Command Palette
Search for a command to run...
Pour La Première Fois, L’équipe De Tsinghua a Réussi À Unifier La Génération Moléculaire Et La Prédiction Des propriétés. Il a Proposé Un Mécanisme De Génération De Diffusion En Deux Étapes Et a Été Sélectionné Pour l'ICLR 2025.

La technologie de l’intelligence artificielle transforme profondément le processus de développement des médicaments.Parmi elles, la prédiction des propriétés moléculaires et la génération moléculaire, deux tâches principales, se sont développées depuis longtemps selon des voies techniques indépendantes.L’objectif de la prédiction des propriétés moléculaires est de prédire les diverses propriétés chimiques et biologiques des molécules à partir d’informations sur la structure moléculaire et d’accélérer le criblage des médicaments. La génération moléculaire vise à estimer la distribution des données moléculaires, à potentiellement apprendre les interactions atomiques et les informations conformationnelles, et à être capable de générer de nouvelles molécules chimiquement rationnelles à partir de zéro, repoussant ainsi les limites des possibilités de conception de médicaments. Bien que de nombreuses recherches aient été menées dans ces domaines ces dernières années, ils se sont largement développés de manière indépendante.Les canaux de collaboration entre ces deux maillons clés n’ont jamais été effectivement ouverts.
Compte tenu de cela,L'équipe de l'Université Tsinghua et de l'Académie chinoise des sciences a proposé le modèle UniGEM, qui a permis pour la première fois l'amélioration collaborative de deux tâches basées sur un modèle de diffusion.L’équipe de recherche a souligné que la génération et la prédiction des propriétés sont fortement corrélées et reposent sur une représentation moléculaire efficace. L’équipe a proposé de manière innovante un processus de génération en deux étapes, qui a surmonté les incohérences de la formation conjointe traditionnelle et a ouvert une nouvelle voie dans le domaine de la génération moléculaire et de la prédiction des propriétés. Cette réalisation a été sélectionnée pour l'ICLR 2025 sous le titre « UniGEM : une approche unifiée de la génération et de la prédiction des propriétés des molécules ».

Adresse du document :
https://openreview.net/pdf?id=Lb91pXwZMR
Ensemble de données de chimie quantique QM9 :
Ensemble de données de conformation moléculaire 3D GEOM-Drugs :
Le projet open source « awesome-ai4s » rassemble plus de 200 interprétations d'articles AI4S et fournit des ensembles de données et des outils massifs :
https://github.com/hyperai/awesome-ai4s
Motivation pour unifier les tâches de génération et de prédiction
L’équipe de recherche estime que l’essence des tâches de génération et de prédiction réside dans l’apprentissage des représentations moléculaires.D’une part, l’efficacité de diverses méthodes de pré-formation moléculaire montre que la prédiction des propriétés moléculaires repose sur une représentation moléculaire robuste comme fondement. D’autre part, la génération de molécules nécessite une compréhension approfondie de la structure moléculaire pour pouvoir créer de bonnes représentations pendant le processus de génération.
Des résultats de recherche récents viennent étayer ce point de vue. Par exemple, les travaux en vision par ordinateur ont montré que les modèles de diffusion eux-mêmes ont la capacité d’apprendre des représentations d’images efficaces. Dans le domaine moléculaire, des études ont montré que la pré-formation générative peut améliorer les tâches de prédiction des propriétés moléculaires, bien que ces méthodes nécessitent souvent des ajustements supplémentaires pour obtenir des performances prédictives optimales. De plus, bien que les prédicteurs puissent guider la génération de molécules via des méthodes de guidage de classificateur, il n’est pas encore clair si la formation des prédicteurs peut directement améliorer les performances de génération.
Par conséquent, les recherches existantes n’ont pas encore complètement clarifié la relation entre les tâches de génération et les tâches de prédiction.Cela soulève une question clé : pouvons-nous construire un modèle unifié qui permette une amélioration synergique des tâches de génération et de prédiction ?
