Command Palette
Search for a command to run...
La Vitesse d'inférence a Été Augmentée De 1,7 Fois, La Version vLLM v1 Est Sortie ! Le Premier Benchmark De Raisonnement Multimodal Étape Par Étape VRC-Bench Est Lancé Avec Plus De 4 000 Étapes d'annotation

Le mois dernier, dans un contexte de forte demande d'inférence de grands modèles, le framework d'inférence de grands modèles d'IA vLLM a officiellement inauguré la version v1.0. Par rapport aux versions précédentes, l'efficacité de calcul a été considérablement optimisée, la conception de l'API est devenue plus stable, le potentiel matériel a été pleinement libéré et la vitesse d'inférence a été augmentée de 1,7 fois ! Il offre un support plus solide pour le déploiement efficace de modèles avec des dizaines de milliards de paramètres.
à l'heure actuelle,Le tutoriel d'introduction vLLM a été lancé sur le site officiel hyper.ai, qui vous guidera de l'installation à l'exploitation, afin que vous puissiez rapidement maîtriser vLLM !
Tutoriel de démarrage vLLM :https://go.hyper.ai/qHl62
Pour plus de documents et de tutoriels vLLM chinois, veuillez visiter → https://vllm.hyper.ai
Du 5 au 14 février, le site officiel de hyper.ai est mis à jour :
* Ensembles de données publiques de haute qualité : 10
* Sélection de tutoriels de haute qualité : 6
* Sélection d'articles communautaires : 5 articles
* Entrées d'encyclopédie populaire : 5
* Principales conférences avec date limite en février : 3
Visitez le site officiel :hyper.ai
Ensembles de données publiques sélectionnés
1. Ensemble de données de référence de raisonnement visuel VRC-Bench
L'ensemble de données couvre les défis dans huit domaines différents, notamment le raisonnement visuel, le raisonnement mathématique et logique, le raisonnement scientifique, la compréhension culturelle et sociale, etc. Il contient plus de 4 000 étapes de raisonnement vérifiées manuellement, qui peuvent évaluer de manière exhaustive l'exactitude et la cohérence logique du modèle dans le raisonnement en plusieurs étapes.
Utilisation directe :https://go.hyper.ai/AV43N

2. Ensemble de données spatio-temporelles multimodales Terra
Terra est un ensemble de données spatio-temporelles multimodales à couverture mondiale, fournissant 45 ans de données spatio-temporelles dans le monde entier, couvrant 6,48 millions de points de grille haute résolution, et vise à promouvoir la recherche future dans l'exploration de données spatio-temporelles et à promouvoir la réalisation d'une intelligence spatio-temporelle plus large.
Utilisation directe :https://go.hyper.ai/9eev3

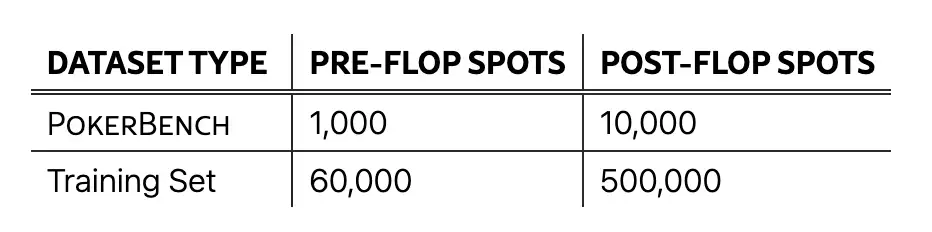
3. Ensemble de données d'évaluation du jeu de poker PokerBench
L'ensemble de données contient 11 000 scènes clés, divisées en 1 000 scènes pré-flop et 10 000 scènes post-flop, couvrant un large éventail de situations de jeu et est conçu pour évaluer les performances des grands modèles de langage (LLM) dans des jeux de poker complexes et stratégiques.
