Command Palette
Search for a command to run...
Modèle De Langage Médical Général Open Source De 176 Milliards De Paramètres ! BUPT/PKU/China Three Gorges University a Proposé MedFound, Dont La Capacité De Raisonnement Est Proche De Celle Des Médecins Experts

Comme le dit le vieil adage, « l’erreur est humaine », mais dans le domaine médical, une erreur comme un mauvais diagnostic peut avoir des conséquences désastreuses. D’un côté, pour les patients, le pire scénario est une fausse alerte, et le pire scénario est un retard dans le traitement de la maladie. Dans les deux cas, le patient subira des dommages mentaux, matériels et même mortels. D’un autre côté, pour les médecins, des jugements erronés peuvent nuire à leur image de sauveur de vies et même affecter la crédibilité de l’ensemble du système médical. Cependant, contrairement aux attentes, les erreurs de diagnostic restent un incident fréquent, tant au pays qu’à l’étranger.
Chen Xiaohong, ancien rédacteur en chef de la revue « Clinical Misdiagnosis and Mistreatment » et l'un des auteurs de la monographie médicale « Misdiagnosis », a mentionné dans une interview que les taux de diagnostic erroné mentionnés dans les tailles d'échantillon dans la littérature nationale et étrangère sont généralement d'environ 20% à 40%. En outre, son livre « Misdiagnosis » contient des statistiques pertinentes, par exemple, il mentionne que dans 200 données de discussion de pathologie clinique rapportées par plusieurs revues médicales nationales représentatives de 1973 à 1980, le taux de diagnostic erroné était aussi élevé que 48 %. On peut dire que les erreurs de diagnostic sont devenues l’un des principaux obstacles au progrès de la médecine humaine.
Afin de résoudre le problème des erreurs de diagnostic, dans l'Antiquité, des ouvrages médicaux tels que « Medical Records of Combineing Chinese and Western Medicine », « Medical Mistakes » et « Medical Corrections » ont tous fait de leur mieux pour inclure les leçons des erreurs de diagnostic dans les dossiers médicaux afin d'avertir les générations futures ; à l'époque moderne, avec l'aide de méthodes médicales modernes telles que l'échographie B, la tomodensitométrie et l'IRM, les moyens de diagnostic clinique sont devenus de plus en plus riches et sophistiqués. Cependant, la médecine, en tant que science pratique et discipline exploratoire, ne peut jamais éviter complètement les erreurs de diagnostic. C’est pourquoi ce n’est qu’en réduisant davantage le taux d’erreurs de diagnostic et en améliorant la précision et l’accessibilité du diagnostic des maladies que nous pourrons ouvrir la voie au développement futur de la médecine.
En prenant l’IA pour la science comme nouveau paradigme, elle fournit de nouvelles idées pour résoudre les problèmes ci-dessus. Il y a quelques jours,Une équipe interdisciplinaire d'ingénierie médicale composée du professeur Wang Guangyu de l'Université des postes et télécommunications de Pékin, du professeur Song Chunli du troisième hôpital de l'Université de Pékin et du professeur Yang Jian de l'Université des Trois Gorges de Chine a présenté et vérifié MedFound (176B), le modèle de langage biomédical avec le plus grand nombre de paramètres.Nous avons également créé MedFound-DX-PA, un grand modèle de langage pour le diagnostic médical généraliste, qui possède des capacités de connaissances et de raisonnement proches de celles des experts et peut fournir un support de diagnostic efficace et précis dans tous les scénarios médicaux.
Les résultats correspondants ont été publiés dans Nature Medicine sous le titre « Un modèle de langage médical généraliste pour l'aide au diagnostic des maladies ».

Adresse du document :
https://www.nature.com/articles/s41591-024-03416-6
Suivez le compte officiel et répondez « MedFound » pour obtenir le PDF complet
Le projet open source « awesome-ai4s » rassemble plus de 200 interprétations d'articles AI4S et fournit des ensembles de données et des outils massifs :
https://github.com/hyperai/awesome-ai4s
Quelle est l’innovation de MedFound ?
