Command Palette
Search for a command to run...
Le Didacticiel De Déploiement En Un Clic Du QwQ-32B Est En Ligne, Les Performances Sont Comparables À Celles De La Version Complète De DeepSeek-R1

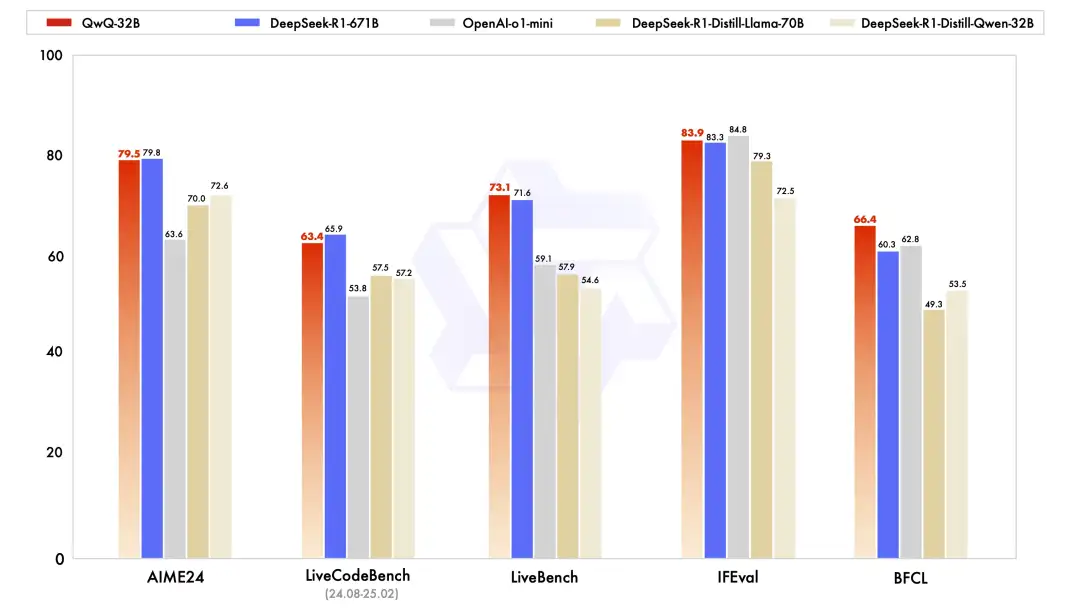
Hier, Alibaba Cloud a soudainement fait un grand pas en avant et a ouvert le code source d'un nouveau modèle de raisonnement, Tongyi Qianwen QwQ-32B.Sur plusieurs benchmarks clés, il a surpassé OpenAI-o1-mini avec 32B paramètres et était comparable à la version complète de DeepSeek-R1 avec 671B paramètres. Le QwQ-32B offre non seulement des performances étonnantes, mais réduit également considérablement le coût de déploiement tout en maintenant des performances élevées. Il peut également être déployé localement sur des cartes graphiques grand public, ce qui en fait un modèle de robustesse et de rentabilité.
Sur le plan technique, le QwQ-32B adopte une méthode d’apprentissage par renforcement en deux étapes basée sur le démarrage à froid. La première étape se concentre sur les tâches mathématiques et de code, et utilise des vérificateurs mathématiques et des bacs à sable de code pour se concentrer sur l'amélioration de la capacité de raisonnement logique du modèle.
La deuxième étape utilise un mécanisme de vérification des réponses pour remplacer le modèle de récompense traditionnel. Pour les problèmes mathématiques, un retour d'information est donné en fonction de l'exactitude des résultats. Pour les tâches de programmation, une évaluation en temps réel est effectuée sur le serveur via des cas de test pour améliorer les capacités générales. De plus, QwQ-32B intègre également des fonctions liées à l'agent, lui permettant d'ajuster de manière flexible le processus de raisonnement en fonction des retours environnementaux, améliorant ainsi considérablement l'autonomie et l'adaptabilité du modèle.
