Command Palette
Search for a command to run...
Au-delà De GPT-4o ! Du HTML Au Markdown, Organisez Des Pages Web Complexes En Un Clic ; Les Conversations d'IA Ne Sont Plus Froides Et Les Conversations De Grands Modèles Affinent Les Ensembles De Données Pour Rendre Les Réponses Plus Fluides

Face à un contenu de page Web contenant des informations redondantes, comment pouvons-nous extraire rapidement des informations essentielles complètes ? Le modèle Reader-LM vous offre une solution professionnelle. Reader-LM peut traiter efficacement du contenu très long jusqu'à 256 Ko et convertir avec précision le HTML en format Markdown clair. Ses performances dépassent même celles des grands modèles de langage tels que GPT-4o, et sa conception légère le rend également plus adapté aux scénarios à ressources limitées.
à l'heure actuelle,Le modèle Reader-LM est désormais disponible sur le site hyper.ai. Vous pouvez bénéficier d'une conversion efficace avec un démarrage en un clic. Vous n’avez plus à vous soucier de l’organisation des informations Web.
Du 13 au 17 janvier, le site officiel de hyper.ai a été mis à jour rapidement :
* Ensembles de données publiques de haute qualité : 10
* Tutoriels de haute qualité : 9
* Sélection d'articles communautaires : 5 articles
* Entrées d'encyclopédie populaire : 5
* Principales conférences avec date limite en janvier : 5
Visitez le site officiel : hyper.ai
Ensembles de données publiques sélectionnés
1. Ensemble de données DPO de type humain Ensemble de données de réglage fin de dialogue de grand modèle
Cet ensemble de données est spécialement conçu pour améliorer la fluidité et l'engagement des conversations de grands modèles linguistiques, visant à guider le modèle pour générer des réponses plus humaines. L'ensemble de données couvre 256 sujets et contient 10 884 échantillons dans divers domaines, notamment la technologie, la vie quotidienne, la science, l'histoire et l'art.
Utilisation directe :https://go.hyper.ai/zDsGL

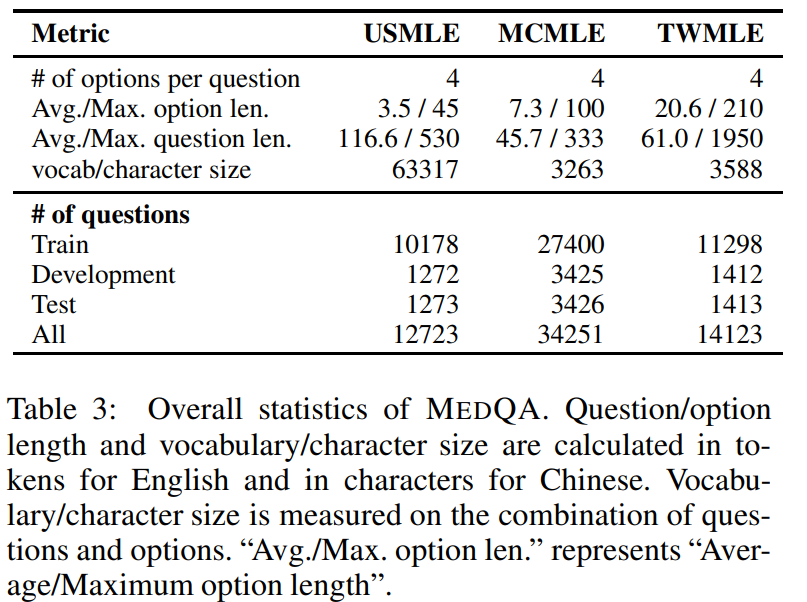
2. Ensemble de données de réponses aux questions de texte médical MedQA
L'ensemble de données MedQA simule le style de l'examen de licence médicale des États-Unis (USMLE) et est conçu pour évaluer la compréhension et l'application des connaissances médicales par le modèle. L'ensemble de données est collecté à partir d'examens médicaux professionnels et couvre l'anglais, le chinois simplifié et le chinois traditionnel, contenant respectivement 12 723, 34 251 et 14 123 questions.
Utilisation directe :https://go.hyper.ai/cV2ei
3. Identification des légumes Ensemble de données de reconnaissance d'images de légumes
L'ensemble de données contient des images de six types de légumes : aubergines, haricots, gombos, courges, pommes de terre et oignons, avec 800 images de chaque type, pour un total de 4 800 images. Il vise à améliorer les capacités de l’apprentissage automatique et de la vision par ordinateur dans la détection, la classification et la reconnaissance des légumes.
Utilisation directe :https://go.hyper.ai/mCZr4

4. Ensemble de données de panneaux de signalisation Street View en Chine
L'ensemble de données comprend 9 898 images de Street View. Chaque photo contient au moins un ou plusieurs panneaux de signalisation, et les coordonnées et catégories des panneaux de signalisation sont indiquées. Les données proviennent de la base de données de détection des panneaux de signalisation de Chine.