Analyse des raisons de l'échec des méthodes traditionnelles
Une manière simple de combiner ces deux tâches consiste à utiliser un cadre d’apprentissage multitâche traditionnel, dans lequel le modèle optimise à la fois la perte de génération et la perte de prédiction. Cependant, les expériences menées par l'équipe de recherche ont montré que cette approche réduisait considérablement les performances des tâches de génération et des tâches de prédiction de propriétés (la stabilité de la génération a chuté de 6% et l'erreur de prédiction a augmenté de plus de 1 fois). Même après avoir gelé les poids du modèle génératif et ajouté une tête distincte pour la tâche de prédiction de propriété afin de maintenir les performances de génération, les chercheurs n'ont observé aucune amélioration des performances de prédiction de propriété par rapport à la formation à partir de zéro.
Les chercheurs attribuent les mauvais résultats des méthodes traditionnelles à l’incohérence inhérente entre les tâches de génération et de prédiction.Au cours du processus de génération par diffusion, la structure moléculaire doit subir une reconstruction progressive du bruit désordonné à la structure fine. Cependant, dans les tâches de prédiction, les propriétés moléculaires significatives ne peuvent être définies qu'une fois la structure moléculaire fondamentalement établie. Par conséquent, la simple adoption d’une approche d’optimisation multitâche simple entraînera l’association incorrecte de conformations moléculaires hautement désordonnées à des étiquettes de propriété au stade de diffusion précoce, ce qui aura un impact négatif sur la génération de molécules et la prédiction des propriétés.
Pour illustrer davantage ce point, les chercheurs ont mené une analyse théorique de l’information mutuelle entre les représentations intermédiaires au sein du réseau de débruitage et les molécules cibles lors de l’entraînement par diffusion.De plus, il est théoriquement prouvé que le modèle de diffusion maximise implicitement la limite inférieure de l'information mutuelle entre la représentation intermédiaire et la molécule cible, indiquant la capacité d'apprentissage de la représentation du modèle de diffusion. Cependant, l'information mutuelle entre la représentation intermédiaire et la molécule cible montre une tendance monotone à la baisse et s'approche de zéro à des pas de temps plus longs, ce qui signifie que la représentation intermédiaire dans l'étape désordonnée ne peut pas prendre en charge une prédiction efficace. Par conséquent, l’intuition et la théorie suggèrent que les tâches de génération et de prédiction ne peuvent être alignées qu’à des pas de temps plus petits, lorsque les molécules restent relativement ordonnées.
Mécanisme de génération par diffusion en deux étapes
Sur la base de l’analyse ci-dessus,L’équipe de recherche a proposé une nouvelle méthode de génération en deux étapes qui vise à unifier la prédiction et la génération de propriétés moléculaires, comme le montre la figure ci-dessous.
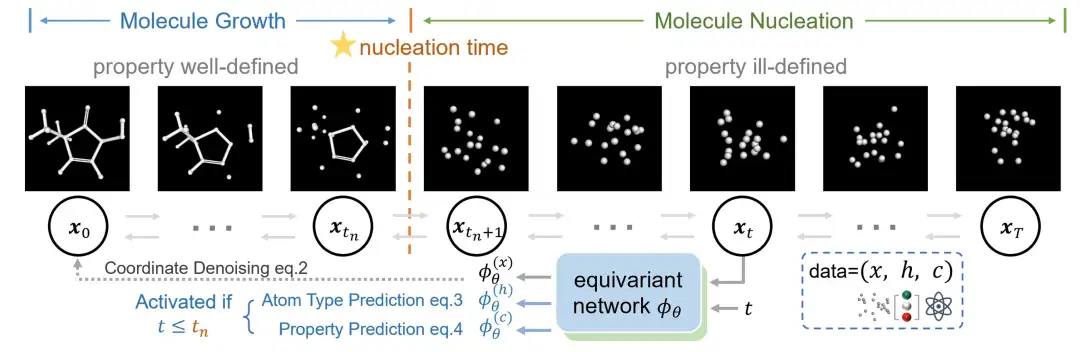
Les chercheurs divisent le processus de génération de molécules en deux étapes, à savoir « l'étape de nucléation moléculaire » et « l'étape de croissance moléculaire »,Cette division s'inspire du processus de formation des cristaux en physique.
Au cours de l'étape de nucléation moléculaire, la molécule forme son squelette à partir d'un état complètement désordonné, puis la molécule complète se développe sur la base de ce squelette. Ces deux étapes sont séparées par le « temps de nucléation ». Les chercheurs ont introduit une nouvelle façon de générer des molécules pour décrire ces deux étapes. Parmi eux, avant le « temps de nucléation », le modèle de diffusion génère progressivement des coordonnées moléculaires ; après la nucléation, le modèle continue d'ajuster les coordonnées moléculaires tout en optimisant les propriétés et les pertes de prédiction de type atomique.
