Command Palette
Search for a command to run...
Microsoft Et Tencent Sont En Concurrence Technologique, TRELLIS Mène La Nouvelle Direction Du Support Multiformat Dans Le Domaine De La Génération 3D ; Plus De 5 000 Questions Répondues ! VIS-Bench Permet À l'IA d'apprendre La « Mémoire Spatiale »

En novembre dernier, Tencent a lancé le modèle génératif Hunyuan3D, le premier grand modèle open source du secteur qui prend en charge la génération 3D de texte et d'images. Moins d'un mois plus tard, Microsoft a publié un nouveau framework, TRELLIS, pour rejoindre la compétition dans le domaine de la génération d'actifs 3D. TRELLIS prend en charge plusieurs formats de sortie, notamment le champ de rayonnement, le gaussien 3D et le maillage, offrant une flexibilité maximale pour différents besoins.
Les deux modèles sont désormais disponibles sur le site officiel hyper.ai. Venez essayer pour voir lequel est le meilleur.
Utilisez Hunyuan3D en ligne :https://go.hyper.ai/Rsrno
Utilisation de TRELLIS en ligne :https://go.hyper.ai/JE5s5
Du 6 au 11 janvier, le site officiel de hyper.ai est mis à jour :
* Ensembles de données publiques de haute qualité : 10
* Sélection de tutoriels de haute qualité : 6
* Sélection d'articles communautaires : 8 articles
* Entrées d'encyclopédie populaire : 5
* Principales conférences avec dates limites en janvier : 7
Visitez le site officiel :hyper.ai
Ensembles de données publiques sélectionnés
1. VSI-Bench, test de référence en intelligence spatiale visuelle
L'ensemble de données contient plus de 5 000 paires de questions-réponses, couvrant près de 290 vidéos de scènes intérieures réelles, impliquant une variété d'environnements tels que des résidences, des bureaux et des usines, et couvrant de multiples problèmes tels que la reconnaissance d'objets, la relation de position et la prédiction d'actions.
Utilisation directe :https://go.hyper.ai/q0DYA

2. Ensemble de données d'extraction de caractéristiques faciales Ensemble de données d'extraction de caractéristiques faciales
Cet ensemble de données est un ensemble de données étiqueté contenant 750 images permettant de détecter les sourcils, les yeux, le nez, les lèvres et la barbe du visage. Le processus d'étiquetage des données a été réalisé dans Roboflow et exporté au format YOLOv8.
Utilisation directe :https://go.hyper.ai/O3kER

3. Ensemble de données d'analyse des sentiments et des émotions Ensemble de données d'analyse des sentiments et des émotions
L'ensemble de données contient 422 000 phrases d'analyse des sentiments et 3 309 phrases d'analyse des sentiments en tant que suppléments. L'analyse des sentiments identifie 6 émotions différentes : la joie, la tristesse, la colère, la peur, l'amour et la surprise.
Utilisation directe :https://go.hyper.ai/wFNO6
4. Ensemble de données d'entraînement aux problèmes de programmation mathématique Eurus-2-RL-Data
Cet ensemble de données est un ensemble de données de haute qualité spécifiquement utilisé pour la formation par apprentissage par renforcement. Il est principalement utilisé pour résoudre des problèmes mathématiques et de programmation. Il contient environ 455 000 problèmes mathématiques et 27 000 problèmes de programmation.
Utilisation directe :https://go.hyper.ai/Wdo1k
5. Ensemble de données de raisonnement médical SFT o1 Reasoning
Cet ensemble de données est conçu pour affiner le grand modèle de langage médical HuatuoGPT-o1 afin d'améliorer ses performances dans les tâches de raisonnement médical complexes. La construction de l'ensemble de données s'appuie sur GPT-4o, qui garantit l'exactitude et la fiabilité des données en recherchant des questions médicales vérifiables et en vérifiant les réponses à l'aide d'un vérificateur médical.
Utilisation directe :https://go.hyper.ai/XMtXp
6. Ensemble de données simplifiées en texte chinois MCTS
L'ensemble de données contient 723 phrases structurées complexes sélectionnées à partir d'un corpus d'actualités basé sur la norme Penn Chinese Treebank (CTB), et chaque phrase est équipée de plusieurs versions simplifiées manuellement, ce qui en fait l'ensemble de données d'évaluation le plus grand et le plus référencé pour la tâche de simplification de texte chinois.
Utilisation directe :https://go.hyper.ai/UR3CN
7. educhat-sft-002-data-osm Ensemble de données de dialogue éducatif
L'ensemble de données contient 4 millions de points de données, couvrant une variété de secteurs verticaux éducatifs, tels que les questions-réponses ouvertes, la notation des dissertations, l'enseignement heuristique, le soutien émotionnel et le tutorat de cours.
