Command Palette
Search for a command to run...
Tutoriels En Ligne | La Série YOLO a Été Mise À Jour Avec 11 Versions En 10 Ans, Et Le Dernier Modèle a Atteint Le Niveau SOTA Dans Les Tâches De Détection De Cibles Multiples
YOLO (You Only Look Once) est l'un des algorithmes de détection d'objets en temps réel les plus influents dans le domaine de la vision par ordinateur.Il est privilégié par l'industrie pour sa haute précision et son efficacité, et est largement utilisé dans la conduite autonome, la surveillance de la sécurité, l'imagerie médicale et d'autres domaines.
Le modèle a été publié pour la première fois en 2015 par Joseph Redmon, un étudiant diplômé de l’Université de Washington. Il a été le pionnier du concept de traitement de la détection d'objets comme un problème de régression unique, a réalisé une détection d'objets de bout en bout et a rapidement acquis une large reconnaissance parmi les développeurs. Par la suite, des équipes comprenant Alexey Bochkovskiy, Glenn Jocher (équipe Ultralytics) et le département d'intelligence visuelle de Meituan ont lancé plusieurs versions importantes.
À ce jour, le nombre d'étoiles des modèles de la série YOLO sur GitHub a atteint des centaines de milliers, démontrant son influence dans le domaine de la vision par ordinateur.

La série de modèles YOLO se caractérise par son architecture de détection en une seule étape, qui ne nécessite pas de génération de boîte candidate de région complexe et peut terminer la détection de cible dans une seule propagation vers l'avant, améliorant considérablement la vitesse de détection. Comparé aux détecteurs traditionnels à deux étages (tels que Faster R-CNN),YOLO a une vitesse d'inférence plus rapide, peut réaliser un traitement en temps réel d'images à fréquence d'images élevée et optimise l'adaptabilité du matériel,Largement utilisé dans les appareils embarqués et les scénarios d'informatique de pointe.
à l'heure actuelle,La section « Tutoriel » du site officiel d'HyperAI a lancé plusieurs versions de la série YOLO, qui peuvent être déployées en un clic pour en faire l'expérience~
À la fin de cet article, nous utiliserons la dernière version de YOLOv11 comme exemple pour expliquer le didacticiel de déploiement en un clic.
1. YOLOv2
Heure de sortie :2017
Mise à jour importante :Des boîtes d'ancrage ont été proposées et Darknet-19 a été utilisé comme réseau principal pour améliorer la vitesse et la précision.
Compiler YOLO-V2 dans le modèle DarkNet avec TVM :
2. YOLOv3
Heure de sortie :2018
Mise à jour importante :En utilisant Darknet-53 comme réseau fédérateur, la précision est considérablement améliorée tout en maintenant la vitesse en temps réel, et une prédiction multi-échelle (structure FPN) est proposée, ce qui a permis d'obtenir des améliorations significatives dans la détection d'objets de différentes tailles et le traitement d'images complexes.
Compiler YOLO-V3 dans le modèle DarkNet avec TVM :
3 , YOLOv5
Heure de sortie :2020
Mise à jour importante :L'introduction d'un mécanisme de réglage automatique du cadre d'ancrage maintient les capacités de détection en temps réel et améliore la précision. Une implémentation PyTorch plus légère est utilisée pour faciliter la formation et le déploiement.
Déploiement en un clic :https://go.hyper.ai/jxqfm
4 , YOLOv7
Heure de sortie :2022
Mise à jour importante :Basé sur le réseau d'agrégation de couches efficace étendu, l'utilisation des paramètres et l'efficacité de calcul sont améliorées, permettant d'obtenir de meilleures performances avec moins de ressources de calcul. Ajout de tâches supplémentaires telles que l'estimation de la pose sur l'ensemble de données de points clés COCO.
Déploiement en un clic :https://go.hyper.ai/d1Ooq
5 , YOLOv8
Heure de sortie :2023
Mise à jour importante :
Il adopte un nouveau réseau fédérateur et introduit une nouvelle tête de détection sans ancrage et une fonction de perte, qui surpasse les versions précédentes en termes de précision moyenne, de taille et de latence.
Déploiement en un clic :https://go.hyper.ai/Cxcnj
6 , YOLOv10
Heure de sortie :Mai 2024
Mise à jour importante :Élimine l’exigence de suppression non maximale (NMS), réduisant ainsi la latence d’inférence. L'intégration de modules de convolution de noyau volumineux et d'auto-attention partielle améliore les performances sans ajouter beaucoup de coûts de calcul. Différents composants ont été entièrement optimisés pour améliorer l’efficacité et la précision.
Déploiement en un clic de la détection de cible YOLOv10 :
Déploiement en un clic de la détection d'objets YOLOv10 :
7 , YOLOv11
Heure de sortie :Septembre 2024
Mise à jour importante :Offrant des performances de pointe (SOTA) dans de multiples tâches, notamment la détection, la segmentation, l'estimation de pose, le suivi et la classification, il exploite les capacités d'un large éventail d'applications et de domaines d'IA.