Utilisation directe :https://go.hyper.ai/HK73H
Cet ensemble de données contient des données sur les attractions touristiques de 352 villes de Chine. Le fichier csv pour chaque ville contient 100 emplacements. Les données comprennent le nom du lieu, le site Web, l'adresse, la présentation de l'attraction, les heures d'ouverture, l'URL de l'image, la note, la durée de visite recommandée, la saison de visite recommandée, les informations sur les billets, les conseils et d'autres informations.
Utilisation directe :https://go.hyper.ai/uZ5Wh
5. Ensemble de données vidéo du jeu GF-Minecraft
Cet ensemble de données collecte 70 heures de vidéos de jeux en exécutant des séquences d'actions aléatoires prédéfinies et en les annotant. L'ensemble de données est préconfiguré avec 3 biomes (forêt, plaines, désert), 3 conditions météorologiques (clair, pluvieux, orage) et 6 périodes (par exemple, lever du soleil, midi, minuit), générant plus de 2 000 clips vidéo.
Utilisation directe :https://go.hyper.ai/25DAe
6. Ensemble de données de mise au point de la culture nationale NCIFD
Cet ensemble de données est un ensemble de données de réglage fin de la culture nationale pour les grands modèles, contenant 151 159 éléments de données, couvrant sept domaines principaux : l'architecture, les vêtements, l'artisanat, la nourriture, l'étiquette, la langue et les coutumes.
Utilisation directe :https://go.hyper.ai/Vd6ZP
7. Ensemble de données de raisonnement mathématique AceMath Instruct Training Data
Cet ensemble de données est un ensemble de données publié par NVIDIA en 2025 pour la formation du modèle AceMath, visant à améliorer les performances du modèle dans les tâches de raisonnement mathématique.
Utilisation directe :https://go.hyper.ai/pT5Tr
8. ComplexFuncBench Ensemble de données d'évaluation d'appel de fonction complexe
L'ensemble de données couvre 1 000 échantillons d'appels de fonctions complexes dans 5 scénarios réels, dont 600 échantillons à domaine unique, 150 échantillons d'hôtels, de vols, de locations de voitures et d'attractions, et 400 échantillons inter-domaines. Le domaine taxi n'a que 2 fonctions, il n'est donc utilisé que sur plusieurs domaines.
Utilisation directe :https://go.hyper.ai/v0p4c
9. Ensemble de données de planification de voyage TravelPlanner
L'ensemble de données contient 1 225 intentions de planification et plans de référence organisés. L'ensemble de données est défini dans le contexte de la planification de voyage et nécessite qu'un agent linguistique génère un plan de voyage complet basé sur une requête donnée, comprenant le transport, les repas quotidiens, les attractions et l'hébergement.
Utilisation directe :https://go.hyper.ai/22AhZ
10. Ensemble de données sur la solubilité aqueuse des composés inorganiques
Cet ensemble de données contient des données expérimentales de solubilité dans l'eau de centaines de composés inorganiques. Les données proviennent de multiples références et sont adaptées au domaine de l'informatique des matériaux. Toutes les données de solubilité sont exprimées en grammes de soluté pour 100 grammes d’eau.
Utilisation directe :https://go.hyper.ai/dqL1y
Tutoriels publics sélectionnés
1. Tutoriel de démarrage vLLM : un guide étape par étape pour les débutants
vLLM est un framework conçu spécifiquement pour accélérer le raisonnement de grands modèles de langage. Il a attiré une attention considérable dans le monde entier en raison de son excellente efficacité de raisonnement et de ses capacités d’optimisation des ressources. Les chercheurs ont construit un moteur de service LLM distribué à haut débit vLLM, ont obtenu une perte quasi nulle de mémoire cache KV et ont résolu le problème du goulot d'étranglement de la gestion de la mémoire dans le raisonnement du modèle de langage volumineux.
Ce tutoriel vous montre étape par étape comment configurer et exécuter vLLM, en fournissant un guide de démarrage complet de l'installation au démarrage. Cliquez sur le lien ci-dessous et suivez le tutoriel pour déployer vLLM.