Utilisation directe :https://go.hyper.ai/nQw0K
8. Ensemble de données de réglage fin des tâches arithmétiques GOAT
Cet ensemble de données contient deux fichiers : dataset.json et dataset.ipynb. Le fichier dataset.json contient environ 1,7 million de données synthétiques pour les tâches arithmétiques générées par dataset.ipynb.
Utilisation directe :https://go.hyper.ai/8ZAvG
9. Ensemble de données de raisonnement mathématique NaturalProofs
L'ensemble de données est un corpus multi-domaines permettant d'étudier le raisonnement mathématique en langage naturel. Il contient environ 30 000 énoncés et preuves de théorèmes, 15 000 définitions et 2 000 pages supplémentaires (par exemple, axiomes, corollaires), tous écrits en langage mathématique naturel.
Utilisation directe :https://go.hyper.ai/Bk4WE
10. Ensemble de données de pré-formation du dialogue de trafic TransGPT-pt&sft
Cet ensemble de données fait partie de TransGPT, le premier modèle de transport complet en Chine. Il contient environ 346 000 éléments de données textuelles dans le domaine des transports, qui sont utilisés pour la pré-formation dans le domaine, et environ 58 000 éléments de données de dialogue dans le domaine des transports, qui sont utilisés pour le réglage fin.
Utilisation directe :https://go.hyper.ai/vuDHa
Tutoriels publics sélectionnés
1. Hunyuan3D : générez des ressources 3D en seulement 10 secondes
Hunyuan3D est un modèle de diffusion générative 3D, comprenant une version allégée et une version standard, toutes deux prenant en charge la génération d'éléments 3D de haute qualité à partir d'entrées de texte et d'image. Après une évaluation multidimensionnelle qualitative et quantitative, Hunyuan3D-1.0 a obtenu de très bons résultats en termes de détails géométriques, de détails de texture, de cohérence texture-géométrie, de rationalité 3D et de conformité aux instructions.
Ce tutoriel est une version allégée de Hunyuan3D. Cliquez sur le lien ci-dessous et suivez les instructions du didacticiel pour découvrir la génération de modèles 3D.
Exécutez en ligne :https://go.hyper.ai/Rsrno
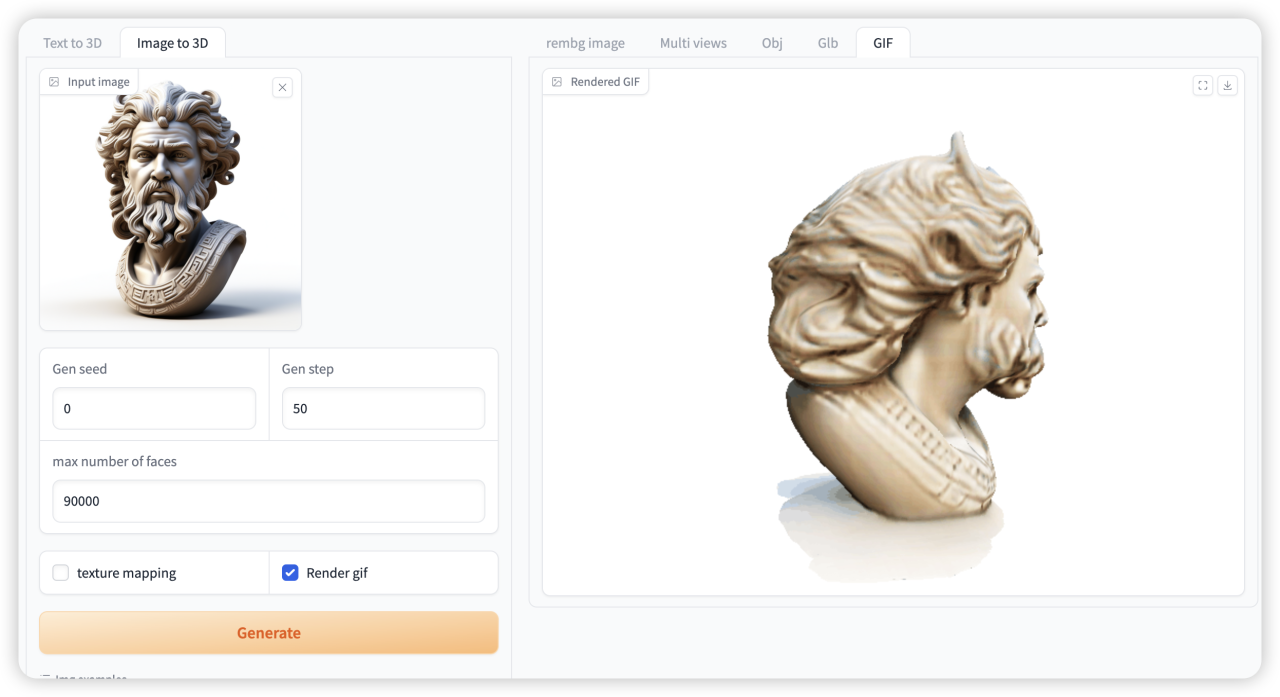
2. TRELLIS : démonstration du modèle de génération d'actifs 3D open source de Microsoft
TRELLIS est un framework d'interprétabilité basé sur un réseau neuronal graphique développé par l'équipe Microsoft en 2024. Il vise à fournir une interprétabilité efficace des modèles en apprenant les caractéristiques des données structurées par graphique.
