Command Palette
Search for a command to run...
Ebook2Audiobook Convertit Les Livres Électroniques En Livres Audio En Un Clic ; Le Premier Ensemble De Données De Défi De Détection d'objets À Petits Échantillons inter-domaines De CVPR Est En Ligne

À l'ère de l'explosion de l'information, nos yeux sont depuis longtemps submergés : nous fixons les écrans de nos téléphones portables sur le chemin du travail, nous faisons face à des documents informatiques pendant que nous travaillons et nous nous immergeons dans le monde des romans avant d'aller nous coucher. Si un texte peut être transformé en une voix chaleureuse que l’on peut écouter en faisant du jogging le matin, en cuisinant ou en se reposant les yeux fermés, alors l’acquisition d’informations ne se limitera plus à la vision.
Ebook2Audiobook est un outil open source conçu pour convertir des livres électroniques (eBooks) en livres audio (audiobooks). Le projet utilise la technologie avancée de synthèse vocale (TTS) pour convertir le contenu textuel des livres électroniques en fichiers vocaux et générer des livres audio pouvant être écoutés.
à l'heure actuelle,Le tutoriel « Ebook2Audiobook, e-book to audiobook » est désormais en ligne sur le site officiel d'hyper.ai, le démarrage en un clic peut faire renaître votre bibliothèque de livres électroniques dans les ondes sonores, venez l'essayer~
Utilisation en ligne :https://go.hyper.ai/sgLbN
Du 3 au 7 mars, le site officiel de hyper.ai a été mis à jour rapidement :
* Ensembles de données publiques de haute qualité : 10
* Sélection de tutoriels de haute qualité : 3
* Sélection d'articles communautaires : 6 articles
* Entrées d'encyclopédie populaire : 5
* Principales conférences avec date limite en mars : 5
Visitez le site officiel :hyper.ai
Ensembles de données publiques sélectionnés
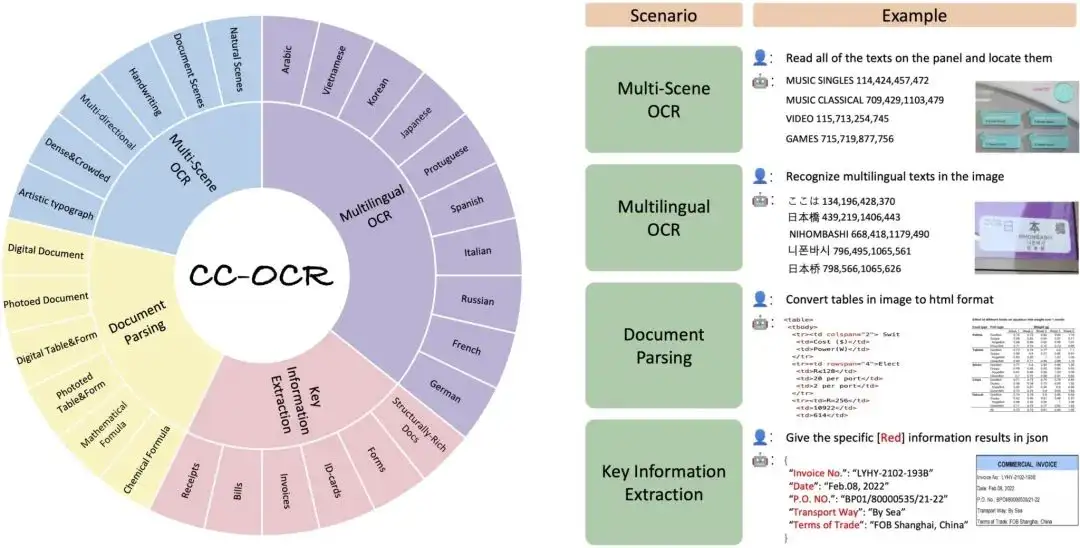
1. Ensemble de données de reconnaissance de texte CC-OCR
L'ensemble de données CC-OCR couvre quatre tâches principales : la lecture de texte multi-scènes, la lecture de texte multilingue, l'analyse de documents et l'extraction d'informations clés, et contient 39 sous-ensembles et 7 058 images entièrement annotées. Le lancement de CC-OCR comble le vide dans l’évaluation des modèles multimodaux actuels dans les structures complexes et les défis visuels à granularité fine, et est d’une grande importance pour promouvoir les progrès des modèles multimodaux dans les applications pratiques.