Contrairement aux modèles génératifs traditionnels qui effectuent généralement une diffusion conjointe des types d'atomes et des coordonnées, cette méthode innovante se concentre uniquement sur la diffusion des coordonnées et traite les types d'atomes comme une tâche de prédiction distincte.Parce que les chercheurs ont observé que les types d’atomes pouvaient souvent être déduits des coordonnées des molécules formées. Plus précisément, avant la nucléation, le processus de diffusion vise à reconstruire les coordonnées ; après la nucléation, il intègre les pertes de prédiction des types et propriétés atomiques dans un cadre d'apprentissage unifié.
Stratégie de formation UniGEM
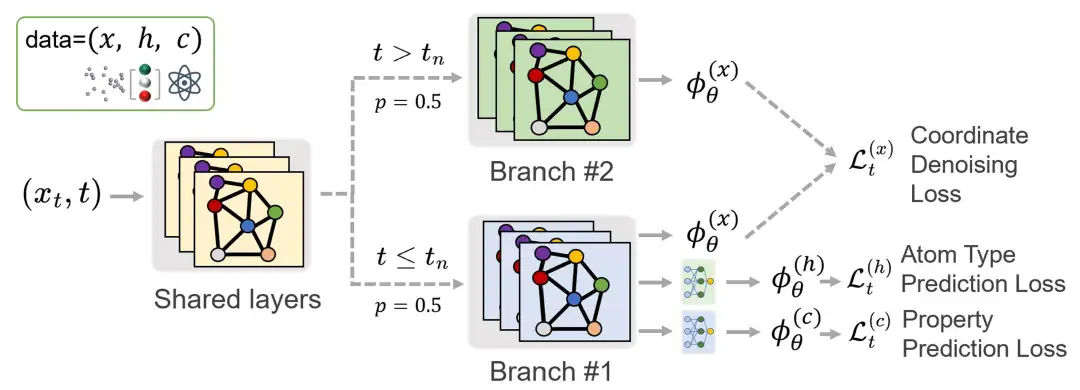
Afin de faciliter la comparaison avec la méthode traditionnelle de diffusion conjointe, les chercheurs ont adopté le modèle de diffusion équivariante E(3) (EDM) en utilisant EGNN comme squelette de structure de réseau. Parmi elles, la phase de croissance ne représente qu’environ 1% de l’ensemble du processus de formation. Si nous suivons la procédure d'entraînement par diffusion standard et échantillonnons les pas de temps de manière uniforme, le nombre d'itérations pour la tâche de prédiction ne représentera que 1% du processus d'entraînement total, ce qui réduira considérablement les performances du modèle sur cette tâche.Par conséquent, pour assurer une formation adéquate à la tâche de prédiction, les chercheurs ont suréchantillonné les pas de temps pendant la phase de croissance.
Cependant, les chercheurs ont observé que le suréchantillonnage pouvait conduire à un entraînement déséquilibré sur toute la plage de pas de temps, ce qui affectait à son tour la qualité du processus de génération. Pour résoudre ce problème, une architecture de réseau multi-branches est proposée. Le réseau partage des paramètres dans les couches superficielles, mais se divise en deux branches dans les couches plus profondes, chacune avec un ensemble indépendant de paramètres.Ces branches sont activées à différentes étapes de la formation : une branche se concentre sur la phase de nucléation, une autre gère la phase de croissance,Comme le montre la figure ci-dessous. Cette conception garantit que la tâche de prédiction et la tâche de génération peuvent être formées efficacement sans s'affecter mutuellement.