Le plus grand modèle de langage biomédical open source avec le plus grand nombre de paramètres
L'équipe de recherche a déclaré que le manque de LLM bien conçus, accessibles au public et spécifiquement adaptés aux contextes cliniques réels est la principale raison pour laquelle les LLM en sont encore à leurs balbutiements dans les applications biomédicales. MedFound est pré-entraîné sur la base du modèle de langage de domaine général BLOOM-176B, qui est un modèle de langage médical général avec une échelle de paramètres de 176 milliards.
Afin de garantir que le modèle puisse acquérir des connaissances médicales générales complètes, l'équipe de recherche a spécialement construit un ensemble de données de corpus médical MedCorpus qui intègre des connaissances médicales massives et la pratique clinique. Il se compose d'un total de 6,3 milliards de jetons de texte provenant de 4 ensembles de données, dont MedText, PubMed Central Case Report (PMC-CR), MIMIC-III-Note et MedDX-Note. Ces ensembles de données couvrent la littérature médicale chinoise et anglaise, les livres professionnels et 8,7 millions de dossiers médicaux électroniques réels, qui constituent une base importante pour que le modèle soit applicable au diagnostic dans diverses disciplines.
Il convient de mentionner que, selon l'équipe de recherche, MedFound est désormais open source et peut fournir des services de base de grands modèles sous-jacents aux chercheurs, cliniciens et institutions médicales du monde entier.
Adresse du projet :
https://github.com/medfound/medfound?tab=readme-ov-file
Des capacités innovantes de raisonnement diagnostique clinique en font un « médecin vivant »
En outre, une différence importante entre les machines et les humains est que les médecins humains peuvent tirer des conclusions raisonnables sur l’état réel du patient en se basant sur leur propre expérience et leurs réserves de connaissances, et ainsi fournir des traitements différenciés. L'équipe de recherche a indiqué que certaines études actuelles intègrent simplement les connaissances cliniques dans le LLM pour les questions-réponses ou les conversations médicales, mais ne reflètent pas la capacité du raisonnement diagnostique clinique.
Par exemple, Sainan Zhang et Jisung Song ont publié un résultat dans Nature, dans lequel ils ont développé une interface conversationnelle nommée Chat Ella basée sur l'apprentissage par transfert et le réglage fin de GPT-2. Le système peut prédire avec précision les maladies chroniques en fonction des symptômes décrits par l’utilisateur. Cependant, à la fin de l’article, les chercheurs ont également mentionné les lacunes de l’étude, soulignant certaines limites des résultats dans le processus de raisonnement, comme l’incapacité à expliquer le processus de raisonnement. L'article s'intitule « Un système de questions et réponses basé sur un chatbot pour le diagnostic auxiliaire des maladies chroniques basé sur un grand modèle de langage ».