Utilisation directe :https://go.hyper.ai/rQT2y
2. Ensemble de données d'alignement des préférences multimodales MM-RLHF
Cet ensemble de données contient 120 000 paires de données de comparaison de préférences à granularité fine et annotées manuellement, couvrant trois domaines : la compréhension des images, l'analyse vidéo et la sécurité multimodale. La quantité de données dépasse de loin les ressources existantes, couvrant plus de 100 000 instances de tâches multimodales. Chaque élément de données a été soigneusement noté et interprété par plus de 50 annotateurs, garantissant la haute qualité et la granularité des données.
Utilisation directe :https://go.hyper.ai/sTfNc
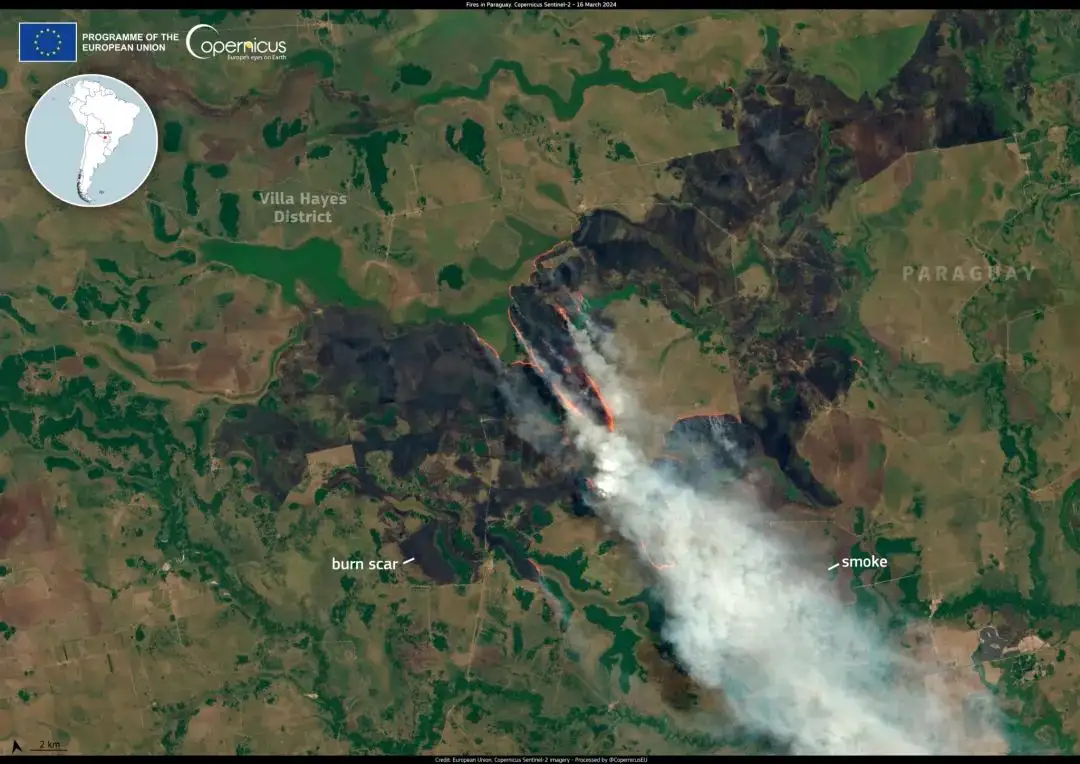
3. Ensemble de données de compréhension d'images de télédétection GAIA Visual Language
GAIA est un ensemble de données de vision-langage global, multimodal et multi-échelle pour l'analyse d'images de télédétection, qui vise à combler le fossé entre l'imagerie de télédétection (RS) et la compréhension du langage naturel. L'ensemble de données couvre 25 années de données d'observation de la Terre (1998-2024) couvrant un large éventail de zones géographiques, de missions satellites et de modalités de télédétection.
Utilisation directe :https://go.hyper.ai/JHgSb
4. Ensemble de données de raisonnement mathématique OpenR1-Math-220k
OpenR1-Math-220k est un ensemble de données de raisonnement mathématique à grande échelle qui contient 220 000 problèmes mathématiques de haute qualité et leurs traces de raisonnement, qui sont dérivées de 800 000 traces de raisonnement générées par DeepSeek R1.
Utilisation directe :https://go.hyper.ai/VkUMt
5. Ensemble de données de référence sur les jugements juridiques chinois JuDGE
JuDGE est un ensemble de données de référence de génération de documents juridiques conçu pour le système juridique chinois. Cet ensemble de données vise à améliorer les performances des modèles de génération de documents juridiques grâce à des données annotées de haute qualité, notamment dans le raisonnement juridique et la rédaction de documents. Il convient à divers scénarios d'application tels que les systèmes juridiques intelligents, la génération automatique de documents juridiques et les systèmes de questions-réponses juridiques.