Utilisation directe :https://go.hyper.ai/9wb5f

5. Images de serpents prétraitées
L'ensemble de données contient cinq espèces de serpents : la couleuvre d'eau du Nord, la couleuvre rayée commune, la couleuvre brune de Decker, la couleuvre obscure et le crotale de l'Ouest. L'ensemble de données a été prétraité pour augmenter la luminosité et le contraste, supprimer et recadrer manuellement les images pour rendre les images plus propres, uniformes et utilisables.
Utilisation directe :https://go.hyper.ai/YAgyI

6. Panneaux de signalisation chinois Données d'image des panneaux de signalisation chinois
L'ensemble de données contient 5 998 images de panneaux de signalisation provenant de 58 catégories. Chaque image est une vue agrandie d'un seul panneau de signalisation. Les annotations fournissent les propriétés de l'image (nom du fichier, largeur, hauteur) ainsi que les coordonnées des panneaux de signalisation dans l'image et les catégories (par exemple, limite de vitesse de 5 km/h).
Utilisation directe :https://go.hyper.ai/Tvvh8

7. Images de préférences de style humain Ensemble de données de préférences de génération d'images
Cet ensemble de données est un ensemble de données annoté par l’homme pour évaluer les modèles de génération de texte en image. Il collecte les évaluations de consensus humain des modèles de génération d'images en montrant deux images et en demandant aux participants laquelle semble la moins étrange ou artificielle, et comprend plus de 1,2 million de votes de consensus humain.
Utilisation directe :https://go.hyper.ai/dErEz
8. M²E : Ensemble de données de formules mathématiques multilignes
L'ensemble de données contient 99 956 images d'expressions mathématiques multilignes et leurs annotations. Toutes les images sont prises avec un téléphone portable à partir de scènes du monde réel, et plusieurs lignes de formules mathématiques sont capturées à partir de sujets de test de mathématiques et de cahiers d'exercices pour la tâche de reconnaissance de formules mathématiques.
Utilisation directe :https://go.hyper.ai/5BMnN
9. Ensemble de données sur les distiques chinois
Cet ensemble de données contient environ 740 000 couplets. fixed_couplets_in.txt est le distique supérieur et fixed_couplets_out.txt est le distique inférieur.
Utilisation directe :https://go.hyper.ai/oPxHl
10. Ensemble de données sur le bruit audio
Cet ensemble de données contient 10 catégories différentes de bruit et peut être utilisé pour le filtrage du bruit, la génération de bruit et la reconnaissance du bruit dans la classification audio, la reconnaissance audio, la génération audio et l'apprentissage automatique lié à l'audio.
Utilisation directe :https://go.hyper.ai/MXXZy
Tutoriels publics sélectionnés
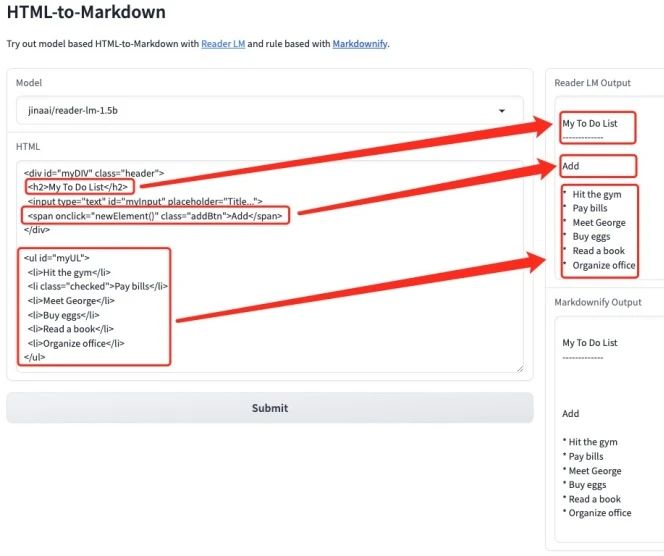
1. Reader-LM : Convertissez du HTML en MarkDown rapidement et efficacement
Reader-LM est un modèle spécialement conçu pour convertir le contenu HTML brut du Web en un format Markdown clair et ordonné. Il excelle dans la gestion de textes longs et de contenus multilingues, prenant en charge des longueurs de contexte allant jusqu'à 256 Ko. Son objectif est de répondre au besoin d’extraction de données efficace et économique à partir de contenus Web bruyants.
Ce tutoriel montre comment convertir du HTML en markdown à l'aide de reader-lm-1.5b ou reader-lm-0.5b. Cliquez sur le lien ci-dessous et suivez le tutoriel pour en faire l'expérience.