« Utiliser vLLM pour déployer QwQ-32B » est désormais disponible dans la section « Tutoriels » du site officiel d'HyperAI.Petits paramètres et grande puissance, en attente de vérification !
Adresse du tutoriel :
Essai de démonstration
1. Connectez-vous à hyper.ai, sur la page Tutoriel, sélectionnez Déployer QwQ-32B à l'aide de vLLM, puis cliquez sur Exécuter ce tutoriel en ligne.
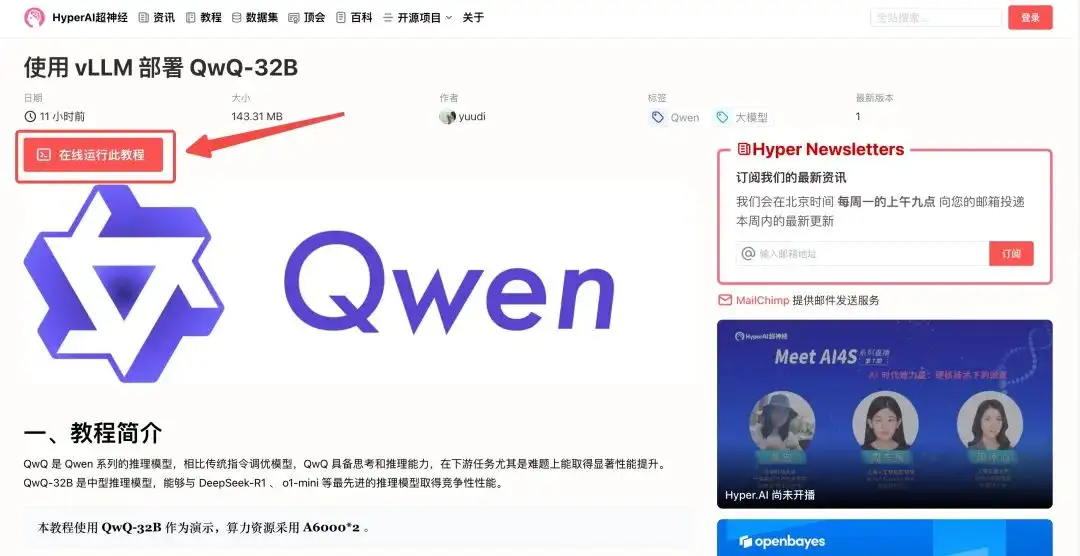
2. Une fois la page affichée, cliquez sur « Cloner » dans le coin supérieur droit pour cloner le didacticiel dans votre propre conteneur.