Déploiement en un clic :https://go.hyper.ai/Nztnq
Tutoriel de déploiement en un clic de YOLOv11
La section Tutoriel HyperAI HyperNeural a maintenant lancé « Déploiement en un clic de YOLOv11 ». Le tutoriel a mis en place l'environnement pour tout le monde. Vous n’avez pas besoin de saisir de commandes. Cliquez simplement sur Cloner pour découvrir rapidement les puissantes fonctions de YOLOv11 !
Adresse du tutoriel :https://go.hyper.ai/Nztnq
Essai de démonstration
1. Connectez-vous à hyper.ai, sur la page Tutoriel, sélectionnez Déploiement en un clic de YOLOv11, puis cliquez sur Exécuter ce tutoriel en ligne.
2. Une fois la page affichée, cliquez sur « Cloner » dans le coin supérieur droit pour cloner le didacticiel dans votre propre conteneur.
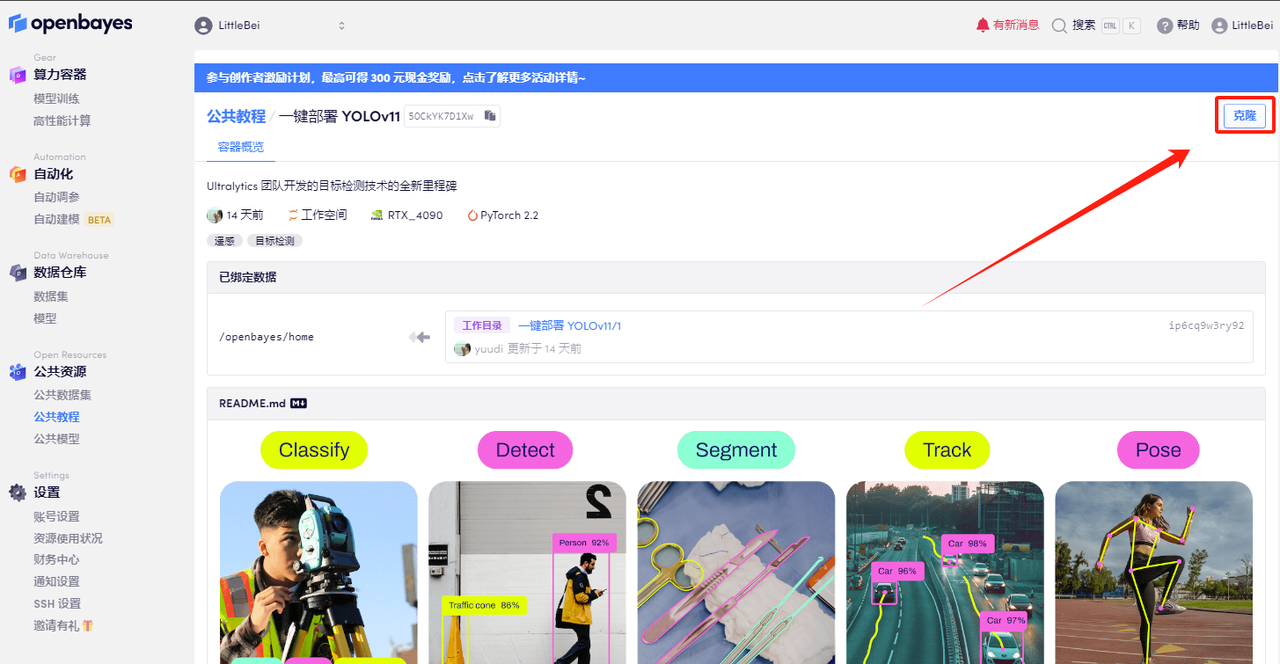
3. Cliquez sur « Suivant : sélectionner le taux de hachage » dans le coin inférieur droit.
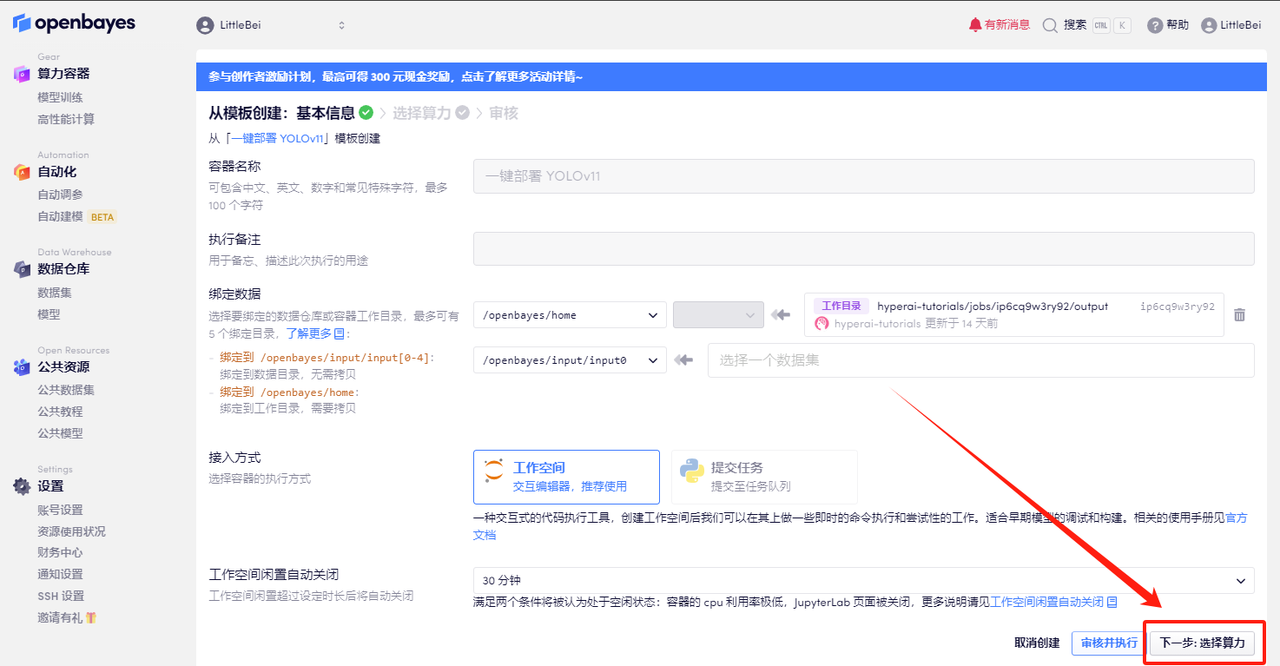
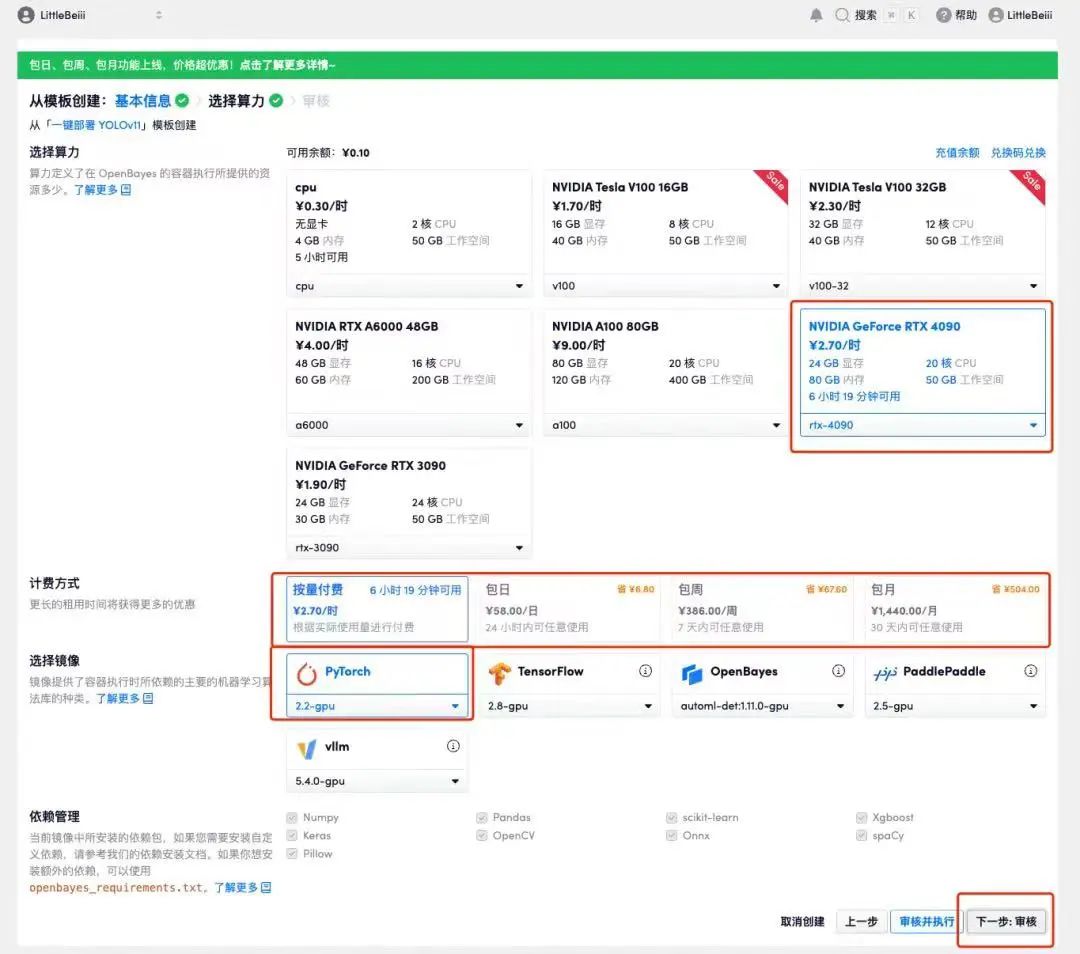
4. Une fois la page affichée, sélectionnez les images « NVIDIA RTX 4090 » et « PyTorch ». Les utilisateurs peuvent choisir « Payer au fur et à mesure » ou « Forfait journalier/hebdomadaire/mensuel » selon leurs besoins. Après avoir terminé la sélection, cliquez sur « Suivant : Réviser ».Les nouveaux utilisateurs peuvent s'inscrire en utilisant le lien d'invitation ci-dessous pour obtenir 4 heures de RTX 4090 + 5 heures de temps CPU gratuit !