Adresse du document :
https://www.nature.com/articles/s41598-024-67429-4
Par conséquent, pour parvenir à un diagnostic rigoureux des maladies, il ne suffit pas que le grand modèle dispose de vastes connaissances médicales interdisciplinaires, il doit également être capable d’effectuer un raisonnement complexe.Sur la base du modèle MedFound, l'équipe de recherche a également créé MedFound-DX, un grand modèle de langage pour le diagnostic médical généraliste avec des capacités de connaissances et de raisonnement proches de celles des experts, grâce à une optimisation de la formation en deux étapes.Comme le montre la figure suivante :
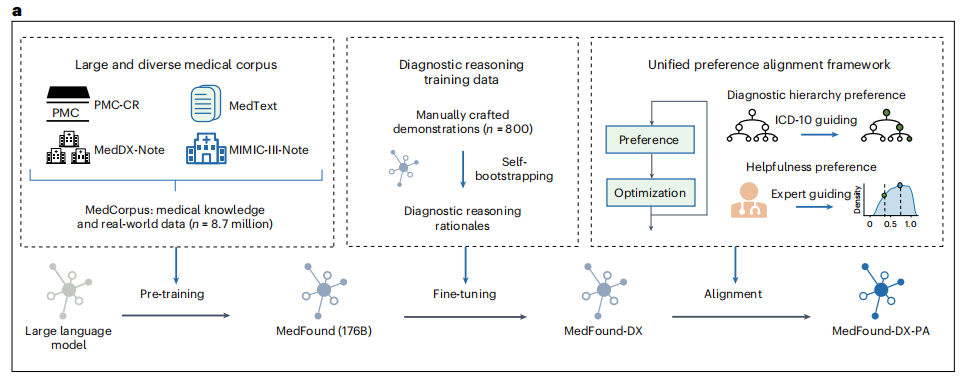
Plus précisément, dans la première phase, l'équipe de recherche a utilisé la méthode de la chaîne de pensée (CoT) basée sur des stratégies autoguidées pour permettre au grand modèle de générer automatiquement une base de diagnostic et un processus de raisonnement comme les experts médicaux. Cependant, les LLM génératifs peuvent produire des « hallucinations » ou fabriquer de faux faits, et si ces diagnostics sont adoptés, les conséquences peuvent être désastreuses.
Par conséquent, dans la deuxième phase, l'équipe de recherche a également introduit un cadre unifié d'alignement des préférences pour aligner le LLM sur le système de connaissances des domaines professionnels et les préférences de diagnostic clinique afin de garantir que le modèle est non seulement scientifique et raisonnable lors de l'établissement de diagnostics, mais également cohérent avec la logique et les valeurs des experts médicaux dans la pratique clinique. Le cadre intègre la « préférence de hiérarchie diagnostique » et la « préférence d'utilité », qui utilisent toutes deux l'algorithme d'optimisation des préférences directes (DPO) - un algorithme simple qui ne nécessite pas d'apprentissage par renforcement. D’une part, cela peut guider le modèle pour améliorer la précision fine de l’identification des maladies, et d’autre part, cela peut également améliorer l’efficacité et la crédibilité du raisonnement du modèle et réduire le risque d’informations trompeuses et incorrectes.
Il convient de mentionner que dans le cadre du réglage fin et de l'alignement de cette partie, l'équipe de recherche a également spécialement construit un ensemble de données appelé MedDX-FT, qui contient des démonstrations de processus de raisonnement écrits manuellement par des médecins sur la base de dossiers médicaux réels pour la formation et le réglage fin. L'ensemble de données se compose d'un ensemble de semences basé sur des démonstrations manuelles et de 109 364 notes de DSE.
Des résultats de démonstration étonnants montrent ses capacités d'application potentielles
Au cours de la phase d’évaluation, l’équipe de recherche a également construit un ensemble de données MedDX-Bench, qui comprend trois ensembles de données cliniques : MedDX-Test, MedDX-OOD et MedDX-Rare.
* L'ensemble de données MedDX-Test est utilisé pour évaluer les performances diagnostiques de MedFound-DX-PA dans divers domaines et contient 11 662 dossiers médicaux avec la même distribution que l'ensemble de données de formation.
* MedDX-OOD et MedDX-Rare sont des ensembles de validation externes, le premier contient 23 917 enregistrements de maladies courantes et le second contient 20 257 enregistrements de 2 105 maladies rares, qui ont une distribution à longue traîne.
L'expérience d'évaluation se compose principalement de trois étapes, à savoir l'évaluation en distribution (ID), l'évaluation hors distribution (OOD) et l'évaluation de la distribution des maladies à longue traîne. Les objets de comparaison incluent les principaux LLM open source et closed source tels que MEDITRON-70B, Clinical Camel-70B, Llama 3-70B et GPT-4o.