Exécutez en ligne :https://go.hyper.ai/S15IL
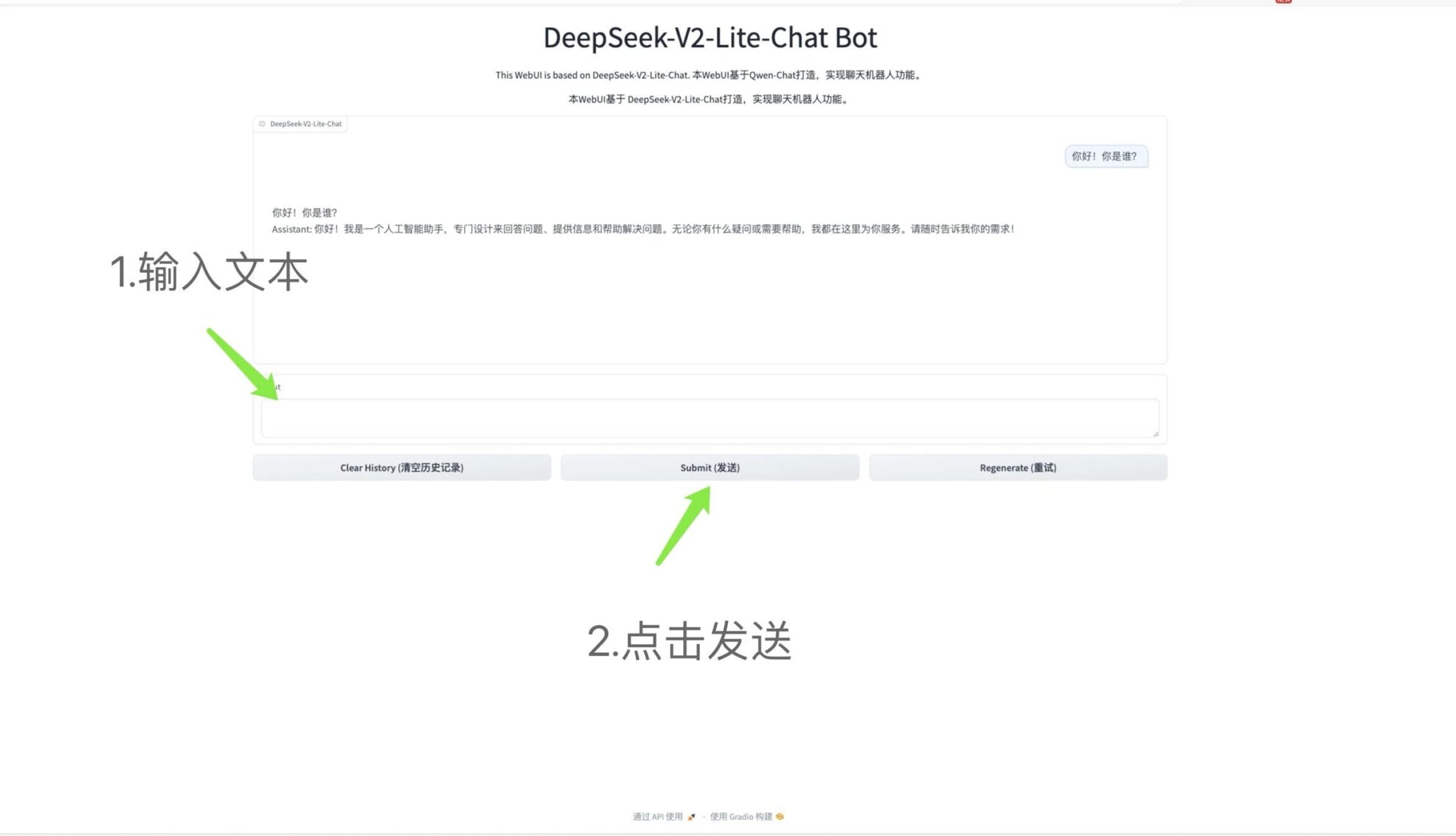
2. Déploiement en un clic de DeepSeek-V2-Lite-Chat
DeepSeek-V2 est un puissant modèle de langage de mélange d'experts (MoE) qui est économique à former et efficace à déduire. Il contient 236 B de paramètres au total, où chaque jeton active 21 B de paramètres.
Ce tutoriel est une démonstration de déploiement en un clic de DeepSeek-V2-Lite-Chat. Il vous suffit de cloner et de démarrer le conteneur et de copier directement l'adresse API générée pour expérimenter l'inférence du modèle.