Le modèle et l'environnement ont été déployés. Vous pouvez utiliser le grand modèle pour convertir des images en images 3D selon les instructions du didacticiel.
Exécutez en ligne :https://go.hyper.ai/JE5s5

3.Déploiement rapide de ChatGLM2-6b-32k
ChatGLM-6B est un modèle de langage conversationnel open source qui prend en charge le chinois et l'anglais. Il est basé sur l'architecture General Language Model (GLM) et comporte 6,2 milliards de paramètres. Associé à la technologie de quantification de modèle, les utilisateurs peuvent effectuer un niveau local (quantification INT4) sur des cartes graphiques grand public avec seulement 6 Go de mémoire vidéo).
Suivez les étapes du didacticiel et copiez directement l'adresse API générée pour utiliser ChatGLM-6B.
Exécutez en ligne :https://go.hyper.ai/B0b7V
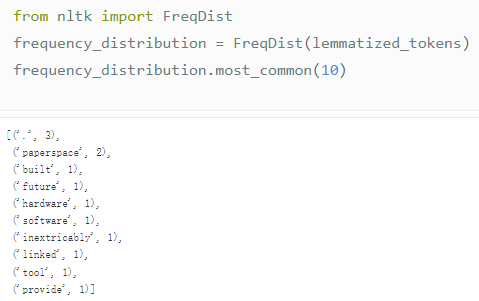
4. Traitement du langage naturel avec NLTK
NLTK est l’une des plateformes les plus populaires pour créer des programmes Python à l’aide de données en langage naturel. En plus des bibliothèques de traitement de texte pour la classification, la tokenisation, la recherche de racines, le balisage, l'analyse et le raisonnement sémantique, il fournit des interfaces simples vers plus de 50 grands ensembles de données textuelles structurées (corpus) et ressources lexicales.
Ce tutoriel montre comment utiliser NLTK pour effectuer diverses opérations NLP au stade du traitement de texte et créer un modèle Keras à l'aide de certains outils NLTK pour la classification de texte d'analyse des sentiments.
Exécutez en ligne :https://go.hyper.ai/BFZ10
5. Tutoriel d'édition audio LDM
AudioLDM est un modèle de diffusion texte-audio latent capable de générer des échantillons audio réalistes à partir de n'importe quelle entrée textuelle. AudioLDM prend une invite de texte en entrée et prédit l'audio correspondant. Il peut générer des effets sonores conditionnés par du texte, de la parole humaine et de la musique.
Ce projet peut générer une interface interactive front-end via l'interface Gradio. Les modèles et dépendances pertinents ont été déployés. Cliquez sur le lien ci-dessous pour éditer l'audio.