Utilisation directe :https://go.hyper.ai/Fygtg
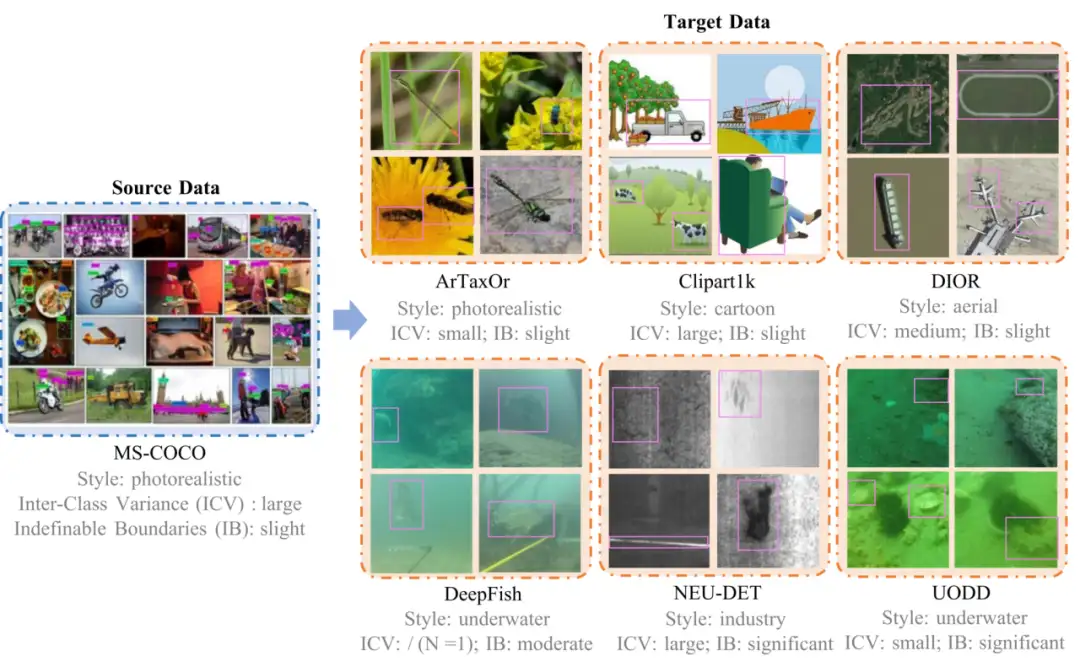
6. Ensemble de données de détection d'objets à petit échantillon NTIRE2025 CDFSOD
Cet ensemble de données est utilisé par le premier défi de détection d'objets à petits échantillons inter-domaines NTIRE 2025, qui comprend l'ensemble de données source COCO et plusieurs ensembles de données de vérification tels que ArTaxOr, Clipart1k, DIOR, DeepFish, NEU-DET, UODD, etc. Le problème de recherche principal de cet ensemble de données est de savoir comment effectuer la détection de cibles dans des scénarios inter-domaines en utilisant uniquement des images cibles annotées très limitées.
Utilisation directe :https://go.hyper.ai/kGZhW
Cet ensemble de données est un ensemble de données au format YOLO pour détecter les objets griffés par les chats. Il contient environ 1 500 images avec arrière-plans. Chaque image possède un fichier d'étiquette .txt compatible avec YOLO, qui peut être utilisé pour former des modèles de détection d'objets afin d'identifier si un chat gratte quelque chose.
Utilisation directe :https://go.hyper.ai/wkzNJ

Cet ensemble de données est un ensemble de données R1 chinois open source distillé de sang complet. L'ensemble de données contient non seulement des données mathématiques, mais également une grande quantité de données de type général, avec un montant total de 110 000.
Utilisation directe :https://go.hyper.ai/5zvRt
9. Ensemble de données de détection de gestes de la main
Cet ensemble de données est spécialement conçu pour les systèmes de contrôle gestuel des téléviseurs intelligents et contient environ 500 courts échantillons vidéo collectés indépendamment. Chaque clip vidéo dure 2 à 3 secondes, enregistrant entièrement le processus dynamique depuis le mouvement initial du geste jusqu'à l'affichage complet. Ces gestes incluent les pouces vers le haut, les pouces vers le bas, le balayage vers la gauche, le balayage vers la droite et l'arrêt, et servent d'échantillons d'entraînement distincts pour le modèle de reconnaissance des gestes. Les échantillons ont été complétés de manière collaborative par des participants d'âges différents (18-65 ans), de sexes et de couleurs de peau différents, couvrant une variété de postures interactives telles que la position debout et assise, afin de saisir les différences dans les habitudes de fonctionnement qui peuvent survenir parmi les utilisateurs réels.