Lien d'invitation exclusif HyperAI (copier et ouvrir dans le navigateur) :
https://openbayes.com/console/signup?r=Ada0322_QZy7
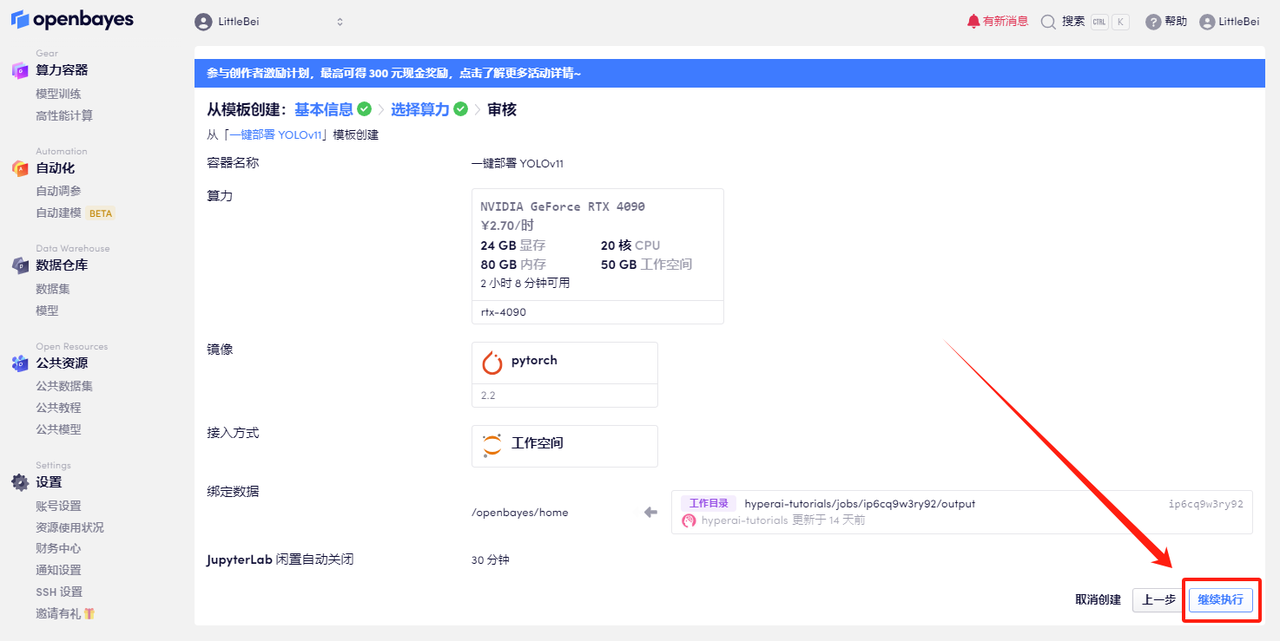
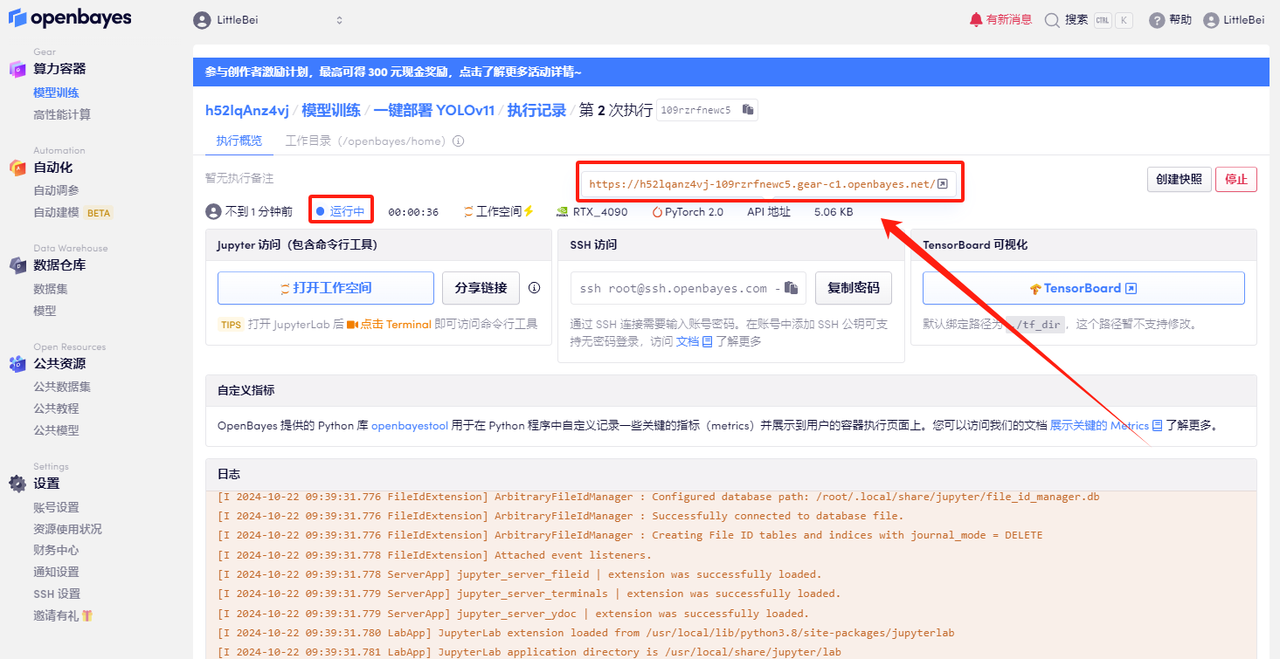
5. Après confirmation, cliquez sur « Continuer » et attendez que les ressources soient allouées. Le premier processus de clonage prendra environ 2 minutes. Lorsque le statut passe à « En cours d'exécution », cliquez sur la flèche de saut à côté de « Adresse API » pour accéder à la page de démonstration. Veuillez noter que les utilisateurs doivent effectuer l'authentification par nom réel avant d'utiliser la fonction d'accès à l'adresse API.