Exécutez en ligne :https://go.hyper.ai/AD6XU
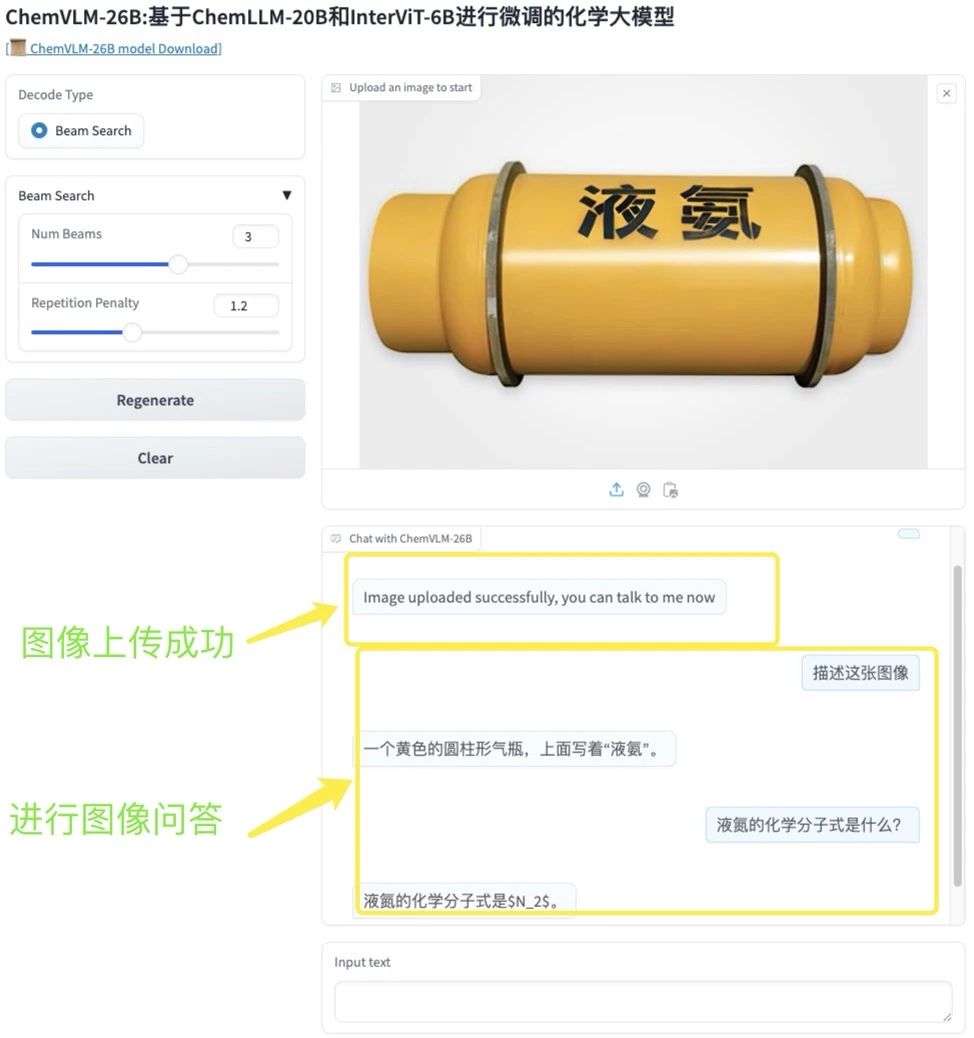
3.Déploiement en un clic de ChemVLM-26B
ChemVLM est un modèle de langage multimodal open source pour la chimie. Le modèle vise à résoudre l’incompatibilité entre la compréhension d’images chimiques et l’analyse de texte. En combinant les avantages du Visual Transformer (ViT), du Multi-layer Perceptron (MLP) et du Large Language Model (LLM), il permet un raisonnement complet des images chimiques et du texte.
Suivez les étapes du didacticiel et copiez directement l'adresse API générée pour utiliser ChatVLM-26B.