Les résultats montrent que ses performances sont meilleures que celles des autres LLM de premier plan.Par exemple, dans les performances diagnostiques des maladies courantes, la précision moyenne Top-3 de MedFound-DX-PA est de 84,2% (sous le paramètre ID), en comparaison, la précision diagnostique de GPT-4o n'est que de 62% ; dans la performance diagnostique des maladies rares, la précision moyenne Top-3 de MedFound-DX-PA dans 8 spécialités est de 80,7%, et GPT-4o se classe deuxième avec une moyenne de 59,1%.
Il convient de mentionner que dans la comparaison entre MedFound-DX-PA et les endocrinologues et les pneumologues, les taux de précision diagnostique étaient respectivement de 74,7% et 72,6%, ce qui était bien supérieur à celui des médecins ayant des années d'expérience inférieures et moyennes, et comparable à celui des médecins ayant des années d'expérience supérieures. En termes de diagnostic auxiliaire, il peut aider les médecins de ces deux départements à améliorer la précision diagnostique du 11.9% et du 4.4% respectivement. La figure ci-dessous est un cas de diagnostic de modèle intuitif.
Comme le montre la figure ci-dessous, le diagnostic initial du médecin était une bronchite aiguë. Le modèle MedFound a mis en évidence les antécédents de bronchite récurrente du patient. À la demande du modèle, le médecin a révisé le diagnostic en une exacerbation aiguë de bronchite chronique.

Comme le montre la figure ci-dessous, le médecin a initialement diagnostiqué chez le patient une hypothyroïdie subclinique. Le modèle MedFound a suggéré la possibilité d'une maladie thyroïdienne auto-immune sous-jacente, et le médecin a révisé le résultat en thyroïdite auto-immune.

On peut constater que MedFound a non seulement le potentiel d’améliorer l’efficacité et la précision du diagnostic, mais a également le potentiel de devenir un assistant de diagnostic pour les travailleurs cliniques.Cela apporte un soutien solide au développement futur du diagnostic et du traitement cliniques intelligents et de la médecine personnalisée.
L'IA pour le développement durable continue de progresser et l'ère de sa mise en œuvre est arrivée
L'équipe de Wang Guangyu continue d'avancer
Dans cet effort collaboratif, chaque équipe a fait de son mieux et a utilisé son expertise pour contribuer à cette réalisation. Il convient de mentionner que le professeur Wang Guangyu de l’Université des postes et télécommunications de Pékin est l’un des auteurs correspondants de cette étude.
En fait, ce n’est pas la première fois que l’équipe du professeur Wang Guangyu intègre l’IA à la biomédecine.En tant que premier lauréat du Science Exploration Award après les années 90, Wang Guangyu est depuis longtemps célèbre et a publié une série de réalisations académiques de pointe à l'échelle internationale.Ses travaux ont été inclus dans des revues universitaires internationales de premier plan telles que Cell, Nature Medicine et Nature Biomedical Engineering.

Par exemple, en 2020, le professeur Wang Guangyu, en tant que premier auteur correspondant, a publié une étude intitulée « Système d'IA cliniquement applicable pour un diagnostic et un pronostic précis de la pneumonie COVID-19 à l'aide de la tomodensitométrie » dans la revue internationale de renom Cell. L'étude s'est concentrée sur la pneumonie COVID-19 qui faisait alors rage et a utilisé un total de plus de 530 000 images CT pour construire un modèle de diagnostic IA basé sur la segmentation des lésions, avec un taux de précision diagnostique allant jusqu'à 92,49%.
Adresse du document :
https://www.cell.com/pb-assets/products/coronavirus/CELL_CELL-D-20-00656.pdf

En 2023, l’équipe de Wang Guangyu a de nouveau publié deux articles de recherche dans Nature Medicine. Un article intitulé « Analyse des interactions protéine-protéine basée sur l'apprentissage profond pour la prédiction de l'infectiosité et de l'évolution des variants du SARS-CoV-2 » a proposé un cadre d'intelligence artificielle appelé UniBild, qui peut prédire de manière efficace et évolutive l'impact des variants de la protéine de pointe du SARS-CoV-2 sur les humains.