Démonstration d'effet
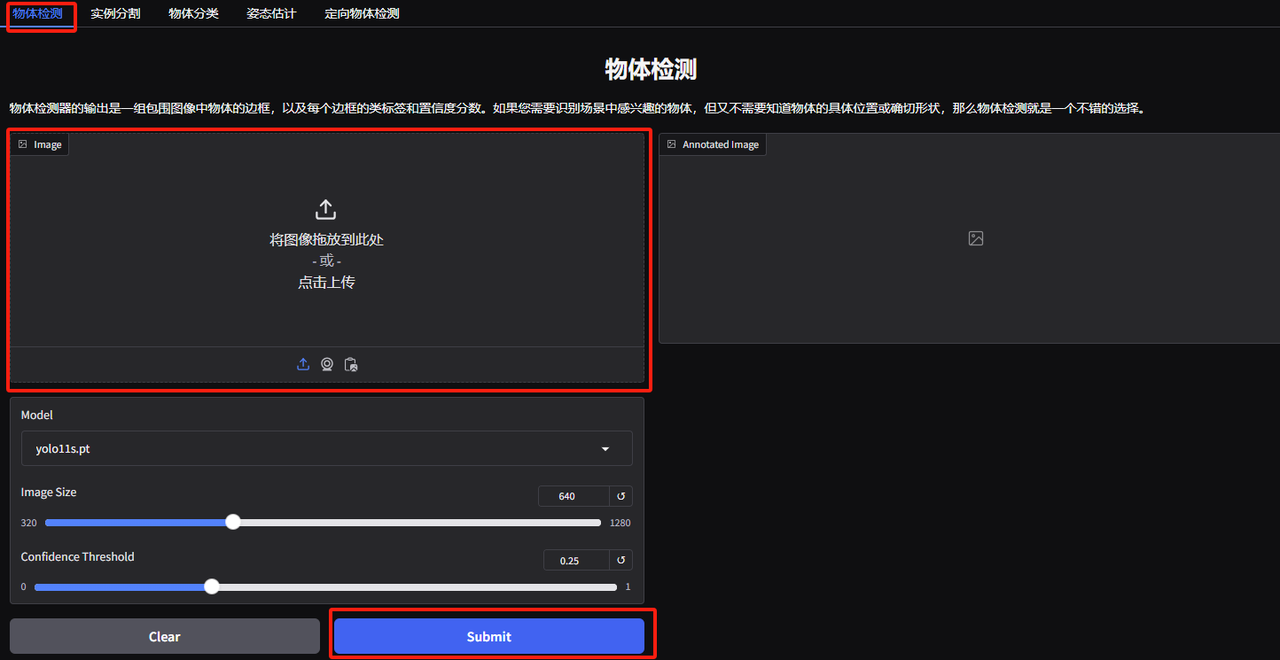
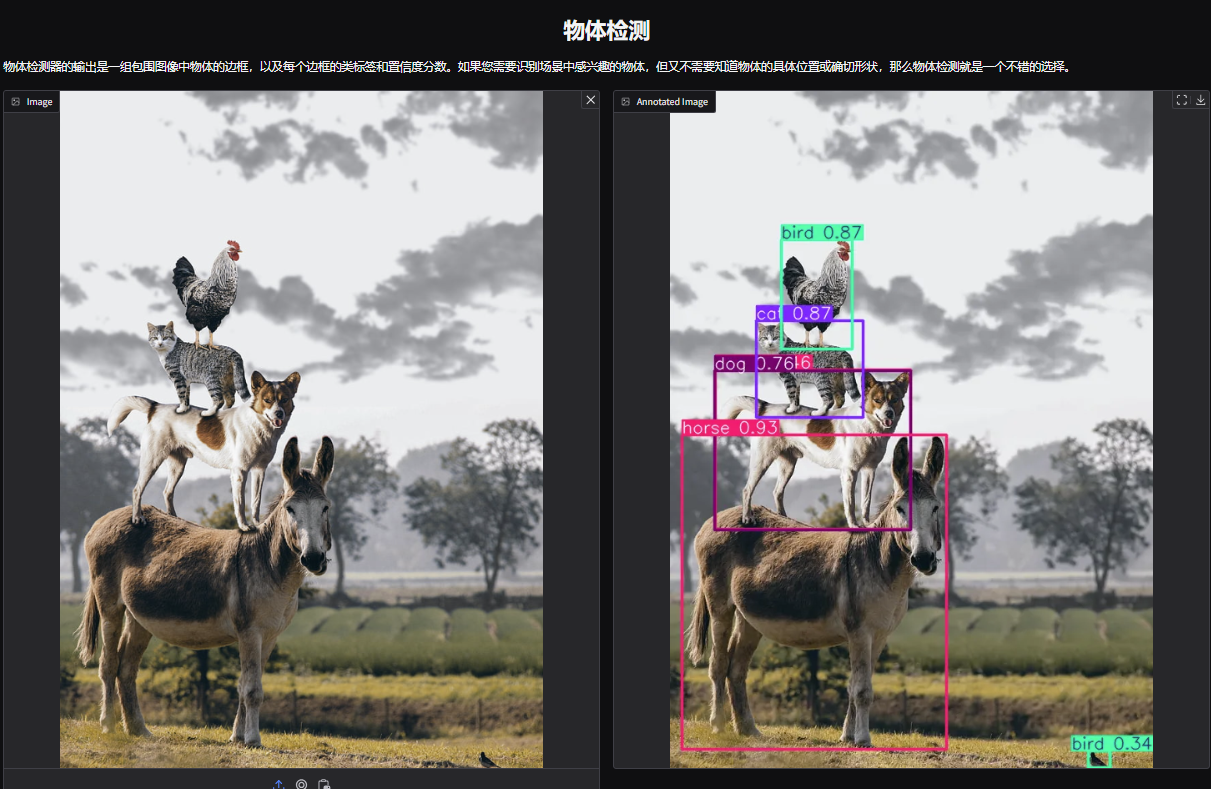
1. Ouvrez la page de démonstration de détection d’objets YOLOv11. J'ai téléchargé une photo d'animaux empilés, ajusté les paramètres et cliqué sur « Soumettre ». Vous pouvez voir que YOLOv11 a détecté avec précision tous les animaux sur la photo. Il s’avère qu’il y a un petit oiseau caché dans le coin inférieur droit ! Avez-vous remarqué ?
Les paramètres suivants représentent :
* Modèle:Fait référence à la version du modèle YOLO sélectionnée pour utilisation.
* Taille de l'image :La taille de l'image d'entrée. Le modèle redimensionnera l'image à cette taille lors de la détection.