Exécutez en ligne :https://go.hyper.ai/NRBXG
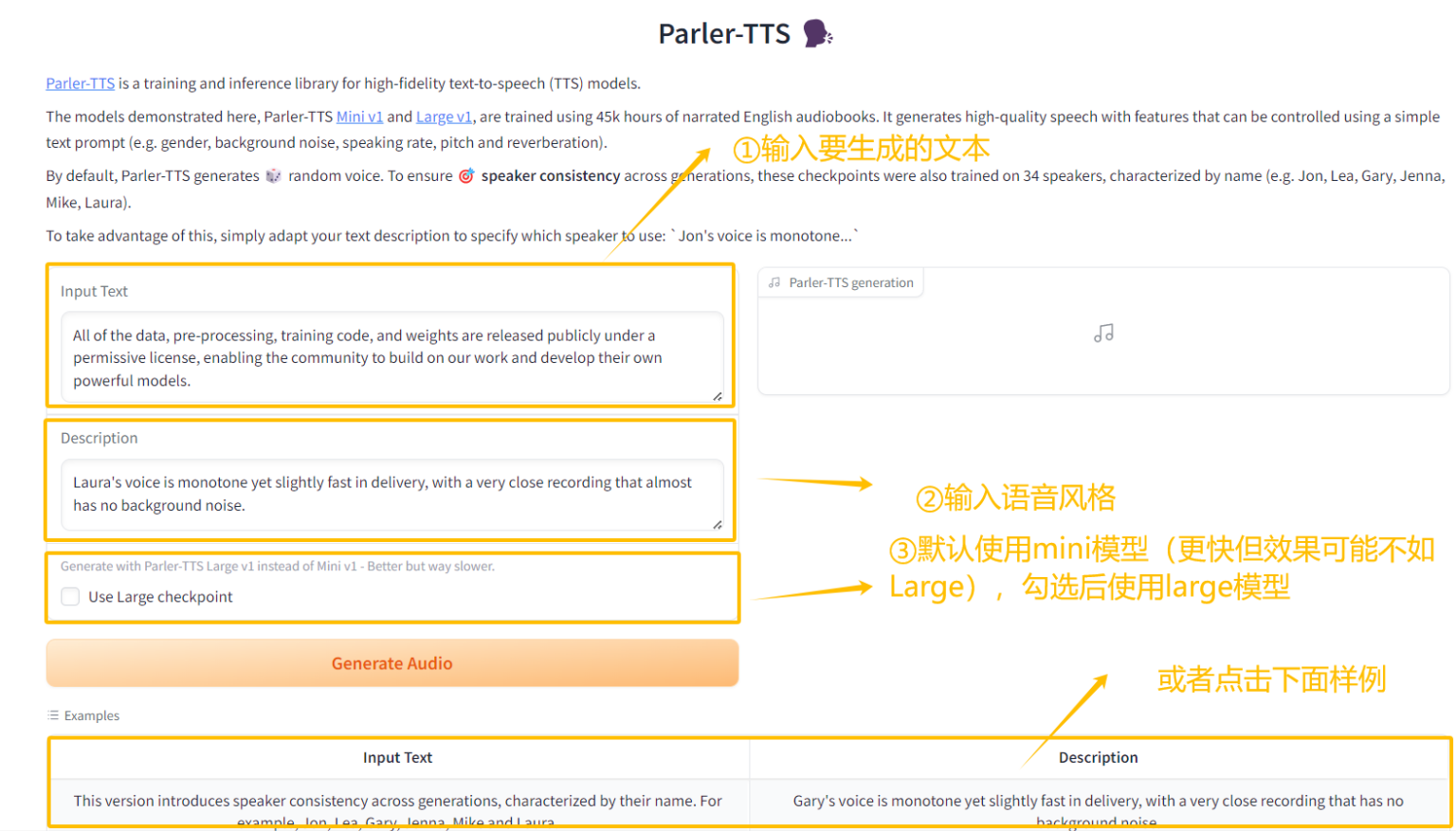
4. Déploiement en un clic de Parler-TTS
Parler-TTS est un modèle de synthèse vocale (TTS) léger qui peut générer un discours naturel de haute qualité dans le style d'un locuteur donné. Il offre un haut degré de liberté et d'innovation et peut contrôler le genre, le timbre, l'intonation et la scène du locuteur (à l'intérieur, à l'extérieur, sur la route, dans une salle de concert, etc.) via Prompt.
Ce projet peut générer une interface interactive front-end via l'interface Gradio. Les modèles et dépendances pertinents ont été déployés et les fichiers audio sur l'eau peuvent être générés en un seul clic.
Exécutez en ligne :https://go.hyper.ai/pk6lF
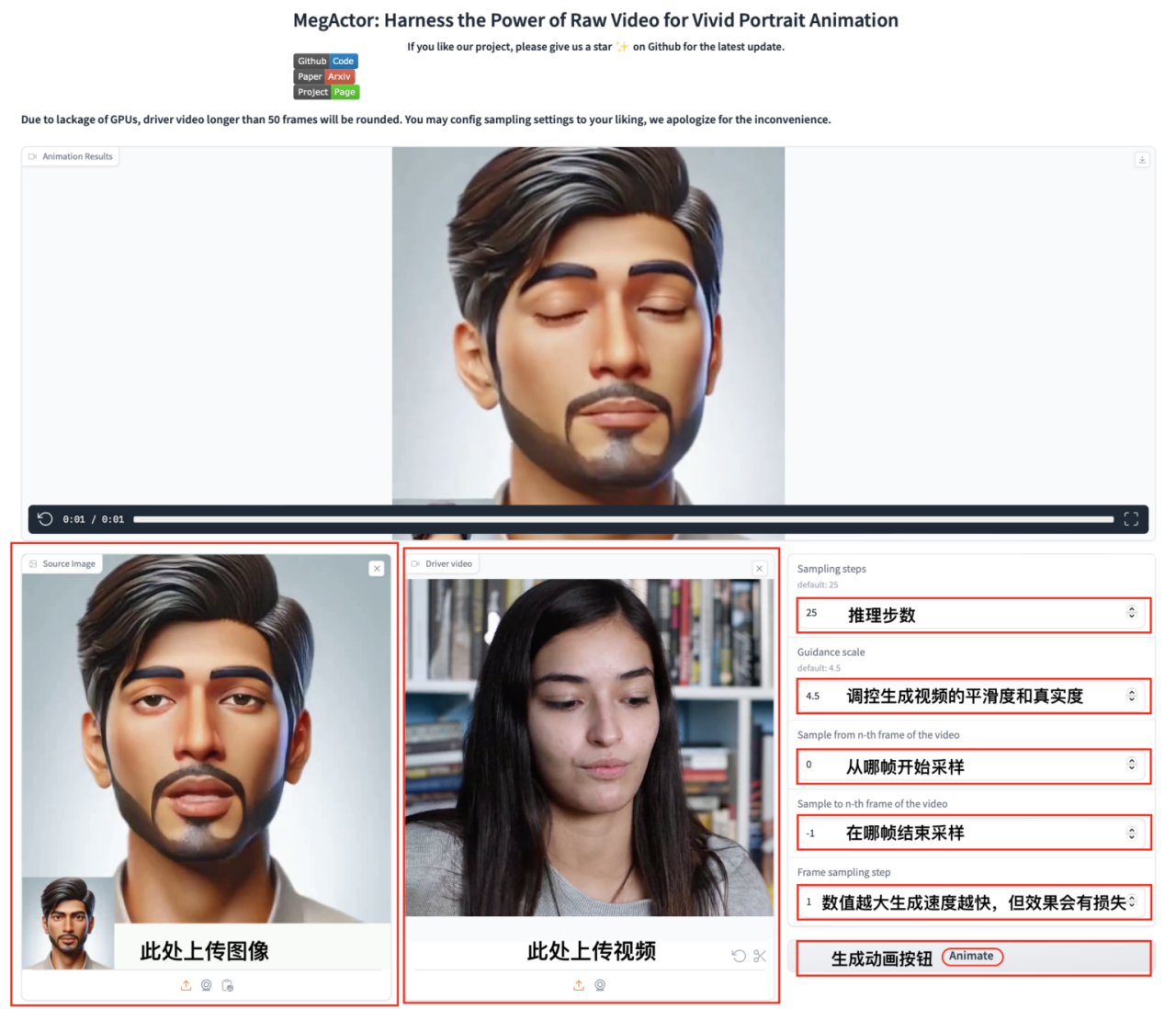
5. Démo du générateur d'animation de portraits MegActor
MegActor est un animateur de portrait qui utilise la vidéo brute comme pilote pour générer des vidéos de têtes parlantes réalistes et animées.
Suivez les étapes du didacticiel, clonez simplement le lanceur et ouvrez l'adresse API pour générer des vidéos synthétiques vives basées sur le contenu vidéo d'origine.
Exécutez en ligne :https://go.hyper.ai/wkCPo
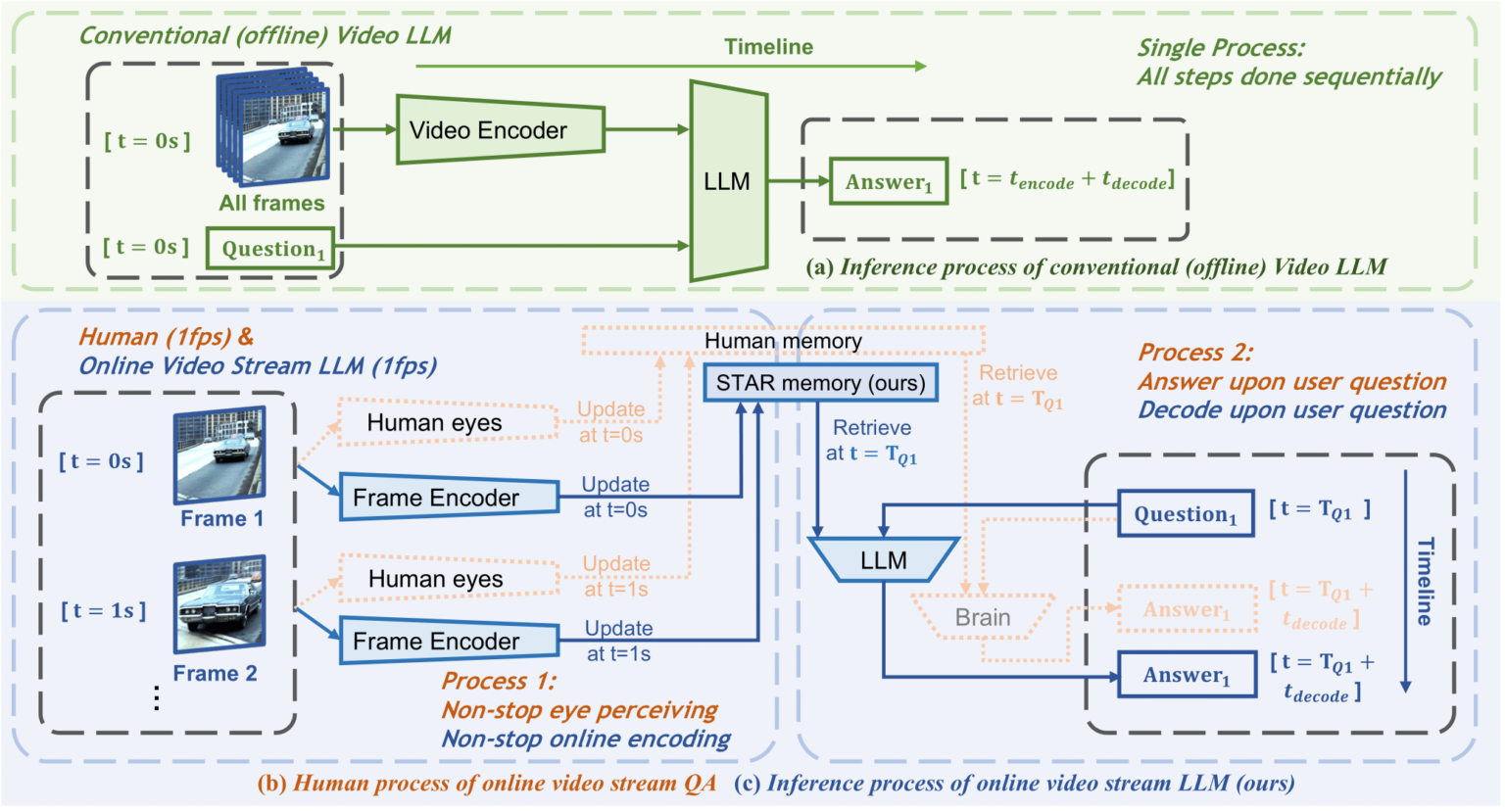
6. Démonstration de compréhension de la vidéo Flash-VStream