Processus de raisonnement d'UniGEM
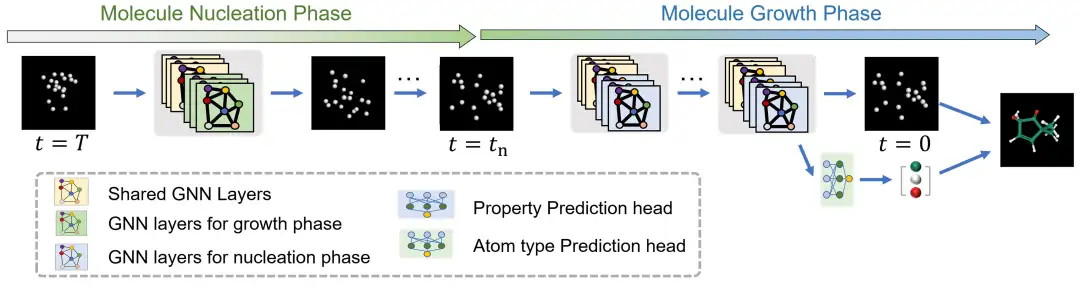
Dans UniGEM,La génération moléculaire est réalisée en reconstruisant les coordonnées atomiques via un processus de rétrodiffusion, puis en prédisant le type atomique en fonction des coordonnées générées.Comme indiqué sur l'image. Pour la prédiction des propriétés, le pas de temps d'entrée du réseau est fixé à zéro et la tête de prédiction des propriétés est utilisée. Il convient de noter que cette approche n’entraîne pas de surcharge de calcul supplémentaire pour la tâche de génération et la tâche de prédiction, et que le temps d’inférence total est le même que celui de la ligne de base.
Pour la tâche de génération moléculaire, les chercheurs ont également analysé les différences d’erreurs de génération entre UniGEM et les méthodes traditionnelles de génération conjointe.Premièrement, il est observé que l'erreur de perte de prédiction du type d'atome dans UniGEM est inférieure à la perte de génération de débruitage du type d'atome dans la génération conjointe. Deuxièmement, pendant le processus de génération conjointe, la génération de coordonnées sera affectée par l’oscillation des résultats de prédiction du type d’atome, ce qui entraînera une augmentation des erreurs. Enfin, la méthode de génération conjointe introduit également des erreurs de distribution initiale et de discrétisation plus importantes. Ces facteurs expliquent ensemble comment UniGEM obtient des résultats de génération supérieurs.
Résultats expérimentaux : surpassent le modèle de base dans les tâches de génération moléculaire et de prédiction de propriétés
Génération moléculaire : UniGEM surpasse les modèles de référence
Les chercheurs ont d’abord comparé l’UniGEM basé sur EDM avec les variantes EDM sur les ensembles de données QM9 et GEOM-Drugs. UniGEM a surpassé le modèle de référence dans presque tous les indicateurs d’évaluation, comme le montre la figure ci-dessous. Il convient de noter que par rapport aux autres variantes EDM,UniGEM est nettement plus simple car il ne repose pas sur des connaissances préalables et ne nécessite pas de formation supplémentaire sur l'autoencodeur, mais il surpasse EDM-Bridge et GeoLDM, soulignant ainsi les avantages d'UniGEM.
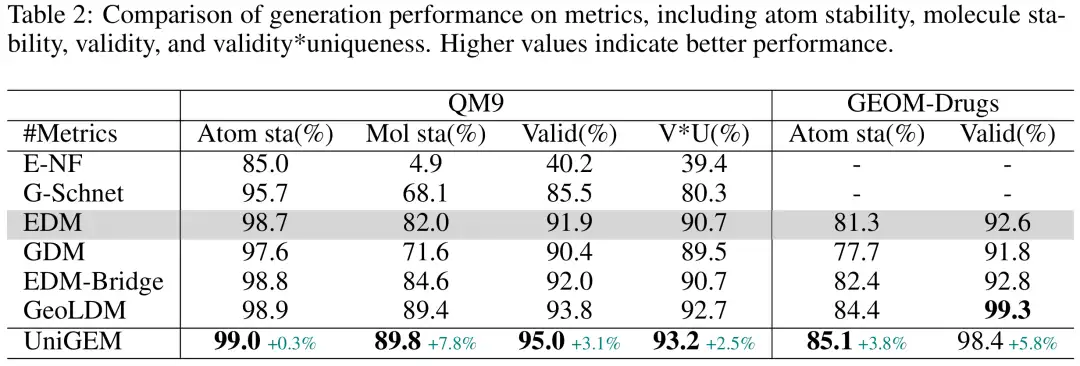
Pour démontrer la flexibilité d'UniGEM dans l'adaptation à divers algorithmes de génération, les chercheurs ont appliqué UniGEM aux réseaux de flux bayésiens (BFN), surpassant GeoBFN, qui générait conjointement des coordonnées et des types d'atomes, sur l'ensemble de données QM9, obtenant des résultats SOTA.