* Seuil de confiance :Le seuil de confiance signifie que lorsque le modèle effectue une détection de cible, seuls les résultats de détection dont la confiance dépasse cette valeur définie seront considérés comme des cibles valides.
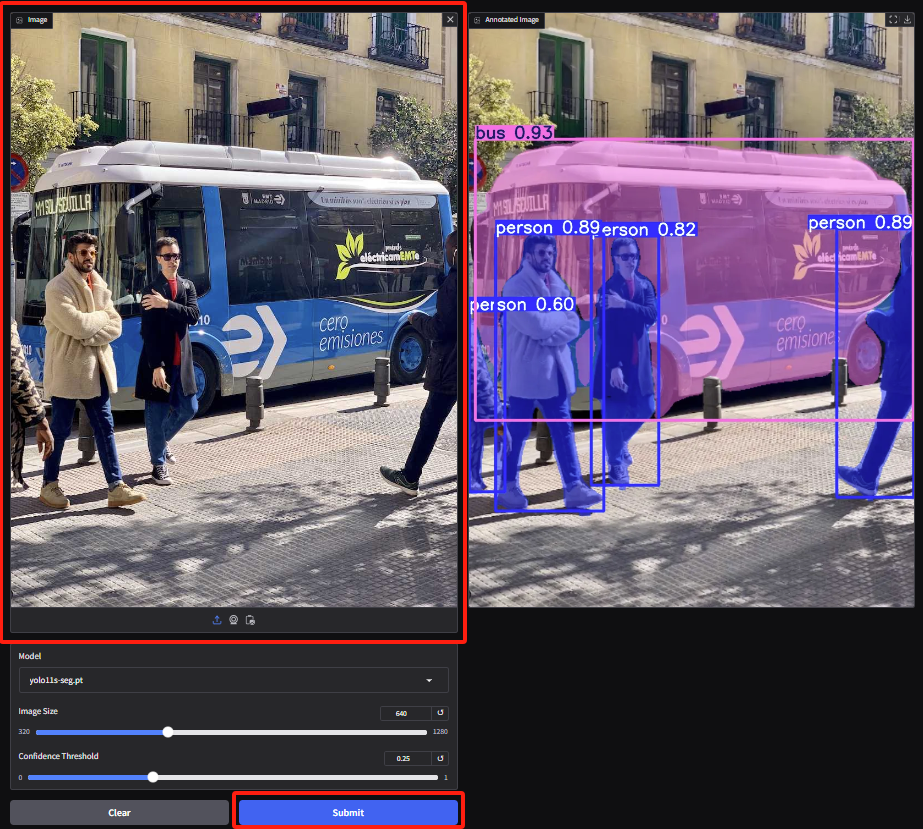
2. Accédez à la page de démonstration de segmentation d'instance, téléchargez l'image et ajustez les paramètres, puis cliquez sur « Soumettre » pour terminer l'opération de segmentation. Même avec des occlusions, YOLOv11 fait un excellent travail en segmentant avec précision les personnes et en décrivant le bus.