Flash-VStream est un modèle de langage vidéo qui simule les mécanismes de la mémoire humaine. Il est capable de traiter des flux vidéo extrêmement longs en temps réel et de répondre simultanément aux requêtes des utilisateurs.
Ce tutoriel est une démonstration d'exécution en un clic de Flash-VStream. L'environnement et les dépendances pertinents ont été installés. Vous pouvez en faire l'expérience en le clonant et en le démarrant en un clic.
Exécutez en ligne :https://go.hyper.ai/M3pBO
7. PhotoMaker V2 génère des portraits personnalisés en quelques secondes Démo
PhotoMaker est un modèle graphique personnalisé de portrait efficace, open source par l'équipe Tencent en 2024. Il peut générer rapidement des photos de style artistique personnalisées basées sur des photos de portrait. En plus de générer des photos personnalisées de personnes, il peut également modifier l'âge et le sexe des personnes et intégrer les caractéristiques de différentes personnes pour créer de nouvelles informations sur les personnes.
Ce tutoriel est la version 2.0 de PhotoMaker, qui a considérablement amélioré la cohérence et la contrôlabilité des personnages par rapport à la V1.
Exécutez en ligne :https://go.hyper.ai/VcewN

8. Démo du générateur de bandes dessinées StoryDiffusion