De plus, les chercheurs ont testé les performances d’UniGEM dans les tâches de génération conditionnelle, évitant ainsi la nécessité de recycler le modèle de génération conditionnelle en utilisant le module de prédiction des propriétés du modèle comme guide pendant le processus d’échantillonnage.
Prédiction des propriétés moléculaires : UniGEM surpasse la plupart des méthodes de pré-formation
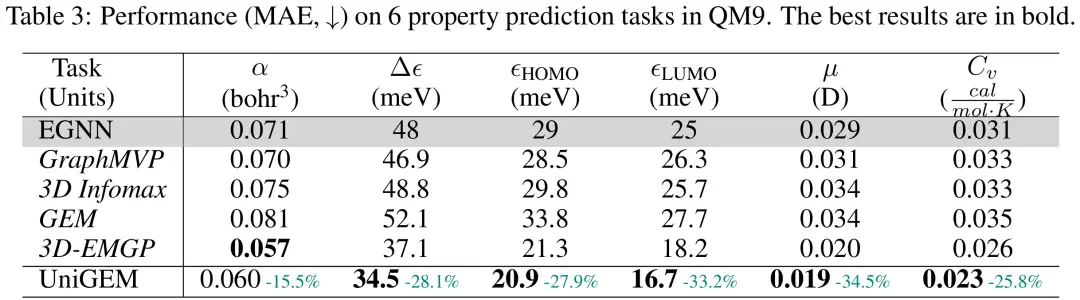
Les chercheurs ont évalué les performances de la prédiction des propriétés UniGEM sur l'ensemble de données QM9, en utilisant l'erreur absolue moyenne (MAE) sur l'ensemble de test comme mesure d'évaluation. Comme le montre la figure,UniGEM surpasse considérablement l'EGNN formé à partir de zéro, démontrant l'efficacité de la modélisation unifiée.Étonnamment, UniGEM surpasse toujours la plupart de ces méthodes de pré-formation de pointe malgré l’exploitation d’ensembles de données de pré-formation supplémentaires à grande échelle. Cela met en évidence l’avantage de son modèle unifié pour la génération et la prédiction, qui peut exploiter efficacement la puissance de l’apprentissage de la représentation moléculaire pendant le processus de génération sans avoir besoin de données supplémentaires et d’étapes de pré-formation.
Conclusion
Le modèle UniGEM unifie les tâches de génération de molécules et de prédiction de propriétés et améliore considérablement les performances des deux. Les performances améliorées d’UniGEM sont soutenues par une analyse théorique solide et des études expérimentales complètes. Nous pensons que le processus de génération innovant en deux étapes et son modèle correspondant fournissent un nouveau paradigme pour le développement de cadres de génération moléculaire et peuvent inspirer le développement de cadres de génération moléculaire plus avancés, bénéficiant ainsi à la génération moléculaire dans des domaines d'application plus spécifiques.
Cette recherche est menée par ATOM Lab. L'équipe a plus de résultats de recherche dans les domaines de la pré-formation moléculaire, de la génération moléculaire, de la prédiction de la structure des protéines, du criblage virtuel, etc., alors faites attention !
Bienvenue sur la page d'accueil d'ATOM Lab :
https://atomlab.yanyanlan.com/
À propos de l'auteur :
* Lan Yanyan est professeur à l'Institut des industries intelligentes (AIR) de l'Université Tsinghua. Ses intérêts de recherche comprennent l’IA4Science, l’apprentissage automatique et le traitement du langage naturel.
* Shikun Feng est doctorant à l'Institut des industries intelligentes (AIR) de l'Université Tsinghua. Ses intérêts de recherche comprennent l’apprentissage par représentation, les modèles génératifs et l’IA4Science.
* Yuyan Ni est doctorant à l'Académie des mathématiques et des sciences des systèmes (AMSS) de l'Académie chinoise des sciences. Ses intérêts de recherche comprennent les modèles génératifs, l'apprentissage par représentation, l'IA4Science et la théorie de l'apprentissage profond.
Les principaux auteurs de cet article, le Dr Shikun Feng et le Dr Yuyan Ni, sont actuellement à la recherche d’opportunités d’emploi. Les amis intéressés peuvent les contacter.
*E-mail de Feng Shikun : [email protected]
* Adresse e-mail de Ni Yuyan : [email protected]