Exécutez en ligne :https://go.hyper.ai/BCOWL
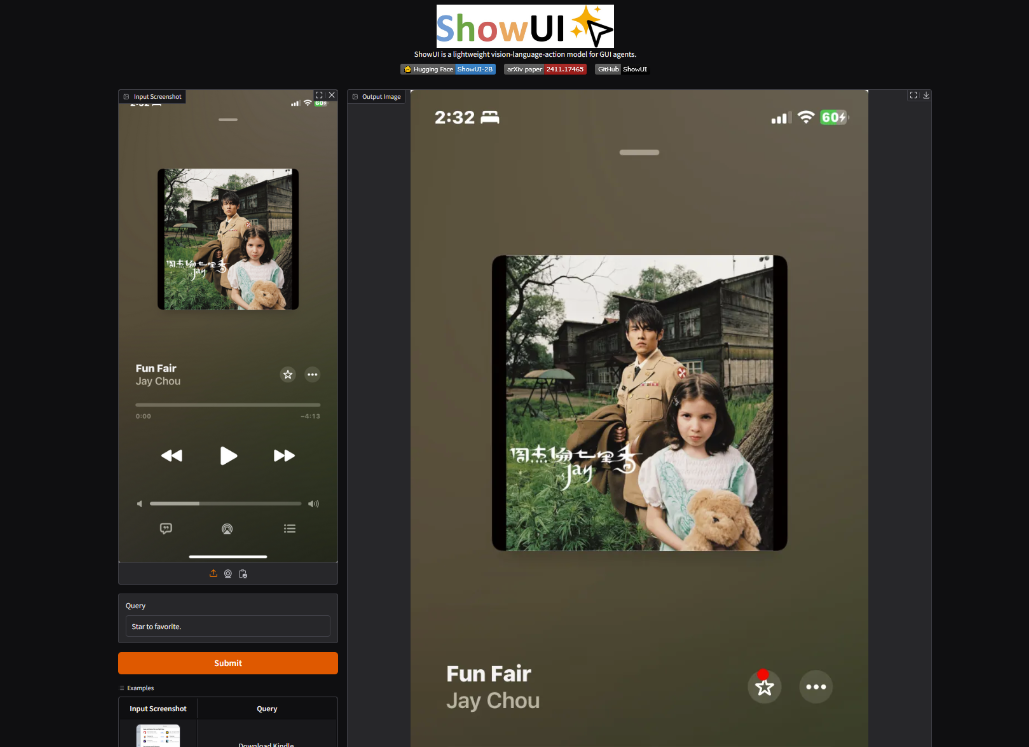
6. ShowUI : un modèle vision-langage-action axé sur l'automatisation de l'interface utilisateur graphique
Le modèle ShowUI prend en charge les scénarios d'applications Web et mobiles en comprenant le contenu de l'interface de l'écran et en effectuant des actions interactives telles que cliquer, saisir et faire défiler. Il peut effectuer automatiquement des tâches d'interface utilisateur complexes. ShowUI peut analyser les captures d'écran et les commandes utilisateur pour prédire les actions interactives sur l'interface.
Ce tutoriel est une démonstration de déploiement en un clic du modèle. Il vous suffit de cloner et de démarrer le conteneur et de copier directement l'adresse API générée pour découvrir le modèle.
Exécutez en ligne :https://go.hyper.ai/reHs7
💡Nous avons également créé un groupe d'échange de tutoriels Stable Diffusion. Bienvenue aux amis pour scanner le code QR et commenter [tutoriel SD] pour rejoindre le groupe pour discuter de divers problèmes techniques et partager les résultats de l'application ~

Articles de la communauté
Pendant la période de Noël, HyperAI a préparé pour vous 10 ensembles de données liés à Noël, qui prennent en charge l'utilisation en ligne et le téléchargement accéléré. Venez les découvrir.
Afficher le résumé du jeu de données :https://go.hyper.ai/if7Lc
La société de biotechnologie E11 Bio a lancé la technologie PRISM, qui permet de cartographier les connexions entre des millions de cellules dans tout le cerveau à un coût très faible. Cette série d’innovations devrait réduire le coût global de la connectomique du cerveau entier d’au moins 100 fois, offrant ainsi des possibilités d’exploration future du cerveau humain. Cet article est un rapport détaillé sur l'entreprise, cliquez pour le lire rapidement.
Voir le rapport complet :https://go.hyper.ai/ISc4j
HyperAI a trié et examiné les événements à fort impact dans le domaine de l'IA pour la science en 2024. Cliquez ici pour voir le rapport détaillé.
Voir le rapport complet :https://go.hyper.ai/d2Dlv
Dans le contexte du réchauffement climatique continu, des événements climatiques extrêmes rares ont commencé à se produire fréquemment. Une équipe de recherche de l'Université de Stanford, de l'Université d'État du Colorado et de l'ETH Zurich a utilisé un système de réseau neuronal convolutif d'intelligence artificielle pour prédire le réchauffement climatique et a découvert que même si nous pouvons parvenir à des réductions rapides des émissions, il existe toujours une probabilité de 90% que les températures mondiales continuent d'augmenter. Cet article est une interprétation et un partage détaillés du document.
Voir le rapport complet :https://go.hyper.ai/vDt3e
Xu Zhengtong, étudiant en troisième année de doctorat à l'Université Purdue, a partagé ses deux principaux résultats de recherche scientifique, le contrôleur de préhension réactif LeTac-MPC et UniT pour la représentation tactile unifiée des robots, avec le thème « Représentation tactile efficace en données pour l'apprentissage des robots ». Cet article est une compilation de contenu partagé, cliquez pour lire rapidement.