StoryDiffusion est un outil d'IA axé sur la génération d'images et de vidéos à longue portée. Cette technologie utilise un mécanisme d'auto-attention cohérent pour assurer la continuité et la cohérence du contenu des images et des vidéos, en maintenant la cohérence du style, que ce soit lors de la création de bandes dessinées, de personnages de dessins animés ou de la génération de longues vidéos.
Ce tutoriel est la dernière version du package d'exécution en un clic StoryDiffusion. Vous pouvez découvrir StoryDiffusion avec un clonage en un clic.
Exécutez en ligne :https://go.hyper.ai/HPu2p

9. Simulateur de dynamique moléculaire facile à utiliser LAMMPS : contrôle de température npt pour estimer le point de fusion du FCC Cu
LAMMPS peut être utilisé pour modéliser une variété de matériaux, y compris les matériaux à l'état solide (métaux, semi-conducteurs), les biomolécules, les polymères, etc., et peut fournir une variété de modèles d'interaction de particules pour différents matériaux.
Ce tutoriel est un tutoriel d'introduction pour LAMMPS : estimation du point de fusion du FCC Cu à l'aide du contrôle de température npt. Vous pouvez l'exécuter en utilisant la version CPU de LAMMPS pour expérimenter des simulations de dynamique moléculaire.