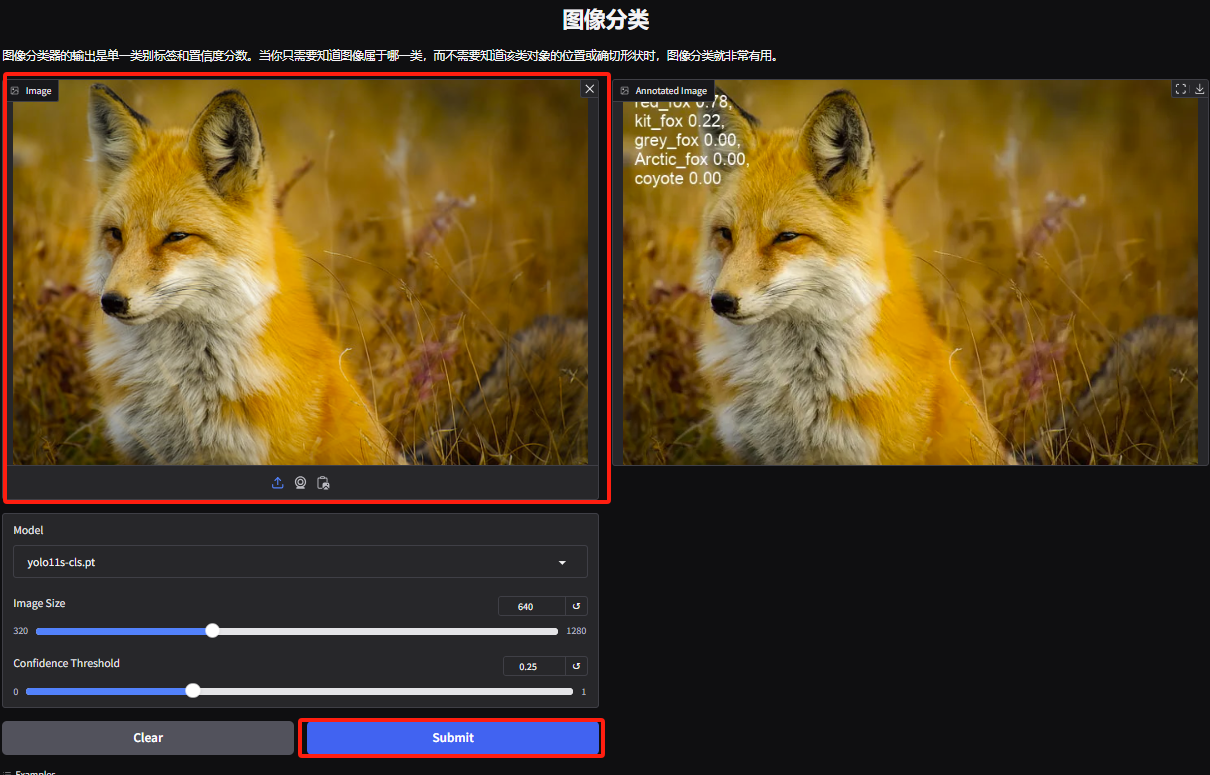
3. Accédez à la page de démonstration de classification d'objets. L'éditeur a téléchargé une photo d'un renard. YOLOv11 peut détecter avec précision l'espèce spécifique du renard sur la photo comme étant un renard roux.