Voir le rapport complet :https://go.hyper.ai/IPIjj
Le CASP est depuis longtemps considéré par l’industrie comme un baromètre de la prédiction de la structure des protéines. Dans ce contexte, HyperAI a eu l’honneur d’avoir un entretien approfondi avec le professeur Zheng Wei. Grâce au CASP, un concours international qui sert de référence pour l’industrie, il a analysé pour nous les tendances actuelles de développement dans le domaine de la prédiction de la structure des protéines. Plein d'informations utiles, cliquez pour le lire rapidement.
Voir le rapport complet :https://go.hyper.ai/Y83iz
Dans une étude récente, une équipe de recherche du MIT et du Toyota Research Institute s'est penchée sur la complexité de différents modèles génératifs avancés dans la génération de polymères et a proposé une méthode de conception de novo capable de générer et d'évaluer en continu de nouveaux électrolytes polymères basés sur le GPT et la diffusion, fournissant de nouveaux candidats pour les tests expérimentaux. Cet article est une interprétation et un partage détaillés du document.
Voir le rapport complet :https://go.hyper.ai/PDc8J
Lors de la conférence CES 2025, la Nvidia RTX 5090 a été officiellement annoncée. C'est le GPU GeForce RTX le plus rapide à ce jour. Le prix initial est de 14 000 yuans et la version nationale du 5090 D est proposée au prix de 16 000 yuans. La RTX 5090 ajoute également la prise en charge FP4, permettant une empreinte mémoire plus petite et des modèles d'IA génératifs jusqu'à 2 fois plus rapides à exécuter que la génération précédente. Cet article est une introduction détaillée au produit, cliquez pour le lire rapidement.
Voir le rapport complet :https://go.hyper.ai/dyyZS
Articles populaires de l'encyclopédie
1. Norme nucléaire
2. Test t apparié
3. Compréhension linguistique multitâche à grande échelle (MMLU)
4. Fonction sigmoïde
5. La méthode des moindres carrés
Voici des centaines de termes liés à l'IA compilés pour vous aider à comprendre « l'intelligence artificielle » ici :
Date limite de janvier pour la conférence de haut niveau
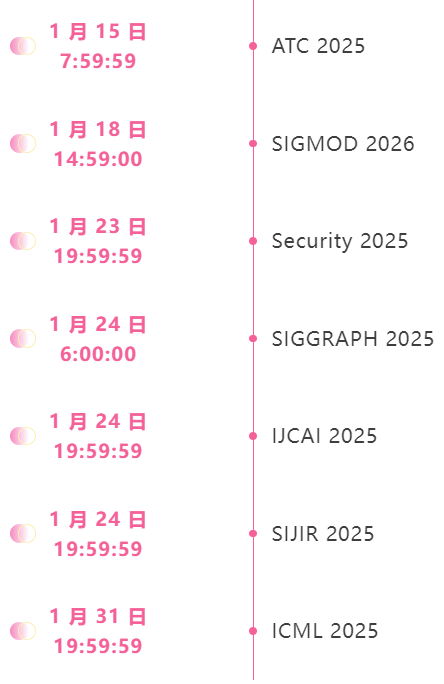
Suivi unique des principales conférences universitaires sur l'IA :https://go.hyper.ai/event
Voici tout le contenu de la sélection de l’éditeur de cette semaine. Si vous avez des ressources que vous souhaitez inclure sur le site officiel hyper.ai, vous êtes également invités à laisser un message ou à soumettre un article pour nous le dire !
À la semaine prochaine !
À propos d'HyperAI
HyperAI (hyper.ai) est une communauté leader en matière d'intelligence artificielle et de calcul haute performance en Chine.Nous nous engageons à devenir l'infrastructure dans le domaine de la science des données en Chine et à fournir des ressources publiques riches et de haute qualité aux développeurs nationaux. Jusqu'à présent, nous avons :
* Fournir des nœuds de téléchargement accélérés nationaux pour plus de 1 700 ensembles de données publiques
* Comprend plus de 500 tutoriels en ligne classiques et populaires
* Interprétation de plus de 200 cas d'articles AI4Science
* Prend en charge la recherche de plus de 600 termes associés
* Hébergement de la première documentation complète d'Apache TVM en Chine
Visitez le site Web officiel pour commencer votre parcours d'apprentissage :
Enfin, je recommande un « Programme d’incitation aux créateurs ». Les amis intéressés peuvent scanner le code QR pour participer !