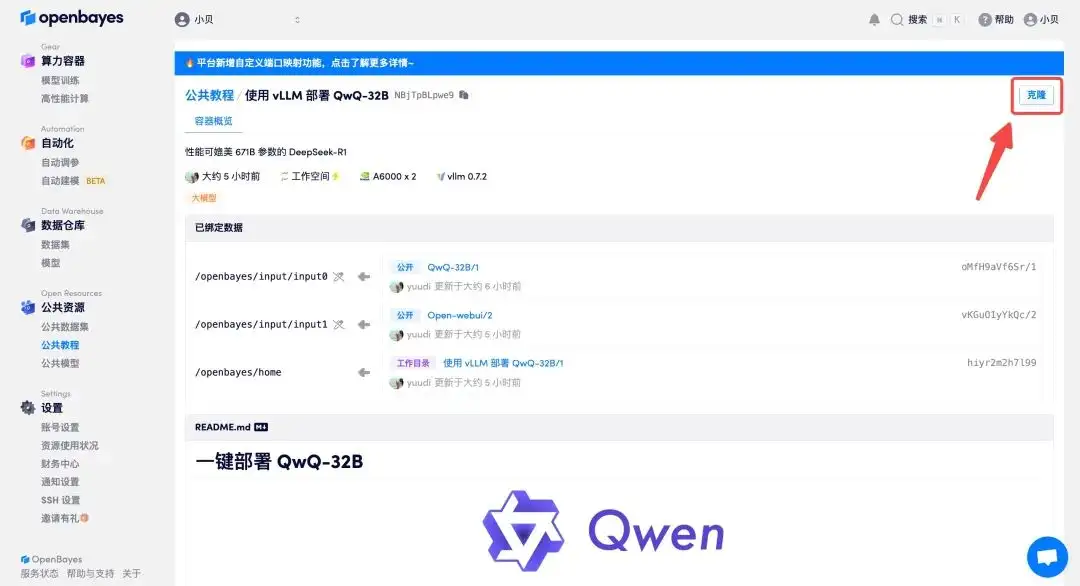
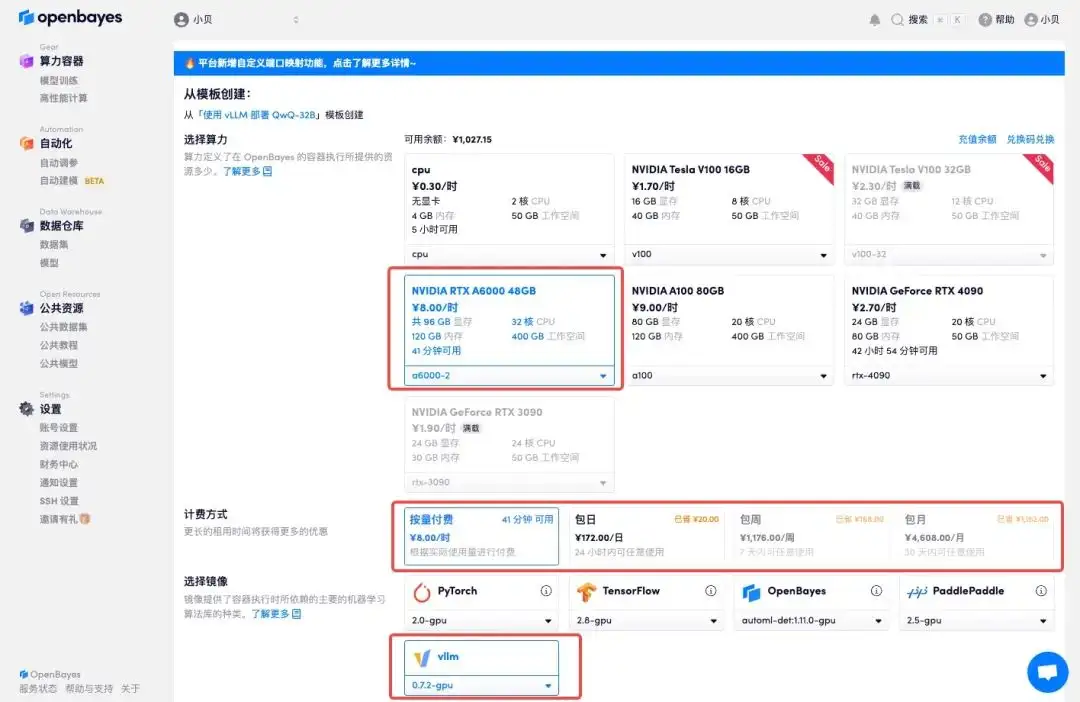
3. Sélectionnez les images « NVIDIA A6000-2 » et « vllm ». La plateforme OpenBayes a lancé une nouvelle méthode de facturation. Vous pouvez choisir « Payer au fur et à mesure » ou « Quotidien/Hebdomadaire/Mensuel » selon vos besoins. Cliquez sur « Continuer ». Les nouveaux utilisateurs peuvent s'inscrire en utilisant le lien d'invitation ci-dessous pour obtenir 4 heures de RTX 4090 + 5 heures de temps CPU gratuit !