Utilisation directe :https://go.hyper.ai/nMdjB

10. Ensemble de données d'images riches en commentaires humains
Cet ensemble de données est conçu pour fournir des commentaires riches pour la formation et l'évaluation des modèles de génération de texte en image et contient 15 000 images. Il collecte 1,5 million d'annotations fournies par plus de 150 000 personnes, couvrant des commentaires tels que les évaluations d'images, la cohérence sémantique et les suggestions de correction.
Utilisation directe :https://go.hyper.ai/GhD9w

Tutoriels publics sélectionnés
1. Déploiement en un clic de YOLOv12
Depuis longtemps, l’amélioration de l’architecture réseau du framework YOLO est un sujet central dans le domaine de la vision par ordinateur. Bien que le mécanisme d’attention excelle dans les capacités de modélisation, les améliorations basées sur le CNN sont toujours courantes car les modèles basés sur l’attention sont difficiles à égaler en termes de vitesse. Cependant, l’introduction de YOLOv12 a changé cette situation. Non seulement il est comparable aux frameworks basés sur CNN en termes de vitesse, mais il exploite également pleinement les avantages de performance du mécanisme d'attention, devenant une nouvelle référence pour la détection d'objets en temps réel.
Les modèles et dépendances pertinents de ce projet ont été déployés. Après avoir démarré le conteneur, cliquez sur l’adresse API pour accéder à l’interface Web.
Exécutez en ligne :https://go.hyper.ai/Wy1So

2. Ebook2Audiobook : conversion d'un livre électronique en livre audio
Ebook2Audiobook est un outil open source conçu pour convertir des livres électroniques (eBooks) en livres audio (audiobooks). Le projet utilise une technologie avancée de synthèse vocale (TTS) pour convertir automatiquement le contenu textuel des livres électroniques en parole et générer des livres audio que les utilisateurs peuvent écouter. Ebook2Audiobook prend en charge plusieurs formats de livres électroniques, tels que EPUB, PDF, MOBI, etc., et peut préserver la structure des chapitres et les métadonnées, ce qui rend les livres audio générés plus faciles à parcourir et à comprendre.
Accédez au site Web officiel pour cloner et démarrer le conteneur, copiez directement l'adresse API, puis démarrez le modèle.
Exécutez en ligne :https://go.hyper.ai/sgLbN
Articles de la communauté
Une équipe de l’Université d’Australie occidentale et d’autres institutions a proposé l’utilisation d’un cadre automatisé basé sur l’apprentissage profond. L’étude a utilisé 200 scanners crâniens provenant d’un hôpital indonésien pour former et tester trois configurations de réseau basées sur l’apprentissage profond. Le cadre d’apprentissage profond le plus précis a pu combiner les caractéristiques du genre et du crâne pour le jugement, avec une précision de classification de 97%, significativement supérieure aux 82% des observateurs humains. Cet article est une interprétation et un partage détaillés du document.
Voir le rapport complet :https://go.hyper.ai/0rfjM
Des chercheurs du laboratoire clé SIG provincial du Zhejiang ont proposé un modèle d'apprentissage profond CatGWR basé sur le mécanisme d'attention. Le modèle introduit un mécanisme d’attention pour combiner la distance spatiale et la similarité contextuelle entre les échantillons afin d’estimer plus précisément la non-stationnarité spatiale. Cela offre de nouvelles perspectives pour la modélisation géospatiale, en particulier lorsqu’il s’agit de phénomènes géographiques complexes, et peut mieux saisir l’hétérogénéité spatiale et les effets contextuels. Cet article est une interprétation détaillée et un partage de la recherche.
Voir le rapport complet :https://go.hyper.ai/irDAo
HyperAI a soigneusement compilé les ensembles de données de raisonnement les plus populaires, couvrant plusieurs domaines tels que les mathématiques, le code, la science, les puzzles, etc. Pour les praticiens et les chercheurs qui souhaitent améliorer considérablement les capacités de raisonnement des grands modèles, ces ensembles de données constituent sans aucun doute un excellent point de départ. Cet article est l'adresse de téléchargement du jeu de données.
Voir le rapport complet :https://go.hyper.ai/XGIi8
L'Université du Zhejiang et d'autres ont proposé une technique appelée alignement de Boltzmann, qui a transféré les connaissances du modèle de pliage inverse pré-entraîné à la prédiction de l'énergie libre de liaison. Cette méthode a été réalisée à un niveau supérieur et a été incluse dans l’ICLR 2025, la principale conférence universitaire internationale dans le domaine de l’intelligence artificielle. Cet article est une interprétation et un partage détaillés du document.