Adresse du document :
https://www.nature.com/articles/s41591-023-02483-5

Un autre article, intitulé « Contrôle glycémique optimisé du diabète de type 2 avec l’apprentissage par renforcement : un essai de preuve de concept », propose un cadre d’apprentissage par renforcement basé sur un modèle RL-DITR, comprenant un modèle de patient qui suit l’état de glycémie individuel et un modèle de politique pour la planification en plusieurs étapes des soins de longue durée, qui peut aider les médecins et les patients à spécifier des plans de traitement à l’insuline dynamiques et flexibles.
Adresse du document :
https://www.nature.com/articles/s41591-023-02552-9
Comme l'a déclaré Wang Guangyu : « Nous avons des attentes à ce sujet. Personnellement, j'espère développer des méthodes d'IA plus performantes et les utiliser pour résoudre de nombreux problèmes biomédicaux importants, comme la lutte contre les épidémies soudaines ou le cancer. »
L'intégration de l'IA et de la biomédecine s'accélère
En fait, l’intégration de l’IA et de la biomédecine est depuis longtemps une priorité des grands laboratoires. En raison de la particularité du domaine médical, l’IA a davantage d’opportunités de jouer un rôle dans ce domaine, et davantage d’équipes sont prêtes à approfondir ce domaine.
Par exemple, en 2024, une équipe de l'Université chinoise de Hong Kong a également développé un système de consultation virtuelle de médecins à plusieurs cycles basé sur le LLM, appelé DrHouse, qui peut améliorer la précision et la fiabilité du diagnostic à l'aide d'appareils intelligents, et en même temps, grâce à une base de connaissances médicales constamment mise à jour et à des algorithmes de diagnostic avancés, il a une durée de vie ultra-longue et fournit des évaluations médicales intelligentes et fiables. L'article connexe s'intitule « DrHouse : un système de raisonnement diagnostique basé sur un LLM grâce à l'exploitation des résultats des données des capteurs et des connaissances d'experts ».
Adresse du document :
https://arxiv.org/abs/2405.12541
En outre, l'équipe de Wang Yanfeng et Xie Weidi de l'Université Jiaotong de Shanghai a également publié des résultats connexes en 2024. L'étude mentionne que l'équipe a construit un corpus médical multilingue - MMedC, contenant environ 25,5 milliards de jetons et couvrant 6 langues principales. Parallèlement, il a également proposé un questionnaire médical multilingue à choix multiples - MMedBench. Le modèle final de l’équipe de recherche, MMed-Llama 3, ne comporte que 8 milliards de paramètres, mais ses performances sont comparables à celles de GPT-4 sur les benchmarks MMedBench et anglais.
On peut constater que la tempête de l’intégration de l’IA et de la biomédecine s’est intensifiée. Grâce à sa puissance de calcul puissante, à ses nouveaux algorithmes et à sa capacité à absorber plus facilement des données massives, l’IA rend la recherche scientifique traditionnelle plus efficace et plus intelligente. Ce qui est encore plus passionnant, c’est que ces résultats qui progressent progressivement permettront à terme à l’application de voir le jour plus rapidement. Une ère où la mise en œuvre est reine semble être arrivée tranquillement.
Références :
1.https://mp.weixin.qq.com/s/9mhp6luTzQeNhqpEKw9CWQ
2.https://mp.weixin.qq.com/s/WlamJ7N9YKrOJljvEvE9cA
3.https://mp.weixin.qq.com/s/r-S9qkVU645K-ZdaLGYhBA
4.https://mp.weixin.qq.com/s/BfByFCWC9VN6iABnPq1iDw









