multifonctionnelle.
Exécutez en ligne :https://go.hyper.ai/WiyVK
Articles de la communauté
Une équipe de l’Université d’Australie occidentale et d’autres institutions a proposé l’utilisation d’un cadre automatisé basé sur l’apprentissage profond. L’étude a utilisé 200 scanners crâniens provenant d’un hôpital indonésien pour former et tester trois configurations de réseau basées sur l’apprentissage profond. Le cadre d’apprentissage profond le plus précis a pu combiner les caractéristiques du genre et du crâne pour le jugement, avec une précision de classification de 97%, significativement supérieure aux 82% des observateurs humains. Cet article est une interprétation et un partage détaillés du document.
Voir le rapport complet :https://go.hyper.ai/0rfjM
Des chercheurs du laboratoire clé SIG provincial du Zhejiang ont proposé un modèle d'apprentissage profond CatGWR basé sur le mécanisme d'attention. Le modèle introduit un mécanisme d’attention pour combiner la distance spatiale et la similarité contextuelle entre les échantillons afin d’estimer plus précisément la non-stationnarité spatiale. Cela offre de nouvelles perspectives pour la modélisation géospatiale, en particulier lorsqu’il s’agit de phénomènes géographiques complexes, et peut mieux saisir l’hétérogénéité spatiale et les effets contextuels. Cet article est une interprétation détaillée et un partage de la recherche.
Voir le rapport complet :https://go.hyper.ai/irDAo
HyperAI a soigneusement compilé les ensembles de données de raisonnement les plus populaires, couvrant plusieurs domaines tels que les mathématiques, le code, la science, les puzzles, etc. Pour les praticiens et les chercheurs qui souhaitent améliorer considérablement les capacités de raisonnement des grands modèles, ces ensembles de données constituent sans aucun doute un excellent point de départ. Cet article est l'adresse de téléchargement du jeu de données.
Voir le rapport complet :https://go.hyper.ai/XGIi8
L'Université du Zhejiang et d'autres ont proposé une technique appelée alignement de Boltzmann, qui a transféré les connaissances du modèle de pliage inverse pré-entraîné à la prédiction de l'énergie libre de liaison. Cette méthode a été réalisée à un niveau supérieur et a été incluse dans l’ICLR 2025, la principale conférence universitaire internationale dans le domaine de l’intelligence artificielle. Cet article est une interprétation et un partage détaillés du document.
Voir le rapport complet :https://go.hyper.ai/MsUDj
NVIDIA, en collaboration avec le MIT et d'autres, a développé un nouveau type de générateur de protéines à flux à grande échelle, Proteina. Proteina possède 5 fois plus de paramètres que le modèle RFdiffusion et a étendu ses données de formation à 21 millions de structures protéiques synthétiques. Il a atteint des performances SOTA dans la conception de squelettes protéiques de novo et a généré des protéines diverses et concevables avec une longueur sans précédent allant jusqu'à 800 résidus. Ses résultats ont été sélectionnés pour l'ICLR 2025 Oral. Cet article est une interprétation détaillée et un partage de la recherche.
Voir le rapport complet :https://go.hyper.ai/n4fWv
Lei Jun, Zhou Hongyi, Liu Qingfeng et d'autres leaders de l'industrie ont suivi de près le pouls de l'époque et ont activement avancé des propositions et des suggestions dans de nombreux domaines clés tels que les véhicules à énergie nouvelle, les hallucinations de grands modèles, les soins médicaux de l'IA, le changement de visage de l'IA et l'éducation à l'IA. Voir ci-dessous pour plus de détails.
Voir le rapport complet :https://go.hyper.ai/EazuY
Articles populaires de l'encyclopédie
1. DALL-E
2. Fusion de tri réciproque RRF
3. Front de Pareto
4. Compréhension linguistique multitâche à grande échelle (MMLU)
5. Apprentissage contrastif
Voici des centaines de termes liés à l'IA compilés pour vous aider à comprendre « l'intelligence artificielle » ici :
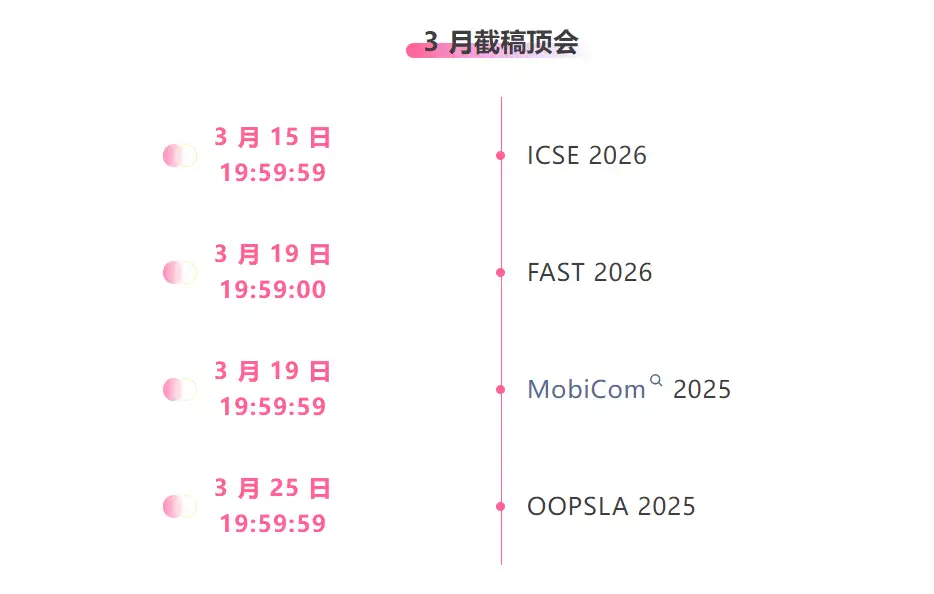
Suivi unique des principales conférences universitaires sur l'IA :https://go.hyper.ai/event
Voici tout le contenu de la sélection de l’éditeur de cette semaine. Si vous avez des ressources que vous souhaitez inclure sur le site officiel hyper.ai, vous êtes également invités à laisser un message ou à soumettre un article pour nous le dire !
À la semaine prochaine !