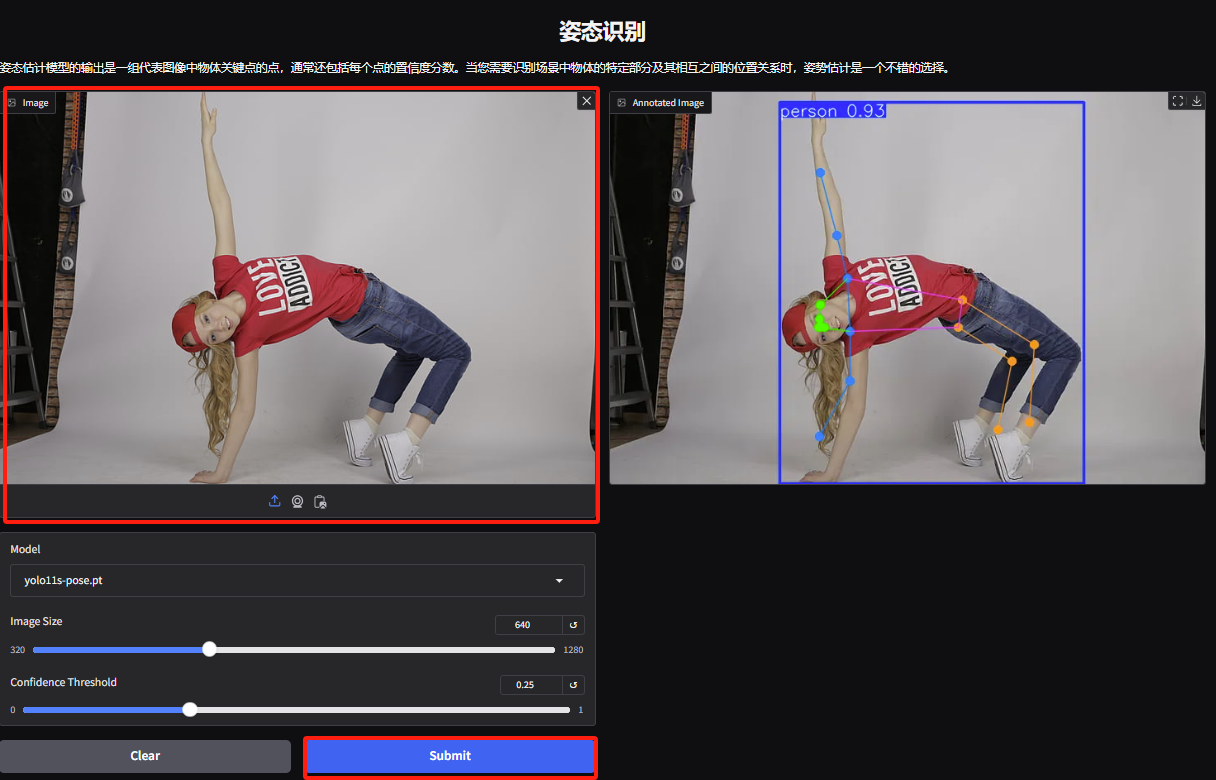
4. Accédez à la page de démonstration de reconnaissance des gestes, téléchargez l'image, ajustez les paramètres en fonction de l'image et cliquez sur « Soumettre » pour terminer l'analyse du mouvement des gestes. Vous pouvez voir qu'il analyse avec précision les mouvements corporels exagérés du personnage.
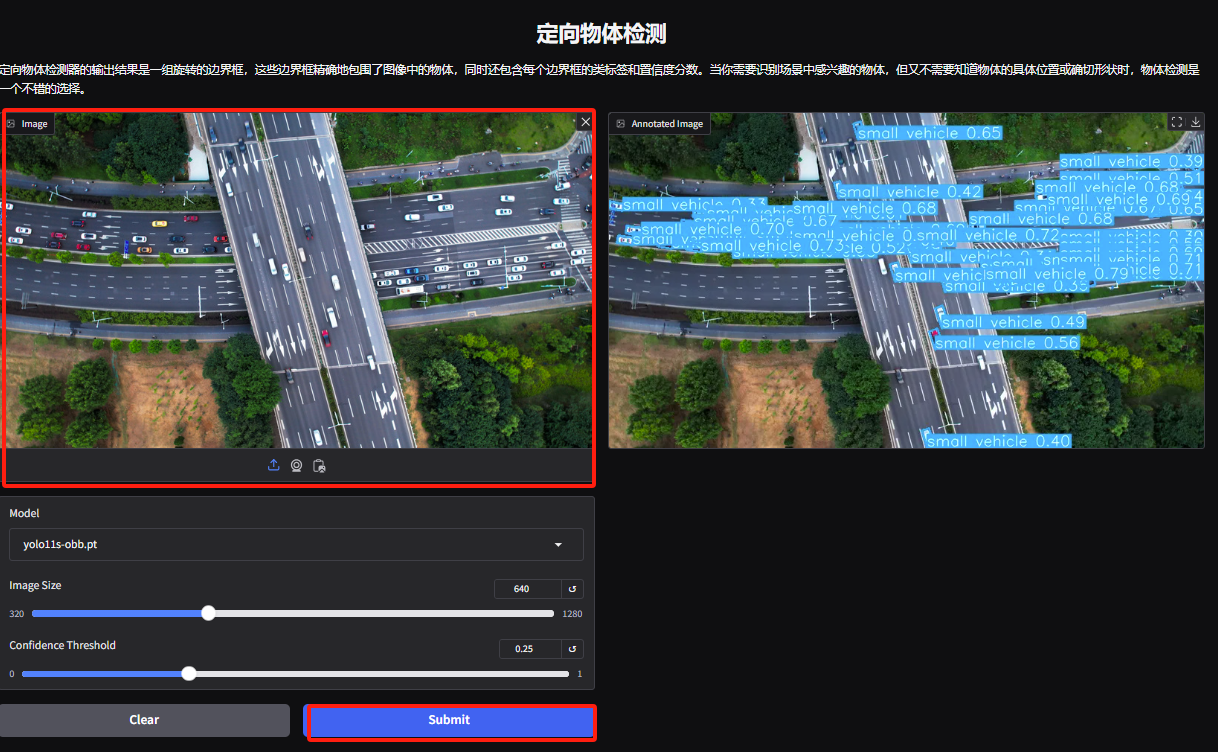
5. Sur la page de démonstration de détection d’objets dirigés, téléchargez une image et ajustez les paramètres, puis cliquez sur « Soumettre » pour identifier l’emplacement spécifique et la classification de l’objet.