Exécutez en ligne :https://go.hyper.ai/qHl62
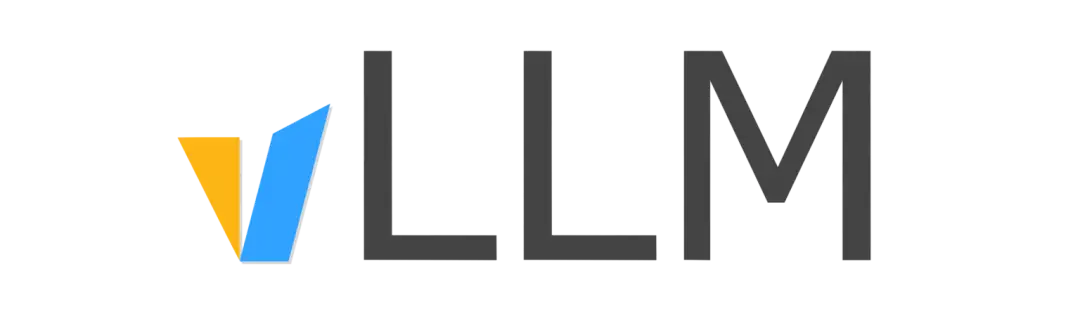
2. Déploiement en un clic de Qwen2.5-Coder
Qwen2.5-Coder est un assistant d'intelligence artificielle doté de puissantes capacités de génération de code. Il prend en charge la sortie de code avec une logique claire et une syntaxe standardisée, et fournit une fonction d'artefacts pour aider les utilisateurs à créer et à mettre en œuvre rapidement divers projets visuels. En termes de développement de mini-jeux, Qwen2.5-Coder peut générer du code de jeu en fonction des règles du jeu, du style graphique et des exigences d'expérience utilisateur. Les développeurs peuvent le personnaliser et l'optimiser sur cette base et lancer rapidement leurs propres jeux.
Ce projet peut générer une interface interactive front-end via l'interface Gradio. Les modèles et dépendances pertinents ont été déployés. Vous pouvez saisir des instructions dans le modèle et générer le code requis en un clic.
Exécutez en ligne :https://go.hyper.ai/JVOTN
3. Modèle de conversation chinois-anglais de bout en bout GLM-4-Voice
GLM-4-Voice est un modèle vocal de bout en bout qui peut comprendre et générer directement des discours en chinois et en anglais, mener des conversations vocales en temps réel et suivre les instructions de l'utilisateur pour modifier les attributs de la parole tels que l'émotion, l'intonation, la vitesse de parole et le dialecte.
Accédez au site Web officiel pour cloner et démarrer le conteneur, copiez directement l'adresse API et vous pourrez communiquer avec le modèle.
Exécutez en ligne :https://go.hyper.ai/s4MId
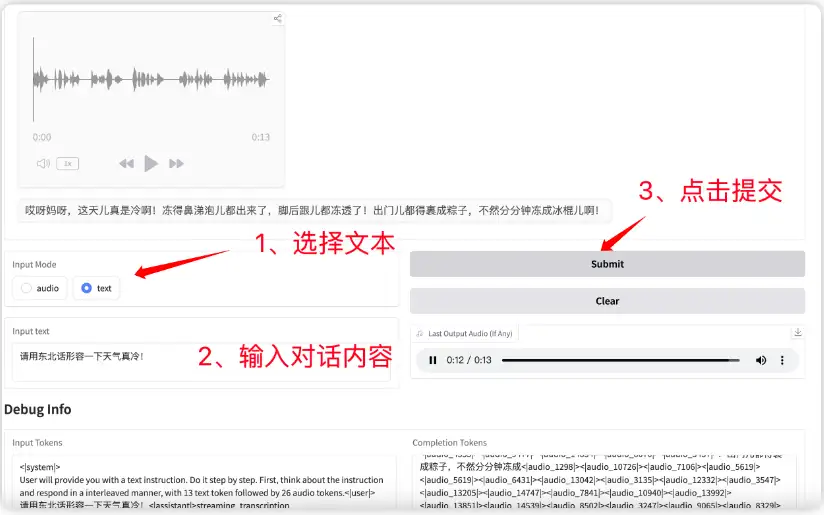
4. Linly-Dubbing Téléchargement vidéo en un clic + traduction + doublage + sous-titres
Linly-Dubbing est un outil intelligent de doublage et de traduction vidéo multilingue basé sur l'IA qui peut traduire automatiquement le contenu vidéo en plusieurs langues et générer des sous-titres.