Exécutez en ligne :https://go.hyper.ai/qQSqr
💡Nous avons également créé un groupe d'échange de tutoriels Stable Diffusion. Bienvenue aux amis pour scanner le code QR et commenter [tutoriel SD] pour rejoindre le groupe pour discuter de divers problèmes techniques et partager les résultats de l'application ~

Articles de la communauté
Découvrez AI Compiler La 6ème revue du salon technique est ici. Quatre experts en compilateurs seniors de Horizon Robotics, Zhiyuan, ByteDance et Lingchuan Technology ont montré à tout le monde les derniers résultats de recherche de leurs équipes respectives. Parallèlement, ils ont également combiné de riches cas d’application pratique pour expliquer de manière simple à comprendre le processus d’application et les effets de ces résultats dans la résolution de problèmes pratiques.
Voir le récapitulatif de l'événement :https://go.hyper.ai/KDzY3
HyperAI a mené un entretien approfondi avec le professeur Xie Weidi, professeur associé titulaire à l'Université Jiao Tong de Shanghai. S'appuyant sur son expérience personnelle, il a partagé avec nous son expérience de transformation de la vision par ordinateur vers l'IA pour les soins de santé, et a également réalisé une analyse approfondie des tendances de développement futures de l'industrie. Ceci est un rapport détaillé de l'entretien.
Voir le rapport complet :https://go.hyper.ai/LqpqE
3. Capteur tactile basé sur un film magnétique flexible
La perception tactile est l’une des capacités importantes des robots intelligents et de l’interaction homme-ordinateur, mais la manière d’obtenir une détection tactile de haute précision et à réponse rapide reste confrontée à de nombreux défis. Le Dr Yan Youcan du Centre national de la recherche scientifique français a partagé avec tout le monde la conception et l'application de capteurs tactiles basés sur des films magnétiques flexibles, et a présenté comment utiliser le réseau Halbach magnétisé orthogonalement pour réaliser l'auto-découplage des forces tridimensionnelles. Cet article est un rapport détaillé sur ce qui a été partagé.
Voir le rapport complet :https://go.hyper.ai/Y5uA0
La fusion d'images médicales multimodales peut révéler de nombreuses informations précieuses et aider les médecins à établir des diagnostics de maladies plus professionnels, mais l'un des principaux défis auxquels nous sommes actuellement confrontés est que les fonctionnalités utilisées pour la fusion et les fonctionnalités utilisées pour l'alignement sont incompatibles. L'Université des sciences et technologies de Kunming et l'Université océanique de Chine ont proposé conjointement une méthode d'alignement de caractéristiques étape par étape bidirectionnelle BSAFusion, qui peut réaliser l'alignement et la fusion d'images médicales multimodales. Cet article est une interprétation et un partage détaillés du document.
Voir le rapport complet :https://go.hyper.ai/sTySj
La pénurie de ressources médicales est un problème à long terme qui affecte le système médical mondial. À cette fin, des équipes de recherche de quatre grandes universités ont proposé KG4Diagnosis. Il s’agit d’un nouveau cadre multi-agents hiérarchique qui peut être utilisé pour automatiser la construction, le diagnostic, le traitement et le raisonnement des graphes de connaissances médicales, aidant à diagnostiquer 362 maladies courantes dans plusieurs domaines médicaux tels que l’obésité. Cet article est une interprétation et un partage détaillés du document.
Voir le rapport complet :https://go.hyper.ai/0CPhV
Articles populaires de l'encyclopédie
1. Perte par diffusion
2. Attention causale
3. Théorème de représentation de Kolmogorov-Arnold
4. Compréhension linguistique multitâche à grande échelle (MMLU)
5. Apprentissage contrastif
Voici des centaines de termes liés à l'IA compilés pour vous aider à comprendre « l'intelligence artificielle » ici :
Date limite de janvier pour la conférence de haut niveau

Suivi unique des principales conférences universitaires sur l'IA :https://go.hyper.ai/event
Voici tout le contenu de la sélection de l’éditeur de cette semaine. Si vous avez des ressources que vous souhaitez inclure sur le site officiel hyper.ai, vous êtes également invités à laisser un message ou à soumettre un article pour nous le dire !
À la semaine prochaine !
À propos d'HyperAI
HyperAI (hyper.ai) est une communauté leader en matière d'intelligence artificielle et de calcul haute performance en Chine.Nous nous engageons à devenir l'infrastructure dans le domaine de la science des données en Chine et à fournir des ressources publiques riches et de haute qualité aux développeurs nationaux. Jusqu'à présent, nous avons :
* Fournir des nœuds de téléchargement accélérés nationaux pour plus de 1 700 ensembles de données publiques
* Comprend plus de 500 tutoriels en ligne classiques et populaires
* Interprétation de plus de 200 cas d'articles AI4Science
* Prend en charge la recherche de plus de 600 termes associés
* Hébergement de la première documentation complète d'Apache TVM en Chine
Visitez le site Web officiel pour commencer votre parcours d'apprentissage :
Enfin, je recommande un « Programme d’incitation aux créateurs ». Les amis intéressés peuvent scanner le code QR pour participer !