Voir le rapport complet :https://go.hyper.ai/MsUDj
NVIDIA, en collaboration avec le MIT et d'autres, a développé un nouveau type de générateur de protéines à flux à grande échelle, Proteina. Proteina possède 5 fois plus de paramètres que le modèle RFdiffusion et a étendu ses données de formation à 21 millions de structures protéiques synthétiques. Il a atteint des performances SOTA dans la conception de squelettes protéiques de novo et a généré des protéines diverses et concevables avec une longueur sans précédent allant jusqu'à 800 résidus. Ses résultats ont été sélectionnés pour l'ICLR 2025 Oral. Cet article est une interprétation détaillée et un partage de la recherche.
Voir le rapport complet :https://go.hyper.ai/n4fWv
Lei Jun, Zhou Hongyi, Liu Qingfeng et d'autres leaders de l'industrie ont suivi de près le pouls de l'époque et ont activement avancé des propositions et des suggestions dans de nombreux domaines clés tels que les véhicules à énergie nouvelle, les hallucinations de grands modèles, les soins médicaux de l'IA, le changement de visage de l'IA et l'éducation à l'IA. Voir ci-dessous pour plus de détails.
Voir le rapport complet :https://go.hyper.ai/EazuY
Articles populaires de l'encyclopédie
1. Perte par diffusion
2. Attention causale
3. Théorème de représentation de Kolmogorov-Arnold
4. Compréhension linguistique multitâche à grande échelle (MMLU)
5. Apprentissage contrastif
Voici des centaines de termes liés à l'IA compilés pour vous aider à comprendre « l'intelligence artificielle » ici :
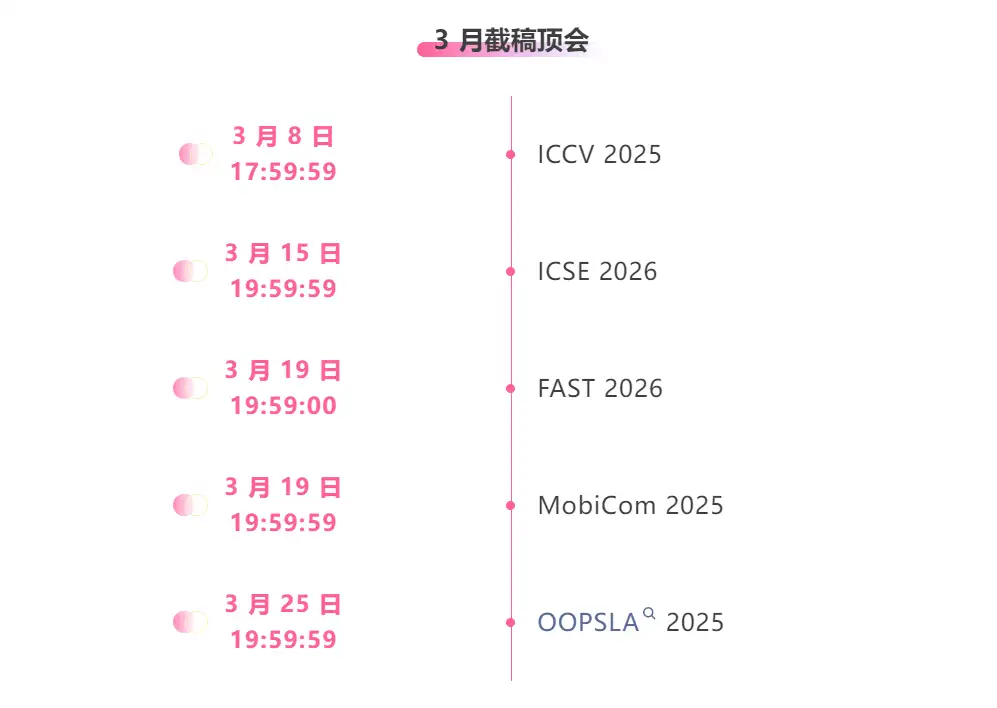
Suivi unique des principales conférences universitaires sur l'IA :https://go.hyper.ai/event
Voici tout le contenu de la sélection de l’éditeur de cette semaine. Si vous avez des ressources que vous souhaitez inclure sur le site officiel hyper.ai, vous êtes également invités à laisser un message ou à soumettre un article pour nous le dire !
À la semaine prochaine !