Cliquez sur le lien ci-dessous pour démarrer immédiatement votre voyage créatif et réaliser le doublage et la traduction de vidéos en plusieurs langues par l'IA.
Exécutez en ligne :https://go.hyper.ai/xEAzn
5. DrawingSpinUp : dessin de personnage 2D → animation 3D
DrawingSpinUp est une technologie innovante de génération d'animation 3D qui transforme les dessins de personnages plats en animations dynamiques avec des effets 3D, tout en préservant soigneusement le style et les caractéristiques de l'œuvre d'art originale.
Suivez les étapes du didacticiel pour créer des animations 3D réalistes et détaillées.
Exécutez en ligne :https://go.hyper.ai/H9fV1
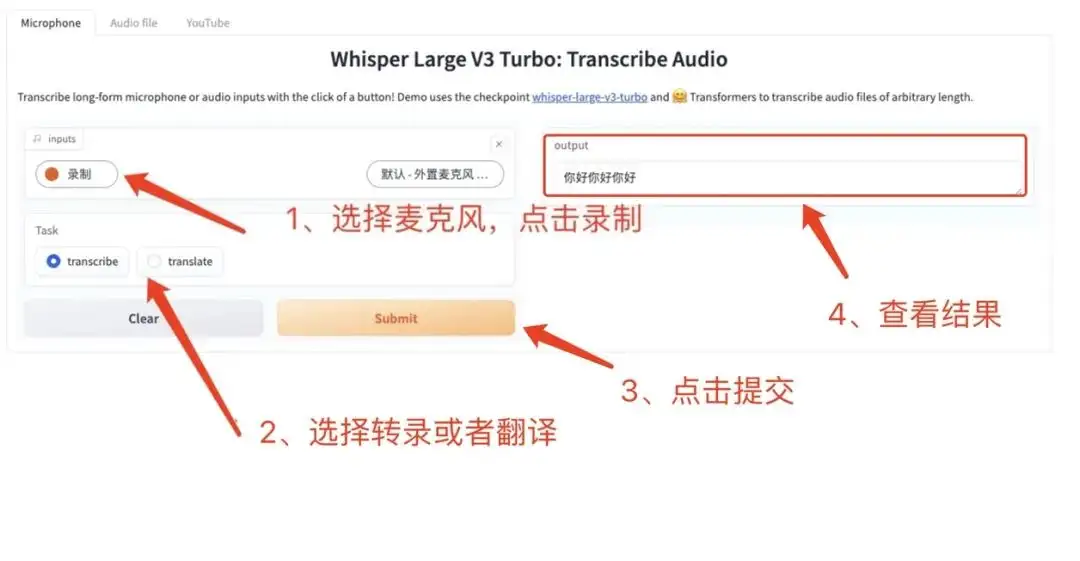
6. Démonstration de reconnaissance vocale et de traduction Whisper-large-v3-turbo
Whisper est un modèle de reconnaissance vocale à usage général. Il est formé sur un ensemble de données audio vaste et diversifié et peut effectuer plusieurs tâches telles que la reconnaissance vocale multilingue et la traduction vocale.
Ce tutoriel est un tutoriel de déploiement en un clic pour whisper-large-v3-turbo. Il est 8 fois plus rapide que whisper-large-v3 avec presque aucune perte de qualité. L'environnement et les dépendances pertinents ont été installés et vous pouvez en faire l'expérience en le clonant et en le démarrant en un clic.