Lien d'invitation exclusif HyperAI (copier et ouvrir dans le navigateur) :
https://openbayes.com/console/signup?r=Ada0322_NR0n
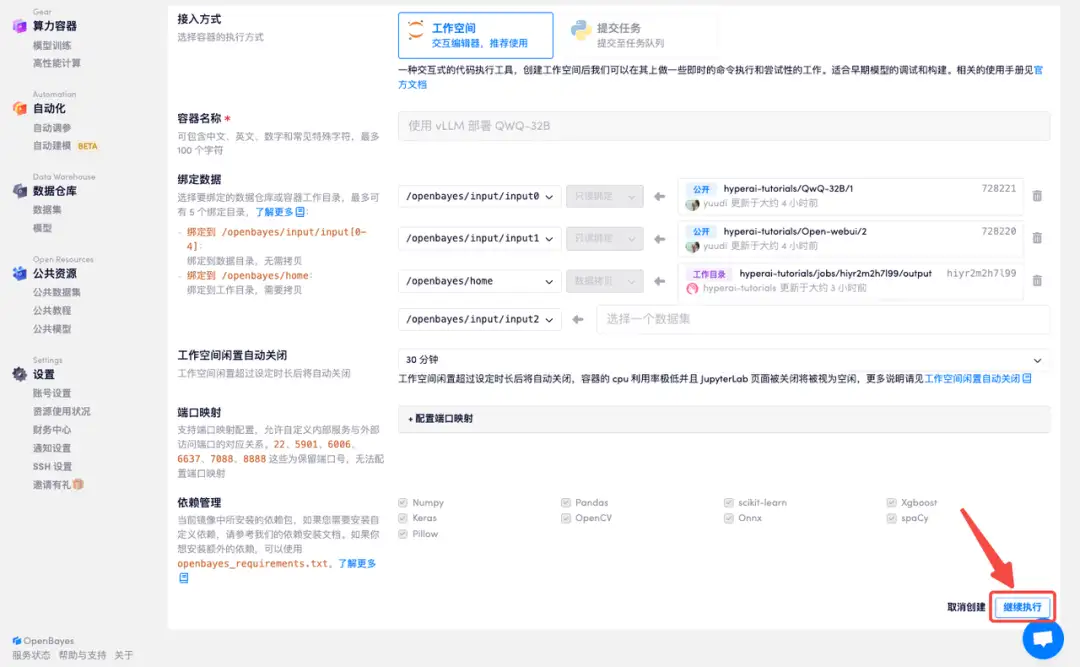
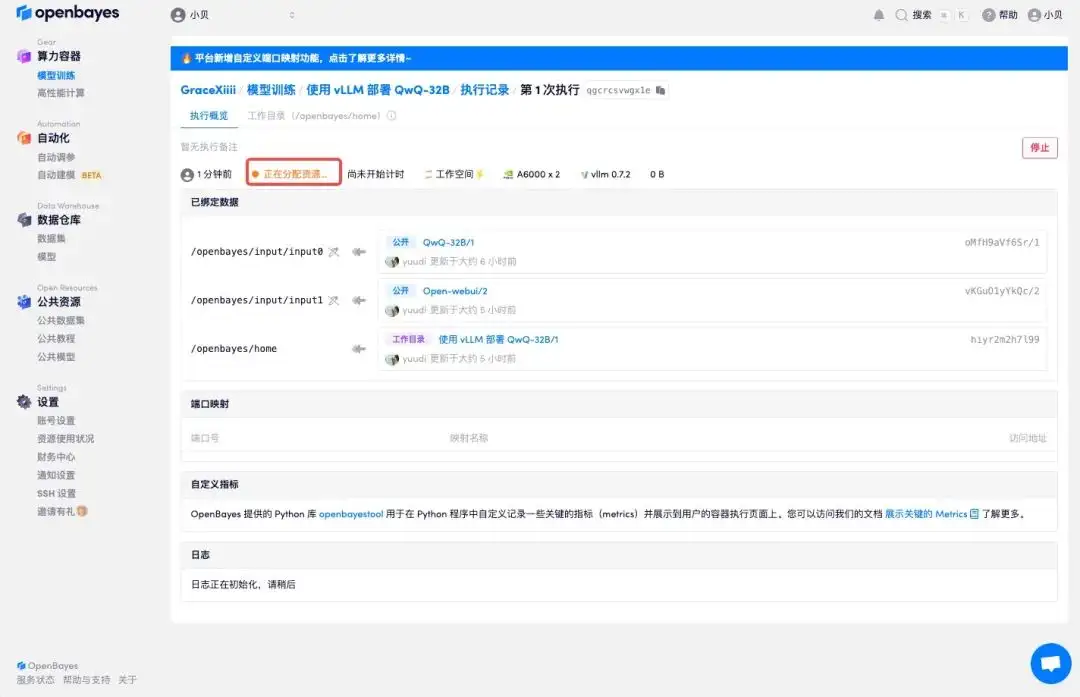
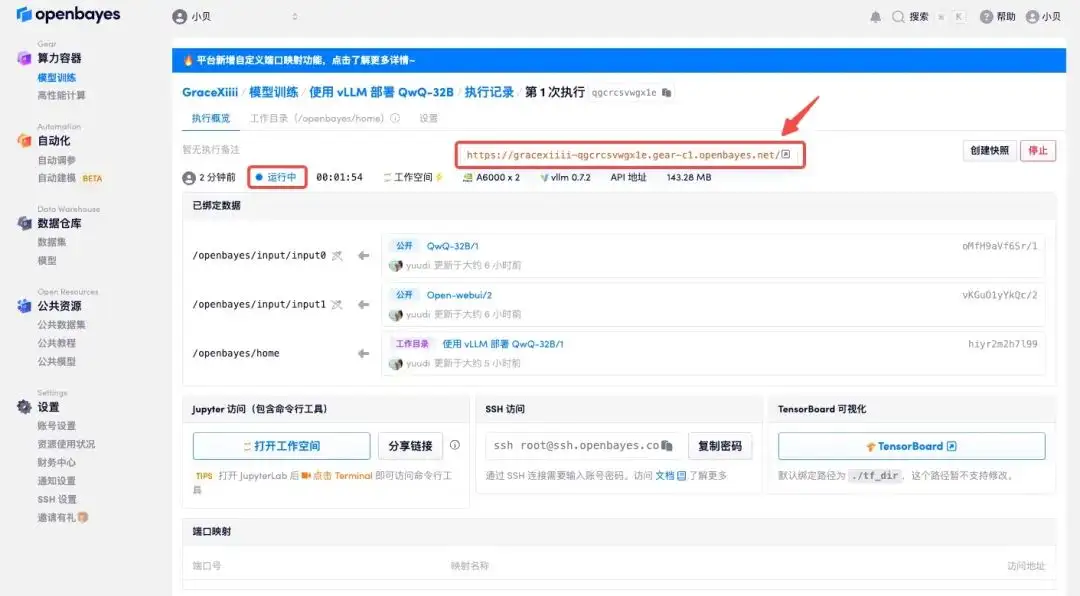
4. Attendez que les ressources soient allouées. Le premier processus de clonage prend environ 2 minutes. Lorsque le statut passe à « En cours d'exécution », cliquez sur la flèche de saut à côté de « Adresse API » pour accéder à la page de démonstration. Veuillez noter que les utilisateurs doivent effectuer l'authentification par nom réel avant d'utiliser la fonction d'accès à l'adresse API.
Affichage des effets
1. Il y a beaucoup de discussions en ligne pour savoir lequel est le meilleur, QwQ-32B ou DeepSeek. Demandons à QwQ-32B et voyons comment il répond.
2. On peut voir que QwQ-32B démontrera un processus de réflexion complet et donnera une analyse objective sous plusieurs angles.