Exécutez en ligne :https://go.hyper.ai/3P9nk
Articles de la communauté
La société biopharmaceutique d'IA Generate: Biomedicines, avec sa plateforme de biologie programmable unique, intègre non seulement en profondeur l'intelligence artificielle dans l'ingénierie des protéines, mais aide également les scientifiques à concevoir des solutions plus efficaces pour des cibles traditionnellement difficiles à traiter. Récemment, Generate a annoncé avoir reçu un investissement stratégique du Samsung Science & Life Science Fund. L’importance de tout cela est évidente. Cet article est un rapport détaillé sur l'entreprise, cliquez pour le lire rapidement.
Voir le récapitulatif de l'événement :https://go.hyper.ai/fVtKK
Ces dernières années, l’IA a été progressivement appliquée plus en profondeur dans le domaine de la recherche sur la littérature chinoise ancienne. En juin 2024, l'Université normale d'Anyang, en collaboration avec l'Université des sciences et technologies de Huazhong, l'Université de technologie de Chine du Sud, etc., a proposé un modèle de diffusion conditionnelle optimisé pour le déchiffrement des os d'oracle. Les résultats ont non seulement été sélectionnés pour l'ACL 2024, mais ont également remporté avec succès le prix du meilleur article. Cela montre que l’IA accélère l’efficacité du travail des chercheurs. Vous trouverez ci-dessous plus de détails sur la manière dont l'IA interprète les os d'oracle.
Voir le rapport complet :https://go.hyper.ai/xzw4c
Le développement rapide de l’intelligence artificielle médicale ne peut être séparé du soutien d’ensembles de données de haute qualité. Du diagnostic des maladies au développement de médicaments en passant par la médecine personnalisée, les ensembles de données jouent un rôle indispensable dans la promotion de l’application de la vision artificielle, des grands modèles, etc. dans le domaine médical. Cet article organise 10 ensembles de données dans le domaine médical, couvrant la médecine chinoise Shennong, les livres de médecine chinoise ancienne, le raisonnement médical, les questions et réponses médicales, etc. Vous pouvez cliquer pour télécharger directement.
Voir le rapport complet :https://go.hyper.ai/NHlJ0
Le développement rapide de l’intelligence artificielle a apporté de nouvelles possibilités à la découverte de médicaments. Récemment, des chercheurs de la société des sciences de la vie Cellarity et NVIDIA ont proposé conjointement une nouvelle méthode d'optimisation de molécules ciblées basée sur l'apprentissage par renforcement latent, MOLRL, qui a montré des performances supérieures dans les tâches liées à la découverte de médicaments, en particulier dans la génération de molécules ciblées et l'optimisation multiparamètres. Cet article est une interprétation et un partage détaillés du document.
Voir le rapport complet :https://go.hyper.ai/YBhnM
Dans le sixième épisode de la série de diffusion en direct « Meet AI4S », le professeur Zheng Wei, professeur à l'École de statistique et de science des données de l'Université de Nankai, a partagé avec tout le monde les limites d'AlphaFold et les futures orientations d'optimisation, ainsi que les algorithmes et les sujets de recherche qui méritent d'être explorés dans la communauté universitaire. Voir ci-dessous pour plus de détails.
Voir le rapport complet :https://go.hyper.ai/YgCip
Articles populaires de l'encyclopédie
1. Fusion de tri réciproque RRF
2. Paramètres du modèle
3. Théorème de représentation de Kolmogorov-Arnold
4. Compréhension linguistique multitâche à grande échelle (MMLU)
5. Apprentissage contrastif
Voici des centaines de termes liés à l'IA compilés pour vous aider à comprendre « l'intelligence artificielle » ici :

Suivi unique des principales conférences universitaires sur l'IA :https://go.hyper.ai/event
Voici tout le contenu de la sélection de l’éditeur de cette semaine. Si vous avez des ressources que vous souhaitez inclure sur le site officiel hyper.ai, vous êtes également invités à laisser un message ou à soumettre un article pour nous le dire !
À la semaine prochaine !








